学习笔记:数据结构与算法(二十一):散列表-哈希表
- 定义
- 散列表的查找步骤
- 构造基本原则
- 散列地址方法
-
- 直接定址法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
- 随机数法
- 选择
- 处理散列冲突
-
- 开放定址法
- 再散列函数法
- 链地址法
- 公共溢出区法
- 代码实现
在a[]中查找key关键字的记录:
- 顺序表查找:按顺序查找
- 有序表查找:二分法查找
- 散列表查找:?
记录的存储位置 = f(关键字)
定义
散列技术是在记录的存储位置和它关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)
这种对应关系f称为散列函数,又称为哈希Hash函数,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间成为散列表或哈希表(Hash Table)。
散列表的查找步骤
1、 当存储记录时,通过散列函数计算出记录的散列地址;
2、 当查找记录时,通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录;
特点:适合一对一的查找
缺点:不适合关键字重复或者范围的查找
构造基本原则
好的散列函数需要遵守两个基本规则
1、 计算简单;
2、 分布均匀(散列地址);
散列地址方法
有这样几种方法
直接定址法
取关键字的某个线性函数值为散列地址,即f(key) = a * key + b
- 例如f(key) = key
- 例如f(key) = key - 1980
优点:简单,均匀
缺点:适合key少,并且提前知道分布
数字分析法
适合处理关键字位数比较大的情况,可以采用抽取的方法选做关键字。
平方取中法
将关键字平方之后取中间若干位数字作为散列地址
折叠法
将关键字从左到右分割成位数相等的几部分,然后将这几部分叠加求和,并按散列表表长取后几位作为散列地址。
例如987 654 321 000
叠加之后为1962,那可以取962为地址。
特点:实现不需要知道关键字的分布,适合位数多的情况
除留余数法
最常用的构造散列函数方法,对于散列表长为m的散列函数计算公式为:

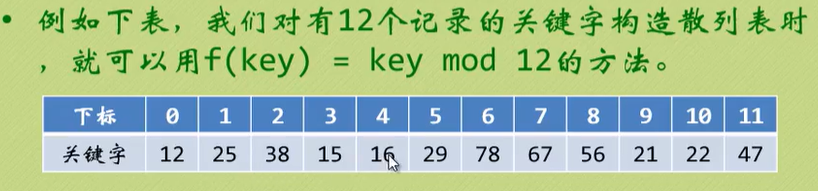
此时,注意p的选择,避免过多的冲突。
随机数法
选择一个随机数,取关键字的随机函数值作为他的散列地址

选择
在这里选择散列函数时,应该根据不同的情况进行选择,一般考虑以下几点
- 计算散列地址所需要的时间
- 关键字的长度
- 散列表的大小
- 关键字的分布情况
- 记录查找的频率
处理散列冲突
开放定址法
一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,总能找到空的地址。
公式为:
fi(key) = (f(key) + di) MOD m (di = 1,2,…,m - 1)
例如
在寻找48的时候,d从1到6才找到
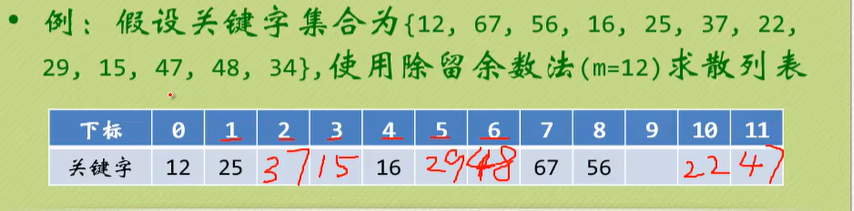
缺点:比较盲目。
->改进1,修改di的取值方式,例如使用平方运算来尽量解决堆积问题
fi(key) = (f(key) + di) MOD m (di = 12, -12, 22, - 22…, q2, - q2, q<=m/2)
->改进2,在冲突时,对于位移量di采用随机函数计算得到,称之为随机探测法
再散列函数法
RHi是准备的各种散列函数,如果发生冲突,就再散列一次。
fi(key ) = RHi(key) (i = 1,2,3,…k)
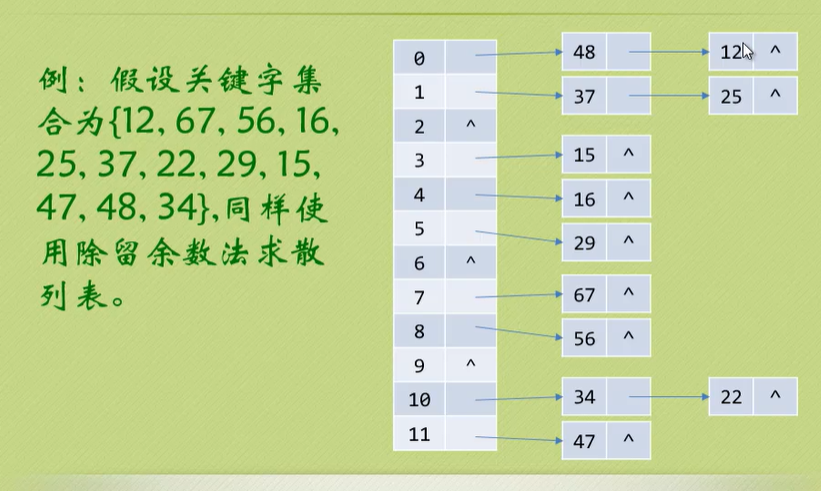
链地址法
在冲突的地方继续开拓空间,采用链表的方式
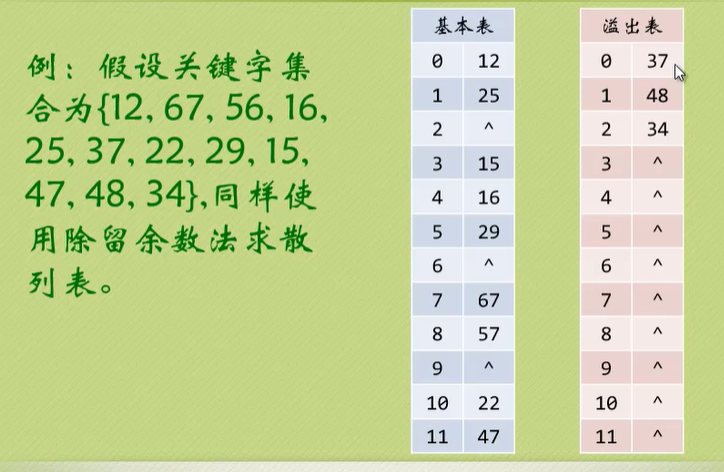
公共溢出区法
用两个表,一个基本的,一个溢出表。如果找到散列地址冲突了,就放在溢出表里。按溢出顺序排放。
代码实现
#define HASHSIZE 12
#define NULLKEY -32768
typedef struct
{
int *elem; //数据元素的基址,动态分配数组
int count;
}HashTable;
int InitHashTable(HashTable *H)
{
H->count = HASHSIZE;
H->elem = (int *) malloc(HASHSIZE * sizeof(int));
if(!H->elem)
{
return -1;
}
for( int i =0;i< HASHSIZE; i++)
H->elem[i] = NULLKEY;
}
//使用除留余数法
int Hash(int key)
{
return key % HASHSIZE;
}
//插入关键字到散列表
void InsertHash(HashTable *T, int key)
{
int addr;
addr = Hash(key);
while(H->elem[addr] != NULLKEY) //产生冲突
{
addr = (addr + 1)% HASHSIZE; //开放定址法的线性探测
}
H->elem[addr] = key;
}
//在散列表里查找关键字
int SearchHash(HashTable *T, int key, int *addr)
{
*addr = Hash(key);
while(H.elem[*addr]!= key) //发生冲突,查找下一位
{
*addr = (*addr + 1) % HASHSIZE;
if(H.elem[*addr] == NULLKEY || *addr == Hash(key))
return -1; //没找到或者回到原点
}
return 0;
}
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: