文章目录
- 一. 代码准备
- 二.运行flink程序
- 参考:
一. 代码准备
org.flink.beans.SensorReading
package org.flink.beans;
/**
* @author 只是甲
* @date 2021-08-30
* @remark 传感器温度读数的数据类型
*/
public class SensorReading {
// 属性:id,时间戳,温度值
private String id;
private Long timestamp;
private Double temperature;
public SensorReading() {
}
public SensorReading(String id, Long timestamp, Double temperature) {
this.id = id;
this.timestamp = timestamp;
this.temperature = temperature;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getTimestamp() {
return timestamp;
}
public void setTimestamp(Long timestamp) {
this.timestamp = timestamp;
}
public Double getTemperature() {
return temperature;
}
public void setTemperature(Double temperature) {
this.temperature = temperature;
}
@Override
public String toString() {
return "SensorReading{" +
"id='" + id + '\'' +
", timestamp=" + timestamp +
", temperature=" + temperature +
'}';
}
}
org.example.SourceTest1_Collection
package org.example;
/**
* @author 只是甲
* @date 2021-08-30
* @remark Flink数据源之从集合读取数据
*/
import org.flink.beans.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class SourceTest1_Collection {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从集合中读取数据
DataStream<SensorReading> dataStream = env.fromCollection(Arrays.asList(
new SensorReading("sensor_1", 1547718199L, 35.8),
new SensorReading("sensor_6", 1547718201L, 15.4),
new SensorReading("sensor_7", 1547718202L, 6.7),
new SensorReading("sensor_10", 1547718205L, 38.1)
));
//DataStream<Integer> integerDataStream = env.fromElements(1, 2, 4, 67, 189);
//打印输出
dataStream.print("data");
//integerDataStream.print();
//执行
env.execute();
}
}
二.运行flink程序
我这边是搭建了CDH 6.3环境,所以flink程序是提交到yarn集群来执行。
flink run -m yarn-cluster -c org.example.SourceTest1_Collection FlinkStudy-1.0-SNAPSHOT.jar
如下截图可以看到,任务执行成功了,但是没有输出
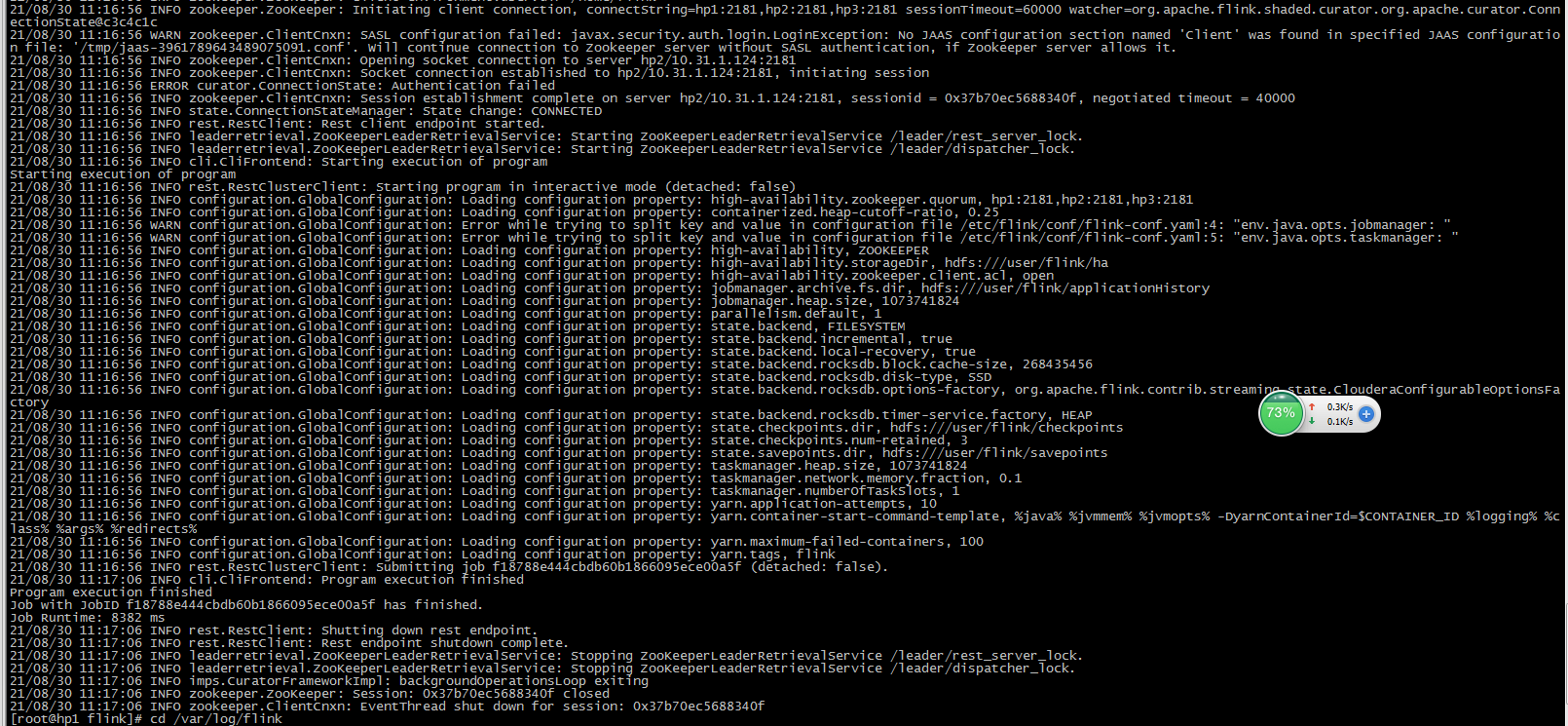
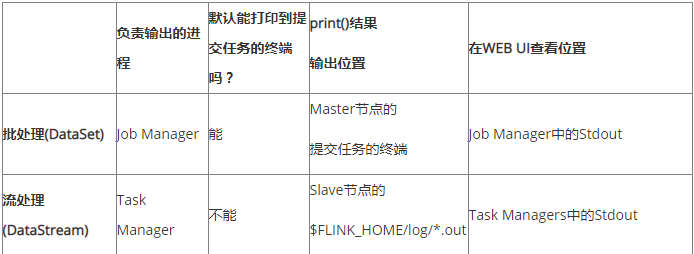
查询资料得知,DataStream是Task Manager负责输出的,不会输出到终端。
参考:
1、 https://www.bilibili.com/video/BV1qy4y1q728;
2. https://ashiamd.github.io/docsify-notes/#/study/BigData/Flink/%E5%B0%9A%E7%A1%85%E8%B0%B7Flink%E5%85%A5%E9%97%A8%E5%88%B0%E5%AE%9E%E6%88%98-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0?id=_521-%e4%bb%8e%e9%9b%86%e5%90%88%e8%af%bb%e5%8f%96%e6%95%b0%e6%8d%ae
3、 https://www.pianshen.com/article/26011976902/;
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: