线性表的链式存储结构
我们知道线性表的顺序存储结构在插入和删除操作时需要移动大量的数据,他们的时间复杂度为O(n) O ( n ) 。当我们需要经常插入和删除数据时,顺序存储结构就不适用了,这时我们就需要用到线性表的链式存储结构。
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置。我们先来看下链式存储结构。
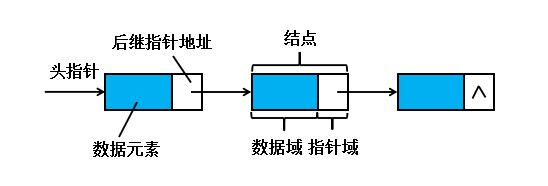
图1单链表的示意图 图 1 单 链 表 的 示 意 图
上图是链式存储结构中单链表的示意图。从图中,我们可以看出一个链式存储结构由若干个结点(Node),串联而成。每个结点有两个部分,数据域和指针域。数据域中存储数据元素,指针域中存储后继指针地址。为了能够找到链表位置,就需要一个指向链表第一个元素的指针,我们把它称为头指针。此外,我们把链表中第一个结点叫做头结点。头结点的数据域一般不存储任何信息,也可以用于存储线性表的长度等附加信息。
线性表链式存储结构代码描述
下面我们以单链表为例,可以用C++的类来描述。
class Node
{
public:
Node();
~Node();
friend void traverse_list(Node *pHead);//输出整个链表
friend Node * create_list();//创建非循环单链表
friend bool is_empty_list(Node *pHead);//判断是否为空
friend int length_list(Node *pHead);//链表长度
friend bool insert_list(Node *pHead, int pos, int val);//在pos位置插入值val
friend bool delet_list(Node *pHead, int pos , int*pval);//将pos位置的值删除
friend void sort_list(Node *pHead);//排序
private:
int data;//数据域
Node *pNext;//指针域
};
我们再看下每个操作的具体实现代码:
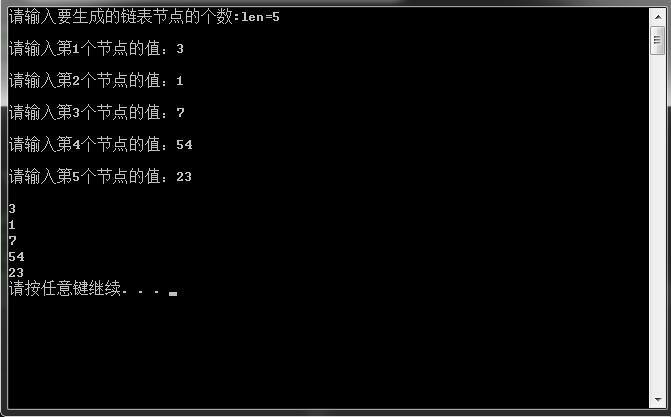
Node * create_list()//创建非循环单链表
{
int len;
int val;//存放临时的值
cout << "请输入要生成的链表节点的个数:len=";
cin >> len;
cout << endl;
Node* pHead = new Node;//头节点
pHead->pNext = NULL;
Node* pTail = pHead;
for (int i = 0; i < len; i++)
{
cout << "请输入第" << i + 1 << "个节点的值:";
cin >> val;
cout << endl;
Node* pNew = new Node;
pNew->data = val;
pTail->pNext = pNew;
pNew->pNext = NULL;
pTail = pNew;
}
return pHead;
}
void traverse_list(Node *pHead)//输出整个链表
{
Node *p = pHead->pNext;
while (p != NULL)
{
cout << p->data << endl;
p = p->pNext;
}
}
bool is_empty_list(Node *pHead)//判断是否为空
{
return pHead->pNext == NULL ? true : false;
}
int length_list(Node *pHead)//链表长度
{
Node* p = pHead;
int len = 0;
while (p->pNext != NULL)
{
len++;
p = p->pNext;
}
return len;
}
void sort_list(Node *pHead)//排序
{
int i, j, t;
int len = length_list(pHead);
Node *p, *q;
for (i = 0, p = pHead->pNext; i < len - 1; i++, p = p->pNext)
{
for (j = i+1, q = p->pNext; j < len; j++, q = q->pNext)
{
if (p->data > q->data)
{
t = p->data;
p->data = q->data;
q->data = t;
}
}
}
}
bool insert_list(Node *pHead, int pos, int val)//在pos位置插入值val
{
int i = 0;
Node* p=pHead;
while (p != NULL&&i < pos - 1)
{
p = p->pNext;
i++;
}
if (i>pos - 1 || p == NULL)
return false;
Node*pNew = new Node;
pNew->data = val;
pNew->pNext = p->pNext;
p->pNext = pNew;
return true;
}
bool delet_list(Node *pHead, int pos, int* pval)//将pos位置的值删除
{
int i = 0;
Node* p = pHead;
while (p->pNext != NULL&&i < pos - 1)
{
p = p->pNext;
i++;
}
if (i>pos - 1 || p->pNext == NULL)
return false;
Node *q = p->pNext;
*pval = q->data;
p->pNext = p->pNext->pNext;
delete q;
return true;
}
我们先来看下单链表的创建,其实就相当于一个数组的初始化。其算法思路如下:
1、 声明一结点p和长度变量len;
2、 初始化一空链表L;
3、 让L的头结点的指针指向NULL,即建立一个带头结点的单链表i;
4、 循环:;
生成一新结点赋值给 p;
随机生成一数字赋值给 p 的数据域 p->data;
将 p 插入到链表中。
要输出整个链表则先读取头结点下个结点数据域中的数据元素,再读取指针域中的地址,将指针指向下一个结点。
#include<iostream>
#include "Node.h"
using namespace std;
Node * create_list();
void traverse_list(Node *pHead);
bool is_empty_list(Node *pHead);
int length_list(Node *pHead);
bool insert_list(Node *pHead,int pos,int val);
bool delet_list(Node *pHead,int pos,int* pval);
void sort_list(Node *pHead);
int main()
{
Node* pHead = NULL;
int val;
pHead = create_list();
system("pause");
return 0;
}
在VS下运行结果如下:
单链表第 i 个数据插入结点的算法思路如下:
1、 声明一结点p指向链表第一个结点,初始化j从1开始;
2、 当j<ij<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3、 若到链衰末尾p为空,则说明第i个元素不存在;
4、 否则查找成功,在系统中生成一个空结点s;;
5、 将数据元素e赋值给s->data;;
6、 单链表的插入标准语句s->next=p->next.;p->next=s;;
7、 返回成功;
#include<iostream>
#include "Node.h"
using namespace std;
Node * create_list();
void traverse_list(Node *pHead);
bool is_empty_list(Node *pHead);
int length_list(Node *pHead);
bool insert_list(Node *pHead,int pos,int val);
bool delet_list(Node *pHead,int pos,int* pval);
void sort_list(Node *pHead);
int main()
{
Node* pHead = NULL;
int val;
pHead = create_list();
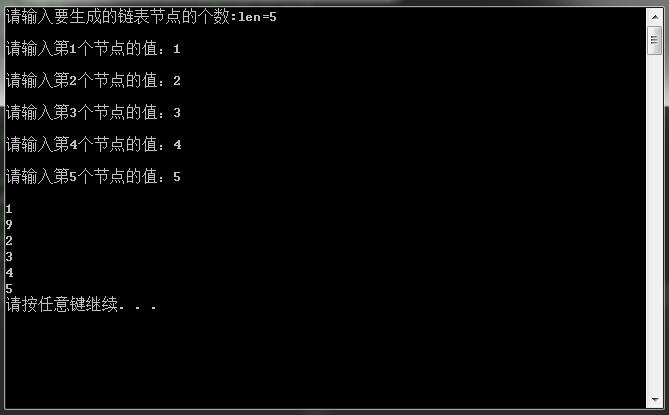
insert_list(pHead, 2, 9);
traverse_list(pHead);
system("pause");
return 0;
}
在VS下运行结果如下:
单链表第 i 个数据删除结点的算法思路:
1、 声明一结点p指向链表第一个结点,初始化j从1开始j;
2、 当j<ij<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
3、 若到链表末尾p为空,则说明第i个元素不存在;;
4、 否则查找成功,将欲删除的结点p->next赋值给q;;
5、 主在链表的删除标准语句p->next=q->next;;
6、 将q结点中的数据赋值给e,作为返回;;
7、 释放q结点;;
8、 返回成功;
#include<iostream>
#include "Node.h"
using namespace std;
Node * create_list();
void traverse_list(Node *pHead);
bool is_empty_list(Node *pHead);
int length_list(Node *pHead);
bool insert_list(Node *pHead,int pos,int val);
bool delet_list(Node *pHead,int pos,int* pval);
void sort_list(Node *pHead);
int main()
{
Node* pHead = NULL;
int val;
pHead = create_list();
traverse_list(pHead);
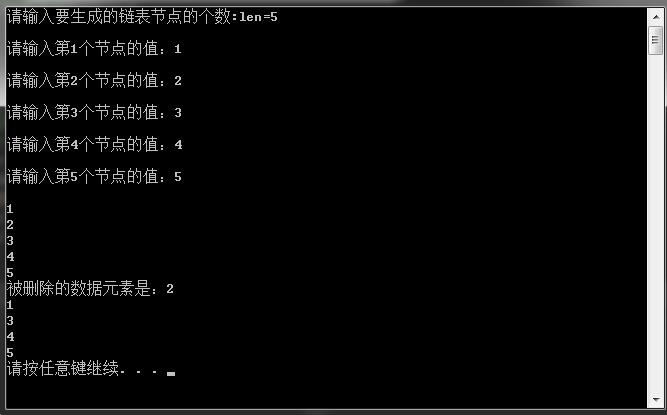
delet_list(pHead, 2, &val);
cout << "被删除的数据元素是:" << val << endl;
traverse_list(pHead);
system("pause");
return 0;
}
在VS下运行结果如下:
单链表结构与顺序存储结构优缺点
储存分配方式
- 顺序存储结构:连续依次存储。
- 单链表:一组任意的存储单元可以离散存储。
时间性能
| 查找 | 插入和删除 | |
|---|---|---|
| 顺序存储结构 | O(1) | O(n) |
| 单链表 | O(n) | O(1) |
空间性能
- 顺序存储结构:需要预分配存储空间,分大了浪费,分小了易发生上溢。
- 单链表:不需要预分配存储空间,只要有就可以分配,元素个数也不受限制。
其他的链式存储结构
下面我们简单介绍下其他几种链式存储结构。
静态链表
静态链表是用数组描述的链表,又叫做游标实现法。它其实是为了给没有指针的高级语言设计的一种实现单链表能力的方法。
循环链表
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表 ( circular linked list) 。
双向链表
双向链表(double linked List) 是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域, 一个指向直接后继,另一个指向直接前驱。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: