在Flink 中,状态可靠性保证由 Checkpoint 支持,当作业出现 failover 的情况下,Flink 会从最近成功的 Checkpoint 恢复。
在实际情况中,我们可能会遇到 Checkpoint 失败,或者 Checkpoint 慢的情况,本文会统一聊一聊 Flink 中 Checkpoint 异常的情况(包括失败和慢),以及可能的原因和排查思路。
1. Checkpoint 流程简介
首先我们需要了解 Flink 中 Checkpoint 的整个流程是怎样的,在了解整个流程之后,我们才能在出问题的时候,更好的进行定位分析。
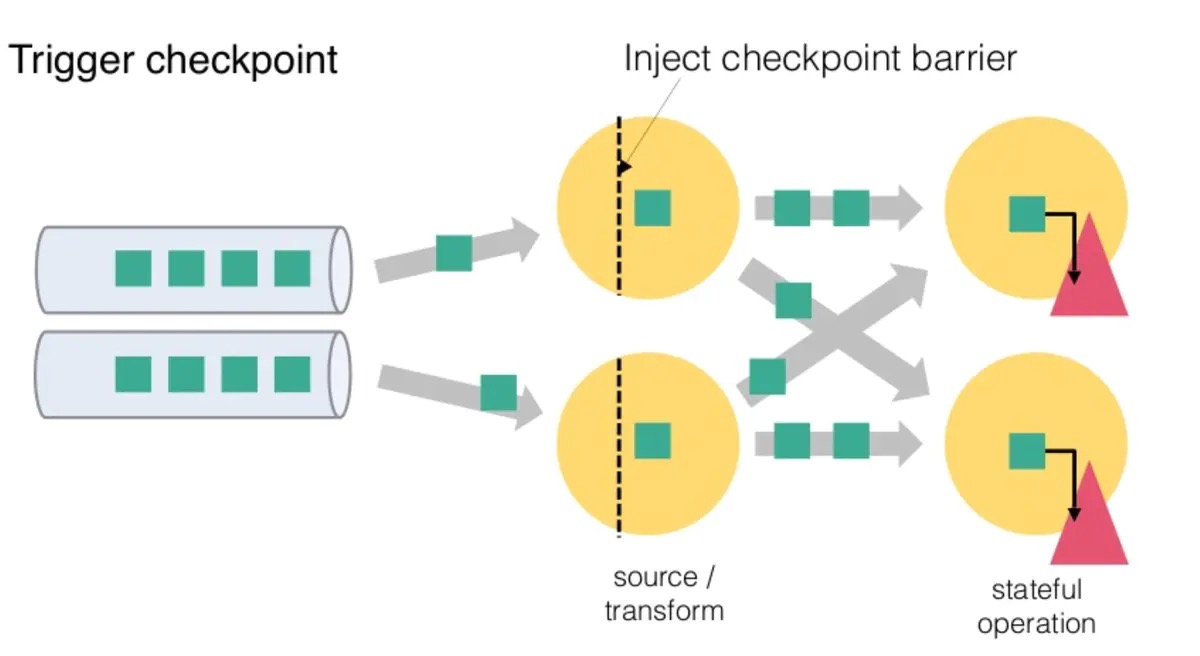 ]
]从上图我们可以知道,Flink 的 Checkpoint 包括如下几个部分:
- JM trigger checkpoint
- Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier
- 下游接收 barrier(需要 barrier 都到齐才会开始做 checkpoint)
- Task 开始同步阶段 snapshot
- Task 开始异步阶段 snapshot
- Task snapshot 完成,汇报给 JM
上面的任何一个步骤不成功,整个 checkpoint 都会失败。
2 Checkpoint 异常情况排查
2、 1Checkpoint失败;
可以在Checkpoint 界面看到如下图所示,下图中 Checkpoint 10423 失败了。
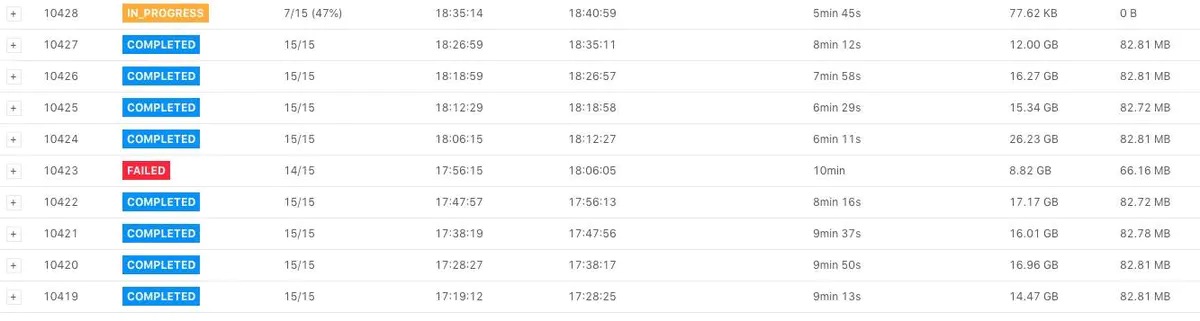 ]
]点击Checkpoint 10423 的详情,我们可以看到类系下图所示的表格(下图中将 operator 名字截取掉了)。
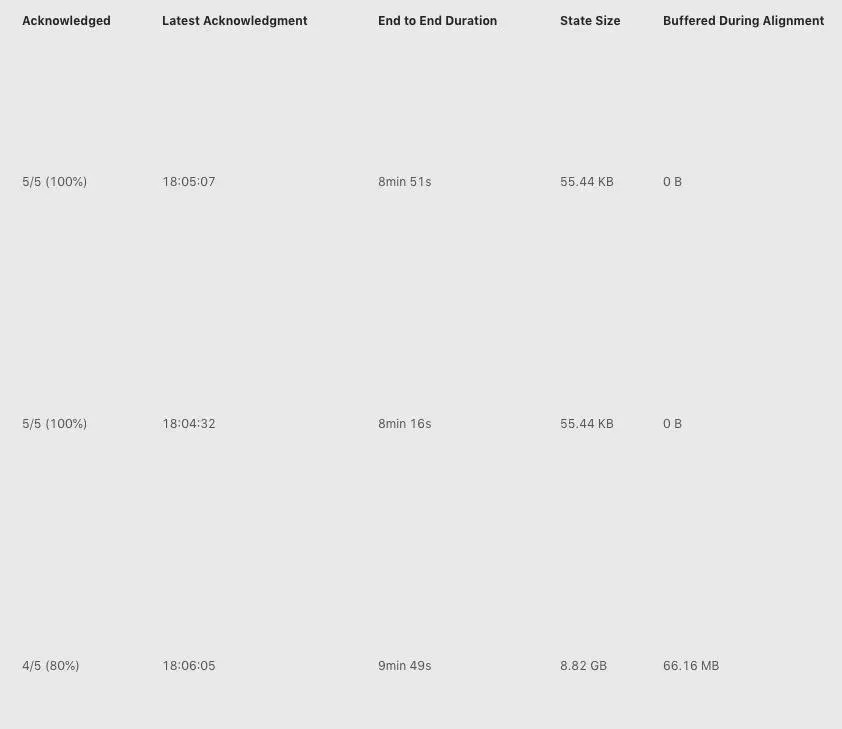 ]
]上图中我们看到三行,表示三个 operator,其中每一列的含义分别如下:
- 其中 Acknowledged 一列表示有多少个 subtask 对这个 Checkpoint 进行了 ack,从图中我们可以知道第三个 operator 总共有 5 个 subtask,但是只有 4 个进行了 ack;
- 第二列 Latest Acknowledgement 表示该 operator 的所有 subtask 最后 ack 的时间;
- End to End Duration 表示整个 operator 的所有 subtask 中完成 snapshot 的最长时间;
- State Size 表示当前 Checkpoint 的 state 大小 – 主要这里如果是增量 checkpoint 的话,则表示增量大小;
- Buffered During Alignment 表示在 barrier 对齐阶段积攒了多少数据,如果这个数据过大也间接表示对齐比较慢);
Checkpoint 失败大致分为两种情况:Checkpoint Decline 和 Checkpoint Expire。
2、 1.1CheckpointDecline;
我们能从 jobmanager.log 中看到类似下面的日志
Decline checkpoint 10423 by task 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178. 其中
10423 是 checkpointID,0b60f08bf8984085b59f8d9bc74ce2e1 是 execution id,85d268e6fbc19411185f7e4868a44178 是 job id,我们可以在 jobmanager.log 中查找 execution id,找到被调度到哪个 taskmanager 上,类似如下所示:
2019-09-02 16:26:20,972 INFO [jobmanager-future-thread-61] org.apache.flink.runtime.executiongraph.ExecutionGraph - XXXXXXXXXXX (100/289) (87b751b1fd90e32af55f02bb2f9a9892) switched from SCHEDULED to DEPLOYING.
2019-09-02 16:26:20,972 INFO [jobmanager-future-thread-61] org.apache.flink.runtime.executiongraph.ExecutionGraph - Deploying XXXXXXXXXXX (100/289) (attempt #0) to slot container_e24_1566836790522_8088_04_013155_1 on hostnameABCDE
另外对于 Checkpoint Decline 的情况,有一种情况我们在这里单独抽取出来进行介绍:Checkpoint Cancel。从上面的日志我们知道该 execution 被调度到 hostnameABCDE 的 container_e24_1566836790522_8088_04_013155_1 slot 上,接下来我们就可以到 container container_e24_1566836790522_8088_04_013155 的 taskmanager.log 中查找 Checkpoint 失败的具体原因了。
当前Flink 中如果较小的 Checkpoint 还没有对齐的情况下,收到了更大的 Checkpoint,则会把较小的 Checkpoint 给取消掉。我们可以看到类似下面的日志:
$taskNameWithSubTaskAndID: Received checkpoint barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint.
这个日志表示,当前 Checkpoint 19 还在对齐阶段,我们收到了 Checkpoint 20 的 barrier。然后会逐级通知到下游的 task checkpoint 19 被取消了,同时也会通知 JM 当前 Checkpoint 被 decline 掉了。
在下游task 收到被 cancelBarrier 的时候,会打印类似如下的日志:
DEBUG
$taskNameWithSubTaskAndID: Checkpoint 19 canceled, aborting alignment.
或者
DEBUG
$taskNameWithSubTaskAndID: Checkpoint 19 canceled, skipping alignment.
或者
WARN
$taskNameWithSubTaskAndID: Received cancellation barrier for checkpoint 20 before completing current checkpoint 19. Skipping current checkpoint.
上面三种日志都表示当前 task 接收到上游发送过来的 barrierCancel 消息,从而取消了对应的 Checkpoint。
2、 1.2CheckpointExpire;
如果Checkpoint 做的非常慢,超过了 timeout 还没有完成,则整个 Checkpoint 也会失败。当一个 Checkpoint 由于超时而失败是,会在 jobmanager.log 中看到如下的日志:
Checkpoint 1 of job 85d268e6fbc19411185f7e4868a44178 expired before completing.
表示Chekpoint 1 由于超时而失败,这个时候可以可以看这个日志后面是否有类似下面的日志:
Received late message for now expired checkpoint attempt 1 from 0b60f08bf8984085b59f8d9bc74ce2e1 of job 85d268e6fbc19411185f7e4868a44178.
可以按照 2.1.1 中的方法找到对应的 taskmanager.log 查看具体信息。
下面的日志如果是 DEBUG 的话,我们会在开始处标记 DEBUG
我们按照下面的日志把 TM 端的 snapshot 分为三个阶段,开始做 snapshot 前,同步阶段,异步阶段:
DEBUG
Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)
这个日志表示 TM 端 barrier 对齐后,准备开始做 Checkpoint。
DEBUG
2019-08-06 13:43:02,613 DEBUG org.apache.flink.runtime.state.AbstractSnapshotStrategy - DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@70442baf, checkpointDirectory=xxxxxxxx, sharedStateDirectory=xxxxxxxx, taskOwnedStateDirectory=xxxxxx, metadataFilePath=xxxxxx, reference=(default), fileStateSizeThreshold=1024}, synchronous part) in thread Thread[Async calls on Source: xxxxxx
_source -> Filter (27/70),5,Flink Task Threads] took 0 ms.
上面的日志表示当前这个 backend 的同步阶段完成,共使用了 0 ms。
DEBUG
DefaultOperatorStateBackend snapshot (FsCheckpointStorageLocation {fileSystem=org.apache.flink.core.fs.SafetyNetWrapperFileSystem@7908affe, checkpointDirectory=xxxxxx, sharedStateDirectory=xxxxx, taskOwnedStateDirectory=xxxxx, metadataFilePath=xxxxxx, reference=(default), fileStateSizeThreshold=1024}, asynchronous part) in thread Thread[pool-48-thread-14,5,Flink Task Threads] took 369 ms
上面的日志表示异步阶段完成,异步阶段使用了 369 ms
在现有的日志情况下,我们通过上面三个日志,定位 snapshot 是开始晚,同步阶段做的慢,还是异步阶段做的慢。然后再按照情况继续进一步排查问题。
2、 2Checkpoint慢;
在2.1 节中,我们介绍了 Checkpoint 失败的排查思路,本节会分情况介绍 Checkpoint 慢的情况。
Checkpoint 慢的情况如下:比如 Checkpoint interval 1 分钟,超时 10 分钟,Checkpoint 经常需要做 9 分钟(我们希望 1 分钟左右就能够做完),而且我们预期 state size 不是非常大。
对于Checkpoint 慢的情况,我们可以按照下面的顺序逐一检查。
2、 2.0SourceTriggerCheckpoint慢;
这个一般发生较少,但是也有可能,因为 source 做 snapshot 并往下游发送 barrier 的时候,需要抢锁(这个现在社区正在进行用 mailBox 的方式替代当前抢锁的方式,详情参考[1])。如果一直抢不到锁的话,则可能导致 Checkpoint 一直得不到机会进行。如果在 Source 所在的 taskmanager.log 中找不到开始做 Checkpoint 的 log,则可以考虑是否属于这种情况,可以通过 jstack 进行进一步确认锁的持有情况。
2、 2.1使用增量Checkpoint;
现在Flink 中 Checkpoint 有两种模式,全量 Checkpoint 和 增量 Checkpoint,其中全量 Checkpoint 会把当前的 state 全部备份一次到持久化存储,而增量 Checkpoint,则只备份上一次 Checkpoint 中不存在的 state,因此增量 Checkpoint 每次上传的内容会相对更好,在速度上会有更大的优势。
现在Flink 中仅在 RocksDBStateBackend 中支持增量 Checkpoint,如果你已经使用 RocksDBStateBackend,可以通过开启增量 Checkpoint 来加速,具体的可以参考 [2]。
2、 2.2作业存在反压或者数据倾斜;
我们知道 task 仅在接受到所有的 barrier 之后才会进行 snapshot,如果作业存在反压,或者有数据倾斜,则会导致全部的 channel 或者某些 channel 的 barrier 发送慢,从而整体影响 Checkpoint 的时间,这两个可以通过如下的页面进行检查:
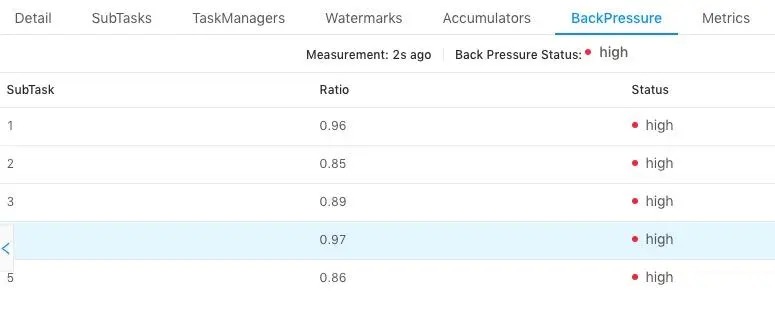 ]
]上图中我们选择了一个 task,查看所有 subtask 的反压情况,发现都是 high,表示反压情况严重,这种情况下会导致下游接收 barrier 比较晚。
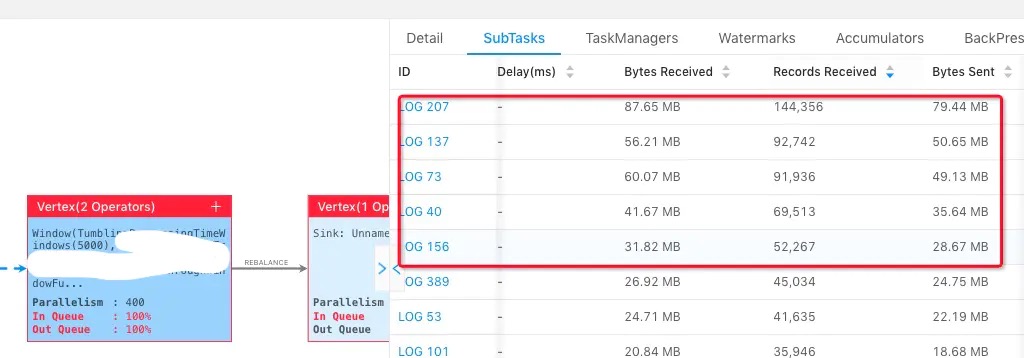 ]
]上图中我们选择其中一个 operator,点击所有的 subtask,然后按照 Records Received/Bytes Received/TPS 从大到小进行排序,能看到前面几个 subtask 会比其他的 subtask 要处理的数据多。
如果存在反压或者数据倾斜的情况,我们需要首先解决反压或者数据倾斜问题之后,再查看 Checkpoint 的时间是否符合预期。
2、 2.2Barrier对齐慢;
从前面我们知道 Checkpoint 在 task 端分为 barrier 对齐(收齐所有上游发送过来的 barrier),然后开始同步阶段,再做异步阶段。如果 barrier 一直对不齐的话,就不会开始做 snapshot。
barrier 对齐之后会有如下日志打印:
DEBUG
Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)
如果taskmanager.log 中没有这个日志,则表示 barrier 一直没有对齐,接下来我们需要了解哪些上游的 barrier 没有发送下来,如果你使用 At Least Once 的话,可以观察下面的日志:
DEBUG
Received barrier for checkpoint 96508 from channel 5
表示该task 收到了 channel 5 来的 barrier,然后看对应 Checkpoint,再查看还剩哪些上游的 barrier 没有接受到,对于 ExactlyOnce 暂时没有类似的日志,可以考虑自己添加,或者 jmap 查看。
2、 2.3主线程太忙,导致没机会做snapshot;
在task 端,所有的处理都是单线程的,数据处理和 barrier 处理都由主线程处理,如果主线程在处理太慢(比如使用 RocksDBBackend,state 操作慢导致整体处理慢),导致 barrier 处理的慢,也会影响整体 Checkpoint 的进度,在这一步我们需要能够查看某个 PID 对应 hotmethod,这里推荐两个方法:
- 多次连续 jstack,查看一直处于 RUNNABLE 状态的线程有哪些;
- 使用工具 AsyncProfile dump 一份火焰图,查看占用 CPU 最多的栈;
如果有其他更方便的方法当然更好,也欢迎推荐。
2、 2.4同步阶段做的慢;
同步阶段一般不会太慢,但是如果我们通过日志发现同步阶段比较慢的话,对于非 RocksDBBackend 我们可以考虑查看是否开启了异步 snapshot,如果开启了异步 snapshot 还是慢,需要看整个 JVM 在干嘛,也可以使用前一节中的工具。对于 RocksDBBackend 来说,我们可以用 iostate 查看磁盘的压力如何,另外可以查看 tm 端 RocksDB 的 log 的日志如何,查看其中 SNAPSHOT 的时间总共开销多少。
RocksDB 开始 snapshot 的日志如下:
2019/09/10-14:22:55.734684 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:83] Started the snapshot process -- creating snapshot in directory /tmp/flink-io-87c360ce-0b98-48f4-9629-2cf0528d5d53/XXXXXXXXXXX/chk-92729
snapshot 结束的日志如下:
2019/09/10-14:22:56.001275 7fef66ffd700 [utilities/checkpoint/checkpoint_impl.cc:145] Snapshot DONE. All is good
#####2.2.6 异步阶段做的慢
对于异步阶段来说,tm 端主要将 state 备份到持久化存储上,对于非 RocksDBBackend 来说,主要瓶颈来自于网络,这个阶段可以考虑观察网络的 metric,或者对应机器上能够观察到网络流量的情况(比如 iftop)。
对于RocksDB 来说,则需要从本地读取文件,写入到远程的持久化存储上,所以不仅需要考虑网络的瓶颈,还需要考虑本地磁盘的性能。另外对于 RocksDBBackend 来说,如果觉得网络流量不是瓶颈,但是上传比较慢的话,还可以尝试考虑开启多线程上传功能[3]。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: