功能就是负责把 Flink 处理后的数据输出到外部系统中。
一、Flink针对DataStream提供了大量的已经实现的数据下沉(sink)方式,具体有:
1、 writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取;
2、 print()/printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中;
3、 自定义输出:addSink可以实现把数据输出到第三方存储介质中;
Flink通过内置的Connector和Apache Bahir组件提供了对应sink的支持。
详细参考:https://blog.csdn.net/zhuzuwei/article/details/107137295
二、Sink组件容错性保证
| Sink | 语义保证 | 备注 |
| HDFS | Exactly-once | |
| Elasticsearch | At-least-once | |
| Kafka Produce | At-least-once / At-most-once | Kafka 0.9和0.10提供At-least-once Kafka 0.11提供Exactly_once |
| File | At-least-once | |
| Redis | At-least-once |
三、实例演示
之前都是print()的sink方式,此处演示sink到Txt文件和Redis数据库。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class AddSinkReivew {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.***.***", 8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> words = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(",");
for (int i = 0; i < words.length; i++) {
collector.collect(Tuple2.of(words[i], 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = words.keyBy(0).sum(1);
summed.print();
summed.writeAsText("C:\\Users\\Dell\\Desktop\\flinkTest\\sinkout1.txt", FileSystem.WriteMode.OVERWRITE);
SingleOutputStreamOperator<Tuple3<String,String, Integer>> words2 = lines.flatMap(new FlatMapFunction<String, Tuple3<String,String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple3<String,String, Integer>> collector) throws Exception {
String[] words = s.split(",");
for (int i = 0; i < words.length; i++) {
collector.collect(Tuple3.of("wordscount",words[i], 1));
}
}
});
SingleOutputStreamOperator<Tuple3<String,String, Integer>> summed2 = words2.keyBy(1).sum(2);
String configPath = "C:\\Users\\Dell\\Desktop\\flinkTest\\config.txt";
ParameterTool parameters = ParameterTool.fromPropertiesFile(configPath);
//设置全局参数
env.getConfig().setGlobalJobParameters(parameters);
summed2.addSink(new MyRedisSinkFunction());
env.execute("AddSinkReivew");
}
}
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import redis.clients.jedis.Jedis;
public class MyRedisSinkFunction extends RichSinkFunction<Tuple3<String, String, Integer>>{
private transient Jedis jedis;
@Override
public void open(Configuration config) {
ParameterTool parameters = (ParameterTool)getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
String host = parameters.getRequired("redis.host");
String password = parameters.get("redis.password", "");
Integer port = parameters.getInt("redis.port", 6379);
Integer timeout = parameters.getInt("redis.timeout", 5000);
Integer db = parameters.getInt("redis.db", 0);
jedis = new Jedis(host, port, timeout);
jedis.auth(password);
jedis.select(db);
}
@Override
public void invoke(Tuple3<String, String, Integer> value, Context context) throws Exception {
if (!jedis.isConnected()) {
jedis.connect();
}
//保存
jedis.hset(value.f0, value.f1, String.valueOf(value.f2));
}
@Override
public void close() throws Exception {
jedis.close();
}
}
WriteAsText中指定的sinkout1.txt并不是一个文件,而是会生成同名文件夹。里面有4个文件对应并行度,保存不同subTask sink的结果。
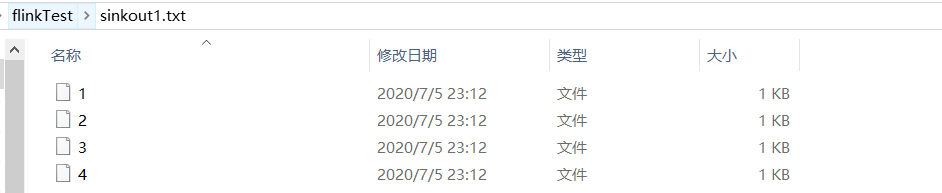
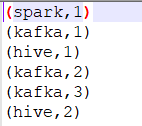
单个文件夹内保存的结果如下:
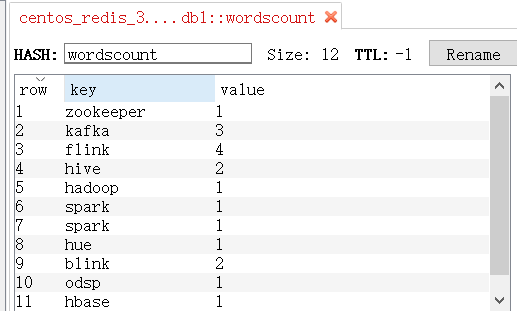
Redis中也有了sink的结果
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: