列表List:什么是列表?
在前面基本数据结构的讨论中, 我们采用Python List来实现了多种线性数据结构
列表List是一种简单强大的数据集结构,提供了丰富的操作接口
但并不是所有的编程语言都提供了List数据类型,有时候需要程序员自己实现。
一种数据项按照相对位置存放的数据集
特别的,被称为“无序表unordered list”,其中数据项只按照存放位置来索引,如第1个、第2个……、最后一个等。(为了简单起见,假设表中不存在重复数据项)
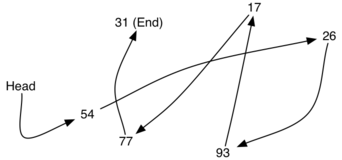
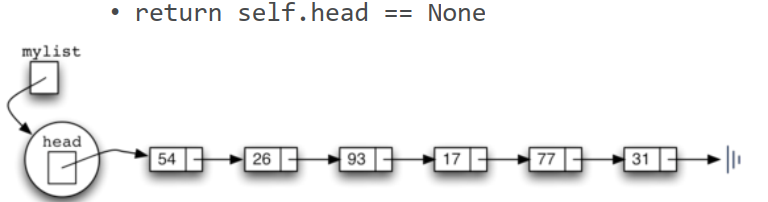
如一个考试分数的集合“54, 26, 93, 17,77和31”
如果用无序表来表示, 就是[54, 26, 93,17, 77, 31]
无序表List的操作如下:
- List():创建一个空列表
- add(item):添加一个数据项到列表中,假设
- item原先不存在于列表中
- remove(item):从列表中移除item,列表被修改, item原先应存在于表中
- search(item):在列表中查找item,返回布尔类型值
- isEmpty():返回列表是否为空
- size():返回列表包含了多少数据项
- append(item):添加一个数据项到表末尾,假设item原先不存在于列表中
- index(item):返回数据项在表中的位置
- insert(pos, item):将数据项插入到位置pos,假设item原先不存在与列表中,同时原列表具有足够多个数据项,能让item占据位置pos
- pop():从列表末尾移除数据项,假设原列表至少有1个数据项
- pop(pos):移除位置为pos的数据项,假设原列表存在位置pos
采用链表实现无序表
为了实现无序表数据结构, 可以采用链接表的方案。
虽然列表数据结构要求保持数据项的前后相对位置, 但这种前后位置的保持, 并不要求数据项依次存放在连续的存储空间

如下图, 数据项存放位置并没有规则, 但如果在数据项之间建立链接指向, 就可以保持其前后相对位置
第一个和最后一个数据项需要显式标记出来,一个是队首,一个是队尾,后面再无数据了。
链表实现:节点Node
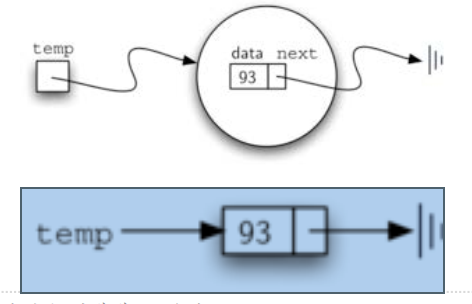
链表实现的最基本元素是节点Node
每个节点至少要包含2个信息: 数据项本身,以及指向下一个节点的引用信息注意next为None的意义是没有下一个节点了,这个很重要
代码
class Node:
def __init__(self, initdata):
self.data = initdata
self.next = None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self, newdata):
self.data = newdata
def setNext(self, newnext):
self.next = newnext
可以采用链接节点的方式构建数据集来实现无序表
链表的第一个和最后一个节点最重要如果想访问到链表中的所有节点,就必须从第一个节点开始沿着链接遍历下去
所以无序表必须要有对第一个节点的引用信息
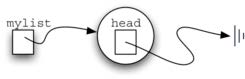
设立一个属性head,保存对第一个节点的引用空表的head为None

随着数据项的加入, 无序表的head始终指向链条中的第一个节点
注意!无序表mylist对象本身并不包含数据项(数据项在节点中)其中包含的head只是对首个节点Node的引用判断空表的isEmpty()很容易实现
接下来, 考虑如何实现向无序表中添加数据项, 实现add方法。
由于无序表并没有限定数据项之间的顺序
新数据项可以加入到原表的任何位置
按照实现的性能考虑, 应添加到最容易加入的位置上。
由链表结构我们知道
要访问到整条链上的所有数据项
都必须从表头head开始沿着next链接逐个向后查找
所以添加新数据项最快捷的位置是表头,整个链表的首位置
add方法
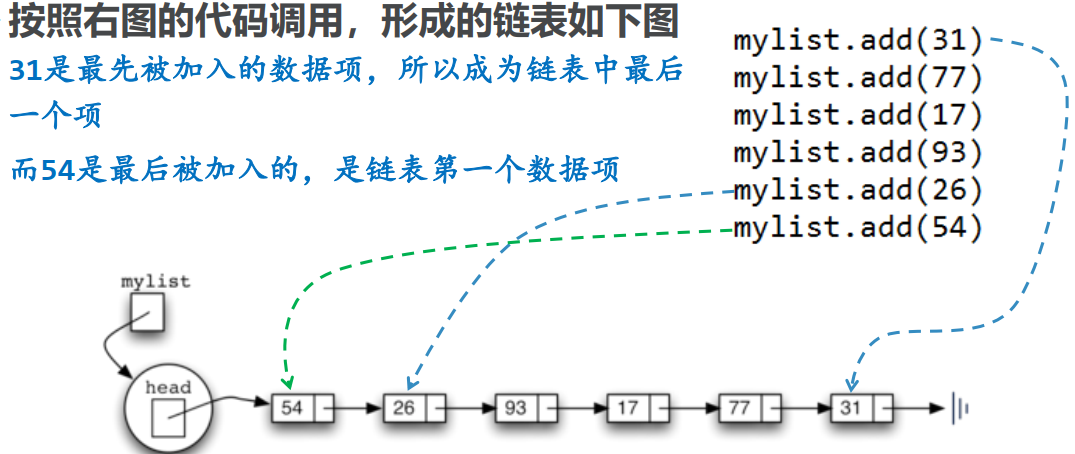
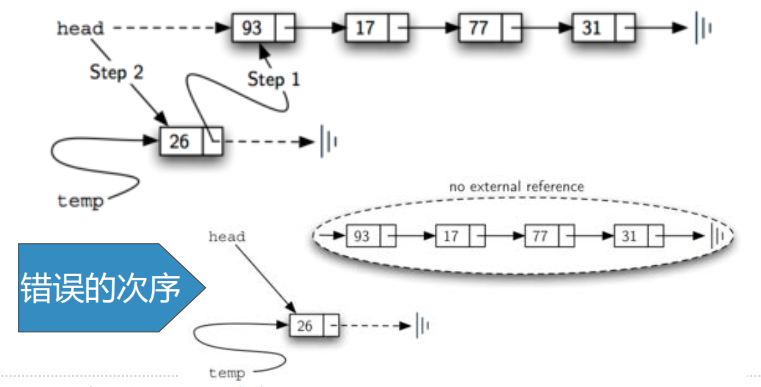
链接次序很重要!add方法实现代码如下:
def add(self, item):
temp = Node(item)
temp.setNext(self.head)
self.head = temp
size:从链条头head开始遍历到表尾同时用变量累加经过的节点个数。
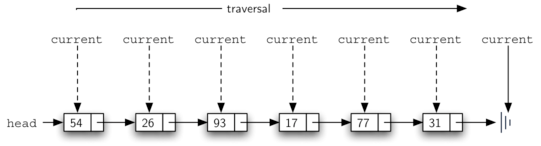
def size(self):
current = self.head
count = 0
while current != None:
count = count + 1
current = current.getNext()
return count
从链表头head开始遍历到表尾, 同时判断当前节点的数据项是否目标
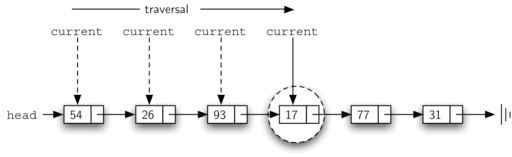
def search(self, item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
remove(item)方法
首先要找到item, 这个过程跟search一样, 但在删除节点时, 需要特别的技巧
current指向的是当前匹配数据项的节点而删除需要把前一个节点的next指向current的下一个节点,所以我们在search current的同时,还要维护前一个(previous)节点的引用
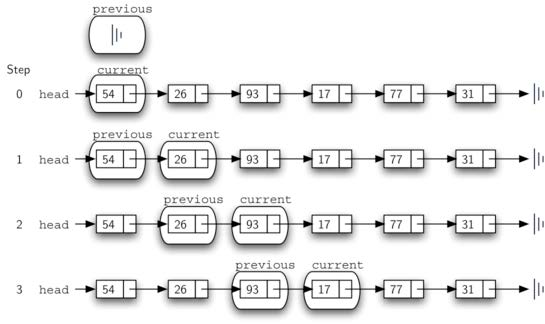
找到item之后, current指向item节点,previous指向前一个节点, 开始执行删除, 需要区分两种情况:
current是首个节点;或者是位于链条中间的节点
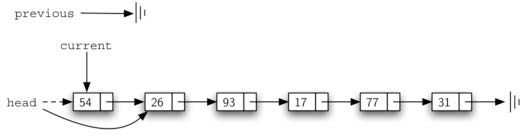
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
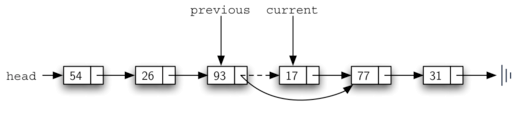
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
完整代码如下:
class UnorderedList:
def __init__(self):
self.head = None
def add(self, item):
temp = Node(item)
temp.setNext(self.head)
self.head = temp
def size(self):
current = self.head
count = 0
while current != None:
count = count + 1
current = current.getNext()
return count
def search(self, item):
current = self.head
found = False
while current != None and not found:
if current.getData() == item:
found = True
else:
current = current.getNext()
return found
def remove(self, item):
current = self.head
previous = None
found = False
while not found:
if current.getData() == item:
found = True
else:
previous = current
current = current.getNext()
if previous == None:
self.head = current.getNext()
else:
previous.setNext(current.getNext())
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: