先读取kafka 指定topic里面的数据,再通过socket控制报错重启,往kafka中再写入数据,结果是在报错之前的中间结果的基础上继续计算的。虽然看不到KeyedState和OperatorState,但是这背后是它们在发挥作用。默认情况下,kafka topic的偏移量会被保存到OperatorState中,wordCount中间结果保存在KeyedState中,报错重启后会从KeyedState和OperatorState读取报错前的结果。
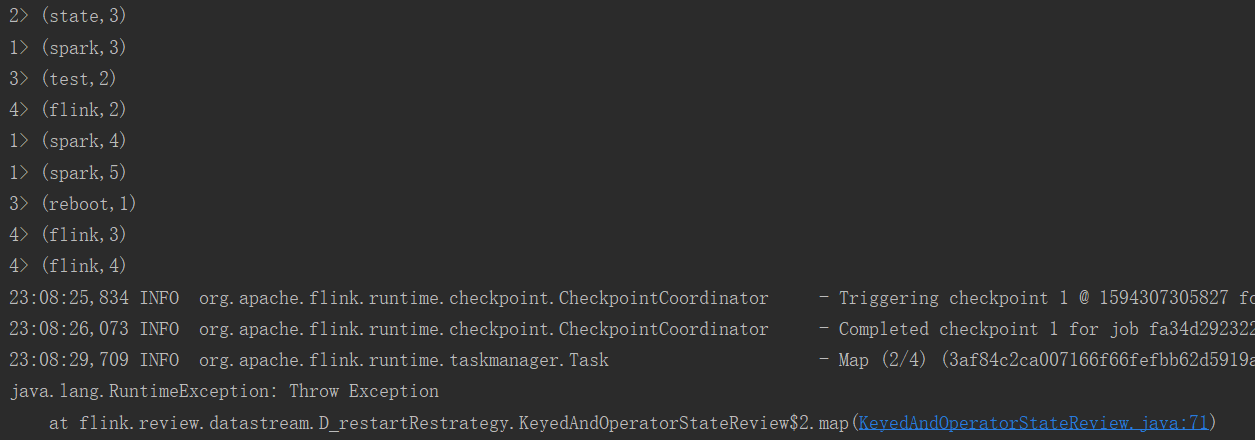
在socket中输入error,程序报错重启,再在kafka中输入以下数据,可以看出是接着上次的结果继续计算的。


具体代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
public class KeyedAndOperatorStateReview {
public static void main(String[] args) throws Exception{
// 1. 获取运行环境实例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 开启CheckPointing
env.enableCheckpointing(10000);
// 3. 设置重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, Time.seconds(2)));
//4. 设置Checkpoint模式(与Kafka整合,一定要设置Checkpoint模式为Exactly_Once)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 5. 创建kafka数据源
// 5.1 Kafka props
Properties properties = new Properties();
//指定Kafka的Broker地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.***.***:9092,192.168.***.***:9092,192.168.***.***:9092");
//指定组ID
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "StateReview8");
//如果没有记录偏移量,第一次从最开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//Kafka的消费者,不自动提交偏移量 (不建议改成false)
// 默认情况下,该参数为true. 会定期把偏移量保存到kafka特殊的topic里面
// 该topic的作用:监控数据的消费情况;重启时优先从save point中恢复,如果没有指定save point,则直接从该topic中恢复(topic和组id名字没有变)
// properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer("StateReview", new SimpleStringSchema(), properties);
DataStreamSource<String> lines = env.addSource(kafkaSource);
// 6 FlinkKafkaStream数据处理
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = line.split(",");
for (int i = 0; i < words.length; i++) {
// if("error".equals(words[i])){
// System.out.println(1/0);
// }
collector.collect(Tuple2.of(words[i], 1));
}
}
});
/**此部分读取Socket数据,只是用来人为出现异常,触发重启策略。验证重启后是否会再次去读之前已读过的数据(Exactly-Once)*/
/*************** start **************/
DataStreamSource<String> socketTextStream = env.socketTextStream("192.168.***.***", 8888);
SingleOutputStreamOperator<String> streamOperator1 = socketTextStream.map(new MapFunction<String, String>() {
@Override
public String map(String word) throws Exception {
if ("error".equals(word)) {
throw new RuntimeException("Throw Exception");
}
return word;
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = wordAndOne.keyBy(0).sum(1);
//7 sink输出
summed.print();
// 8. 执行程序
env.execute("KeyedAndOperatorStateReview");
}
}
注:如果不使用socket处理报错,而是在处理kafka的数据时抛出错误,则重启后会继续读取 "error",造成一直报错重启,直至重启次数用完。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: