目录
0、 相关文章链接;
1、 什么是TableAPI和FlinkSQL;
2、 为什么需要TableAPI&SQL;
3、 TableAPI和FlinkSQL的特点;
4、 TableAPI&FlinkSQL发展历程;
4、 1.架构升级;
4、 2.查询处理器的选择;
4、 3.Blinkplanner和FlinkPlanner具体区别;
5、 API稳定性;
6、 性能对比;
0. 相关文章链接
1. 什么是 Table API 和 Flink SQL
Flink本身是批流统一的处理框架,所以Table API和SQL,就是批流统一的上层处理API。目前功能尚未完善,处于活跃的开发阶段。
Table API是一套内嵌在Java和Scala语言中的查询API,它允许我们以非常直观的方式,组合来自一些关系运算符的查询(比如select、filter和join)。而对于Flink SQL,就是直接可以在代码中写SQL,来实现一些查询(Query)操作。Flink的SQL支持,基于实现了SQL标准的Apache Calcite(Apache开源SQL解析工具)。
无论输入是批输入还是流式输入,在这两套API中,指定的查询都具有相同的语义,得到相同的结果。
2. 为什么需要Table API & SQL
官网网址:Apache Flink 1.12 Documentation: Table API & SQL

Flink的Table模块包括 Table API 和 SQL:
- Table API 是一种类SQL的API,通过Table API,用户可以像操作表一样操作数据,非常直观和方便
- SQL作为一种声明式语言,有着标准的语法和规范,用户可以不用关心底层实现即可进行数据的处理,非常易于上手
- Flink Table API 和 SQL 的实现上有80%左右的代码是公用的。作为一个流批统一的计算引擎,Flink 的 Runtime 层是统一的。
3. Table API 和 Flink SQL的特点
Flink之所以选择将 Table API & SQL 作为未来的核心 API,是因为其具有一些非常重要的特点:

- 声明式:属于设定式语言,用户只要表达清楚需求即可,不需要了解底层执行;
- 高性能:可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
- 简单易学:易于理解,不同行业和领域的人都懂,学习成本较低;
- 标准稳定:语义遵循SQL标准,非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
- 流批统一:可以做到API层面上流与批的统一,相同的SQL逻辑,既可流模式运行,也可批模式运行,Flink底层Runtime本身就是一个流与批统一的引擎
4. Table API & Flink SQL发展历程
4.1. 架构升级
自2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。随着版本的不断更新,API 也出现了很多不兼容的地方。
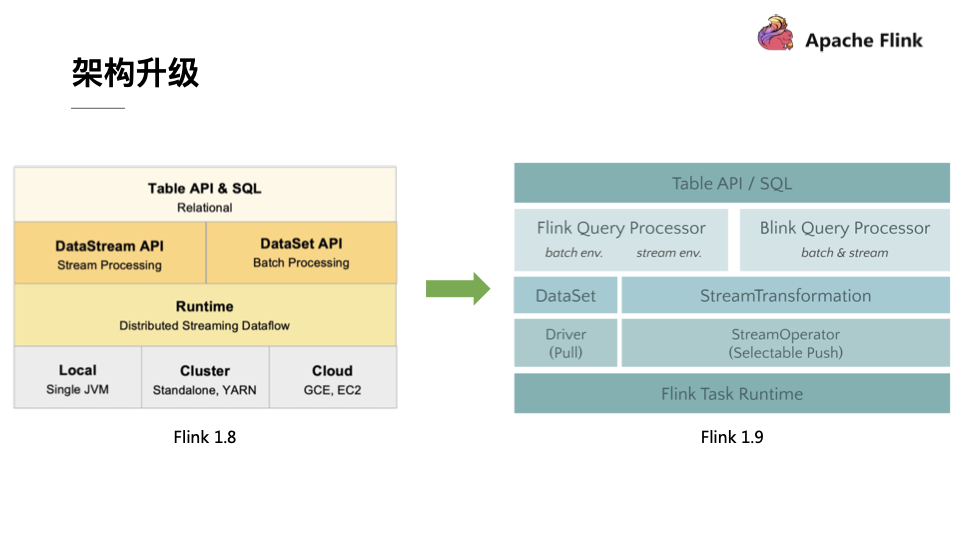
在Flink 1.9 中,Table 模块迎来了核心架构的升级,引入了阿里巴巴Blink团队贡献的诸多功能。在Flink 1.9 之前,Flink API 层 一直分为DataStream API 和 DataSet API,Table API & SQL 位于 DataStream API 和 DataSet API 之上。可以看处流处理和批处理有各自独立的api (流处理DataStream,批处理DataSet)。而且有不同的执行计划解析过程,codegen过程也完全不一样,完全没有流批一体的概念,面向用户不太友好。
在Flink1.9之后新的架构中,有两个查询处理器:Flink Query Processor,也称作Old Planner和Blink Query Processor,也称作Blink Planner。为了兼容老版本Table及SQL模块,插件化实现了Planner,Flink原有的Flink Planner不变,后期版本会被移除。新增加了Blink Planner,新的代码及特性会在Blink planner模块上实现。批或者流都是通过解析为Stream Transformation来实现的,不像Flink Planner,批是基于Dataset,流是基于DataStream。
4.2. 查询处理器的选择
查询处理器是 Planner 的具体实现,通过parser、optimizer、codegen(代码生成技术)等流程将 Table API & SQL作业转换成 Flink Runtime 可识别的 Transformation DAG,最终由 Flink Runtime 进行作业的调度和执行。
Flink Query Processor查询处理器针对流计算和批处理作业有不同的分支处理,流计算作业底层的 API 是 DataStream API, 批处理作业底层的 API 是 DataSet API
Blink Query Processor查询处理器则实现流批作业接口的统一,底层的 API 都是Transformation,这就意味着我们和Dataset完全没有关系了
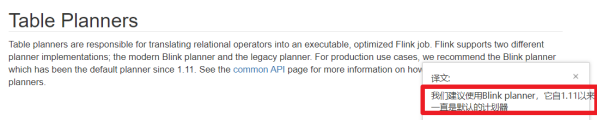
Flink1.11之后Blink Query Processor查询处理器已经是默认的了:Apache Flink 1.12 Documentation: Table API & SQL
4.3. Blink planner和Flink Planner具体区别
官网网址:Apache Flink 1.12 Documentation: Concepts & Common API
- 批流统一:Blink将批处理作业,视为流式处理的特殊情况。所以,blink不支持表和DataSet之间的转换,批处理作业将不转换为DataSet应用程序,而是跟流处理一样,转换为DataStream程序来处理。
- 因为批流统一,Blink planner也不支持BatchTableSource,而使用有界的StreamTableSource代替。
- Blink planner只支持全新的目录,不支持已弃用的ExternalCatalog。
- 旧planner和Blink planner的FilterableTableSource实现不兼容。旧的planner会把PlannerExpressions下推到filterableTableSource中,而blink planner则会把Expressions下推。
- 基于字符串的键值配置选项仅适用于Blink planner。
- PlannerConfig在两个planner中的实现不同。
- Blink planner会将多个sink优化在一个DAG中(仅在TableEnvironment上受支持,而在StreamTableEnvironment上不受支持)。而旧planner的优化总是将每一个sink放在一个新的DAG中,其中所有DAG彼此独立。
- 旧的planner不支持目录统计,而Blink planner支持。

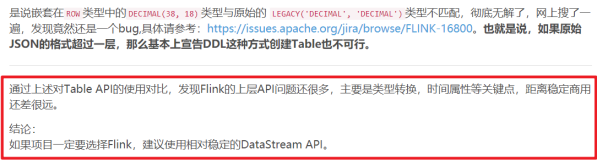
5. API稳定性
6. 性能对比
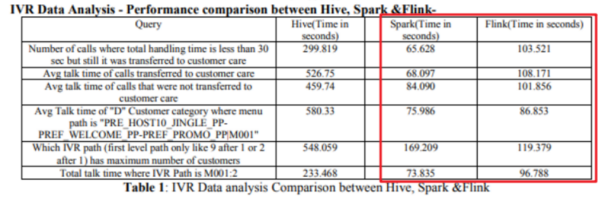
注意:目前FlinkSQL性能不如SparkSQL,未来FlinkSQL可能会越来越好
下图是Hive、Spark、Flink的SQL执行速度对比:
此博客根据某马2020年贺岁视频改编而来:【狂野大数据】Flink1.12从入门到精通#2021#流批一体#黑马程序员#大数据_哔哩哔哩_bilibili
注:其他相关文章链接由此进 ->Flink文章汇总
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: