目录
0、 相关文章链接;
1、 依赖介绍;
2、 程序结果;
3、 API;
3、 1.获取环境;
3、 2.创建表;
3、 3.查询表;
3、 4.写出表;
3、 5.与DataSet/DataStream集成;
3、 6.TableAPI&SQL;
4、 相关概念;
4、 1.动态表和连续查询;
4、 2.表到流的转换;
4、 2.1.表中的Update和Delete;
4、 2.2.对表的编码操作;
4、 2.3.将表转换为三种不同编码方式的流;
0. 相关文章链接
1. 依赖介绍
官网地址:Apache Flink 1.12 Documentation: Table API & SQL
pom:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- flink执行计划,这是1.9版本之前的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- blink执行计划,1.11+默认的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
具体说明:
*flink-table-common:这个包中主要是包含 Flink Planner 和 Blink Planner一些共用的代码。
*flink-table-api-java:这部分是用户编程使用的 API,包含了大部分的 API。
*flink-table-api-scala:这里只是非常薄的一层,仅和 Table API 的 Expression 和 DSL 相关。
*两个 Planner:flink-table-planner 和 flink-table-planner-blink。
*两个 Bridge:flink-table-api-scala-bridge 和 flink-table-api-java-bridge,
Flink Planner 和 Blink Planner 都会依赖于具体的 JavaAPI,也会依赖于具体的 Bridge,通过 Bridge 可以将 API 操作相应的转化为Scala 的 DataStream、DataSet,或者转化为 JAVA 的 DataStream 或者Data Set
2. 程序结果
官网地址:Apache Flink 1.12 Documentation: Concepts & Common API
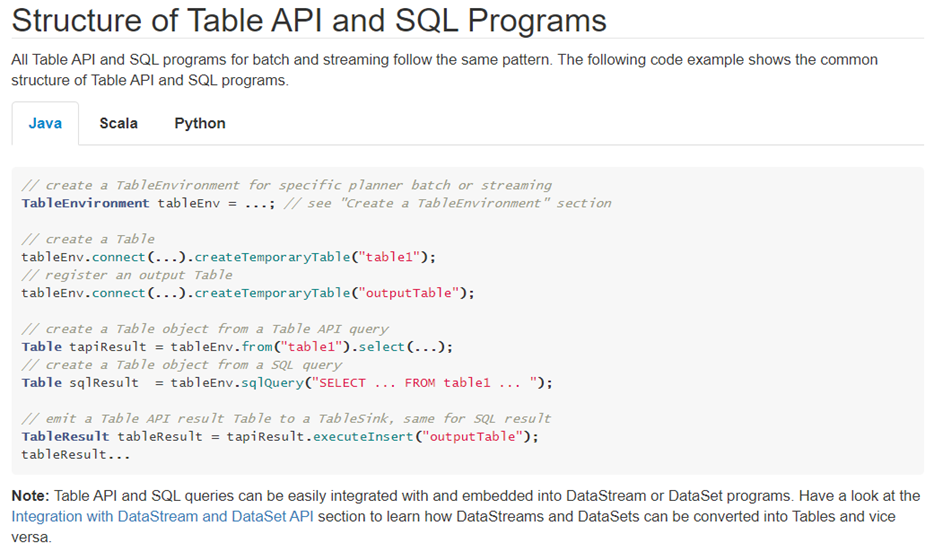
核心代码:
// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create a Table
tableEnv.connect(...).createTemporaryTable("table1");
// register an output Table
tableEnv.connect(...).createTemporaryTable("outputTable");
// create a Table object from a Table API query
Table tapiResult = tableEnv.from("table1").select(...);
// create a Table object from a SQL query
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");
// emit a Table API result Table to a TableSink, same for SQL result
TableResult tableResult = tapiResult.executeInsert("outputTable");
tableResult...
3. API
3.1. 获取环境
官网地址:Apache Flink 1.12 Documentation: Concepts & Common API
// **********************
// FLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
// or TableEnvironment fsTableEnv = TableEnvironment.create(fsSettings);
// ******************
// FLINK BATCH QUERY
// ******************
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.BatchTableEnvironment;
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
// **********************
// BLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
// or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings);
// ******************
// BLINK BATCH QUERY
// ******************
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
3.2. 创建表
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// table is the result of a simple projection query
Table projTable = tableEnv.from("X").select(...);
// register the Table projTable as table "projectedTable"
tableEnv.createTemporaryView("projectedTable", projTable);
tableEnvironment
.connect(...)
.withFormat(...)
.withSchema(...)
.inAppendMode()
.createTemporaryTable("MyTable")
3.3. 查询表
TableAPI:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// scan registered Orders table
Table orders = tableEnv.from("Orders");// compute revenue for all customers from France
Table revenue = orders
.filter($("cCountry")
.isEqual("FRANCE"))
.groupBy($("cID"), $("cName")
.select($("cID"), $("cName"), $("revenue")
.sum()
.as("revSum"));
// emit or convert Table
// execute query
SQL:
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register Orders table
// compute revenue for all customers from France
Table revenue = tableEnv.sqlQuery(
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
// emit or convert Table
// execute query
// ######################################################################
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// register "Orders" table
// register "RevenueFrance" output table
// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.executeSql(
"INSERT INTO RevenueFrance " +
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);
3.4. 写出表
// get a TableEnvironment
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create an output Table
final Schema schema = new Schema()
.field("a", DataTypes.INT())
.field("b", DataTypes.STRING())
.field("c", DataTypes.BIGINT());
tableEnv.connect(new FileSystem().path("/path/to/file"))
.withFormat(new Csv().fieldDelimiter('|').deriveSchema())
.withSchema(schema)
.createTemporaryTable("CsvSinkTable");
// compute a result Table using Table API operators and/or SQL queries
Table result = ...
// emit the result Table to the registered TableSink
result.executeInsert("CsvSinkTable");
3.5. 与DataSet/DataStream集成
官网地址:Apache Flink 1.12 Documentation: Concepts & Common API

- 从DataSet或者DataStream中创建一个视图:
// get StreamTableEnvironment
// registration of a DataSet in a BatchTableEnvironment is equivalent
StreamTableEnvironment tableEnv = ...;
// see "Create a TableEnvironment" section
DataStream<Tuple2<Long, String>> stream = ...
// register the DataStream as View "myTable" with fields "f0", "f1"
tableEnv.createTemporaryView("myTable", stream);
// register the DataStream as View "myTable2" with fields "myLong", "myString"
tableEnv.createTemporaryView("myTable2", stream, $("myLong"), $("myString"));
- 将一个DataSet或者DataStream转换成表:
// get StreamTableEnvironment// registration of a DataSet in a BatchTableEnvironment is equivalent
StreamTableEnvironment tableEnv = ...;
// see "Create a TableEnvironment" section
DataStream<Tuple2<Long, String>> stream = ...
// Convert the DataStream into a Table with default fields "f0", "f1"
Table table1 = tableEnv.fromDataStream(stream);
// Convert the DataStream into a Table with fields "myLong", "myString"
Table table2 = tableEnv.fromDataStream(stream, $("myLong"), $("myString"));
- 将一个表转换成DataStream
Append Mode: This mode can only be used if the dynamic Table is only modified by INSERT changes, i.e, it is append-only and previously emitted results are never updated.
追加模式:只有当动态表仅通过插入更改进行修改时,才能使用此模式,即,它是仅追加模式,并且以前发出的结果从不更新。
Retract Mode: This mode can always be used. It encodes INSERT and DELETE changes with a boolean flag.
撤回模式:此模式始终可用。它使用布尔标志对插入和删除更改进行编码。
// get StreamTableEnvironment.
StreamTableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// Table with two fields (String name, Integer age)
Table table = ...
// convert the Table into an append DataStream of Row by specifying the class
DataStream<Row> dsRow = tableEnv.toAppendStream(table, Row.class);
// convert the Table into an append DataStream of Tuple2<String, Integer>
// via a TypeInformation
TupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(
Types.STRING(),
Types.INT());
DataStream<Tuple2<String, Integer>> dsTuple =
tableEnv.toAppendStream(table, tupleType);
// convert the Table into a retract DataStream of Row.
// A retract stream of type X is a DataStream<Tuple2<Boolean, X>>.
// The boolean field indicates the type of the change.
// True is INSERT, false is DELETE.
DataStream<Tuple2<Boolean, Row>> retractStream =
tableEnv.toRetractStream(table, Row.class);
- 将一个表转换成DataSet
// get BatchTableEnvironment
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
// Table with two fields (String name, Integer age)
Table table = ...
// convert the Table into a DataSet of Row by specifying a class
DataSet<Row> dsRow = tableEnv.toDataSet(table, Row.class);
// convert the Table into a DataSet of Tuple2<String, Integer> via a TypeInformationTupleTypeInfo<Tuple2<String, Integer>> tupleType = new TupleTypeInfo<>(
Types.STRING(),
Types.INT());
DataSet<Tuple2<String, Integer>> dsTuple =
tableEnv.toDataSet(table, tupleType);
3.6. TableAPI & SQL
TableAPI:Apache Flink 1.12 Documentation: Table API
SQL:Apache Flink 1.12 Documentation: SQL
4. 相关概念
官网地址:Apache Flink 1.12 Documentation: Dynamic Tables
4.1. 动态表和连续查询
在Flink中,它把针对无界流的表称之为Dynamic Table(动态表)。它是Flink Table API和SQL的核心概念。顾名思义,它表示了Table是不断变化的。
我们可以这样来理解,当我们用Flink的API,建立一个表,其实把它理解为建立一个逻辑结构,这个逻辑结构需要映射到数据上去。Flink source源源不断的流入数据,就好比每次都往表上新增一条数据。表中有了数据,我们就可以使用SQL去查询了。要注意一下,流处理中的数据是只有新增的,所以看起来数据会源源不断地添加到表中。
动态表也是一种表,既然是表,就应该能够被查询。我们来回想一下原先我们查询表的场景。
打开编译工具,编写一条SQL语句:
- 将SQL语句放入到mysql的终端执行
- 查看结果
- 再编写一条SQL语句
- 再放入到终端执行
- 再查看结果
…..如此反复
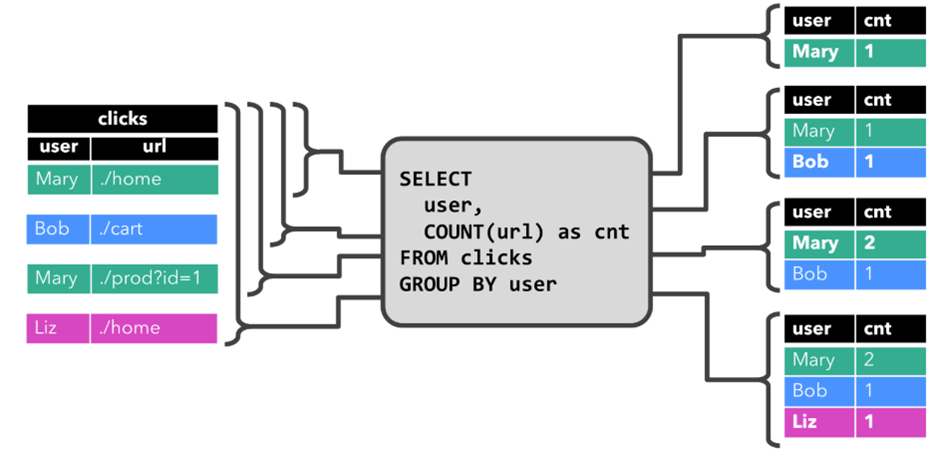
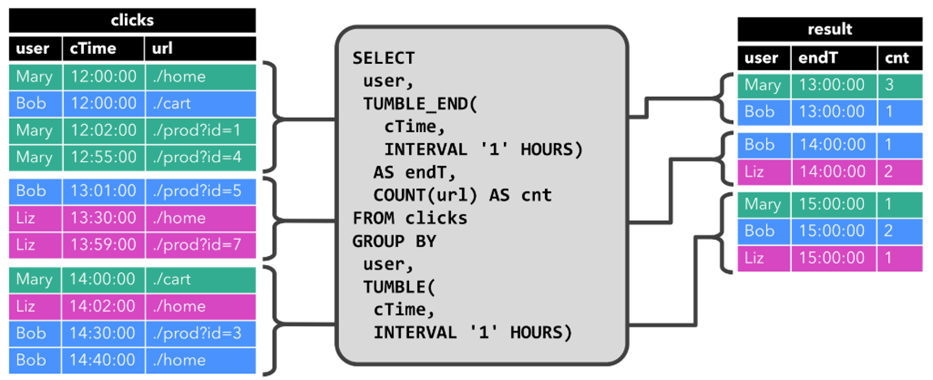
而针对动态表,Flink的source端肯定是源源不断地会有数据流入,然后我们基于这个数据流建立了一张表,再编写SQL语句查询数据,进行处理。这个SQL语句一定是不断地执行的。而不是只执行一次。注意:针对流处理的SQL绝对不会像批式处理一样,执行一次拿到结果就完了。而是会不停地执行,不断地查询获取结果处理。所以,官方给这种查询方式取了一个名字,叫Continuous Query,中文翻译过来叫连续查询。而且每一次查询出来的数据也是不断变化的。
这是一个非常简单的示意图。该示意图描述了:我们通过建立动态表和连续查询来实现在无界流中的SQL操作。大家也可以看到,在Continuous上面有一个State,表示查询出来的结果会存储在State中,再下来Flink最终还是使用流来进行处理。
所以,我们可以理解为Flink的Table API和SQL,是一个逻辑模型,通过该逻辑模型可以让我们的数据处理变得更加简单。

4.2. 表到流的转换
4.2.1. 表中的Update和Delete
我们前面提到的表示不断地Append,表的数据是一直累加的,因为表示对接Source的,Source是不会有update的。但如果我们编写了一个SQL。这个SQL看起来是这样的:
```java SELECT user, sum(money) FROM order GROUP BY user;
>
>当执行一条SQL语句之后,这条语句的结果还是一个表,因为在Flink中执行的SQL是Continuous Query,这个表的数据是不断变化的。新创建的表存在Update的情况。仔细看下下面的示例,例如:
>
>第一条数据,张三,2000,执行这条SQL语句的结果是,张三,2000
>
>第二条数据,李四,1500,继续执行这条SQL语句,结果是,张三,2000 | 李四,1500
>
>第三条数据,张三,300,继续执行这条SQL语句,结果是,张三,2300 | 李四,1500
>
>….
>
>大家发现了吗,现在数据结果是有Update的。张三一开始是2000,但后面变成了2300。
>
>那还有删除的情况吗?有的。看一下下面这条SQL语句
>
> ```java
> SELECT t1.user, SUM(t1.money) FROM t_order t1
> WHERE
> NOT EXISTS (SELECT T2.userAS TOTAL_MONEY FROM t_order t2 WHERE T2.user = T1.user GROUP BY t2.user HAVING SUM(T2.money) >` 3000)
> GROUP BY t1.userGROUP BY t1.user
>
第一条数据,张三,2000,执行这条SQL语句的结果是,张三,2000
第二条数据,李四,1500,继续执行这条SQL语句,结果是,张三,2000 | 李四,1500
第三条数据,张三,300,继续执行这条SQL语句,结果是,张三,2300 | 李四,1500
第四条数据,张三,800,继续执行这条SQL语句,结果是,李四,1500
惊不惊喜?意不意外?
因为张三的消费的金额已经超过了3000,所以SQL执行完后,张三是被处理掉了。从数据的角度来看,它不就是被删除了吗?
通过上面的两个示例,给大家演示了,在Flink SQL中,对接Source的表都是Append-only的,不断地增加。执行一些SQL生成的表,这个表可能是要UPDATE的、也可能是要INSERT的。
4.2.2. 对表的编码操作
我们前面说到过,表是一种逻辑结构。而Flink中的核心还是Stream。所以,Table最终还是会以Stream方式来继续处理。如果是以Stream方式处理,最终Stream中的数据有可能会写入到其他的外部系统中,例如:将Stream中的数据写入到MySQL中。
我们前面也看到了,表是有可能会UPDATE和DELETE的。那么如果是输出到MySQL中,就要执行UPDATE和DELETE语句了。而DataStream我们在学习Flink的时候就学习过了,DataStream是不能更新、删除事件的。
如果对表的操作是INSERT,这很好办,直接转换输出就好,因为DataStream数据也是不断递增的。但如果一个TABLE中的数据被UPDATE了、或者被DELETE了,如果用流来表达呢?因为流不可变的特征,我们肯定要对这种能够进行UPDATE/DELETE的TABLE做特殊操作。
我们可以针对每一种操作,INSERT/UPDATE/DELETE都用一个或多个经过编码的事件来表示。
例如:针对UPDATE,我们用两个操作来表达,[DELETE] 数据+ [INSERT]数据。也就是先把之前的数据删除,然后再插入一条新的数据。针对DELETE,我们也可以对流中的数据进行编码,[DELETE]数据。
总体来说,我们通过对流数据进行编码,也可以告诉DataStream的下游,[DELETE]表示发出MySQL的DELETE操作,将数据删除。用 [INSERT]表示插入新的数据。
4.2.3. 将表转换为三种不同编码方式的流
Flink中的Table API或者SQL支持三种不同的编码方式。分别是:
Append-only流
Retract流
Upsert流
分别来解释下这三种流。
Append-only流:
跟INSERT操作对应。这种编码类型的流针对的是只会不断新增的Dynamic Table。这种方式好处理,不需要进行特殊处理,源源不断地往流中发送事件即可。
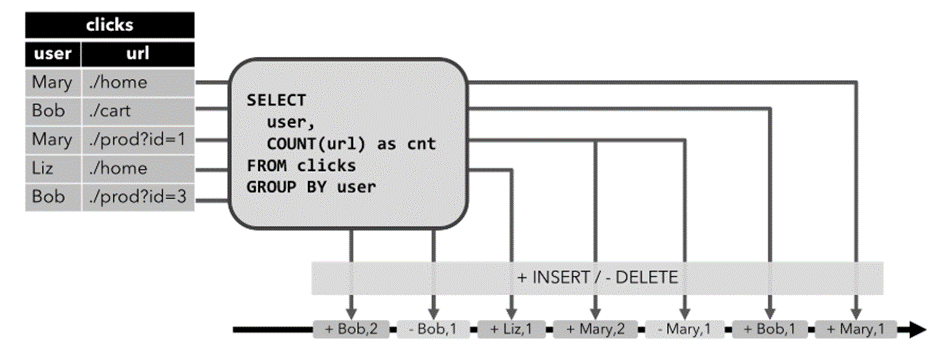
Retract流:
这种流就和Append-only不太一样。上面的只能处理INSERT,如果表会发生DELETE或者UPDATE,Append-only编码方式的流就不合适了。Retract流有几种类型的事件类型:
1)ADD MESSAGE:这种消息对应的就是INSERT操作。
2)RETRACT MESSAGE:直译过来叫取消消息。这种消息对应的就是DELETE操作。
我们可以看到通过ADD MESSAGE和RETRACT MESSAGE可以很好的向外部系统表达删除和插入操作。那如何进行UPDATE呢?好办!RETRACT MESSAGE + ADD MESSAGE即可。先把之前的数据进行删除,然后插入一条新的。完美~
Upsert流:
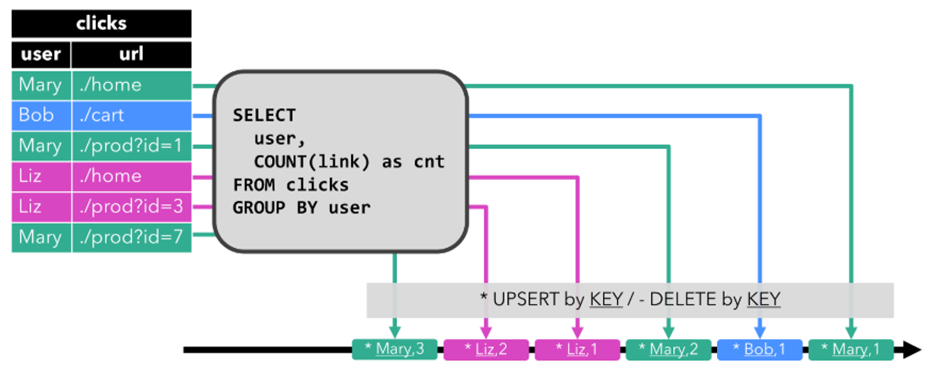
前面我们看到的RETRACT编码方式的流,实现UPDATE是使用DELETE + INSERT模式的。大家想一下:在MySQL中我们更新数据的时候,肯定不会先DELETE掉一条数据,然后再插入一条数据,肯定是直接发出UPDATE语句执行更新。而Upsert编码方式的流,是能够支持Update的,这种效率更高。它同样有两种类型的消息:
1)UPSERT MESSAGE:这种消息可以表示要对外部系统进行Update或者INSERT操作
2)DELETE MESSAGE:这种消息表示DELETE操作。
Upsert流是要求必须指定Primary Key的,因为Upsert操作是要有Key的。Upsert流针对UPDATE操作用一个UPSERT MESSAGE就可以描述,所以效率会更高。
注:其他相关文章链接由此进 ->Flink文章汇总
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: