一、Flink针对DataStream提供了大量的已经实现的算子。
1、 map:输入一个元素,返回一个元素,中间可以进行清洗转换等操作;
2、 FlatMap:压平,即将嵌套集合转换并平铺成非嵌套集合,可以根据业务需求返回0个、一个或者多个元素;
3、 Filter:过滤函数,对传入的数据进行判断,符合条件的数据才会被留下;
4、 KeyBy:根据指定的Key进行分组,Key相同的数据会进入同一个分区用法:;
(1)DataStream.keyBy("key")指定对象中的具体key字段分组;
(2)DataStream.keyBy(0) 根据Tuple中的第0个元素进行分组。
5、 Reduce:对数据进行聚合操作,结合当前元素和上一次Reduce返回的值进行聚合操作,返回返回一个新的值;
6、 Aggregations:sum(),min(),max()等;
7、 Union:合并多个流,新的流会包含所有流中的数据,但是Union有一个限制,就是所有合并的流类型必须是一致的;
8、 Connect:和Union类似,但是只能连接两个流,两个流的数据类型可以不听,会对两个流中的数据应用不同的处理方法;
9、 coMap和coFlatMap:在ConnectedStream中需要使用这种函数,类似于Map和flatMap.;
10、 Split:根据规则把一个数据流切分为多个流;
11、 Select:和Split配合使用,选择切分后的流;
二、另外,Flink针对DataStream提供了一些数据分区的规则
1、 Randmpartitioning:随机分区DataStream.shuffle();
2、 Rebalancing:对数据集进行再平衡、重分区和消除数据倾斜DataStream.rebalance().;
3、 Rescaling:重新调节和Rebalancing类似,但是Rebalancing会产生全量重分区,而Rescaling不会DataStream.rescale().;
4、 Custompartitioning:自定义分区DataStream.partitionCustom(partitioner,"key")或者;
DataStream.partitionCustom(partitioner,0) .
三、实例
下面针对部分transformation算子进行实例演示
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class MapAndKeyByReview {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.137.189", 8888);
/**
* 1. flatMap 进行切分压平
* input: line 一行字符串,包含一个或多个单词
* output: words, 将line切分成单词后一个个返回
*/
SingleOutputStreamOperator<Tuple2<String, Integer>> words = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = line.split(",");
for (int i = 0; i < words.length; i++) {
//将每个单词与 1 组合,形成一个元组
Tuple2<String, Integer> tp = Tuple2.of(words[i], words[i].length());
//将组成的Tuple放入到 Collector 集合,并输出
collector.collect(tp);
}
}
});
/**
* 2. filter方法过滤掉长度为3及以下的word
*/
SingleOutputStreamOperator<Tuple2<String, Integer>> filtered = words.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> tp2) throws Exception {
if(tp2.f1>3){
return true; // 返回值为ture的Tupl2才会返回
}
return false;
}
});
/**
* 当Tuple2和1组合成一个Tuple3,方便统计次数/个数
*/
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> mapped =
filtered.map(new MapFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>>() {
@Override
public Tuple3<String, Integer, Integer> map(Tuple2<String, Integer> tp2) throws Exception {
return Tuple3.of(tp2.f0,tp2.f1,1);
}});
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> sumed = mapped.keyBy(0).sum(2);
sumed.print();
env.execute("MapAndKeyByReview");
}
}
socket输入如下:
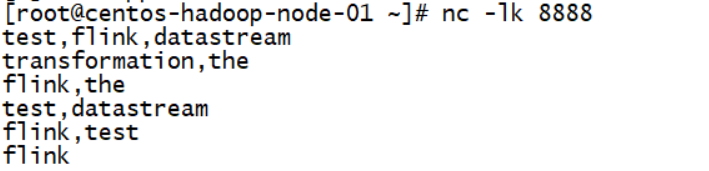
输出结果如下:
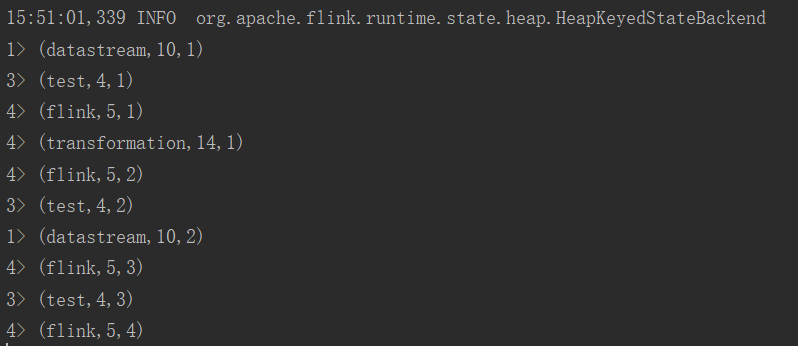
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: