摘要
并查集解决的就是快速查找和连接的问题,所以就有在连接(即合并)上的优化和在查找上的优化。不管哪个方面的优化,核心就是降低树的高度,就能减少合并时调整的路径,查找时经过的路径,时间复杂度也就随之降低。
上期文章中谈到,并查集能解决快速查询和连接的问题,并根据查找优先或者合并优先两个不同的方向,介绍它的实现方式,核心思想就是保证比较高效率的查找和连接。并且并查集是基于数组来实现。
但是在合并(Union)的过程中,可能会出现树不平衡的情况,甚至退化为链表,比如下图例子:
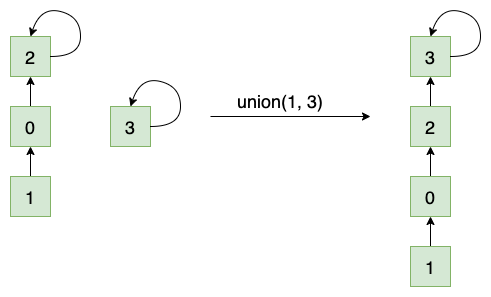
当元素1所在的集合合并到元素3所在的集合后,集合就退化为链表。这种情况就失去了并查集的特性了,怎样对并查集进行优化呢?
优化一:基于 size
第一种是基于 size 的优化,即当集合合并时,将元素少的树合并到元素多的树上,如下图:
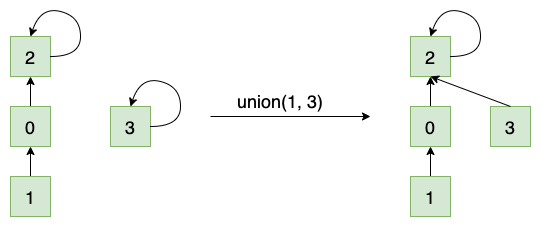
代码逻辑中,需要添加一个属性,在初始化数组的时候就记录每一个集合中的元素数量:
sizes = new int[capacity];
for (int i = 0; i < sizes.length; i++) {
sizes[i] = 1;
}
这里是创建一个 sizes 的数组,来存放每一个集合中的元素的数量,初始化时,每个集合的数量都是 1 个。
下面在合并函数中,判断两个集合中的元素数量大小,小的集合合并到大的集合中,最重要的是,合并之后要更新集合的元素数量:
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
// 判断 size 大小
if (sizes[p1] < sizes[p2]) {
parents[p1] = p2;
// 更新元素数量
sizes[p2]+= sizes[p1];
} else {
parents[p2] = p1;
sizes[p1] += sizes[p2];
}
}
代码中发现,被合并的集合的元素数量没有更新,为什么?这是因为记录的元素数量的集合中,只有是根节点的元素位置记录的数量是有效的,所以只需要保证根节点的元素数量正确,不需要每个元素都要做更新。
优化二:基于 rank
基于size 的优化在一些情况下,也可能造成树的不平衡情况,比如下图:
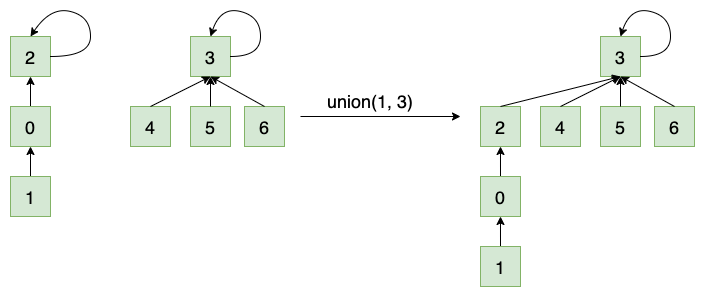
为了避免出现类似图中的情况,可以应用基于 rank 的优化。
基于rank 的优化就是将高度低的树接到高度高的树,即上图的合并可以这样处理:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qT2x3agI-1647003479747)(https://cdn.jsdelivr.net/gh/shPisces/writing_pic/img/202203061448670.png)]
代码中,也是需要定义一个数组,存放每个集合的高度:
ranks = new int[capacity];
for (int i = 0; i < ranks.length; i++) {
ranks[i] = 1;
}
然后在合并时,判断集合的高度,将高度值低的树接到高度值高的的树上。重点是在两个高度相等的树要合并到一起时,更新合并之后的集合的高度,即高度加 1:
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
// 判断 size 大小
if (ranks[p1] < ranks[p2]) {
parents[p1] = p2;
} else if (ranks[p1] > ranks[p2]) {
parents[p2] = p1;
} else {
parents[p1] = p2;
ranks[p2]++;
}
}
优化三:路径压缩
基于rank 的优化,在一定程度上保证树的相对平衡,但是在不断的合并过程中,整个树的高度是在不断地增加,这就会导致查找操作所用的时间会越来越多,尤其是最底部的元素,会更加的慢。路径压缩就是为了解决这个问题。
路径压缩就的核心思想就是在查找过程中,让路径上的所有节点都指向根节点,从而保证整个树的高度。即代码如下:
public int find(int v) {
rangeCheck(v);
if (parents[v] != v ) {
// v 元素指向根节点
parents[v] = find(parents[v]);
}
return parents[v];
}
路径压缩是每一个路径上的节点都指向根节点,在实现的成本是很高的,所以在路径压缩的原理上可以继续优化,在保证可以降低树的高度的同时,实现的成本也要低一些。
第一种就是路径分裂,即使路径上的每个节点都指向其祖父节点(即父节点的父节点):
public int find(int v) {
rangeCheck(v);
while (parents[v] != v ) {
int p = parents[v];
// parents[parents[v]] 是重点
parents[v] = parents[parents[v]];
v = p;
}
return v;
}
第二种是路径减半:即使路径上每隔一个节点就指向其祖父节点:
public int find(int v) {
rangeCheck(v);
while (parents[v] != v ) {
parents[v] = parents[parents[v]];
v = parents[v];
}
return v;
}
不管是路径分裂还是路径减半,都要比路径压缩效率要更高一些。这里需要将集合想象成树结构,会更容易理解代码。
总结
- 并查集合并时两种优化,一种是基于 size 优化,另外一种是基于 rank优化;
- 并查集查找是的优化是路径压缩的优化;
- 在路径压缩的优化下可以再有路径分裂和路径减半这两种优化;
- 并查集的优化核心就是第一在合并时尽量降低树的高度,在查找时调整节点的指向,降低树的高度;
- 具体场景的搭配:优先合并+基于rank优化+路径分裂/路径减半。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: