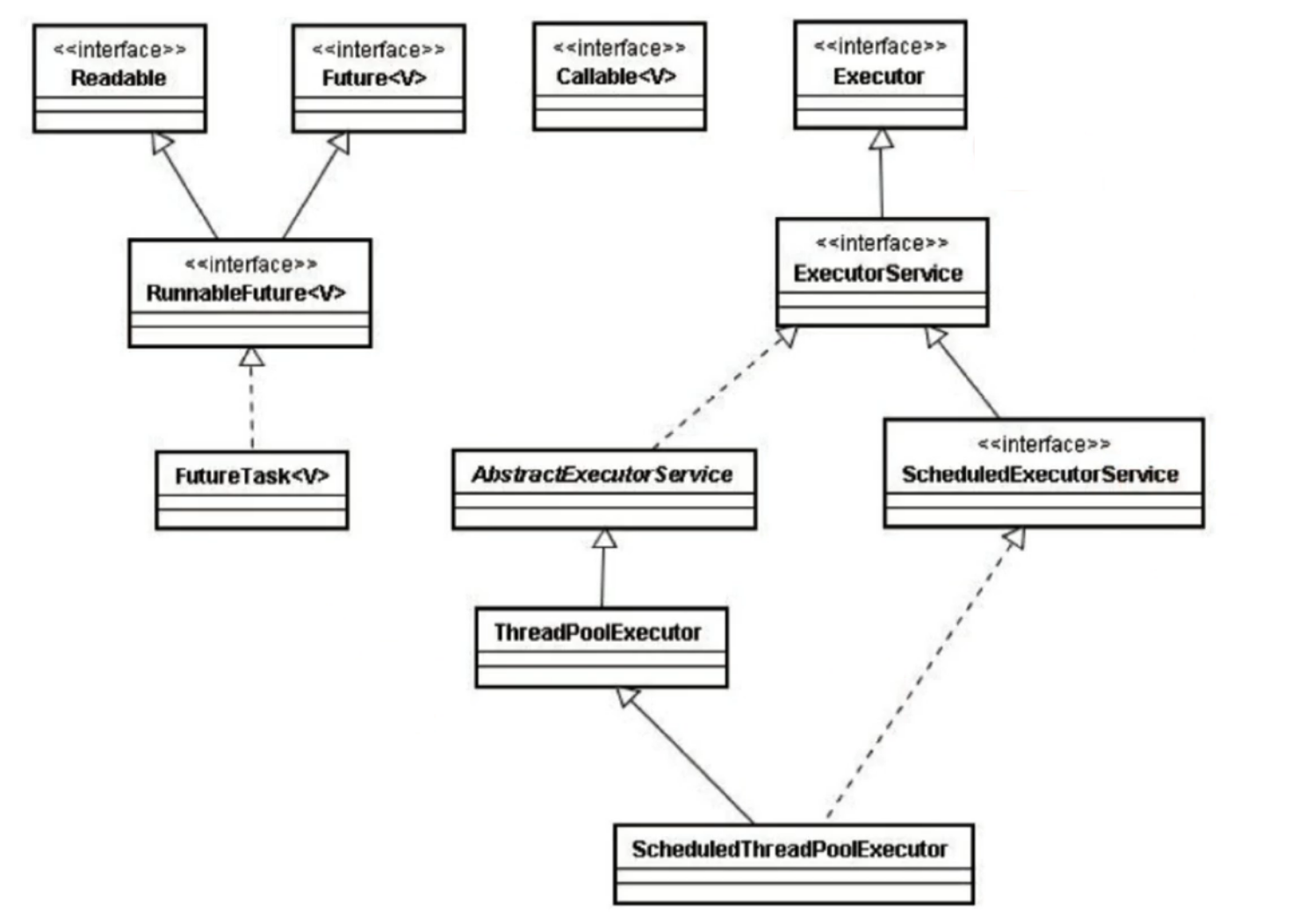
一、Executor框架
1.1 介绍
Executor框架包括3大部分:
- 任务。也就是工作单元,包括被执行任务需要实现的接口:Runnable接口或者Callable接口;
- 任务的执行。也就是把任务分派给多个线程的执行机制,包括Executor接口及继承自Executor接口的ExecutorService接口。
- 异步计算的结果。包括Future接口及实现了Future接口的FutureTask类。
Executor框架的成员及其关系可以用一下的关系图表示:
1.2 使用流程
Executor框架的使用示意图:
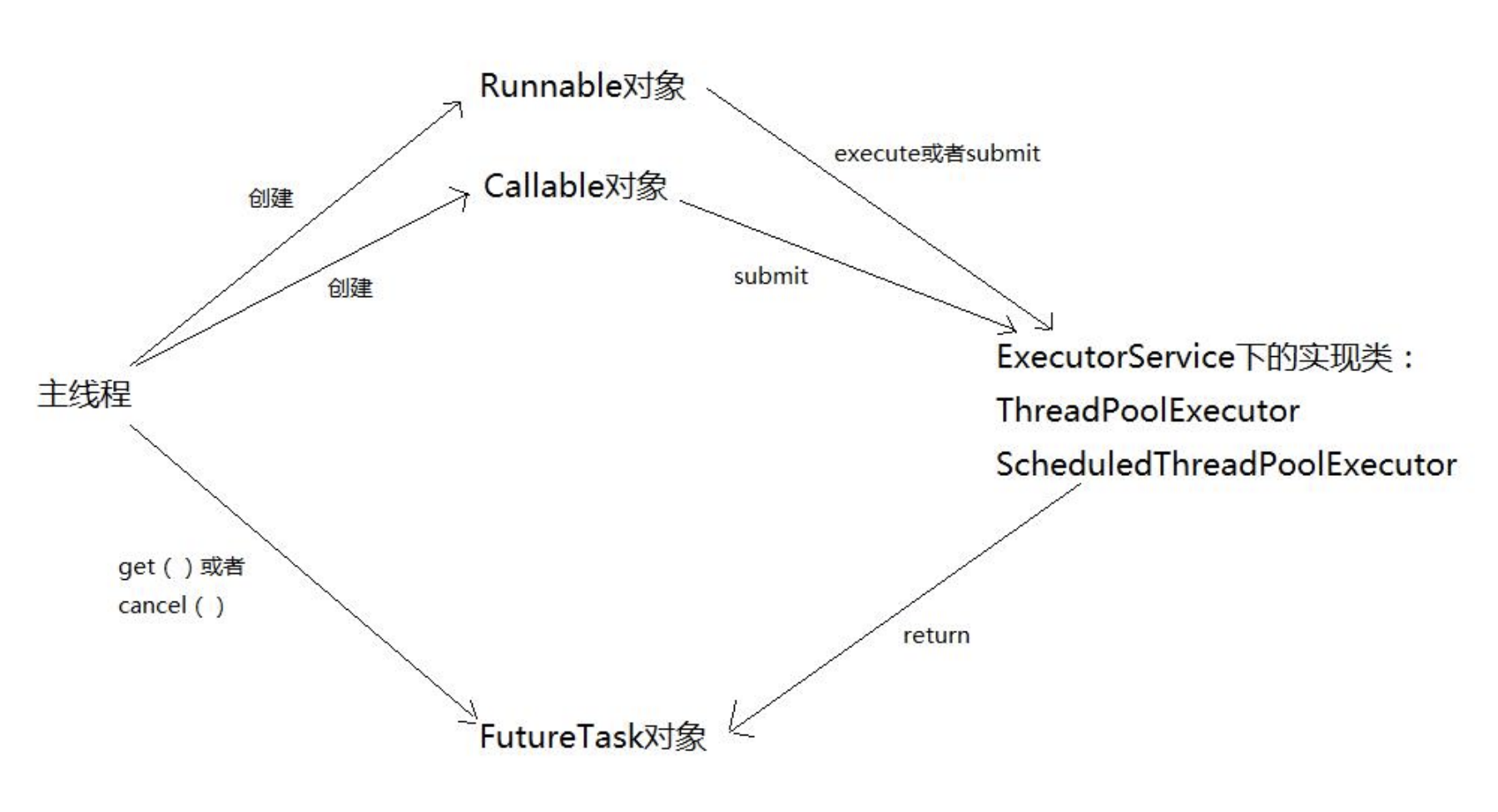
使用步骤:
- 创建Runnable并重写run()方法或者Callable对象并重写call()方法,得到一个任务对象
class callableImp implements Callable<String >{
@Override
public String call() {
try{
String a = "return String";
return a;
}
catch(Exception e){
e.printStackTrace();
return "exception";
}
}
}
- 创建ExecutorService接口的实现类ThreadPoolExecutor类或者ScheduledThreadPoolExecutor类的对象,然后调用其execute()方法或者submit()方法,提交任务对象执行。
- 主线程调用Future对象的get()方法获取返回值,或者调用Future对象的cancel()方法取消当前线程的执行。
1.3 成员介绍
Executor框架成员:ThreadPoolExecutor实现类、ScheduledThreadPoolExecutor实现类、Future接口、Runnable和Callable接口、Executors工厂类
- Executor:执行器接口,也是最顶层的抽象核心接口, 分离了任务和任务的执行。ExecutorService在Executor的基础上提供了执行器生命周期管理,任务异步执行等功能。
- Executors:生产具体的执行器的静态工厂,工具类。
- ThreadPoolExecutor:线程池Executor,也是最常用的Executor,通常使用Executors来创建,可以创建三种类型的ThreadPoolExecutor:SingleThreadPoolExecutor,FixedThreadPool和 CachedThreadPool,以线程池的方式管理线程。
- ScheduledThreadPoolExecutor:在ThreadPoolExecutor基础上,增加了对周期任务调度的支持。
- Runnable和Callable接口:Runnable和Callable接口的实现类,可以被ThreadPoolExecutor和ScheduledThreadPoolExecutor执行,区别是,前没有返回结果,后者可以返回结果。
二、Callable和FutureTask
2.1 介绍
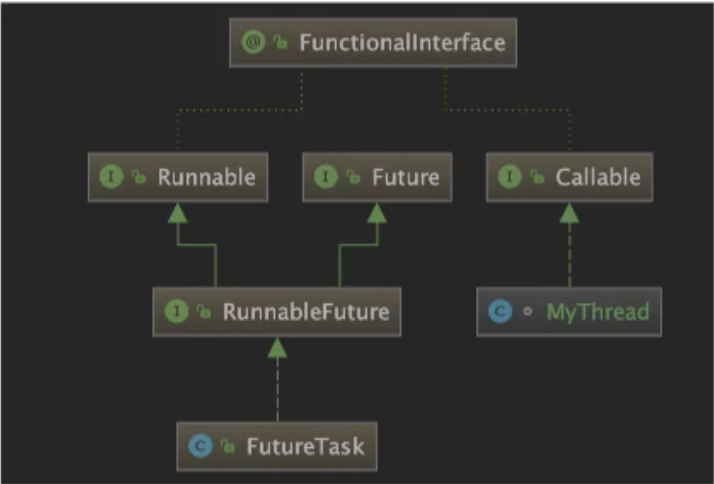
Callable与Runnable的区别
1、 Callable带返回值;
2、 会抛出异常;
3、 覆写call()⽅法,⽽不是run()⽅法;
FutureTask的构造需要一个Callable,Callable里有一个call()方法和Runnable的run()方法作用一样,只不过更强,可以返回结果
2.2 Callable接⼝的使⽤
//实现Callable接口
class MyThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("callable come in ...");
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1024;
}
}
public class CallableDemo {
public static void main(String[] args) throws ExecutionException,InterruptedException {
//创建FutureTask类,接受MyThread。
FutureTask<Integer> futureTask = new FutureTask<>(new MyThread());
//将FutureTask对象放到Thread类的构造器里面。
new Thread(futureTask, "AA").start();
int result01 = 100;
//用FutureTask的get方法得到返回值。
int result02 = futureTask.get();
System.out.println("result=" + (result01 + result02));
}
}
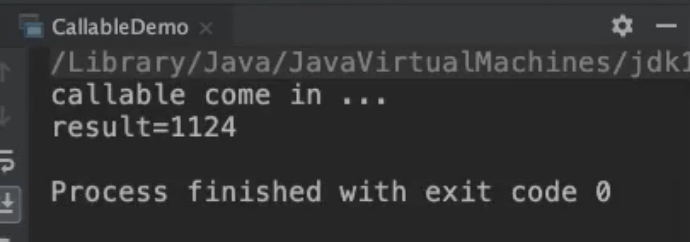
如果异步任务还没有完成,futureTask.get()会让当前线程阻塞,直到获得结果。
三、ThreadPoolExecutor
3.1 线程池基本概念
概念
线程池主要是控制运⾏线程的数量,将待处理任务放到等待队列,然后创建线程执⾏这些任务。如果线程数量超过了最⼤数量,超出数量的任务排队等候,等其他线程执⾏完毕,再从队列中取出任务来执⾏。
线程池的主要特点
线程复⽤;控制最⼤并发数;管理线程。
- 线程复⽤:不⽤⼀直new新线程,重复利⽤已经创建的线程来降低线程的创建和销毁开销,节省系统资源。
- 提⾼响应速度:当任务达到时,不⽤创建新的线程,直接利⽤线程池的线程。
- 管理线程:可以控制最⼤并发数,控制线程的创建等。
例如tomcat,web服务器最大并发量就是里面的线程池的线程数量
和火车站卖票窗口类似。
3.2 API介绍

线程池解决两个问题:
- 如果有大量任务需要异步处理,这些任务交给线程处理势必就会创建大量的线程、再去销毁,如果有线程池就可以避免大量线程的创建和销毁切换,节省资源
- 线程池能解决线程的管理问题。只需要关注业务模块不需要考虑线程的管理问题。
- 维护一些基本的统计信息。多少任务成功、多少任务异常
3.3 ThreadPoolExecutor构造的七个参数
ThreadPoolExecutor一共提供了4种构造器,但其它三种内部其实都调用了下面的构造器。
/**
* 使用给定的参数创建ThreadPoolExecutor.
*
* @param corePoolSize 核心线程池中的核心线程数
* @param maximumPoolSize 总线程池中的最大线程数
* @param keepAliveTime 空闲线程的存活时间
* @param unit keepAliveTime的单位
* @param workQueue 任务队列, 保存已经提交但尚未被执行的线程
* @param threadFactory 线程创建工厂
* @param handler 拒绝策略 (当任务太多导致工作队列满时的处理策略)
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
| 参数 | 意义 |
|---|---|
| corePoolSize | 线程池中的常驻核⼼线程数 |
| maximumPoolSize | 线程池中能够容纳同时指向的最⼤线程数,此值必须⼤于等于1 |
| keepAliveTime | 多余的空闲线程的存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为⽌ |
| unit | keepAliveTime存活时间的单位 |
| workQueue | 任务队列,存放已提交但尚未执⾏的任务 |
| threadFactory | 表示⽣成线程池中⼯作线程的线程⼯⼚,⽤于创建线程,⼀般默认的即可 |
| handler | 拒绝策略,表示当队列满了,并且⼯作线程⼤于等于线程池的最⼤线程数(maximumPoolSize)时,如何来拒绝请求执⾏的runnable的策略 |
3.4 线程池的状态流转
线程池状态定义;
/*
* RUNNING -> SHUTDOWN
* On invocation of shutdown(), perhaps implicitly in finalize()
* (RUNNING or SHUTDOWN) -> STOP
* On invocation of shutdownNow()
* SHUTDOWN -> TIDYING
* When both queue and pool are empty
* STOP -> TIDYING
* When pool is empty
* TIDYING -> TERMINATED
* When the terminated() hook method has completed
*
*/
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
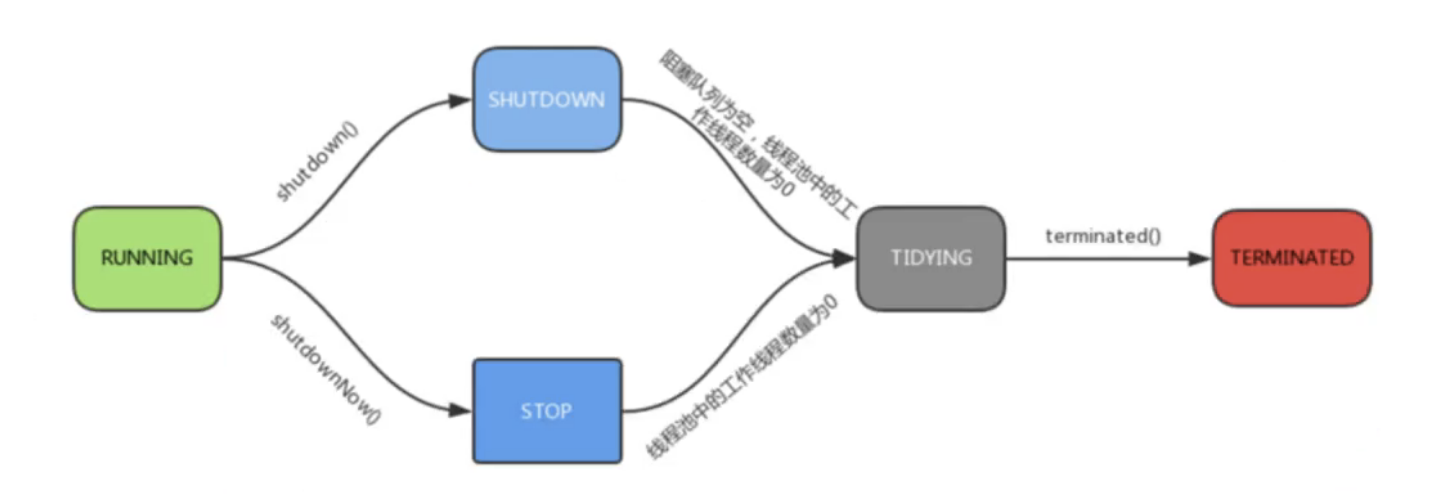
ThreadPoolExecutor一共定义了5种线程池状态:
- RUNNING : 接受新任务, 且处理已经进入阻塞队列的任务
- SHUTDOWN : 不接受新任务, 但处理已经进入阻塞队列的任务
- STOP : 不接受新任务, 且不处理已经进入阻塞队列的任务, 同时中断正在运行的任务
- TIDYING : 所有任务都已终止, 工作线程数为0, 线程转化为TIDYING状态并准备调用terminated方法
- TERMINATED : terminated方法已经执行完成
各个状态之间的流转图:
3.5 线程池底层原理
理解线程池七个参数
线程池的创建参数,就像⼀个银⾏。
corePoolSize 就像银⾏的“当值窗⼝“,⽐如今天有2位柜员在受理客户请求(任务)。
如果超过2个客户,那么新的客户就会在等候区(等待队列 workQueue )等待。
当等候区也满了,这个时候就要开启“加班窗⼝”,让其它3位柜员来加班,此时达到最⼤窗⼝maximumPoolSize ,为5个。
如果开启了所有窗⼝,等候区依然满员,此时就应该启动”拒绝策略“ handler ,告诉不断涌⼊的客户,叫他们不要进⼊,已经爆满了。
由于不再涌⼊新客户,办完事的客户增多,窗⼝开始空闲,这个时候就通过 keepAlivetTime 将多余的3个”加班窗⼝“取消,恢复到2个”当值窗⼝“。
案例图:
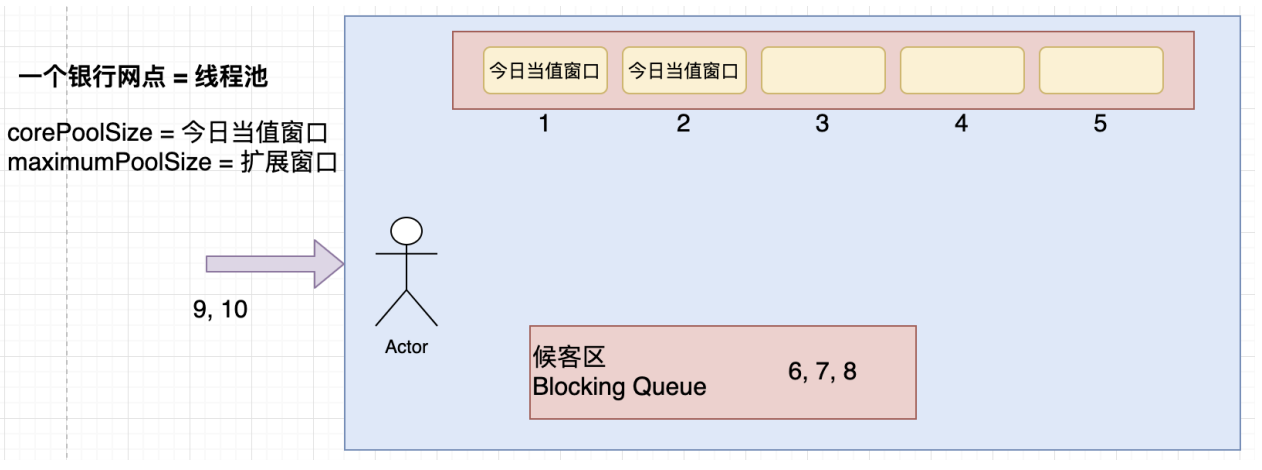
这个图有点小问题,应该是3,4,5在候客区,6,7,8在窗口。
线程池流程图解
原理图:上⾯银⾏的例⼦,实际上就是线程池的⼯作原理。
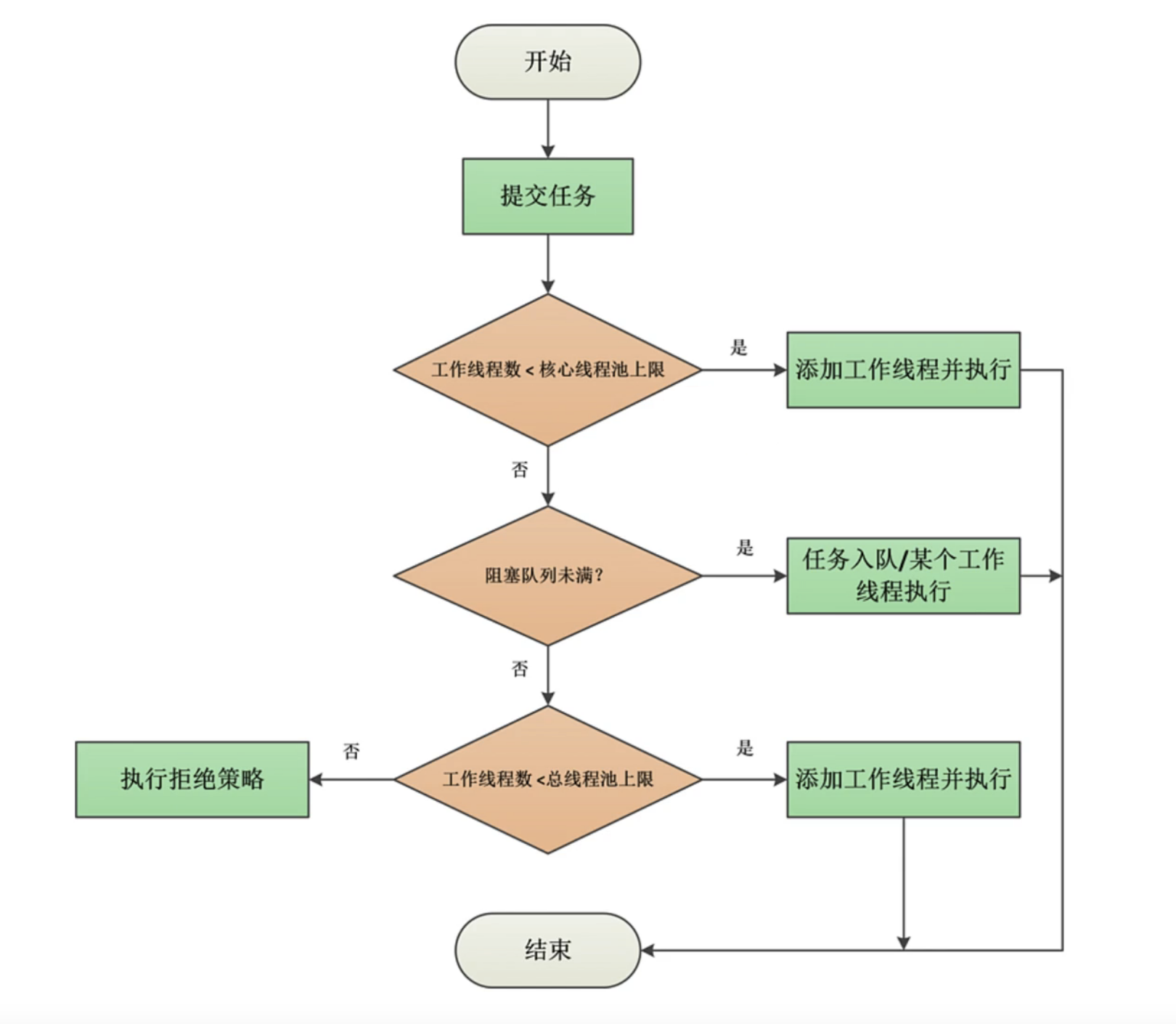
流程:
1、 在创建了线程池后,开始等待请求;
2、 当调⽤execute()⽅法添加⼀个请求任务时,线程池会做出如下判断:;
2、 1如果正在运⾏的线程数量⼩于corePoolSize,那么⻢上创建核⼼线程运⾏执⾏这个任务;
2、 2如果正在运⾏的线程数量⼤于或等于corePoolSize,那么将这个任务放⼊队列;
2、 3如果这个时候等待队列已满,且正在运⾏的线程数量⼩于maximumPoolSize,那么还是要创建⾮核⼼线程⽴刻运⾏这个任务;
2、 4如果这个时候等待队列已满,且正在运⾏的线程数量⼤于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执⾏;
3、 当⼀个线程完成任务时,它会从等待队列中取出下⼀个任务来执⾏;
4、 当⼀个线程⽆事可做超过⼀定的时间(keepAliveTime)后,线程会判断:;
如果当前运⾏的线程数⼤于 corePoolSize ,那么这个⾮核⼼线程就被停掉。当线程池的所有任务完成后,它最终会收缩到 corePoolSize 的⼤⼩。
执行流程源码分析
执行execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();//c是线程池状态
if (workerCountOf(c) < corePoolSize) {
// CASE1: 工作线程数 < 核心线程池上限
if (addWorker(command, true)) // 添加工作线程并执行,true代表线程会被放到核心线程池中
return;
c = ctl.get();
}
// 执行到此处, 说明工作线程创建失败 或 工作线程数≥核心线程池上限
if (isRunning(c) && workQueue.offer(command)) {
// CASE2: 插入任务至队列
// 成功插入再次检查线程池状态
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command))//判断线程池状态,没有运行则移除该任务并执行拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0)//检查工作线程是否为0,防止没有线程执行任务
addWorker(null, false);//添加工作线程
} else if (!addWorker(command, false)) // CASE3: 插入队列失败,则开启一个工作线程去执行该任务
reject(command); // 执行拒绝策略
}
execute的整个执行流程关键是下面两点:
- 如果工作线程数小于核心线程池上限(CorePoolSize),则直接新建一个工作线程并执行任务;
- 如果工作线程数大于等于CorePoolSize,则尝试将任务加入到队列等待以后执行。如果加入队列失败了(比如队列已满的情况),则在总线程池未满的情况下( CorePoolSize ≤ 工作线程数 <maximumPoolSize )新建一个工作线程立即执行任务,否则执行拒绝策略。
3.6 线程池常用三种创建方式
类似Arrays 、 Collections ⼯具类, Executor 也有⾃⼰的⼯具类 Executors 。通过Executor框架的工具类Executors,可以快速创建三种类型的ThreadPoolExecutor:
注意: Executors中快速创建线程池的方式不只下面三种
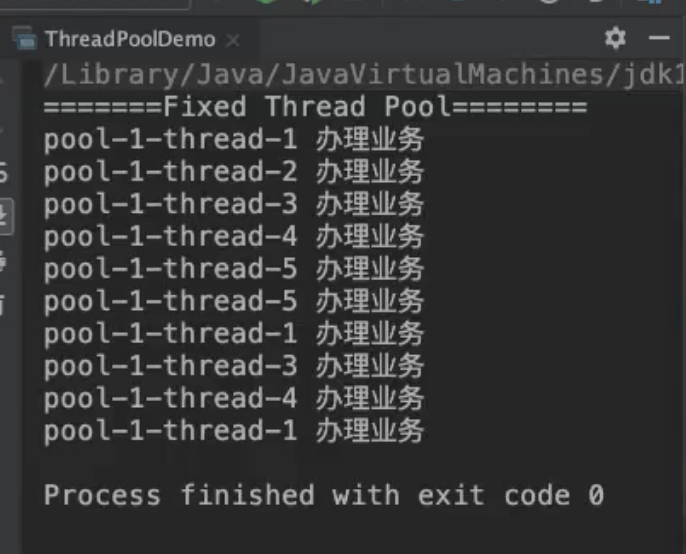
FixedThreadPool
可重用固定线程数的线程池:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
newFixedThreadPool:创建一个固定长度的线程池,每次提交一个任务的时候就会创建一个新的线程,直到达到线程池的最大数量限制。
- 定长,可以控制线程最大并发数, corePoolSize 和 maximumPoolSize 的数值都是nThreads。
- 超出线程数的任务会在队列中等待。
- 工作队列为LinkedBlockingQueue。
创建方法
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads);
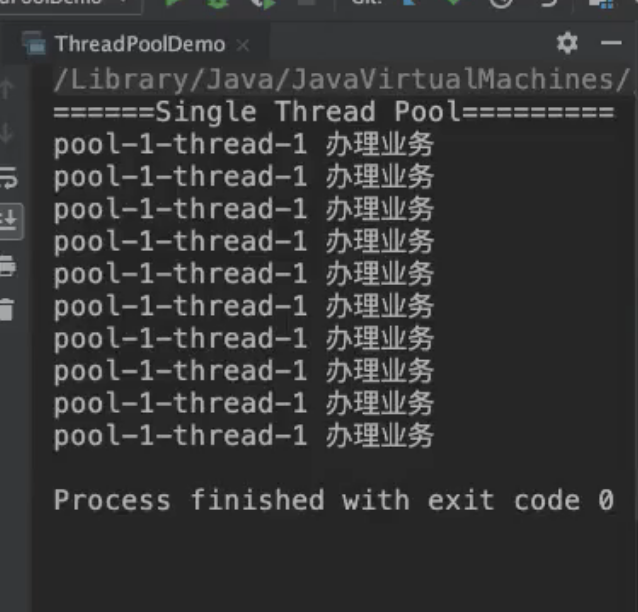
SingleThreadExecutor
使用单个线程的Executor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),threadFactory));
}
newSingleThreadExecutor:只创建一个工作线程执行任务,若这个唯一的线程异常故障了,会新建另一个线程来替代,newSingleThreadExecutor可以保证任务依照在工作队列的排队顺序来串行执行。
- 有且仅有一个工作线程执行任务;
- 所有任务按照工作队列的排队顺序执行,先进先出的顺序。
- 工作队列LinkedBlockingQueue。
创建方法
ExecutorService singleThreadPool = Executors.newSingleThreadPool();
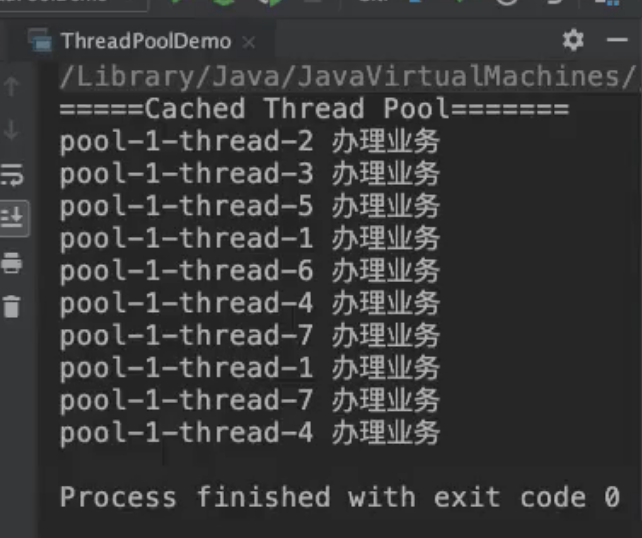
CachedThreadPool
会根据需要创建新线程的线程池
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
newCachedThreadPool将创建一个可缓存的线程池,如果当前线程数超过处理任务时,回收空闲线程;当需求增加时,可以添加新线程去处理任务。
特点:
- 线程数无限制,corePoolSize数值为0, maximumPoolSize 的数值都是为Integer.MAX_VALUE。
- 若线程未回收,任务到达时,会复用空闲线程;若无空闲线程,则新建线程执行任务。
- 因为复用性,一定程序减少频繁创建/销毁线程,减少系统开销。
- 工作队列选用SynchronousQueue。
创建方法
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
案例演示
/**
* 线程池代码演示
*/
public class ThreadPoolDemo {
public static void main(String[] args) {
//System.out.println("=======Fixed Thread Pool========");
//一个池子有5个工作线程,类似银行有5个受理窗口
//threadPoolTask( Executors.newFixedThreadPool(5) );
//System.out.println("======Single Thread Pool=========");
// //一个池子有1个工作线程,类似银行有1个受理窗口
//threadPoolTask( Executors.newSingleThreadExecutor() );
//System.out.println("=====Cached Thread Pool=======");
// //不定量线程,一个池子有N个工作线程,类似银行有N个受理窗口
//threadPoolTask( Executors.newCachedThreadPool() );
//自定义参数线程池
System.out.println("=====Custom Thread Pool=======");
threadPoolTask( new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy()
));
}
private static void threadPoolTask(ExecutorService threadPool) {
//模拟有10个顾客来办理业务
try {
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName()+"\t办理业务");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
}
newFixedThreadPool:看到最多并且一直只有5个线程在处理
newSingleThreadExecutor:看到只有一个线程一直在处理
newCachedThreadPool:随着任务压力动态调整线程数量