文章目录
- 一. Standalone模式
-
- 1.1 Standalone模式概述
- 1.2 standalone模式任务提交
-
- 1.2.1 Web UI提交Job
- 1.2.2 命令行提交job
- 二.yarn模式
-
- 2.1 Flink on yarn
-
- 2.1.1 Session-Cluster模式
- 2.1.2 Per-Job-Cluster模式
- 2.2 Session Cluster
- 2.3 Per-Job-Cluster
- 三. Kubernetes部署
- 参考:
一. Standalone模式
1.1 Standalone模式概述
1、 Flink中每一个TaskManager都是一个JVM进程,它可能会在独立的线程上执行一个或多个subtask;
2、 为了控制一个TaskManager能接收多少个task,TaskManager通过taskslot来进行控制(一个TaskManager至少有一个slot);
3、 每个taskslot表示TaskManager拥有资源的一个固定大小的子集假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot(注:这里不会涉及CPU的隔离,slot仅仅用来隔离task的受管理内存);
4、 可以通过调整taskslot的数量去自定义subtask之间的隔离方式如一个TaskManager一个slot时,那么每个taskgroup运行在独立的JVM中而当一个TaskManager多个slot时,多个subtask可以共同享有一个JVM,而在同一个JVM进程中的task将共享TCP连接和心跳消息,也可能共享数据集和数据结构,从而减少每个task的负载;
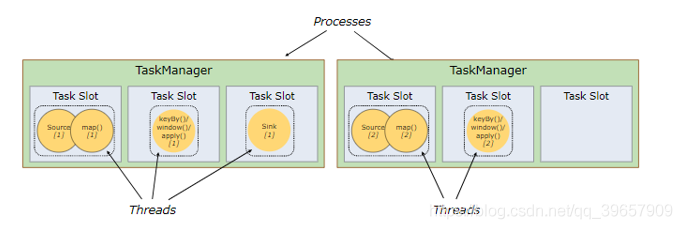
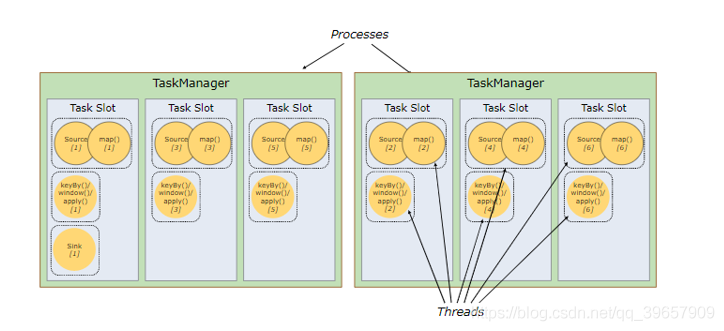
1、 默认情况下,Flink允许子任务共享slot,即使它们是不同任务的子任务(前提是它们来自同一个job)这样的结果是,一个slot可以保存作业的整个管道;
2、 TaskSlot是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度parallelism是动态概念,即TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置;
举例:如果总共有3个TaskManager,每一个TaskManager中分配了3个TaskSlot,也就是每个TaskManager可以接收3个task,这样我们总共可以接收9个TaskSot。但是如果我们设置parallelism.default=1,那么当程序运行时9个TaskSlot将只有1个运行,8个都会处于空闲状态,所以要学会合理设置并行度!具体图解如下:
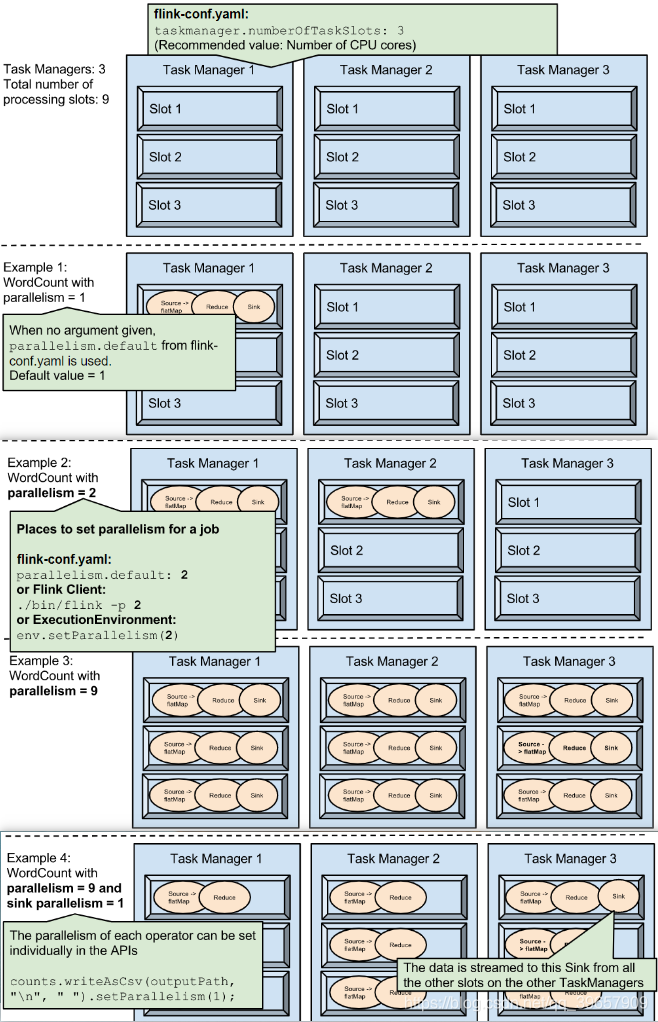
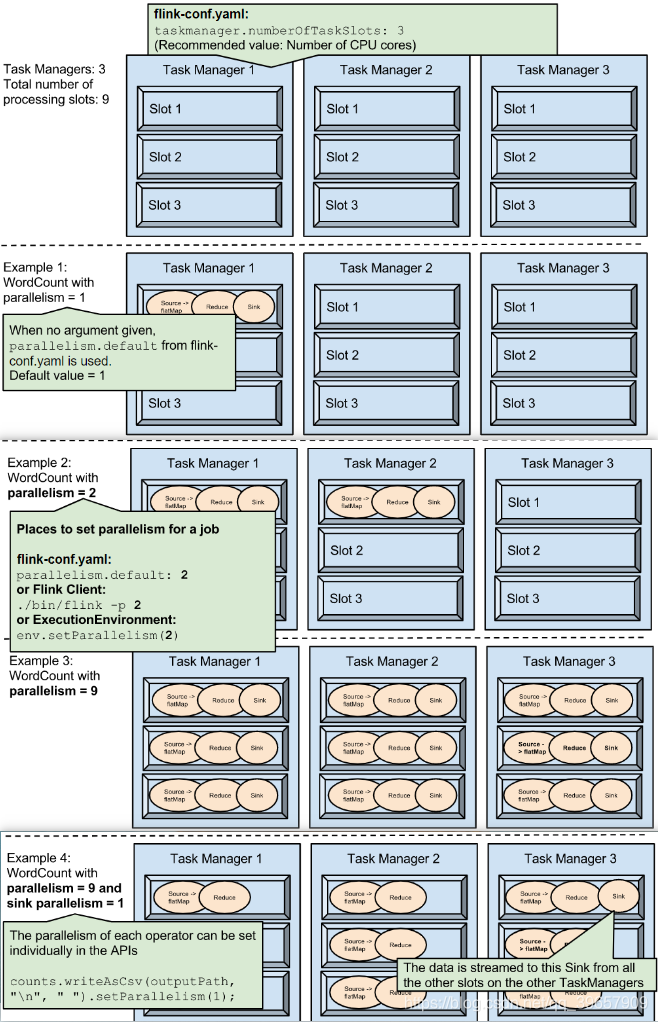
conf/flink-conf.yaml配置文件中
taskmanager.numberOfTaskSlots
parallelism.default
默认值
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
注:Flink存储State用的是堆外内存,所以web UI里JVM Heap Size和Flink Managed MEM是两个分开的值。
1.2 standalone模式任务提交
1.2.1 Web UI提交Job
启动Flink后,可以在Web UI的Submit New Job提交jar包,然后指定Job参数。
1、 EntryClass;
程序的入口,指定入口类(类的全限制名)
2、 ProgramArguments;
程序启动参数,例如–host localhost --port 7777
3、 Parallelism;
设置Job并行度。
Ps:并行度优先级(从上到下优先级递减)
1)代码中算子setParallelism()
2)ExecutionEnvironment env.setMaxParallelism()
3)设置的Job并行度
4)集群conf配置文件中的parallelism.default
ps:socket等特殊的IO操作,本身不能并行处理,并行度只能是1
4、 SavepointPath;
savepoint是通过checkpoint机制为streaming job创建的一致性快照,比如数据源offset,状态等。
(savepoint可以理解为手动备份,而checkpoint为自动备份)
ps:提交job要注意分配的slot总数是否足够使用,如果slot总数不够,那么job执行失败。(资源不够调度)
1.2.2 命令行提交job
1、 查看已提交的所有job;
如果有运行的job,此处可以查看到具体的job id
D:\flink\flink-1.9.0\bin>flink list
log4j:WARN No appenders could be found for logger (org.apache.flink.client.cli.CliFrontend).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Waiting for response...
No running jobs.
No scheduled jobs.
1、 提交job;
-c指定入口类
-p指定job的并行度
bin/flink run -c <入口类> -p <并行度> <jar包路径> <启动参数>
举例:
$ bin/flink run -c wc.StreamWordCount -p 3 /tmp/Flink_Tutorial-1.0-SNAPSHOT.jar --host localhost --port 7777
Job has been submitted with JobID 33a5d1f00688a362837830f0b85fd75e
1、 取消job;
bin/flink cancel <Job的ID>
$ bin/flink cancel 30d9dda946a170484d55e41358973942
Cancelling job 30d9dda946a170484d55e41358973942.
Cancelled job 30d9dda946a170484d55e41358973942.
注:Total Task Slots只要不小于Job中Parallelism最大值即可。
eg:这里我配置文件设置taskmanager.numberOfTaskSlots: 4,实际Job运行时总Tasks显示9,但是里面具体4个任务步骤分别需求(1,3,3,2)数量的Tasks,4>3,满足最大的Parallelism即可运行成功。
二.yarn模式
以Yarn模式部署Flink任务时,要求Flink是有 Hadoop 支持的版本,Hadoop 环境需要保证版本在 2.2 以上,并且集群中安装有 HDFS 服务。
2.1 Flink on yarn
Flink提供了两种在yarn上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式。
2.1.1 Session-Cluster模式
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
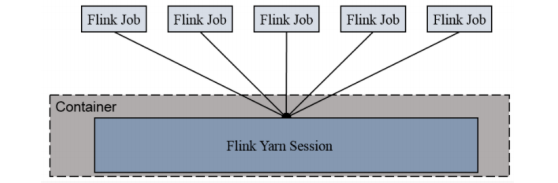
在yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
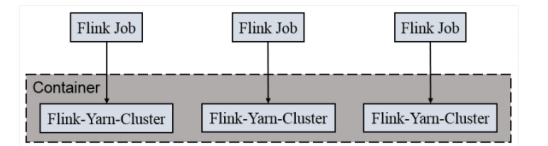
2.1.2 Per-Job-Cluster模式
一个Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
2.2 Session Cluster
1、 启动hadoop集群(略);
2、 启动yarn-session;
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
1)-n(–container):TaskManager的数量。
2)-s(–slots):每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
3)-jm:JobManager的内存(单位MB)。
4)-tm:每个taskmanager的内存(单位MB)。
5)-nm:yarn 的appName(现在yarn的ui上的名字)。
6)-d:后台执行。
3、 执行任务;
./flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
4、 去yarn控制台查看任务状态;
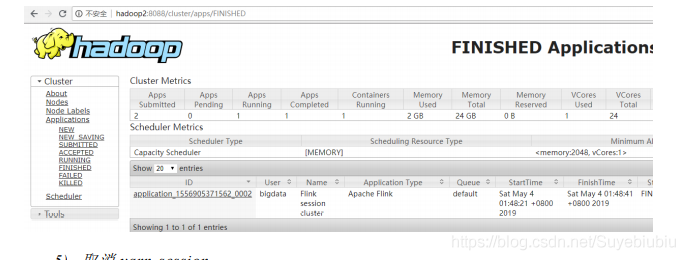
5、 取消yarn-session;
yarn application --kill application_1577588252906_0001
2.3 Per-Job-Cluster
1、 启动hadoop集群(略);
2、 不启动yarn-session,直接执行job;
/flink run –m yarn-cluster -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar --host lcoalhost –port 7777
三. Kubernetes部署
容器化部署时目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。
1、 搭建Kubernetes集群(略);
2、 配置各组件的yaml文件;
在k8s上构建Flink Session Cluster,需要将Flink集群的组件对应的docker镜像分别在k8s上启动,包括JobManager、TaskManager、JobManagerService三个镜像服务。每个镜像服务都可以从中央镜像仓库中获取。
3、 启动FlinkSessionCluster;
// 启动jobmanager-service 服务
kubectl create -f jobmanager-service.yaml
// 启动jobmanager-deployment服务
kubectl create -f jobmanager-deployment.yaml
// 启动taskmanager-deployment服务
kubectl create -f taskmanager-deployment.yaml
1、 访问FlinkUI页面;
集群启动后,就可以通过JobManagerServicers中配置的WebUI端口,用浏览器输入以下url来访问Flink UI页面了:
http://{JobManagerHost:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy
参考:
- https://ashiamd.github.io/docsify-notes/#/study/BigData/Flink/%E5%B0%9A%E7%A1%85%E8%B0%B7Flink%E5%85%A5%E9%97%A8%E5%88%B0%E5%AE%9E%E6%88%98-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0?id=_3-flink%e9%83%a8%e7%bd%b2
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: