对比list和dict的操作
| 类型 | list | dict |
|---|---|---|
| 索引 | 自然数i | 不可类型值key |
| 添加 | append、extend、insert | b[k]=v |
| 删除 | pop、remove* | pop |
| 更新 | a[i]=v | b[k]=v |
| 正查 | a[i]、a[i:j] | b[k]、copy |
| 反查 | index(v)、count(v) | 无 |
| 其它 | reverse、sort | has_key、update |
List列表数据类型
list 类型各种操作的实现方法有很多,如何选择具体哪种实现方法?
总的方案就是,让最常用的操作性能最好,牺牲不太常用的操作
80/20 准则:80%的功能其使用率只有20%
List列表数据类型常用操作性能
最常用的是:按索引取值和赋值(v=a[i], a[i]=v)
由于列表的随机访问特性,这两个操作执行时间与列表大小无关,均为O(1)
另一个是列表增长,可以选择append()和__add__() “+”
lst.append(v),执行时间是O(1)
lst=lst+[v],执行时间是O(n+k),其中k是被加的列表长度
选择哪个方法来操作列表,决定了程序的性能
4 种生成前n个整数列表的方法
首先是循环连接列表 (+)方式生成
def test1():
l = []
for i in range(1000):
l = l + [i]
然后是用append方法添加元素生成
def test2():
l = []
for i in range(1000):
l.append(i)
接着用列表推导式来做
def test3():
l = [i for i in range(1000)]
最后是range函数调用转成列表
def test4():
l = list(range(1000))
使用timeit模块对函数计时
创建一个Timer对象,指定需要反复运行的语句和只需要运行一次的“安装语句”
然后调用这个对象的timeit方法,其中可以指定反复运行多少次
from timeit import Timer
t1 = Timer("test1()", "from main import test1")
print("concat %f seconds\n" % t1.timeit(number=1000))
t2 = Timer("test2()", "from main import test2")
print("append %f seconds\n" % t2.timeit(number=1000))
t3 = Timer("test3()", "from main import test3")
print("comprehension %f seconds\n" % t3.timeit(number=1000))
t4 = Timer("test4()", "from main import test4")
print("list range %f seconds\n" % t4.timeit(number=1000))
list range最快 > 列表推导式 > append > concat 相加
concat 1.818228 seconds
append 0.090310 seconds
comprehension 0.040583 seconds
list range 0.017432 seconds
List基本操作的大O数量级
| Operation | Big-O Efficiency |
|---|---|
| index[] | O(1) |
| index assignment | O(1) |
| append | O(1) |
| pop() | O(1) |
| pop(i) | O(n) |
| insert(i, item) | O(n) |
| del operator | O(n) |
| iteration | O(n) |
| contains(in) | O(n) |
| get slice[x:y] | O(k) |
| get slice | O(k) |
| set slice[x:y] | O(n+k) |
| reverse | O(n) |
| concatenate | O(k) |
| sort | O(n log n) |
| multiply | O(nk) |
list.pop 的计时试验
我们注意到pop这个操作
- pop() 从列表末尾移除元素,O(1)
- pop(i) 从列表中部移除元素,O(n)
原因在于Python所选择的实现方法
从中部移除元素的话,要把移除元素后面的元素全部向前挪位复制一遍,这个看起来有点笨拙,但这种实现方法能够保证列表按索引取值和赋值的操作很快,达到O(1),这也算是一种对常用和不常用操作的折衷方案。
为了验证表中的大O数量级,我们把两种情况下的pop操作来实际计时对比
相对同一个大小的list,分别调用pop()和pop(0)
对不同大小的list做计时,期望的结果是
pop()的时间不随list大小变化,pop(0)的时间随着list变大而变长
首先我们看对比
对于长度2百万的列表,执行1000次
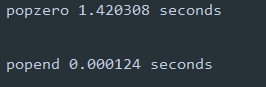
from timeit import Timer
popzero = Timer("x.pop(0)", "from main import x")
print("popzero %f seconds\n" % popzero.timeit(number=1000))
popend = Timer("x.pop()", "from main import x")
print("popend %f seconds\n" % popend.timeit(number=1000))
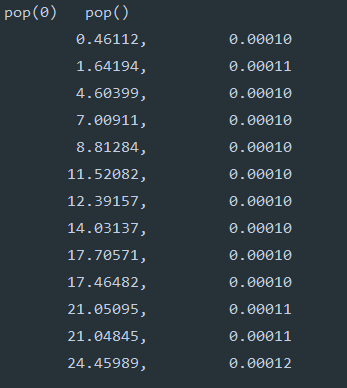
我们通过改变列表的大小来测试两个操作的增长趋势
from timeit import Timer
popzero = Timer("x.pop(0)", "from __main__ import x")
popend = Timer("x.pop()", "from __main__ import x")
print("pop(0) pop()")
for i in range(1000000, 100000001, 1000000):
x = list(range(i))
pt = popend.timeit(number=1000)
x = list(range(i))
pz = popzero.timeit(number=1000)
print("%15.5f, %15.5f"%(pz, pt))
if __name__ == '__main__':
x = list(range(2000000))
输出结果:
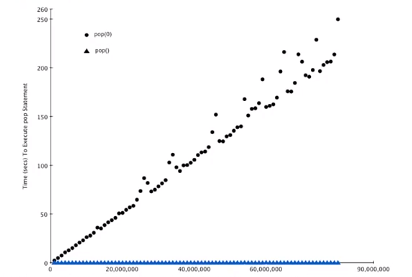
将试验数据画成图表,可以看出增长趋势
pop()是平坦的常数
pop(0)是线性增长的趋势
dict数据类型
字典与列表不同,根据关键码(key)找到数据项,而列表是根据位置(index)
最常用的取值get和赋值set,其性能为O(1),另一个重要操作contains(in)是判断字典中是否存在某个关键码(key),这个性能也是O(1)
| operation | Big-O Efficiency |
|---|---|
| copy | O(n) |
| get item | O(1) |
| set item | O(1) |
| delete item | O(1) |
| contains(in) | O(1) |
| iteration | O(n) |
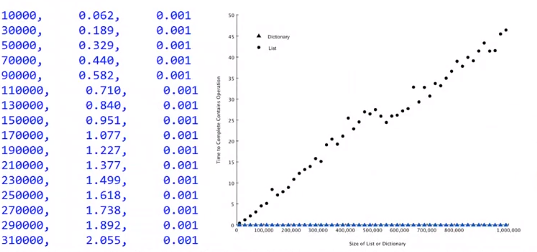
设计一个性能试验来验证list中检索一个值,以及dict中检索一个值的计时对比
生成包含连续值的list和包含连续关键码key的dict,用随机数来检验操作符in的耗时。
for i in range(10000, 1000001, 20000):
t = Timer("random.randrange(%d) in x" % i, "from __main__ import random, x")
x = list(range(i))
lst_time = t.timeit(number=1000)
x = {
j:None for j in range(i)}
d_time = t.timeit(number=1000)
print("%d, %10.3f, %10.3f" % (i, lst_time, d_time))
可见字典的执行时间与规模无关,是常数
而列表的执行时间则随着列表的规模加大而线性上升
输出结果:
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: