自定义多并行DataSource必须继承 RichParallelSourceFunction 类,并重写run()和cancel()方法。
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.io.RandomAccessFile;
// 这里的泛型Tuple2是该source输出的数据类型
public class MyParallelFileSource extends RichParallelSourceFunction<Tuple2<String,String>>{
private String path = "C:\\Users\\Dell\\Desktop\\test";
private Boolean flag = true;
public MyParallelFileSource() {
}
public MyParallelFileSource(String path) {
this.path = path;
}
/**
* run()方法,用于一直运行产生数据
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Tuple2<String, String>> ctx) throws Exception {
//获取当前 subTask 的 index 值
int subtaskIndex = getRuntimeContext().getIndexOfThisSubtask();
//定义用于读取的文件路径
RandomAccessFile randomAccessFile = new RandomAccessFile(path+"/"+subtaskIndex+".txt", "r");
//多并行线程不安全问题。需要加锁。
final Object checkpointLock = ctx.getCheckpointLock();//最好用final修饰
while (flag) { //无限循环,用于一直读取数据
String line = randomAccessFile.readLine();
if (line != null) {
line = new String(line.getBytes("ISO-8859-1"), "UTF-8");
synchronized (checkpointLock){
//将数据发送出去
ctx.collect(Tuple2.of(subtaskIndex+"",line));
}
}else{
Thread.sleep(1000);
}
}
}
/**
* cancel() 方法,用于关闭Source
*/
@Override
public void cancel() {
flag = false;
}
}
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class ReadTxtContentJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, String>> streamSource = env.addSource(new MyParallelFileSource());
streamSource.print();
env.execute("ReadTxtContentJob");
}
}
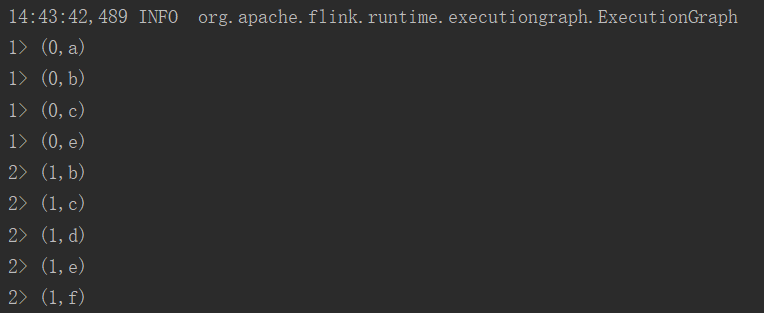
输出结果如下:
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: