目录
0、 相关文章链接;
1、 原理;
2、 操作;
3、 测试;
0. 相关文章链接
1. 原理
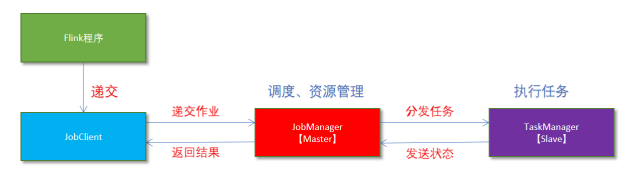
- Flink程序由JobClient进行提交
- JobClient将作业提交给JobManager
- JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(JobClient)
2. 操作
1)下载安装包
2)上传flink-1.12.0-bin-scala_2.12.tgz到node1的指定目录
3)解压
tar-zxvf flink-1.12.0-bin-scala_2.12.tgz
4)如果出现权限问题,需要修改权限
chown -R root:root /export/server/flink-1.12.0
5)改名或创建软链接
mvflink-1.12.0 flink
ln-s /export/server/flink-1.12.0 /export/server/flink
3. 测试
1)准备文件/root/words.txt
vim /root/words.txt
hadoop spark flink
flink flink
spark hive
flink storm
hue
2)启动Flink本地“集群”
/flink/bin/start-cluster.sh
3)使用jps可以查看到下面两个进程
TaskManagerRunner
StandaloneSessionClusterEntrypoint
4)访问Flink的Web UI(http://node1:8081/)
slot在Flink里面可以认为是资源组,Flink是通过将任务分成子任务并且将这些子任务分配到slot来并行执行程序。
5)执行官方示例
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar --input /root/words.txt --output /root/out
6)停止Flink
/export/server/flink/bin/stop-cluster.sh
7)Flink的shell交互式窗口
# 启动shell交互式窗口(目前所有Scala 2.12版本的安装包暂时都不支持 Scala Shell)
/export/server/flink/bin/start-scala-shell.sh local
# 执行如下命令
benv.readTextFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1).print()
# 退出shell
:quit
转载至某马2020年贺岁视频:【狂野大数据】Flink1.12从入门到精通#2021#流批一体#黑马程序员#大数据_哔哩哔哩_bilibili
注:其他相关文章链接由此进 -> Flink文章汇总
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: