文章目录
- 一. 一致性检查点(checkpoint)
- 二. 从检查点恢复状态
- 三. Flink检查点算法
- 四. 保存点(Savepoints)
- 五.检查点和重启策略配置
- 六. 状态一致性
-
- 6.1 概述
- 6.2 分类
- 6.3 一致性检查点(Checkpoints)
- 七. Flink+Kafka 端到端状态一致性的保证
- 参考:
一. 一致性检查点(checkpoint)
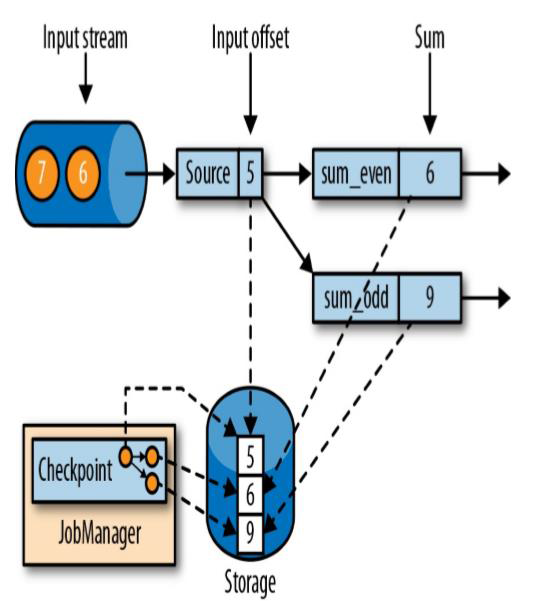
1、 Flink故障恢复机制的核心,就是应用状态的一致性检查点;
2、 有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);
1)这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
5这个数据虽然进了奇数流但是偶数流也应该做快照,因为属于同一个相同数据,只是没有被他处理)
2)(这里根据奇偶性分流,偶数流求偶数和,奇数流求奇数和,5这里明显已经被sum_odd(1+3+5)处理了,且sum_even不需要处理该数据,因为前面已经判断该数据不需要到sum_even流,相当于所有任务都已经处理完source的数据5了。)
3、 在JobManager中也有个Chechpoint的指针,指向了仓库的状态快照的一个拓扑图,为以后的数据故障恢复做准备;
二. 从检查点恢复状态
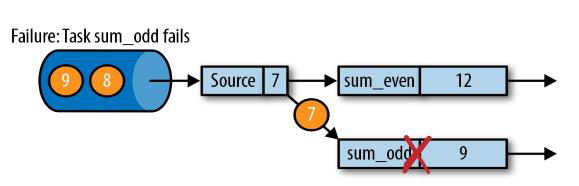
在执行流应用程序期间,Flink 会定期保存状态的一致检查点
如果发生故障, Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程
(如图中所示,7这个数据被source读到了,准备传给奇数流时,奇数流宕机了,数据传输发生中断)
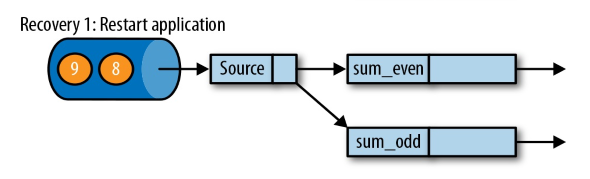
遇到故障之后,第一步就是重启应用
(重启后,起初流都是空的)

第二步是从 checkpoint 中读取状态,将状态重置
(读取在远程仓库(Storage,这里的仓库指状态后端保存数据指定的三种方式之一)保存的状态)
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
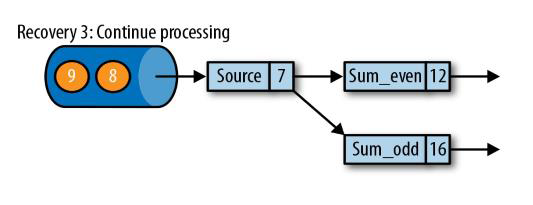
第三步:开始消费并处理检查点到发生故障之间的所有数据
这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置
(这里要求source源也能记录状态,回退到读取数据7的状态,kafka有相应的偏移指针能完成该操作)
三. Flink检查点算法
概述
checkpoint和Watermark一样,都会以广播的形式告诉所有下游。
1、 一种简单的想法;
1)暂停应用,保存状态到检查点,再重新恢复应用(当然Flink 不是采用这种简单粗暴的方式)
2、 Flink的改进实现;
1)基于Chandy-Lamport算法的分布式快照
2)将检查点的保存和数据处理分离开,不暂停整个应用
(就是每个任务单独拍摄自己的快照到内存,之后再到jobManager整合)
3、 检查点分界线(CheckpointBarrier);
1)Flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来把一条流上数据按照不同的检查点分开
2)分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中
具体讲解
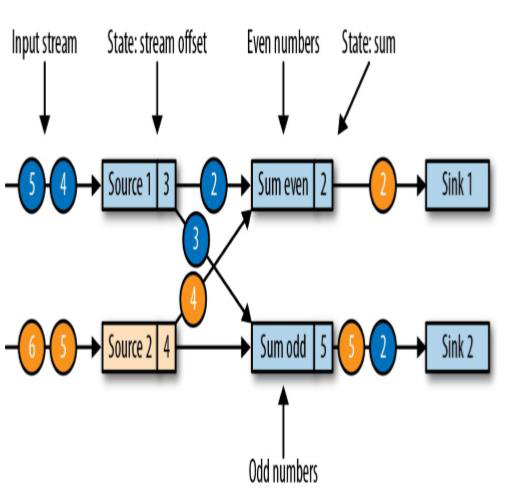
1、 现在是一个有两个输入流的应用程序,用并行的两个Source任务来读取;
2、 两条自然数数据流,蓝色数据流已经输出完蓝3了,黄色数据流输出完黄4了;
3、 在Souce端Source1接收到了数据蓝3正在往下游发向一个数据蓝2和蓝3;Source2接受到了数据黄4,且往下游发送数据黄4;
4、 偶数流已经处理完黄2所以后面显示为2,奇数流处理完蓝1和黄1黄3所以为5,并分别往下游发送每次聚合后的结果给Sink;
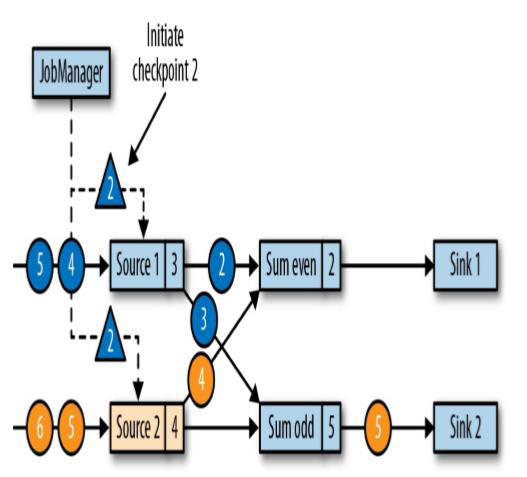
JobManager 会向每个 source 任务发送一条带有新检查点 ID 的消息,通过这种方式来启动检查点
(这个带有新检查点ID的东西为barrier,由图中三角型表示,数值2只是ID)
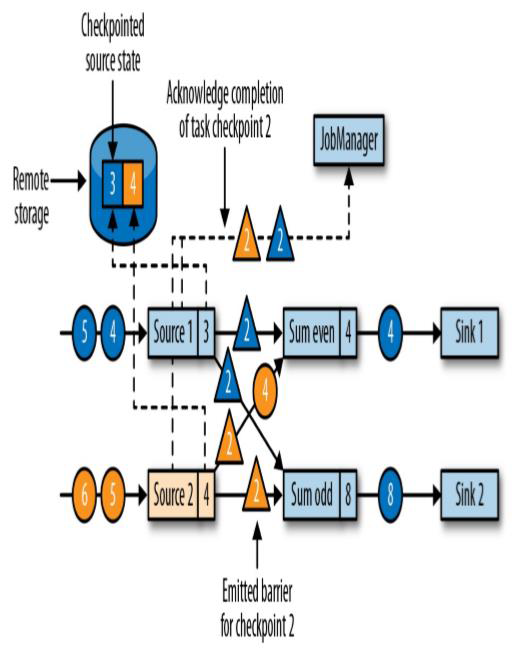
数据源将它们的状态写入检查点,并发出一个检查点barrier
状态后端在状态存入检查点之后,会返回通知给source任务,source任务就会向JobManager确认检查点完成
上图,在Source端接受到barrier后,将自己此身的3 和 4 的数据的状态写入检查点,且向JobManager发送checkpoint成功的消息,然后向下游分别发出一个检查点 barrier
可以看出在Source接受barrier时,数据流也在不断的处理,不会进行中断
此时的偶数流已经处理完蓝2变成了4,但是还没处理到黄4,只是下游sink发送了一个数据4,而奇数流已经处理完蓝3变成了8(黄1+蓝1+黄3+蓝3),并向下游sink发送了8
此时检查点barrier都还未到Sum_odd奇数流和Sum_even偶数流
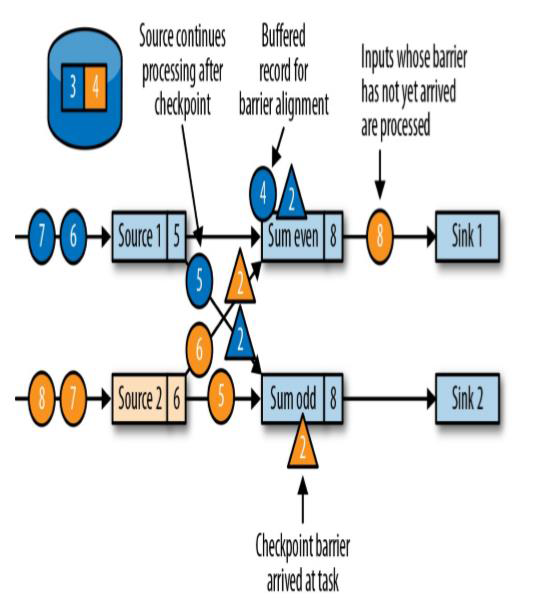
分界线对齐:barrier向下游传递,sum任务会等待所有输入分区的barrier到达
对于barrier已经达到的分区,继续到达的数据会被缓存
而barrier尚未到达的分区,数据会被正常处理
此时蓝色流的barrier先一步抵达了偶数流,黄色的barrier还未到,但是因为数据的不中断一直处理,此时的先到的蓝色的barrier会将此时的偶数流的数据4进行缓存处理,流接着处理接下来的数据等待着黄色的barrier的到来,而黄色barrier之前的数据将会对缓存的数据相加
这次处理的总结:分界线对齐:barrier 向下游传递,sum 任务会等待所有输入分区的 barrier 到达,对于barrier已经到达的分区,继续到达的数据会被缓存。而barrier尚未到达的分区,数据会被正常处理
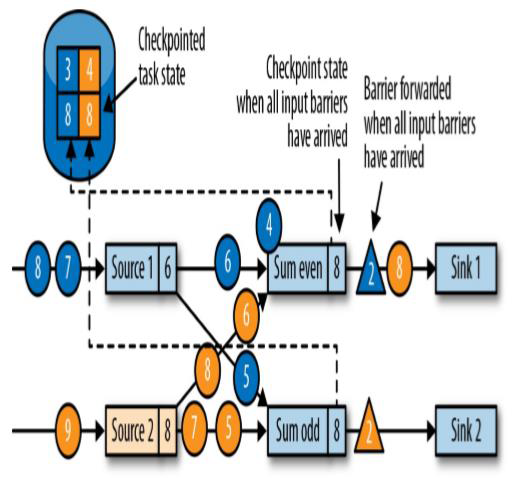
当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发
当蓝色的barrier和黄色的barrier(所有分区的)都到达后,进行状态保存到远程仓库,然后对JobManager发送消息,说自己的检查点保存完毕了
此时的偶数流和奇数流都为8
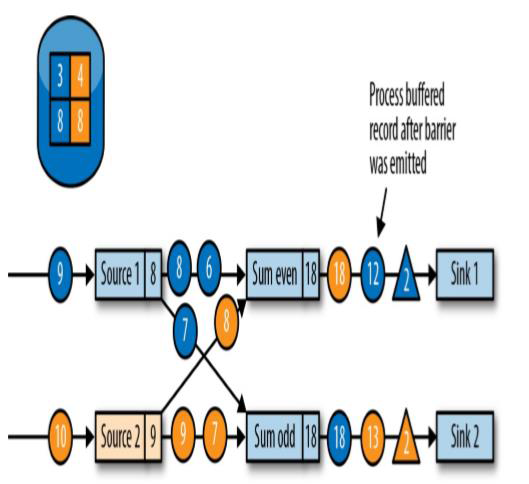
向下游转发检查点 barrier 后,任务继续正常的数据处理
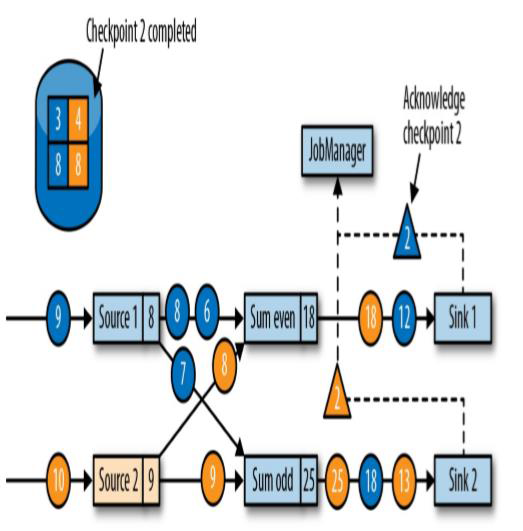
Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕
当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了
四. 保存点(Savepoints)
CheckPoint为自动保存,SavePoint为手动保存
1、 Flink还提供了可以自定义的镜像保存功能,就是保存点(savepoints);
2、 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点;
3、 Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地触发创建操作;
4、 保存点是一个强大的功能除了故障恢复外,保存点可以用于:有计划的手动备份、更新应用程序、版本迁移、暂停和重启程序,等等;
五.检查点和重启策略配置
package org.flink.state;
import org.flink.beans.SensorReading;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 只是甲
* @date 2021-09-17
* @remark 状态后端测试
*/
public class StateTest4_FaultTolerance {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 状态后端配置
env.setStateBackend( new MemoryStateBackend());
env.setStateBackend( new FsStateBackend(""));
env.setStateBackend( new RocksDBStateBackend(""));
// 2. 检查点配置
env.enableCheckpointing(300);
// 高级选项
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(100L);
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
// 3. 重启策略配置
// 固定延迟重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000L));
// 失败率重启
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10), Time.minutes(1)));
// socket文本流
DataStream<String> inputStream = env.socketTextStream("10.31.1.122", 7777);
// 转换成SensorReading类型
DataStream<SensorReading> dataStream = inputStream.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
});
dataStream.print();
env.execute();
}
}
六. 状态一致性
6.1 概述
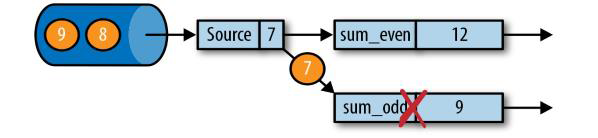
有状态的流处理,内部每个算子任务都可以有自己的状态
对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。
一条数据不应该丢失,也不应该重复计算
在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的。
6.2 分类
Flink的一个重大价值在于,它既保证了exactly-once,也具有低延迟和高吞吐的处理能力。
1、 AT-MOST-ONCE(最多一次)当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据At-most-once语义的含义是最多处理一次事件;
这其实是没有正确性保障的委婉说法——故障发生之后,计算结果可能丢失。类似的比如网络协议的udp。
2、 AT-LEAST-ONCE(至少一次)在大多数的真实应用场景,我们希望不丢失事件这种类型的保障称为at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次;
这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
3、 EXACTLY-ONCE(精确一次)恰好处理一次是最严格的保证,也是最难实现的恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次;
这指的是系统保证在发生故障后得到的计数结果与正确值一致。
6.3 一致性检查点(Checkpoints)
Flink使用了一种轻量级快照机制——检查点(checkpoint)来保证exactly-once语义
有状态流应用的一致检查点,其实就是:所有任务的状态,在某个时间点的一份备份(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时间。
应用状态的一致检查点,是Flink故障恢复机制的核心
端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如Kafka)和输出到持久化系统
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性
整个端到端的一致性级别取决于所有组件中一致性最弱的组件
端到端 exactly-once
1、 内部保证——checkpoint;
2、 source端——可重设数据的读取位置;
3、 sink端——从故障恢复时,数据不会重复写入外部系统;
1)幂等写入
2)事务写入
幂等写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
(中间可能会存在不正确的情况,只能保证最后结果正确。比如5=>10=>15=>5=>10=>15,虽然最后是恢复到了15,但是中间有个恢复的过程,如果这个过程能够被读取,就会出问题。)
事务写入
1、 事务(Transaction);
1)应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤销
2)具有原子性:一个事务中的一系列的操作要么全部成功,要么一个都不做
2、 实现思想;
1)构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才把所有对应的结果写入sink系统中。
3、 实现方式;
1)预写日志
2)两阶段提交
预写日志(Write-Ahead-Log,WAL)
把结果数据先当成状态保存,然后在收到checkpoint完成的通知时,一次性写入sink系统
简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么sink系统,都能用这种方式一批搞定
DataStream API提供了一个模版类:GenericWriteAheadSink,来实现这种事务性sink
两阶段提交(Two-Phase-Commit,2PC)
对于每个checkpoint,sink任务会启动一个事务,并将接下来所有接收到的数据添加到事务里
然后将这些数据写入外部sink系统,但不提交它们——这时只是"预提交"
这种方式真正实现了exactly-once,它需要一个提供事务支持的外部sink系统。Flink提供了TwoPhaseCommitSinkFunction接口
不同Source和Sink的一致性保证
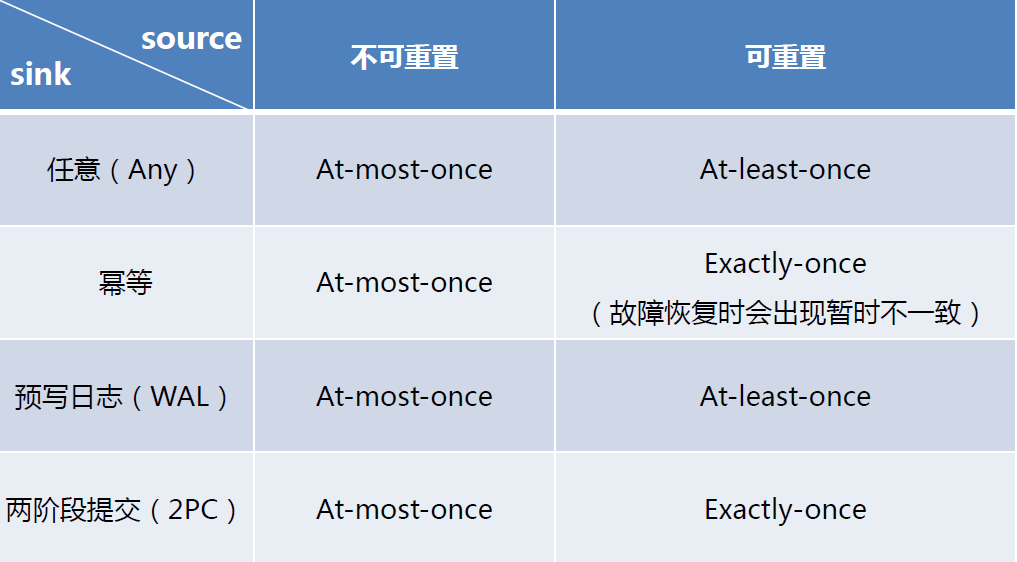
七. Flink+Kafka 端到端状态一致性的保证
内部——利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
source——kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重制偏移量,重新消费数据,保证一致性
sink——kafka producer作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction
Exactly-once 两阶段提交
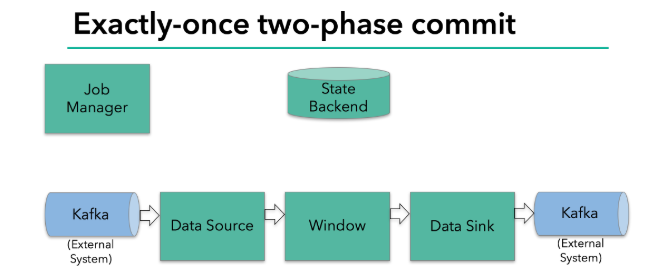
JobManager 协调各个 TaskManager 进行 checkpoint 存储
checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存
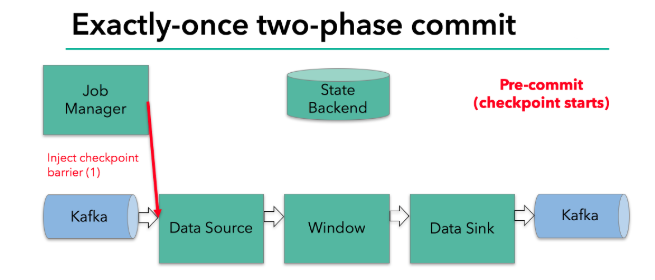
当checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流
barrier会在算子间传递下去
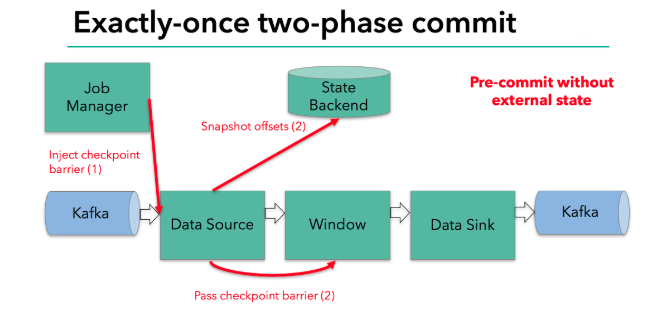
每个算子会对当前的状态做个快照,保存到状态后端
checkpoint 机制可以保证内部的状态一致性
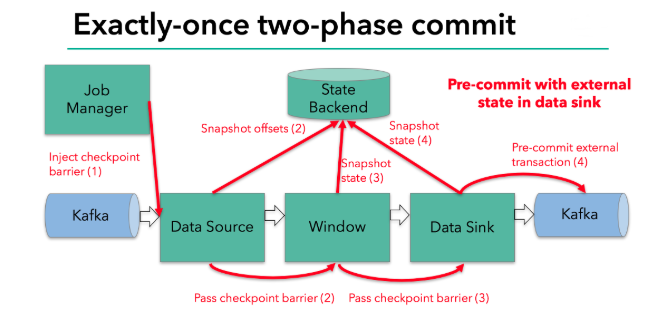
每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里
sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务;遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务
(barrier之前的数据还是在之前的事务中没关闭事务,遇到barrier后的数据另外新开启一个事务)
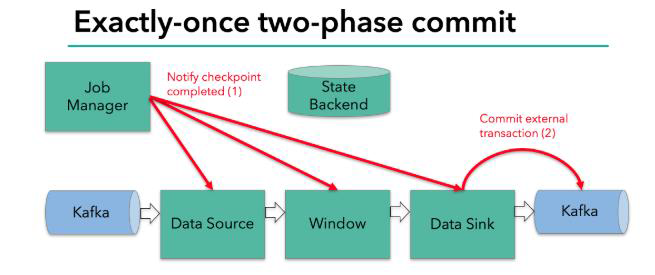
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成
sink 任务收到确认通知,正式提交之前的事务,kafka 中未确认数据改为“已确认”
Exactly-once 两阶段提交步骤总结
1、 第一条数据来了之后,开启一个kafka的事务(transaction),正常写入kafka分区日志但标记为未提交,这就是“预提交”;
2、 jobmanager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知jobmanager;
3、 sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并;
开启下一阶段的事务,用于提交下个检查点的数据
4、 jobmanager收到所有任务的通知,发出确认信息,表示checkpoint完成;
5、 sink任务收到jobmanager的确认信息,正式提交这段时间的数据;
6、 外部kafka关闭事务,提交的数据可以正常消费了;
参考:
1、 https://www.bilibili.com/video/BV1qy4y1q728;
2. https://ashiamd.github.io/docsify-notes/#/study/BigData/Flink/%E5%B0%9A%E7%A1%85%E8%B0%B7Flink%E5%85%A5%E9%97%A8%E5%88%B0%E5%AE%9E%E6%88%98-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0?id=_9-processfunction-api%e5%ba%95%e5%b1%82api
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: