目录
0、 相关文章链接;
1、 StateVsCheckpoint;
2、 Checkpoint执行流程;
2、 1.简单流程;
2、 2.复杂流程;
3、 State状态后端/State存储介质;
3、 1.MemStateBackend;
3、 2.FsStateBackend;
3、 3.RocksDBStateBackend;
4、 Checkpoint配置方式;
4、 1.全局配置;
4、 2.在代码中配置;
5、 代码演示;
6、 Flink的检查点算法;
6、 Flink+Kafka如何实现端到端的exactly-once语义;
0. 相关文章链接
1. State Vs Checkpoint
State:
维护/存储的是某一个Operator的运行的状态/历史值,是维护在内存中!
一般指一个具体的Operator的状态(operator的状态表示一些算子在运行的过程中会产生的一些历史结果,如前面的maxBy底层会维护当前的最大值,也就是会维护一个keyedOperator,这个State里面存放就是maxBy这个Operator中的最大值)
State数据默认保存在Java的堆内存中/TaskManage节点的内存中
State可以被记录,在失败的情况下数据还可以恢复
Checkpoint:
某一时刻,Flink中所有的Operator的当前State的全局快照,一般存在磁盘上
表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Operator的状态
可以理解为Checkpoint是把State数据定时持久化存储了
比如KafkaConsumer算子中维护的Offset状态,当任务重新恢复的时候可以从Checkpoint中获取
注意:
Flink中的Checkpoint底层使用了Chandy-Lamport algorithm分布式快照算法可以保证数据的在分布式环境下的一致性:分布式快照算法: Chandy-Lamport 算法 - 知乎
Chandy-Lamport algorithm算法的作者也是ZK中Paxos 一致性算法的作者:zookeeper学习系列:四、Paxos算法和zookeeper的关系 - 坚毅的刀刀 - 博客园
Flink中使用Chandy-Lamport algorithm分布式快照算法取得了成功,后续Spark的StructuredStreaming也借鉴了该算法
2. Checkpoint执行流程
2.1. 简单流程
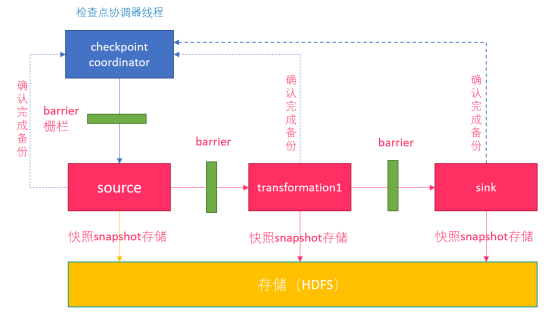
概述:
0.Flink的JobManager创建CheckpointCoordinator
1.Coordinator向所有的SourceOperator发送Barrier栅栏(理解为执行Checkpoint的信号)
2.SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制作State快照, 然后将自己的快照保存到指定的介质中(如HDFS), 一切 ok之后向Coordinator汇报并将Barrier发送给下游的其他Operator
3.其他的如TransformationOperator接收到Barrier,重复第2步,最后将Barrier发送给Sink
4.Sink接收到Barrier之后重复第2步
5.Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功
注意:
1.在往介质(如HDFS)中写入快照数据的时候是异步的(为了提高效率)
2.分布式快照执行时的数据一致性由Chandy-Lamport algorithm分布式快照算法保证!
2.2. 复杂流程
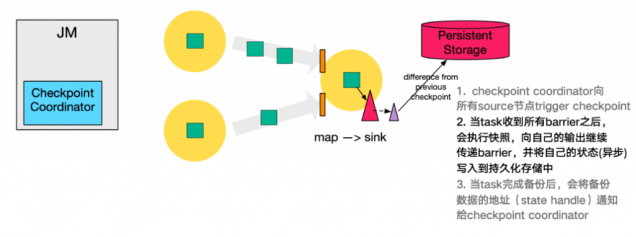
下图左侧是 Checkpoint Coordinator,是整个 Checkpoint 的发起者,中间是由两个 source,一个 sink 组成的 Flink 作业,最右侧的是持久化存储,在大部分用户场景中对应 HDFS。
- Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint。
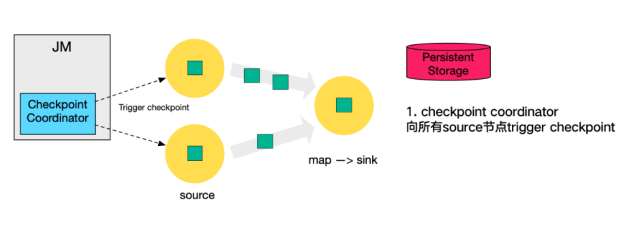
- source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有 input 的 barrier 才会执行相应的 Checkpoint。
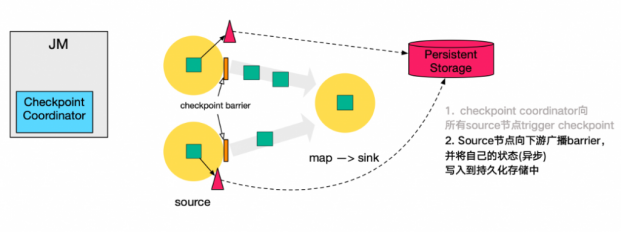
- 当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator。
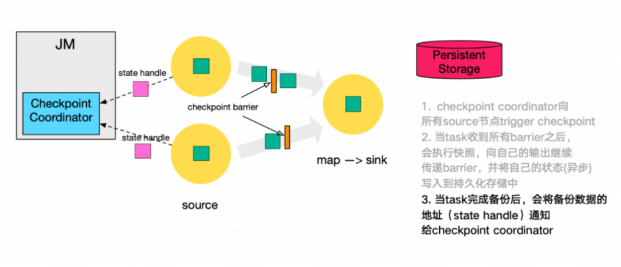
- 下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,(栅栏对齐) 这里还展示了 RocksDB incremental Checkpoint (增量Checkpoint)的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。
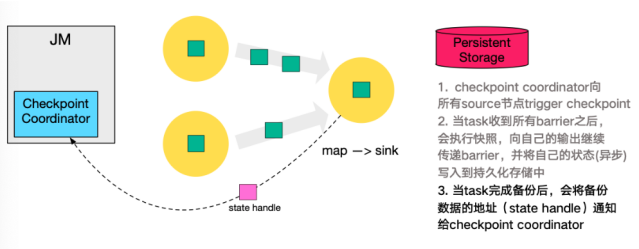
- 同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator。
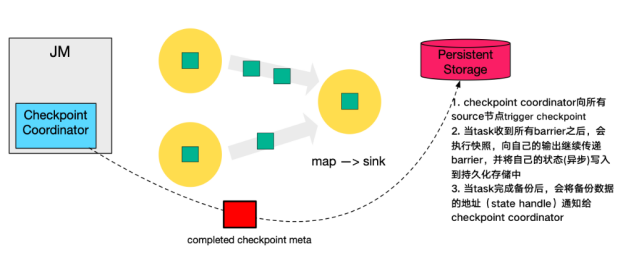
- 最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
3. State状态后端/State存储介质
前面学习了Checkpoint其实就是Flink中某一时刻,所有的Operator的全局快照,那么快照应该要有一个地方进行存储,而这个存储的地方叫做状态后端;Flink中的State状态后端有很多种。
3.1. MemStateBackend

第一种是内存存储,即 MemoryStateBackend,构造方法是设置最大的StateSize,选择是否做异步快照。
对于State状态存储在 TaskManager 节点也就是执行节点内存中的,因为内存有容量限制,所以单个 State maxStateSize 默认 5 M,且需要注意 maxStateSize <= akka.framesize 默认 10 M。
对于Checkpoint 存储在 JobManager 内存中,因此总大小不超过 JobManager 的内存。
推荐使用的场景为:本地测试、几乎无状态的作业,比如 ETL、JobManager 不容易挂,或挂掉影响不大的情况。
不推荐在生产场景使用。
3.2. FsStateBackend

另一种就是在文件系统上的 FsStateBackend 构建方法是需要传一个文件路径和是否异步快照。State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 是 5 M 的设置上限,Checkpoint 存储在外部文件系统(本地或 HDFS),打破了总大小 Jobmanager 内存的限制。
如果使用HDFS,则初始化FsStateBackend时,需要传入以 “hdfs://”开头的路径(即: new FsStateBackend("hdfs:///hacluster/checkpoint")), 如果使用本地文件,则需要传入以“file://”开头的路径(即:new FsStateBackend("file:///Data"))。
在分布式情况下,不推荐使用本地文件。因为如果某个算子在节点A上失败,在节点B上恢复,使用本地文件时,在B上无法读取节点 A上的数据,导致状态恢复失败。
推荐使用的场景为:常规使用状态的作业、例如分钟级窗口聚合或 join、需要开启HA的作业。
3.3. RocksDBStateBackend

还有一种存储为 RocksDBStateBackend ,RocksDB 是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。
不过 RocksDB 支持增量的 Checkpoint,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。
推荐使用的场景为:超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业。
4. Checkpoint配置方式
4.1. 全局配置
修改flink-conf.yaml
#这里可以配置
#jobmanager(即MemoryStateBackend),
#filesystem(即FsStateBackend),
#rocksdb(即RocksDBStateBackend)
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints
4.2. 在代码中配置
//1.MemoryStateBackend--开发中不用
env.setStateBackend(new MemoryStateBackend)
//2.FsStateBackend--开发中可以使用--适合一般状态--秒级/分钟级窗口...
env.setStateBackend(new FsStateBackend("hdfs路径或测试时的本地路径"))
//3.RocksDBStateBackend--开发中可以使用--适合超大状态--天级窗口...
env.setStateBackend(new RocksDBStateBackend(filebackend, true))
注意:RocksDBStateBackend还需要引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.7.2</version>
</dependency>
5. 代码演示
package cn.itcast.checkpoint;
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import java.util.Properties;
/**
* Author itcast
* Desc 演示Checkpoint参数设置(也就是Checkpoint执行流程中的步骤0相关的参数设置)
*/
public class CheckpointDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//===========Checkpoint参数设置====
//===========类型1:必须参数=============
//设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier!
env.enableCheckpointing(1000);
//设置State状态存储介质
/*if(args.length > 0){
env.setStateBackend(new FsStateBackend(args[0]));
}else {
env.setStateBackend(new FsStateBackend("file:///D:\\data\\ckp"));
}*/
if (SystemUtils.IS_OS_WINDOWS) {
env.setStateBackend(new FsStateBackend("file:///D:\\data\\ckp"));
} else {
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));
}
//===========类型2:建议参数===========
//设置两个Checkpoint 之间最少等待时间,如设置Checkpoint之间最少是要等 500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)
//如:高速公路上,每隔1s关口放行一辆车,但是规定了两车之前的最小车距为500m
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//默认是0
//设置如果在做Checkpoint过程中出现错误,是否让整体任务失败:true是 false不是
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);//默认是true
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);//默认值为0,表示不容忍任何检查点失败
//设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//===========类型3:直接使用默认的即可===============
//设置checkpoint的执行模式为EXACTLY_ONCE(默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时时间,如果 Checkpoint在 60s内尚未完成说明该次Checkpoint失败,则丢弃。
env.getCheckpointConfig().setCheckpointTimeout(60000);//默认10分钟
//设置同一时间有多少个checkpoint可以同时执行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//默认为1
//2.Source
DataStream<String> linesDS = env.socketTextStream("node1", 9999);
//3.Transformation
//3.1切割出每个单词并直接记为1
DataStream<Tuple2<String, Integer>> wordAndOneDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//value就是每一行
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
//3.2分组
//注意:批处理的分组是groupBy,流处理的分组是keyBy
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOneDS.keyBy(t -> t.f0);
//3.3聚合
DataStream<Tuple2<String, Integer>> aggResult = groupedDS.sum(1);
DataStream<String> result = (SingleOutputStreamOperator<String>) aggResult.map(new RichMapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return value.f0 + ":::" + value.f1;
}
});
//4.sink
result.print();
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("flink_kafka", new SimpleStringSchema(), props);
result.addSink(kafkaSink);
//5.execute
env.execute();
// /export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic flink_kafka
}
}
6. Flink的检查点算法
Flink检查点的核心作用是确保状态正确,即使遇到程序中断,也要正确。记住这一基本点之后,我们用一个例子来看检查点是如何运行的。Flink为用户提供了用来定义状态的工具。例如,以下这个Scala程序按照输入记录的第一个字段(一个字符串)进行分组并维护第二个字段的计数状态。
val stream: DataStream[(String, Int)] = ...
val counts: DataStream[(String, Int)] = stream
.keyBy(record => record._1)
.mapWithState( (in: (String, Int), state: Option[Int]) =>
state match {
case Some(c) => ( (in._1, c + in._2), Some(c + in._2) )
case None => ( (in._1, in._2), Some(in._2) )
})
该程序有两个算子: keyBy算子用来将记录按照第一个元素(一个字符串)进行分组,根据该key将数据进行重新分区,然后将记录再发送给下一个算子: 有状态的map算子(mapWithState)。map算子在接收到每个元素后,将输入记录的第二个字段的数据加到现有总数中,再将更新过的元素发射出去。下图表示程序的初始状态: 输入流中的6条记录被检查点分割线(checkpoint barrier)隔开,所有的map算子状态均为0(计数还未开始)。所有key为a的记录将被顶层的map算子处理,所有key为b的记录将被中间层的map算子处理,所有key为c的记录则将被底层的map算子处理。
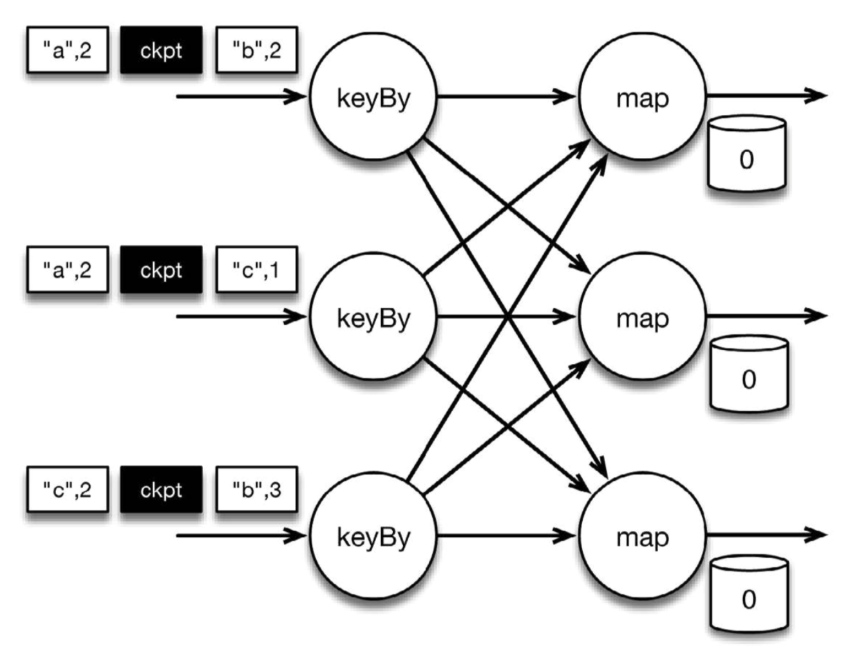 图 按key累加计数程序初始状态
图 按key累加计数程序初始状态
上图是程序的初始状态。注意,a、b、c三组的初始计数状态都是0,即三个圆柱上的值。ckpt表示检查点分割线(checkpoint barriers)。每条记录在处理顺序上严格地遵守在检查点之前或之后的规定,例如["b",2]在检查点之前被处理,["a",2]则在检查点之后被处理。
当该程序处理输入流中的6条记录时,涉及的操作遍布3个并行实例(节点、CPU内核等)。那么,检查点该如何保证exactly-once呢?
检查点分割线和普通数据记录类似。它们由算子处理,但并不参与计算,而是会触发与检查点相关的行为。当读取输入流的数据源(在本例中与keyBy算子内联)遇到检查点屏障时,它将其在输入流中的位置保存到持久化存储中。如果输入流来自消息传输系统(Kafka),这个位置就是偏移量。Flink的存储机制是插件化的,持久化存储可以是分布式文件系统,如HDFS。下图展示了这个过程。
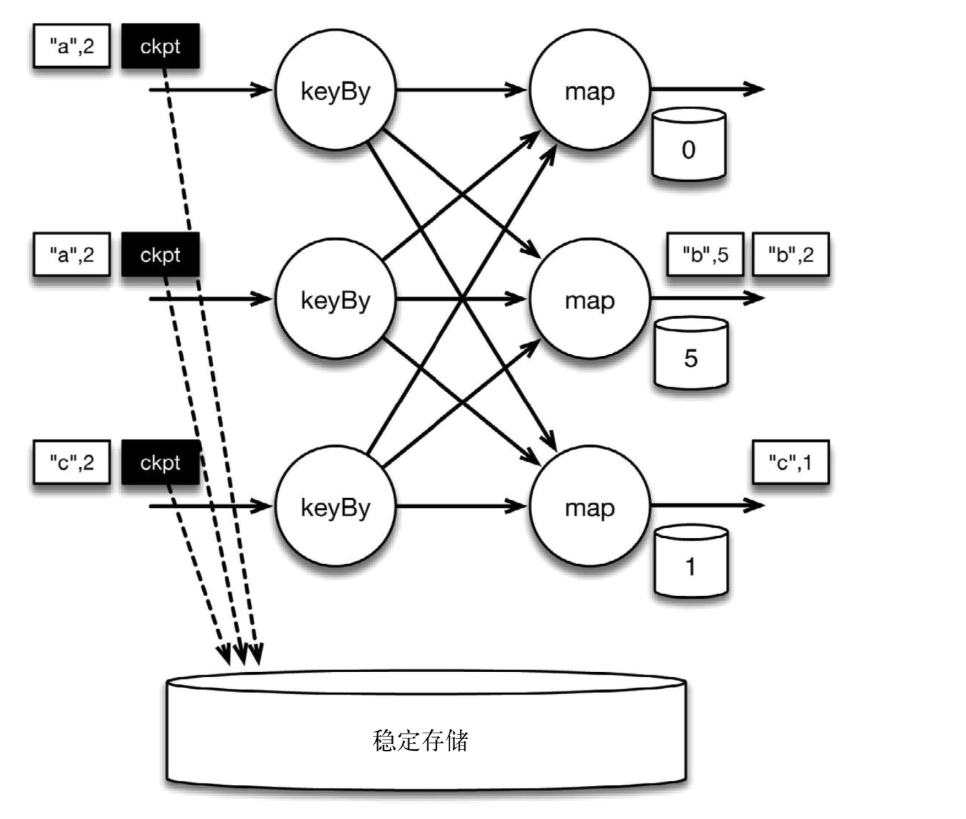 图 遇到checkpoint barrier时,保存其在输入流中的位置
图 遇到checkpoint barrier时,保存其在输入流中的位置
当Flink数据源(在本例中与keyBy算子内联)遇到检查点分界线(barrier)时,它会将其在输入流中的位置保存到持久化存储中。这让 Flink可以根据该位置重启。
检查点像普通数据记录一样在算子之间流动。当map算子处理完前3条数据并收到检查点分界线时,它们会将状态以异步的方式写入持久化存储,如下图所示。
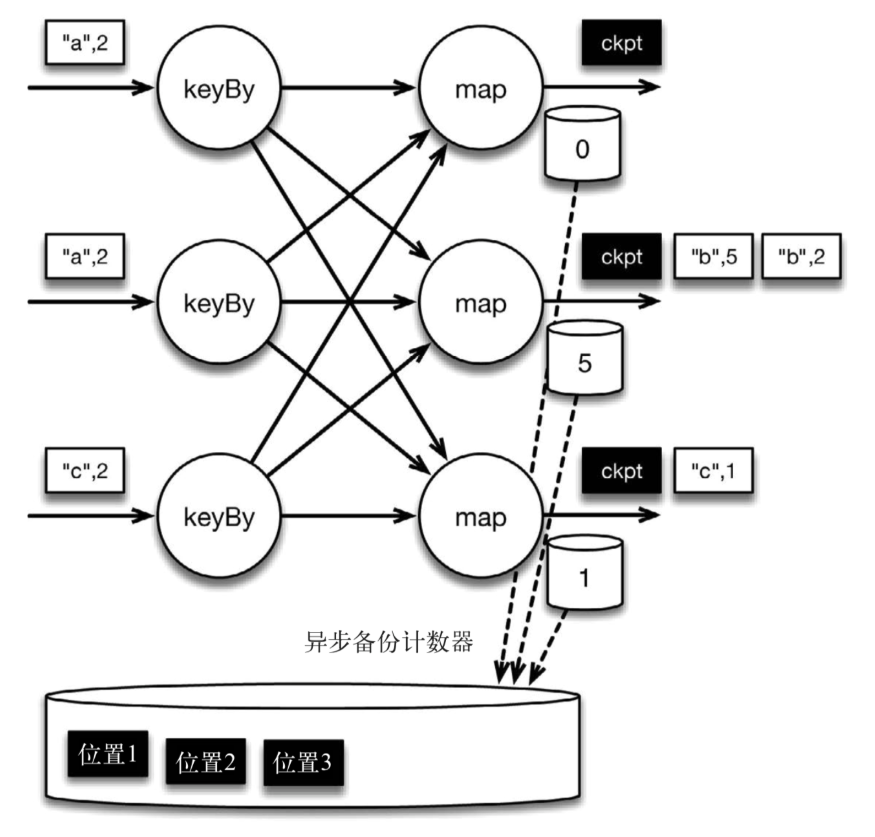 图 保存map算子状态,也就是当前各个key的计数值
图 保存map算子状态,也就是当前各个key的计数值
位于检查点之前的所有记录(["b",2]、["b",3]和["c",1])被map算子处理之后的情况。此时,持久化存储已经备份了检查点分界线在输入流中的位置(备份操作发生在barrier被输入算子处理的时候)。map算子接着开始处理检查点分界线,并触发将状态异步备份到稳定存储中这个动作。
当map算子的状态备份和检查点分界线的位置备份被确认之后,该检查点操作就可以被标记为完成,如下图所示。我们在无须停止或者阻断计算的条件下,在一个逻辑时间点(对应检查点屏障在输入流中的位置)为计算状态拍了快照。通过确保备份的状态和位置指向同一个逻辑时间点,后文将解释如何基于备份恢复计算,从而保证exactly-once。值得注意的是,当没有出现故障时,Flink检查点的开销极小,检查点操作的速度由持久化存储的可用带宽决定。回顾数珠子的例子: 除了因为数错而需要用到皮筋之外,皮筋会被很快地拨过。
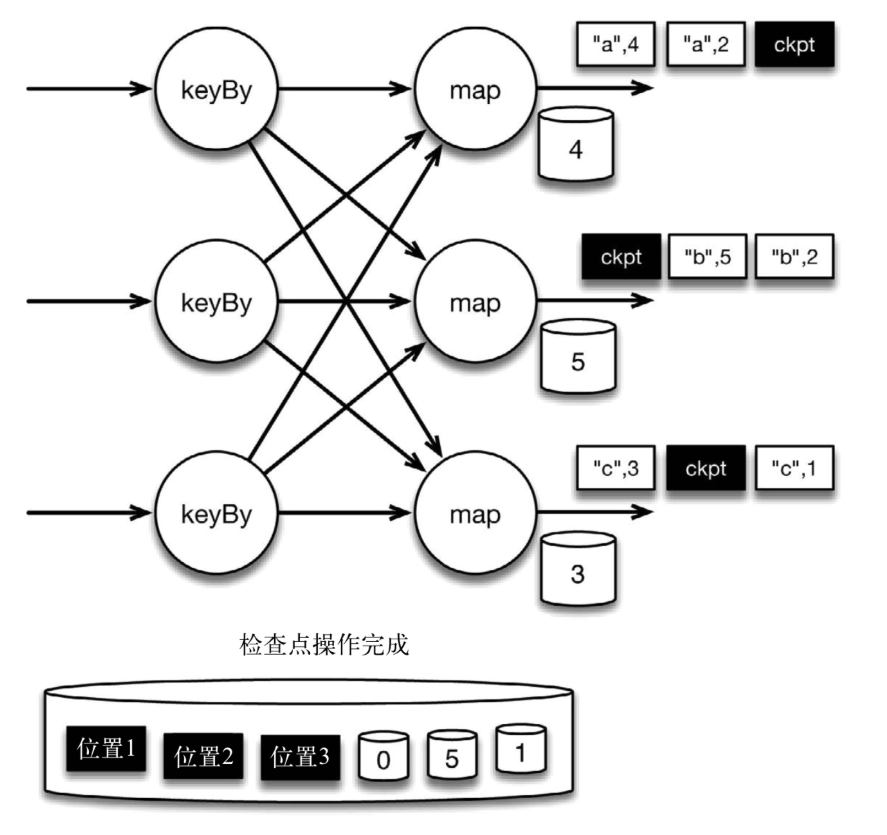 图 检查点操作完成,继续处理数据
图 检查点操作完成,继续处理数据
检查点操作完成,状态和位置均已备份到稳定存储中。输入流中的所有数据记录都已处理完成。值得注意的是,备份的状态值与实际的状态值是不同的。备份反映的是检查点的状态。
如果检查点操作失败,Flink可以丢弃该检查点并继续正常执行,因为之后的某一个检查点可能会成功。虽然恢复时间可能更长,但是对于状态的保证依旧很有力。只有在一系列连续的检查点操作失败之后,Flink才会抛出错误,因为这通常预示着发生了严重且持久的错误。
现在来看看下图所示的情况: 检查点操作已经完成,但故障紧随其后。
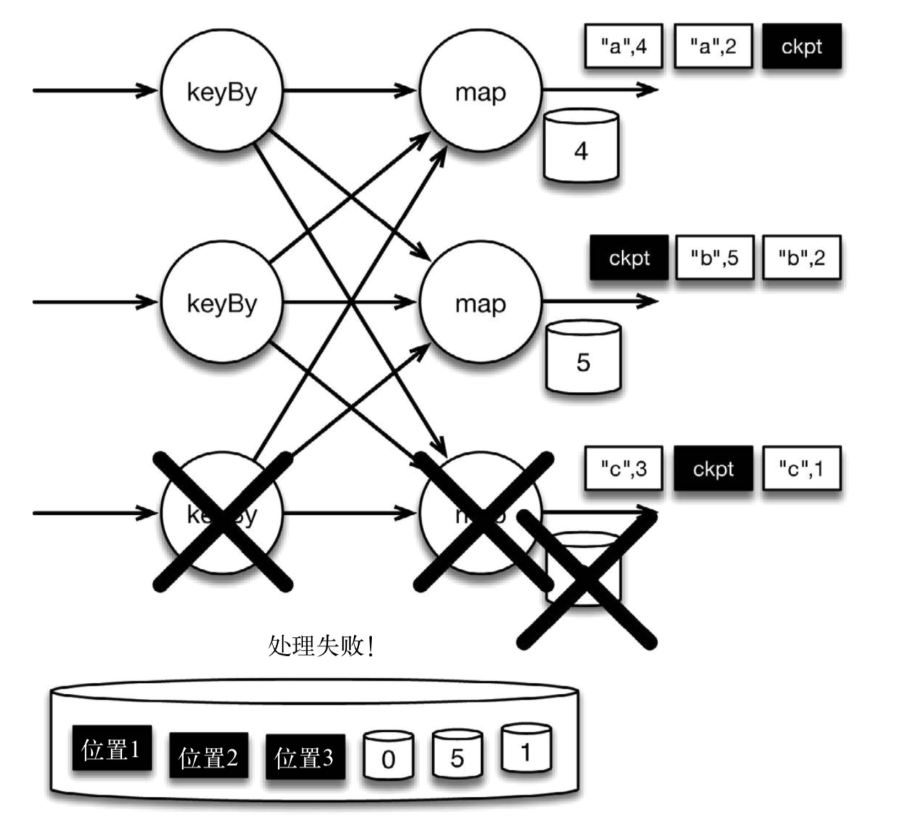 图 故障紧跟检查点,导致最底部的实例丢失
图 故障紧跟检查点,导致最底部的实例丢失
在这种情况下,Flink会重新拓扑(可能会获取新的执行资源),将输入流倒回到上一个检查点,然后恢复状态值并从该处开始继续计算。在本例中,["a",2]、["a",2]和["c",2]这几条记录将被重播。
下图展示了这一重新处理过程。从上一个检查点开始重新计算,可以保证在剩下的记录被处理之后,得到的map算子的状态值与没有发生故障时的状态值一致。
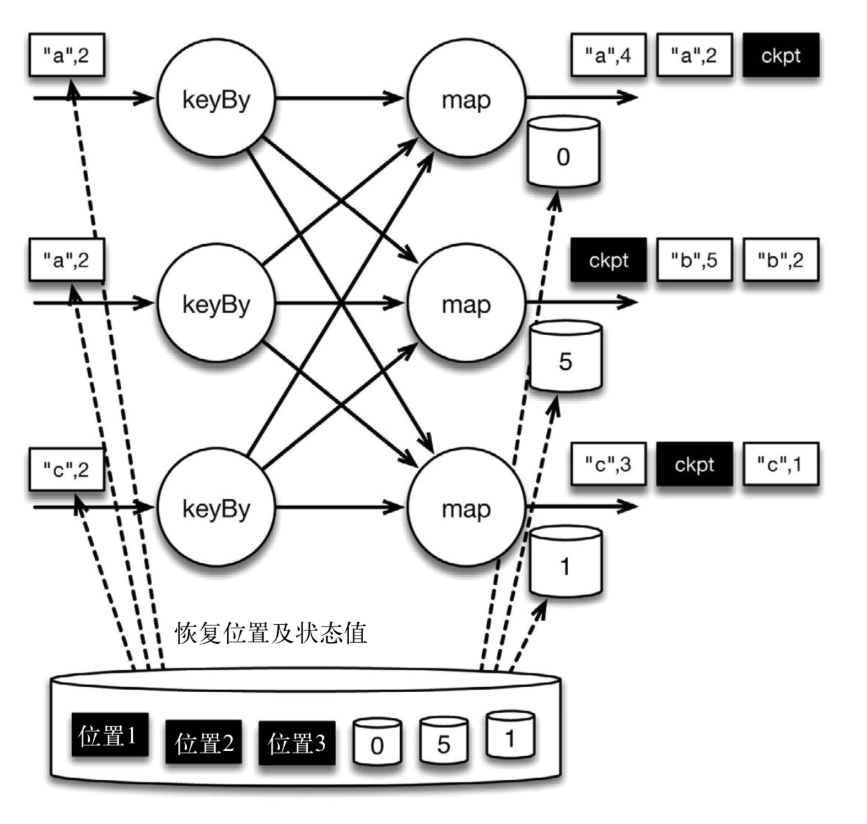 图 故障时的状态恢复
图 故障时的状态恢复
Flink将输入流倒回到上一个检查点屏障的位置,同时恢复map算子的状态值。然后,Flink从此处开始重新处理。这样做保证了在记录被处理之后,map算子的状态值与没有发生故障时的一致。
Flink检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport分布式快照算法。
检查点是Flink最有价值的创新之一,因为它使Flink可以保证exactly-once,并且不需要牺牲性能。
6. Flink+Kafka如何实现端到端的exactly-once语义
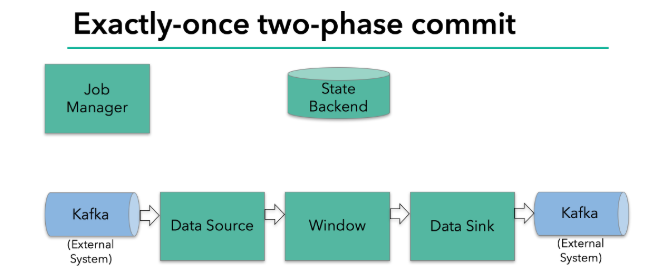
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证exactly-once语义呢?
- 内部 —— 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
内部的checkpoint机制我们已经有了了解,那source和sink具体又是怎样运行的呢?接下来我们逐步做一个分析。
我们知道Flink由JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
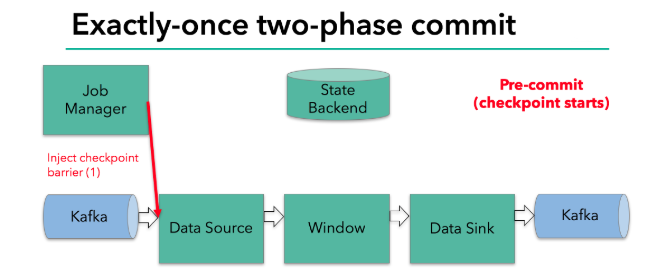
当checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier会在算子间传递下去。
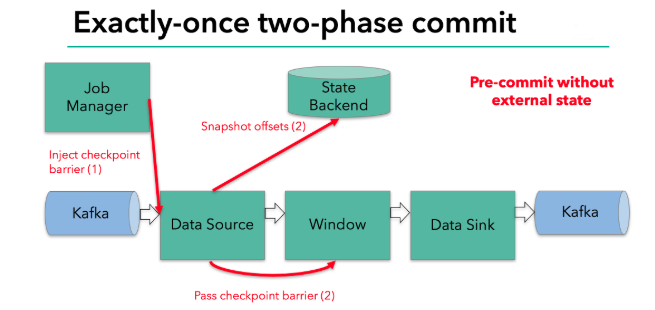
每个算子会对当前的状态做个快照,保存到状态后端。对于source任务而言,就会把当前的offset作为状态保存起来。下次从checkpoint恢复时,source任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。
每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务(还不能被消费);当遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务。
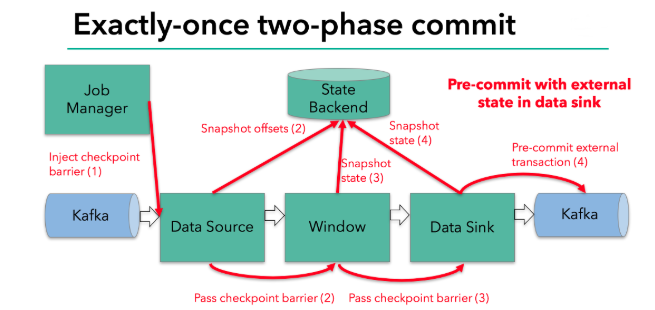
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成。
当sink 任务收到确认通知,就会正式提交之前的事务,kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了。
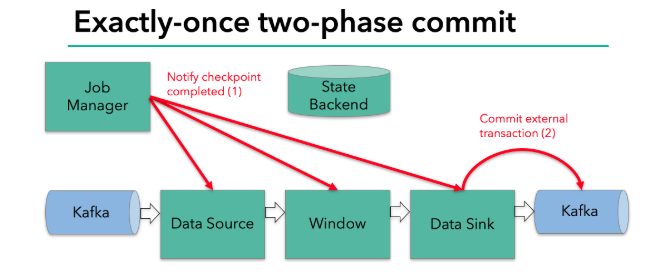
所以我们看到,执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
具体的两阶段提交步骤总结如下:
第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
外部kafka关闭事务,提交的数据可以正常消费了。
所以我们也可以看到,如果宕机需要通过StateBackend进行恢复,只能恢复所有确认提交的操作。
此博客根据某谷和某马2020年贺岁视频改编而来:【狂野大数据】Flink1.12从入门到精通#2021#流批一体#黑马程序员#大数据_哔哩哔哩_bilibili
注:其他相关文章链接由此进 ->Flink文章汇总
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: