作为分布式系统,尤其是对延迟敏感的实时计算引擎,Apache Flink 需要有强大的容错机制,以确保在出现机器故障或网络分区等不可预知的问题时可以快速自动恢复并依旧能产生准确的计算结果。事实上,Flink 有一套先进的快照机制来持久化作业状态[1],确保中间数据不会丢失,这通常需要和错误恢复机制(作业重启策略或 failover 策略)配合使用。在遇到错误时,Flink 作业会根据重启策略自动重启并从最近一个成功的快照(checkpoint)恢复状态。合适的重启策略可以减少作业不可用时间和避免人工介入处理故障的运维成本,因此对于 Flink 作业稳定性来说有着举足轻重的作用。下文就将详细解读 Flink 的错误恢复机制。
Flink 容错机制主要有作业执行的容错以及守护进程的容错两方面,前者包括 Flink runtime 的 ExecutionGraph 和 Execution 的容错,后者则包括 JobManager 和 TaskManager 的容错。
作业执行容错
众所周知,用户使用 Flink 编程 API(DataStream/DataSet/Table/SQL)编写的作业最终会被翻译为 JobGraph 对象再提交给 JobManager 去执行,而后者会将 JobGraph 结合其他配置生成具体的 Task 调度到 TaskManager 上执行。
相信不少读者应该见过来自官网文档的这张架构图(图1),它清晰地描绘了作业的分布式执行机制: 一个作业有多个 Operator,相互没有数据 shuffle 、并行度相同且符合其他优化条件的相邻 Operator 可以合并成 OperatorChain,然后每个 Operator 或者 OperatorChain 称为一个 JobVertex;在分布式执行时,每个 JobVertex 会作为一个 Task,每个 Task 有其并行度数目的 SubTask,而这些 SubTask 则是作业调度的最小逻辑单元。
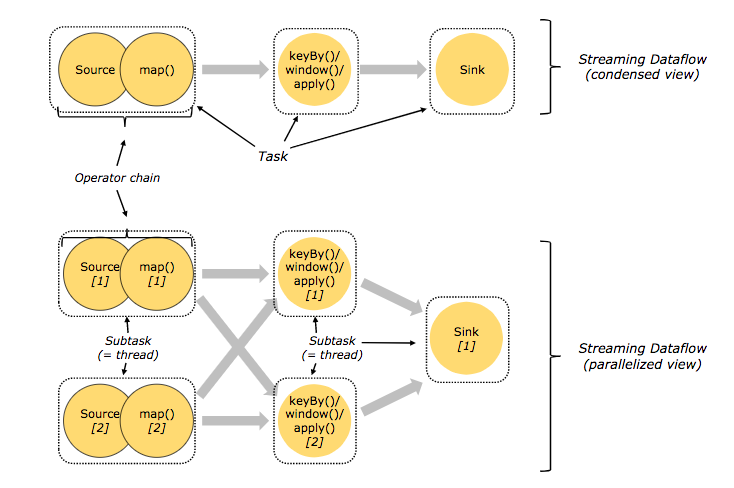
图1.作业的分布式执行
该图主要从 TaskManager 角度出发,而其实在 JobManager 端也存在一个核心的数据结构来映射作业的分布式执行,即 ExecutionGraph。ExecutionGraph 类似于图中并行视角的 Streaming Dataflow,它代表了 Job 的一次执行。从某种意义上讲,如果 JobGraph 是一个类的话,ExecutionGraph 则是它的一个实例。ExecutionGraph 中包含的节点称为 ExecutionJobVertex,对应 JobGrap 的一个 JobVertex 或者说图中的一个 Task。ExecutionJobVertex 可以有多个并行实例,即 ExecutionVertex,对应图中的一个 SubTask。在一个 ExecutionGraph 的生命周期中,一个 ExecutionVertex 可以被执行(重启)多次,每次则称为一个 Execution。小结一下,ExecutionGraph 对应 Flink Job 的一次执行,Execution 对应 SubTask 的一次执行。
相对地,Flink 的错误恢复机制分为多个级别,即 Execution 级别的 Failover 策略和 ExecutionGraph 级别的 Job Restart 策略。当出现错误时,Flink 会先尝试触发范围小的错误恢复机制,如果仍处理不了才会升级为更大范围的错误恢复机制,具体可以用下面的序列图来表达(其中省略了Exection 和 ExecutionGraph 的非关键状态转换)。
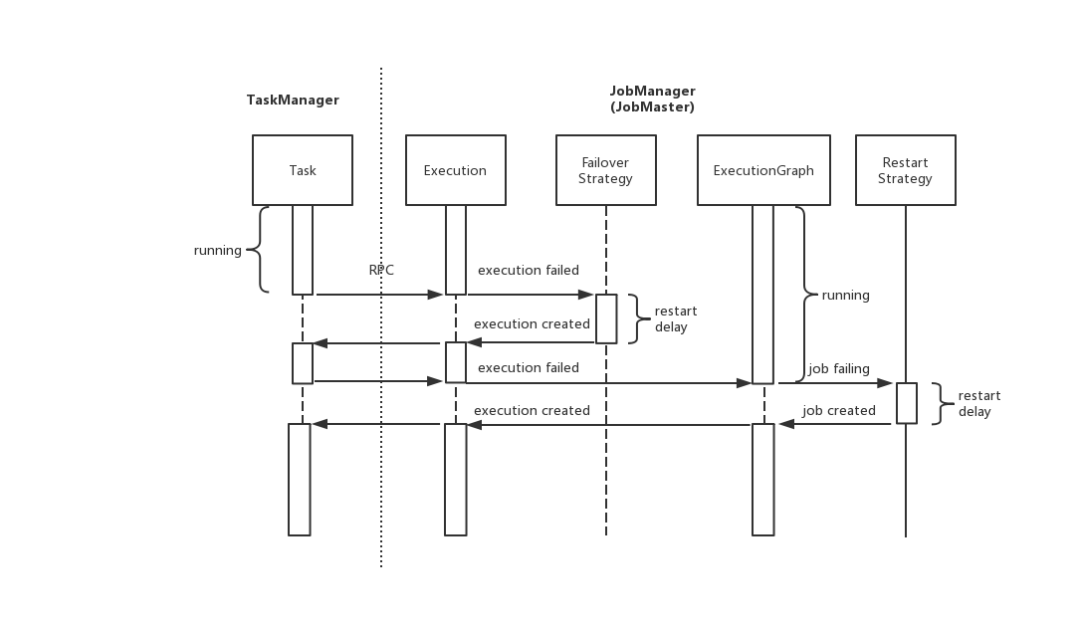
图2.作业执行容错
当Task 发生错误,TaskManager 会通过 RPC 通知 JobManager,后者将对应 Execution 的状态转为 failed 并触发 Failover 策略。如果符合 Failover 策略,JobManager 会重启 Execution,否则升级为 ExecutionGraph 的失败。ExecutionGraph 失败则进入 failing 的状态,由 Restart 策略决定其重启(restarting 状态)还是异常退出(failed 状态)。
下面分别分析两个错误恢复策略的场景及实现。
Task Failover 策略
作为计算的最小执行单位,Task 错误是十分常见的,比如机器故障、用户代码抛出错误或者网络故障等等都可能造成 Task 错误。对于分布式系统来说,通常单个 Task 错误的处理方式是将这个 Task 重新调度至新的 worker 上,不影响其他 Task 和整体 Job 的运行,然而这个方式对于流处理的 Flink 来说并不可用。
Flink 的容错机制主要分为从 checkpoint 恢复状态和重流数据两步,这也是为什么 Flink 通常要求数据源的数据是可以重复读取的。对于重启后的新 Task 来说,它可以通过读取 checkpoint 很容易地恢复状态信息,但是却不能独立地重流数据,因为 checkpoint 是不包含数据的,要重流数据只可以要求依赖到的全部上游 Task 重新计算,通常来说会一直追溯到数据源 Task。熟悉 Spark 的同学大概会联想到 Spark 的血缘机制。简单来说,Spark 依据是否需要 shuffle 将作业分划为多个 Stage,每个 Stage 的计算都是独立的 Task,其结果可以被缓存起来。如果某个 Task 执行失败,那么它只要重读上个 Stage 的计算缓存结果即可,不影响其他 Task 的计算。Spark 可以独立地恢复一个 Task,很大程度上是因为它的批处理特性,这允许了作业通过缓存中间计算结果来解耦上下游 Task 的联系。而 Flink 作为流计算引擎,显然是无法简单做到这点的。
要做到细粒度的错误恢复机制,减小单个 Task 错误对于整体作业的影响,Flink 需要实现一套更加复杂的算法,也就是 FLIP-1 [2] 引入的 Task Failover 策略。Task Failover 策略目前有三个,分别是
RestartAll、RestartIndividualStrategy 和 RestartPipelinedRegionStrategy。
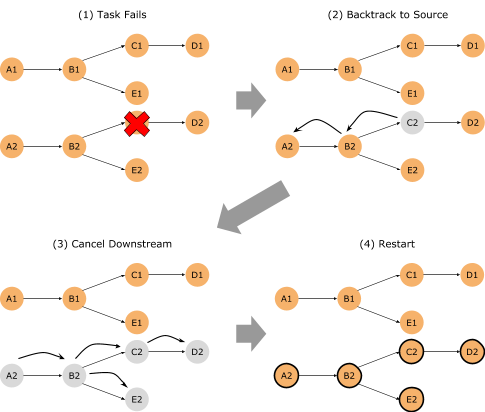
图3.Restart Region 策略重启有数据交换的 Task
- RestartAll: 重启全部 Task,是恢复作业一致性的最安全策略,会在其他 Failover 策略失败时作为保底策略使用。
目前是默认的 Task Failover 策略。
- RestartPipelinedRegionStrategy: 重启错误 Task 所在 Region 的全部 Task。
Task Region 是由 Task 的数据传输决定的,有数据传输的 Task 会被放在同一个 Region,而不同 Region 之间没有数据交换。
- RestartIndividualStrategy: 恢复单个 Task。
因为如果该 Task 没有包含数据源,这会导致它不能重流数据而导致一部分数据丢失。
考虑到至少提供准确一次的投递语义,这个策略的使用范围比较有限,只应用于 Task 间没有数据传输的作业。
不过也有部分业务场景可能需要这种 at-most-once 的投递语义,比如对延迟敏感而对数据一致性要求相对低的推荐系统。
总体来说,RestartAll 较为保守会造成资源浪费,而 RestartIndividualStrategy 则太过激进不能保证数据一致性,而 RestartPipelinedRegionStrategy 重启的是所有 Task 里最小必要子集,其实是最好的 Failover 策略。而实际上 Apache 社区也正准备在 1.9 版本将其设为默认的 Failover 策略[3]。不过值得注意的是,在 1.9 版本以前 RestartPipelinedRegionStrategy 有个严重的问题是在重启 Task 时并不会恢复其状态[4],所以请在 1.9 版本以后才使用它,除非你在跑一个无状态的作业。
Job Restart 策略
如果Task 错误最终触发了 Full Restart,此时 Job Restart 策略将会控制是否需要恢复作业。Flink 提供三种 Job 具体的 Restart Strategy。
- FixedDelayRestartStrategy: 允许指定次数内的 Execution 失败,如果超过该次数则导致 Job 失败。
FixedDelayRestartStrategy 重启可以设置一定的延迟,以减少频繁重试对外部系统带来的负载和不必要的错误日志。
目前 FixedDelayRestartStrategy 是默认的 Restart Strategy。
- FailureRateRestartStrategy: 允许在指定时间窗口内的指定次数内的 Execution 失败,如果超过这个频率则导致 Job 失败。
同样地,FailureRateRestartStrategy 也可以设置一定的重启延迟。
- NoRestartStrategy: 在 Execution 失败时直接让 Job 失败。
目前的Restart Strategy 可以基本满足“自动重启挂掉的作业”这样的简单需求,然而并没有区分作业出错的原因,这导致可能会对不可恢复的错误(比如用户代码抛出的 NPE 或者某些操作报 Permission Denied)进行不必要的重试,进一步的后果是没有第一时间退出,可能导致用户没有及时发现问题,其外对于资源来说也是一种浪费,最后还可能导致一些副作用(比如有些 at-leaset-once 的操作被执行多次)。
对此,社区在 1.7 版本引入了 Exception 的分类[5],具体会将 Runtime 抛出的 Exception 分为以下几类:
- NonRecoverableError: 不可恢复的错误。
不对此类错误进行重试。
- PartitionDataMissingError: 当前 Task 读不到上游 Task 的某些数据,需要上游 Task 重跑和重发数据。
- EnvironmentError: 执行环境的错误,通常是 Flink 以外的问题,比如机器问题、依赖问题。
这种错误的一个明显特征是会在某些机器上执行成功,但在另外一些机器上执行失败。
Flink 后续可以引入黑名单机器来更聪明地进行 Task 调度以暂时避免这类问题的影响。
- RecoverableError: 可恢复错误。
不属于上述类型的错误都暂设为可恢复的。
其实这个分类会应用于 Task Failover 策略和 Job Restart 策略,不过目前只有后者会分类处理,而且 Job Restart 策略对 Flink 作业的稳定性影响显然更大,因此放在这个地方讲。值得注意的是,截至目前(1.8 版本)这个分类只处于很初级的阶段,像 NonRecoverable 只包含了作业 State 命名冲突等少数几个内部错误,而 PartitionDataMissingError 和 EnvironmentError 还未有应用,所以绝大多数的错误仍是 RecoverableError。
守护进程容错
对于分布式系统来说,守护进程的容错是基本要求而且已经比较成熟,基本包括故障检测和故障恢复两个部分:故障检测通常通过心跳的方式来实现,心跳可以在内部组件间实现或者依赖于 zookeeper 等外部服务;而故障恢复则通常要求将状态持久化到外部存储,然后在故障出现时用于初始化新的进程。
以最为常用的 on YARN 的部署模式来讲,Flink 关键的守护进程有 JobManager 和 TaskManager 两个,其中 JobManager 的主要职责协调资源和管理作业的执行分别为 ResourceManager 和 JobMaster 两个守护线程承担,三者之间的关系如下图所示。
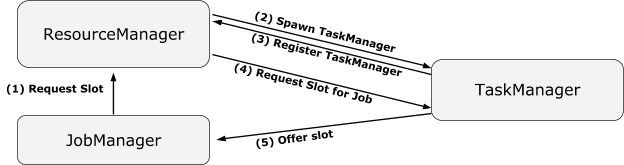
图4.ResourceManager、JobMaster 和 TaskManager 三者关系
在容错方面,三个角色两两之间相互发送心跳来进行共同的故障检测[7]。此外在 HA 场景下,ResourceManager 和 JobMaster 都会注册到 zookeeper 节点上以实现 leader 锁。
TaskManager 的容错
如果ResouceManager 通过心跳超时检测到或者通过集群管理器的通知了解到 TaskManager 故障,它会通知对应的 JobMaster 并启动一个新的 TaskManager 以做代替。注意 ResouceManager 并不关心 Flink 作业的情况,这是 JobMaster 的职责去管理 Flink 作业要做何种反应。
如果JobMaster 通过 ResouceManager 的通知了解到或者通过心跳超时检测到 TaskManager 故障,它首先会从自己的 slot pool 中移除该 TaskManager,并将该 TaskManager 上运行的所有 Tasks 标记为失败,从而触发 Flink 作业执行的容错机制以恢复作业。
TaskManager 的状态已经写入 checkpoint 并会在重启后自动恢复,因此不会造成数据不一致的问题。
ResourceManager 的容错
如果TaskManager 通过心跳超时检测到 ResourceManager 故障,或者收到 zookeeper 的关于 ResourceManager 失去 leadership 通知,TaskManager 会寻找新的 leader ResourceManager 并将自己重启注册到其上,期间并不会中断 Task 的执行。
如果JobMaster 通过心跳超时检测到 ResourceManager 故障,或者收到 zookeeper 的关于 ResourceManager 失去 leadership 通知,JobMaster 同样会等待新的 ResourceManager 变成 leader,然后重新请求所有的 TaskManager。考虑到 TaskManager 也可能成功恢复,这样的话 JobMaster 新请求的 TaskManager 会在空闲一段时间后被释放。
ResourceManager 上保持了很多状态信息,包括活跃的 container、可用的 TaskManager、TaskManager 和 JobMaster 的映射关系等等信息,不过这些信息并不是 ground truth,可以从与 JobMaster 及 TaskManager 的状态同步中再重新获得,所以这些信息并不需要持久化。
JobMaster 的容错
如果TaskManager 通过心跳超时检测到 JobMaster 故障,或者收到 zookeeper 的关于 JobMaster 失去 leadership 通知,TaskManager 会触发自己的错误恢复(目前是释放所有 Task),然后等待新的 JobMaster。如果新的 JobMaster 在一定时间后仍未出现,TaskManager 会将其 slot 标记为空闲并告知 ResourceManager。
如果ResourceManager 通过心跳超时检测到 JobMaster 故障,或者收到 zookeeper 的关于 JobMaster 失去 leadership 通知,ResourceManager 会将其告知 TaskManager,其他不作处理。
JobMaster 保存了很多对作业执行至关重要的状态,其中 JobGraph 和用户代码会重新从 HDFS 等持久化存储中获取,checkpoint 信息会从 zookeeper 获得,Task 的执行信息可以不恢复因为整个作业会重新调度,而持有的 slot 则从 ResourceManager 的 TaskManager 的同步信息中恢复。
并发故障
在on YARN 部署模式下,因为 JobMaster 和 ResourceManager 都在 JobManager 进程内,如果 JobManager 进程出问题,通常是 JobMaster 和 ResourceManager 并发故障,那么 TaskManager 会按以下步骤处理:
1、 按照普通的JobMaster故障处理;
2、 在一段时间内不断尝试将slot提供给新的JobMaster;
3、 不断尝试将自己注册到ResourceManager上;
值得注意的是,新 JobManager 的拉起是依靠 YARN 的 Application attempt 重试机制来自动完成的,而根据 Flink 配置的 YARN Application keep-containers-across-application-attempts 行为,TaskManager 不会被清理,因此可以重新注册到新启动的 Flink ResourceManager 和 JobMaster 中。
Flink 容错机制确保了 Flink 的可靠性和持久性,是 Flink 应用于企业级生产环境的重要保证,具体来说它包括作业执行的容错和守护进程的容错两个方面。在作业执行容错方面,Flink 提供 Task 级别的 Failover 策略和 Job 级别的 Restart 策略来进行故障情况下的自动重试。在守护进程的容错方面,在on YARN 模式下,Flink 通过内部组件的心跳和 YARN 的监控进行故障检测。TaskManager 的故障会通过申请新的 TaskManager 并重启 Task 或 Job 来恢复,JobManager 的故障会通过集群管理器的自动拉起新 JobManager 和 TaskManager 的重新注册到新 leader JobManager 来恢复。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: