一、ConcurrentHashMap
1.1 HashMap
HashMap容量
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
线程不安全的 HashMap
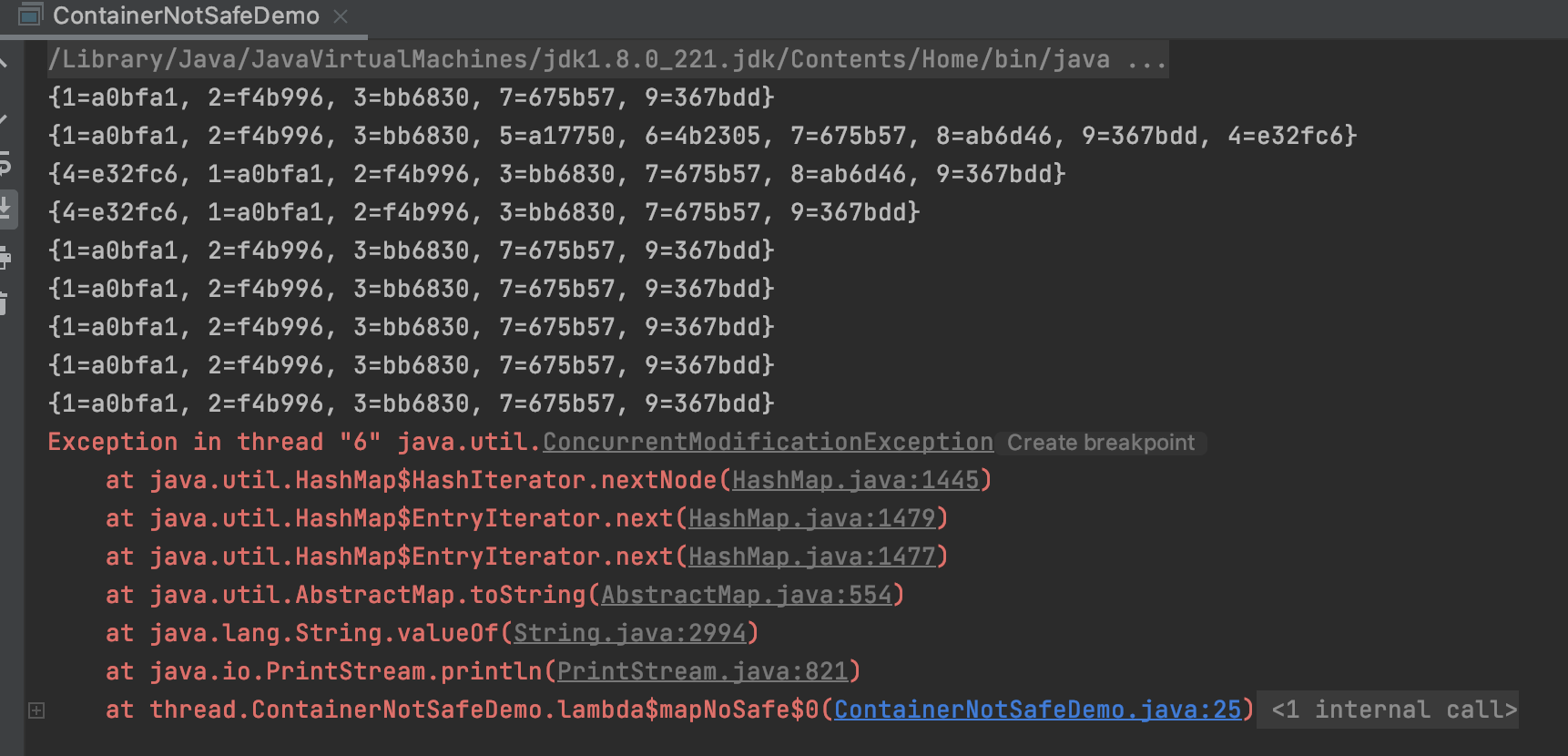
因为多线程环境下,使用 HashMap 进行 put 操作会引起死循环,导致 CPU 利用率接近 100%,所以在并发情况下不能使用 HashMap,如以下代码
/**
* 集合类不安全问题
*/
public class ContainerNotSafeDemo {
public static void main(String[] args) {
//listNoSafe();
//setNoSafe();
mapNoSafe();
}
private static void mapNoSafe() {
Map<String, String> map = new HashMap<>();
//Map<String, String> map = new ConcurrentHashMap<>();
for (int i = 0; i < 10; i++) {
new Thread(()->{
map.put(Thread.currentThread().getName(), UUID.randomUUID().toString().substring(0,6));
System.out.println(map);
}, String.valueOf(i)).start();
}
}
}
HashMap:
效率低下的 HashTable 容器
HashTable 容器使用 syncronized 来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率非常低下。因为当一个线程访问 HashTable 的同步方法时,其他线程访问 HashTable 的同步方法时,可能会进入阻塞或轮询状态。如线程 1 使用 put 进行添加元素,线程 2 不但不能使用 put 方法添加元素,并且也不能使用 get 方法来获取元素,所以竞争越激烈效率越低。
1.2 ConcurrentHashMap jdk1.7 和 jdk1.8 的区别
ConcurrentHashMap 在 jdk1.7 和 jdk1.8 是有区别的。
-
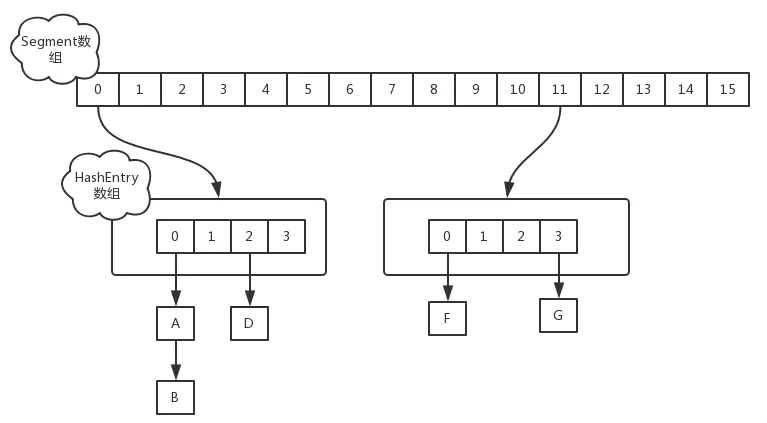
jdk 1.7 :Segment,段的概念,一个段包含多个HashEntry,实行分段加锁
-
jdk 1.8:put操作的锁粒度更细化,并且扩容的时候效率更高。
-
去掉了Segment这种数据结构,只用一个元素类型为HashEntry的数组,只对元素HashEntry(首节点)加锁
-
使用内置锁synchronized来代替重入锁ReentrantLock(synchronized会根据锁的争用情况进行膨胀,相比ReentrantLock性能会提高不少,并且基于API的ReentrantLock会开销更多的内存)
总结:锁粒度演变:无锁 hashMap -> 表锁 hashTable -> 分段锁 ConcurrentHashMap1.7 -> 行锁(链表锁)ConcurrentHashMap1.8
1.3 源码简析
ConcurrentHashMap底层是用一个元素类型为Node的数组存储元素的,Node有四种实现类型:
- Node(链表结构节点)
- TreeNode、TreeBin(红黑树,包含TreeNode)
- ForwardingNode(正在扩容的节点)
ConcurrentHashMap结构
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable {
...
//节点数超过8 链表转换为红黑树
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2, and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
//节点数低于6 红黑树转为链表
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // hash for forwarding nodes //代表正在扩容迁移的节点
static final int TREEBIN = -2; // hash for roots of trees //重点关注这个,节点的hash值为-2说明是红黑树的根节点
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
//我们需要关注的节点类型
static class Node<K,V> implements Map.Entry<K,V> {
...}
static final class ForwardingNode<K,V> extends Node<K,V> {
...}
static final class TreeBin<K,V> extends Node<K,V> {
...}
static final class TreeNode<K,V> extends Node<K,V> {
...}
//这个就是存储元素的数组
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
//扩容迁移时候用
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node<K,V>[] nextTable;
...
}
插入逻辑
//数据插入逻辑:
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p>The value can be retrieved by calling the {@code get} method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
//for循环,通过自旋方式进行数据的插入
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) //第一种情况table空的,则进行初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//第二种情况,通过hash取模计算索引从table数组上获取节点,发现为空
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))//通过CAS添加第一个节点
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//第三种情况,发现当前table正在扩容,则让当前线程参与扩容,数据迁移
tab = helpTransfer(tab, f);
else {
//最后一种情况,table[i]上已经有节点了,出现hash冲突,此时有两种情况,有可能是链表,也有可能是红黑树
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
//fh为table[i]节点的hash值,如果大于0说明是链表
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
//小于0有可能是红黑树,所以还需要在确认一下
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
查找逻辑
//数据查找逻辑:
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());//计算key的hash值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//判断table是否初始化了,table[i]上是否有节点
if ((eh = e.hash) == h) {
//判断hash值是否相同
if ((ek = e.key) == key || (ek != null && key.equals(ek)))//继续判断key是否相同
return e.val;
}
else if (eh < 0) //小于0有可能是红黑树,也有可能是正在迁移的节点,特殊节点查找下一个节点的方式
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
//链表查找下一个节点的方式
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
扩容逻辑
//扩容方法
/**
* Tries to presize table to accommodate the given number of elements.
*
* @param size number of elements (doesn't need to be perfectly accurate)
*/
private final void tryPresize(int size) {
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);//map的容量永远都是2的次方
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
if (tab == null || (n = tab.length) == 0) {
//第一种情况,table还没初始化
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)//当前容量已经达到最大容量
break;
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) {
//这里sc < 0 说明有其他线程正在进行扩容
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)//判断是否能帮助扩容,不能就退出
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);//参与扩容
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);//当前没有线程在扩容,则自己扩容
}
}
}
更多详细源码解读可以参考:
ConcurrentHashMap实现原理及源码分析关于transfer实现逻辑可以参考:
深入分析ConcurrentHashMap1.8的扩容实现
1.4 案例演示
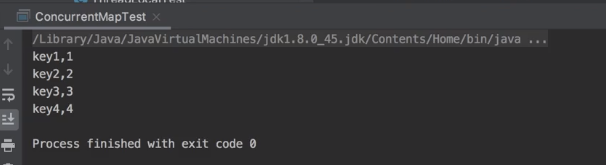
public class ConcurrentHashMapTest {
public static void main(String[] args) {
Map<String, String> map = new ConcurrentHashMap<String, String>();
map.put("key1", "1");
map.put("key2", "2");
map.put("key3", "3");
map.put("key4", "4");
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
System.out.println(key + ","+ map.get(key));
}
}
}
二、ConcurrentSkipListMap
2.1 API介绍
JDK1.6时,为了对高并发环境下的有序Map提供更好的支持,J.U.C新增了一个ConcurrentNavigableMap接口,ConcurrentNavigableMap很简单,它同时实现了NavigableMap和ConcurrentMap接口。
ConcurrentNavigableMap接口提供的功能也和NavigableMap几乎完全一致,很多方法仅仅是返回的类型不同。
NavigableMap接口,进一步扩展了SortedMap的功能,提供了根据指定Key返回最接近项、按升序/降序返回所有键的视图等功能。
J.U.C提供了基于ConcurrentNavigableMap接口的一个实现—— ConcurrentSkipListMap 。ConcurrentSkipListMap可以看成是并发版本的TreeMap,但是和TreeMap不同是,ConcurrentSkipListMap并不是基于红黑树实现的,其底层是一种类似跳表(Skip List)的结构。
ConcurrentSkipListMap
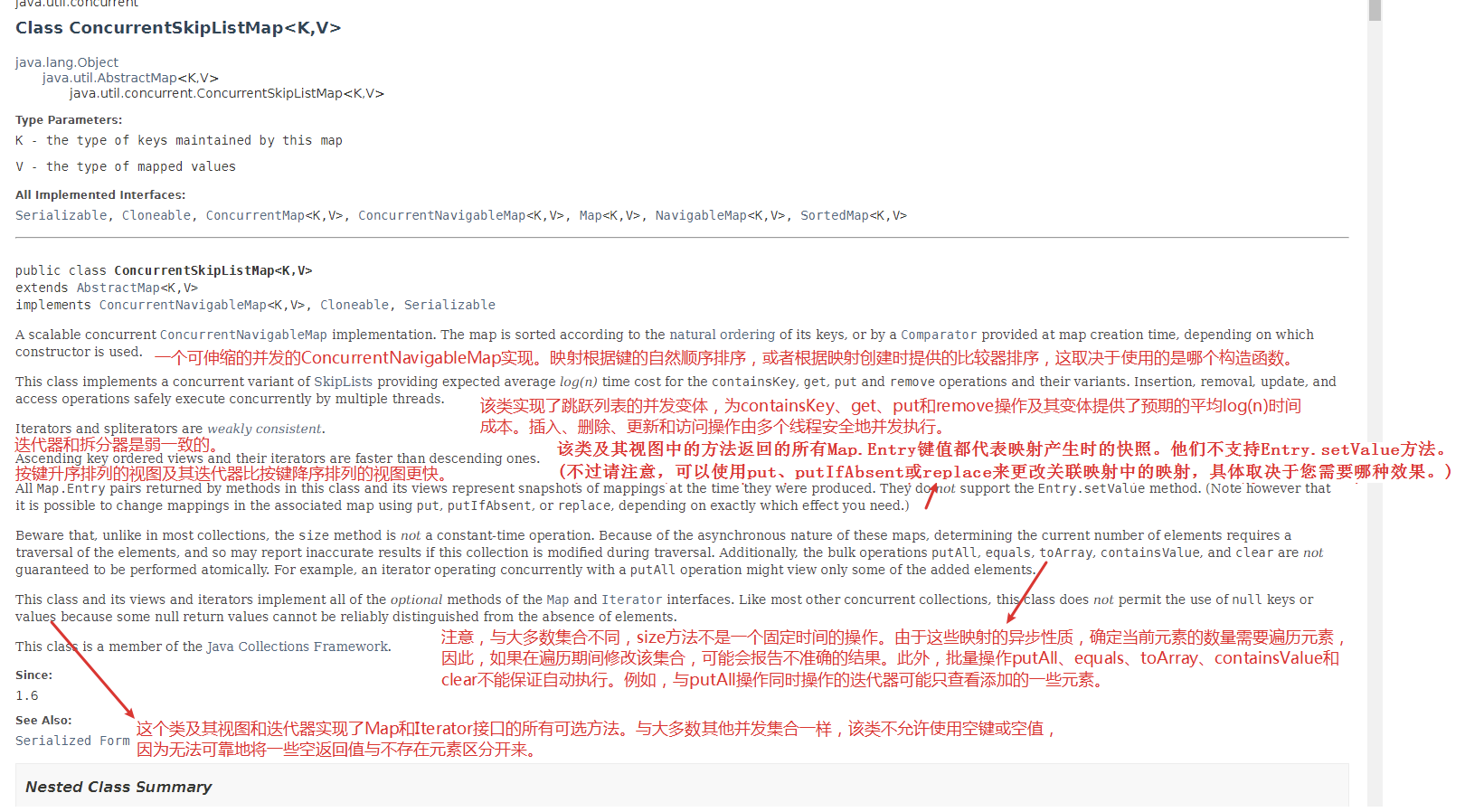
ConcurrentNavigableMap
ConcurrentSkipListMap 继承自 ConcurrentNavigableMap
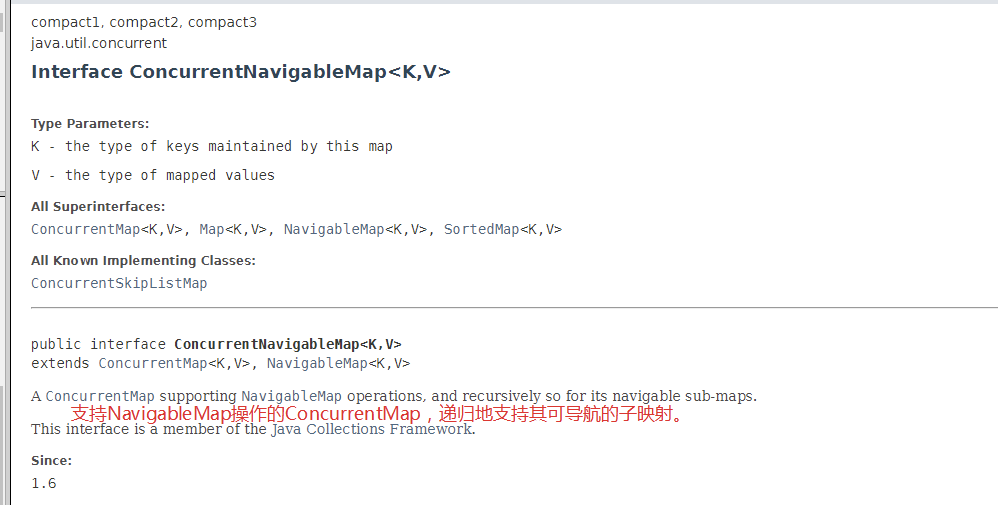
NavigableMap
ConcurrentNavigableMap 继承自 NavigableMap:
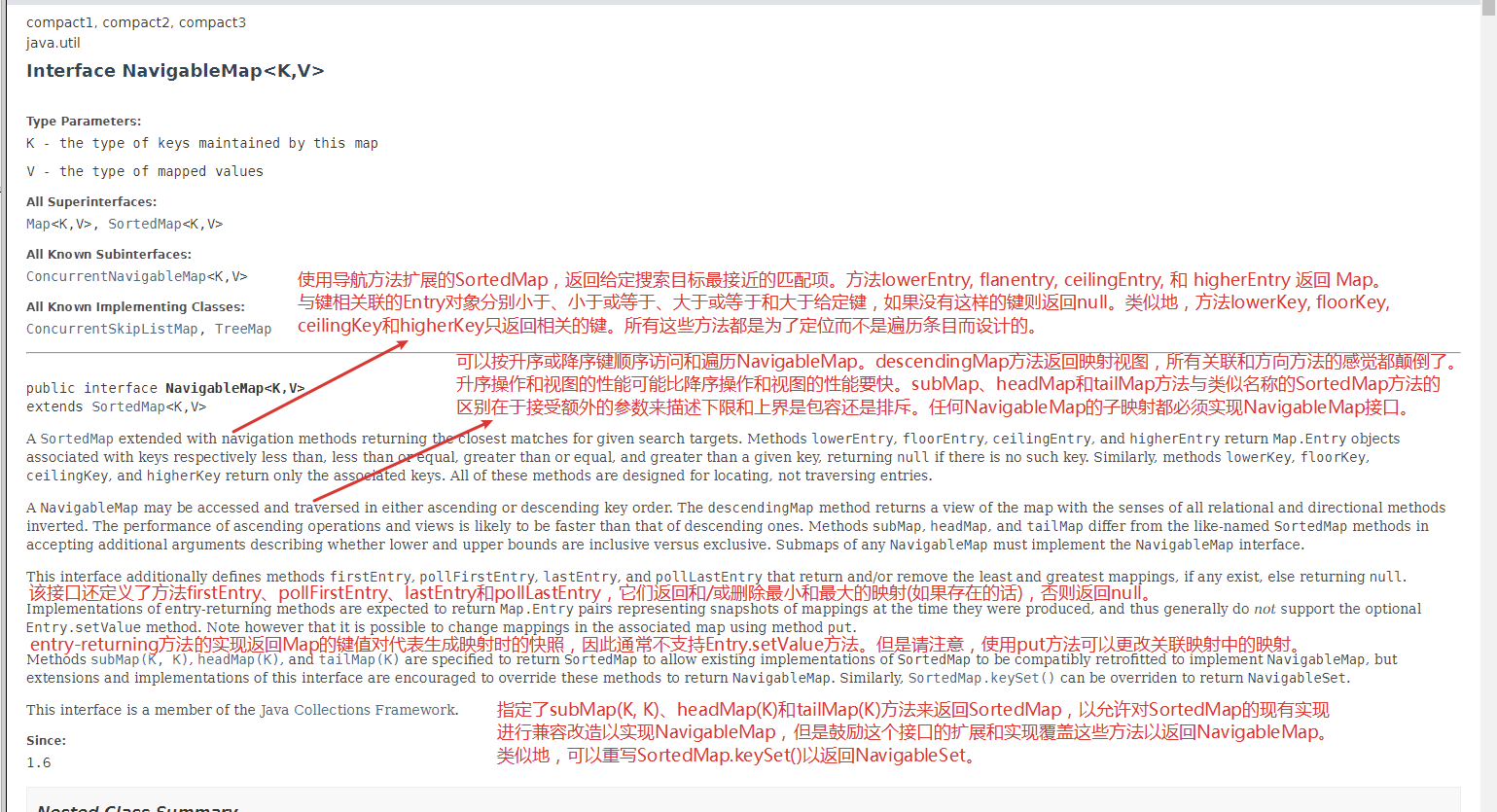
SortedMap
NavigableMap 继承自 SortedMap:
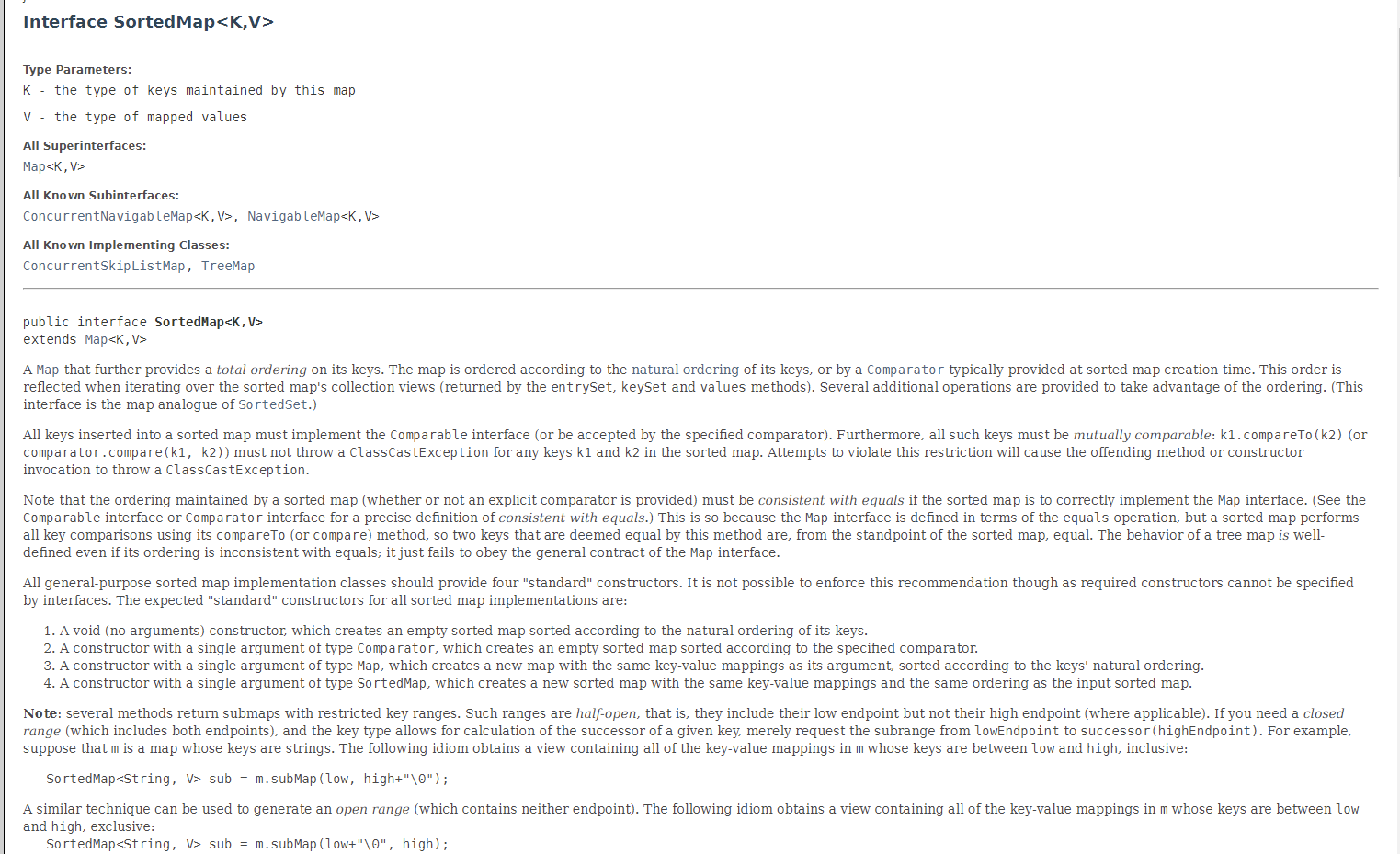
翻译:
进一步提供键的总体排序的映射。映射是根据键的自然顺序排列的,或者通过在sorted map创建时提供的比较器。当迭代排序映射的集合视图(由entrySet、keySet和values方法返回)时,就会反映出这个顺序。提供了几个额外的操作来利用排序。(该接口是SortedSet的映射模拟。)所有插入到sorted map中的键必须实现Comparable接口(或者被指定的比较器接受)。此外,所有这样的键必须是相互可比的:k1. comparator (k2)(或comparator.compare(k1, k2))方法绝不能为 sorted map 中的任何键k1和k2抛出ClassCastException。试图违反此限制将导致违规的方法或构造函数调用抛出ClassCastException。
注意,如果要正确实现map接口,sorted map(无论是否提供显式比较器)所维护的排序必须与equals一致。(有关与equals一致的精确定义,请参阅 Comparable 接口或 Comparator 接口。)之所以如此,是因为Map接口是根据等号操作定义的,但 sorted map 使用其comparareto(或compare)方法执行所有键比较,因此,从sorted map的角度来看,这个方法认为相等的两个键是相等的。tree map的行为是定义良好的,即使它的顺序与等号不一致;它只是没有遵守Map 接口的一般约定。
所有通用的 sorted map实现类都应该提供四个“标准”构造函数。由于接口不能指定所需的构造函数,因此不可能强制执行此建议。所有sorted map实现的预期“标准”构造函数是:
- void(无参数)构造函数,它创建一个根据键的自然顺序排序的空排序映射。
- 具有一个Comparator类型参数的构造函数,它创建一个根据指定的比较器排序的空排序映射。
- 具有单个Map类型参数的构造函数,该构造函数使用与其参数相同的键-值映射创建新映射,并根据键的自然顺序排序。
- 具有SortedMap类型的单个参数的构造函数,它创建一个新的排序映射,该映射具有与输入排序映射相同的键值映射和顺序。
注意:一些方法返回具有限制键范围的子映射(subMap、tailMap)。这些范围是半开放的,也就是说,它们包括它们的低终点,但不包括它们的高终点(如适用)。如果您需要一个封闭的范围(包括两个端点),并且键类型允许计算给定键的后继键,只需请求从lowEndpoint到继承者(highEndpoint)的子范围。例如,假设m是一个映射,它的键是字符串。下面的习语获得一个视图,该视图包含m中键值介于low和high之间的所有键值映射,包括(包含两端):
SortedMap<String, V> sub = m.subMap(low, high+"\0");
可以使用类似的技术生成开放范围(不包含端点)。下面的习语可以获得一个视图,该视图包含m中所有键值介于低和高之间的键值映射,且不包含(不包含两端):
SortedMap<String, V> sub = m.subMap(low+"\0", high);
总结
-
SortedMap:有序的map,根据key排序,可以返回map中key最大firstKey()或者最小lastKey()的键值对,或者返回一段范围的键值对。
-
NavigableMap:对SortedMap进一步扩展,提供了owerEntry, floorEntry, ceilingEntry, higherEntry 等方法
-
ceilingEntry:返回与大于或等于给定键的最小键相关联的键值映射,如果不存在这样的键,则返回null。
-
ceilingKey:返回大于或等于给定键的最小键,如果不存在这样的键,则返回null。
-
floorEntry / floorKey:返回与小于或等于给定键的最大键相关联的键值映射,如果不存在这样的键,则返回null。
-
…
由此可见ConcurrentSkipListMap具有Map、ConcurrentMap、SortedMap、NavigableMap的基因
2.2 源码简析
ConcurrentSkipListMap底层是基于跳表结构
- 数组的优势是查找快,增删慢,复杂度是O(n)
- 链表的优势是查找慢,增删快
- SkipList,让查找、增删,三种操作的复杂度都是O(logn)
2.3 案例演示
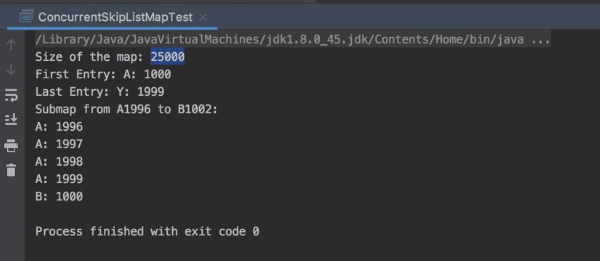
public class ConcurrentSkipListMapTest {
public static void main(String[] args) {
ConcurrentSkipListMap<String, Contact> map = new ConcurrentSkipListMap<>();
Thread threads[]=new Thread[25];
int counter=0;
//创建和启动25个任务,对于每个任务指定一个大写字母作为ID
for (char i='A'; i<'Z'; i++) {
Task0 task = new Task0(map, String.valueOf(i));
threads[counter]=new Thread(task);
threads[counter].start();
counter++;
}
//使用join()方法等待线程的结束
for (int i=0; i<25; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.printf("Size of the map: %d\n",map.size());
Map.Entry<String, Contact> element;
Contact contact;
// 使用firstEntry()方法获取map的第一个实体,并输出。
element=map.firstEntry();
contact=element.getValue();
System.out.printf("First Entry: %s: %s\n",contact.getName(),contact.getPhone());
//使用lastEntry()方法获取map的最后一个实体,并输出。
element=map.lastEntry();
contact=element.getValue();
System.out.printf("Last Entry: %s: %s\n",contact.getName(),contact.getPhone());
//使用subMap()方法获取map的子map,并输出。
System.out.printf("Submap from A1996 to B1002: \n");
ConcurrentNavigableMap<String, Contact> submap=map.subMap("A1996", "B1001");
do {
element=submap.pollFirstEntry();
if (element!=null) {
contact=element.getValue();
System.out.printf("%s: %s\n",contact.getName(),contact.
getPhone());
}
} while (element!=null);
}
}
class Contact {
private String name;
private String phone;
public Contact(String name, String phone) {
this.name = name;
this.phone = phone;
}
public String getName() {
return name;
}
public String getPhone() {
return phone;
}
}
class Task0 implements Runnable {
private ConcurrentSkipListMap<String, Contact> map;
private String id;
public Task0(ConcurrentSkipListMap<String, Contact> map, String id) {
this.id = id;
this.map = map;
}
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
Contact contact = new Contact(id, String.valueOf(i + 1000));
map.put(id + contact.getPhone(), contact);
}
}
}
看到subMap方法默认包左不包右
三、ConcurrentSkipListSet
3.1 API介绍
ConcurrentSkipListSet,是JDK1.6时J.U.C新增的一个集合工具类,它是一种有序的SET类型。
ConcurrentSkipListSet实现了NavigableSet接口,ConcurrentSkipListMap实现了NavigableMap接口,以提供和排序相关的功能,维持元素的有序性,所以ConcurrentSkipListSet就是一种为并发环境设计的有序SET工具类。
ConcurrentSkipListSet底层实现引用了ConcurrentSkipListMap。
有序不重复
3.2 源码简析
public class ConcurrentSkipListSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable {
...
/**
* Constructs a new, empty set that orders its elements according to
* their {@linkplain Comparable natural ordering}.
*/
public ConcurrentSkipListSet() {
m = new ConcurrentSkipListMap<E,Object>();
}
//看到底层就是利用ConcurrentSkipListMap的key
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element {@code e} to this set if
* the set contains no element {@code e2} such that {@code e.equals(e2)}.
* If this set already contains the element, the call leaves the set
* unchanged and returns {@code false}.
*
* @param e element to be added to this set
* @return {@code true} if this set did not already contain the
* specified element
* @throws ClassCastException if {@code e} cannot be compared
* with the elements currently in this set
* @throws NullPointerException if the specified element is null
*/
public boolean add(E e) {
return m.putIfAbsent(e, Boolean.TRUE) == null;
}
...
}
3.3 案例演示
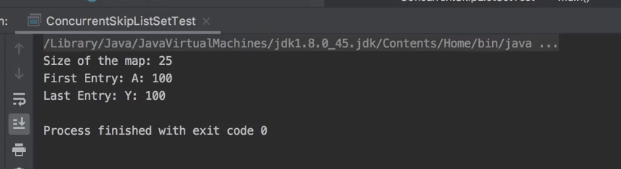
public class ConcurrentSkipListSetTest {
public static void main(String[] args) {
ConcurrentSkipListSet<Contact1> set = new ConcurrentSkipListSet<>();
Thread threads[]=new Thread[25];
int counter=0;
//创建和启动25个任务,对于每个任务指定一个大写字母作为ID
for (char i='A'; i<'Z'; i++) {
Task1 task=new Task1(set, String.valueOf(i));
threads[counter]=new Thread(task);
threads[counter].start();
counter++;
}
//使用join()方法等待线程的结束
for (int i=0; i<25; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.printf("Size of the set: %d\n",set.size());
Contact1 contact;
// 使用first方法获取set的第一个实体,并输出。
contact=set.first();
System.out.printf("First Entry: %s: %s\n",contact.getName(),contact.getPhone());
//使用last方法获取set的最后一个实体,并输出。
contact=set.last();
System.out.printf("Last Entry: %s: %s\n",contact.getName(),contact.getPhone());
}
}
class Contact1 implements Comparable<Contact1> {
private String name;
private String phone;
public Contact1(String name, String phone) {
this.name = name;
this.phone = phone;
}
public String getName() {
return name;
}
public String getPhone() {
return phone;
}
@Override
public int compareTo(Contact1 o) {
//自然排序,只根据name比较
return name.compareTo(o.name);
}
}
class Task1 implements Runnable {
private ConcurrentSkipListSet<Contact1> set;
private String id;
public Task1(ConcurrentSkipListSet<Contact1> set, String id) {
this.id = id;
this.set = set;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
Contact1 contact = new Contact1(id, String.valueOf(i + 100));
set.add(contact);
}
}
}
看到只根据name比较,所以只会有25个元素