1. 概述
分布式链路追踪系统,链路的追踪大体流程如下:
1、 Agent收集Trace数据;
2、 Agent发送Trace数据给Collector;
3、 Collector接收Trace数据;
4、 Collector存储Trace数据到存储器,例如,数据库;
本文主要分享【第四部分】 SkyWalking Collector 存储 Trace 数据。
友情提示:Collector 接收到 TraceSegment 的数据,对应的类是 Protobuf 生成的。考虑到更加易读易懂,本文使用 TraceSegment 相关的原始类。
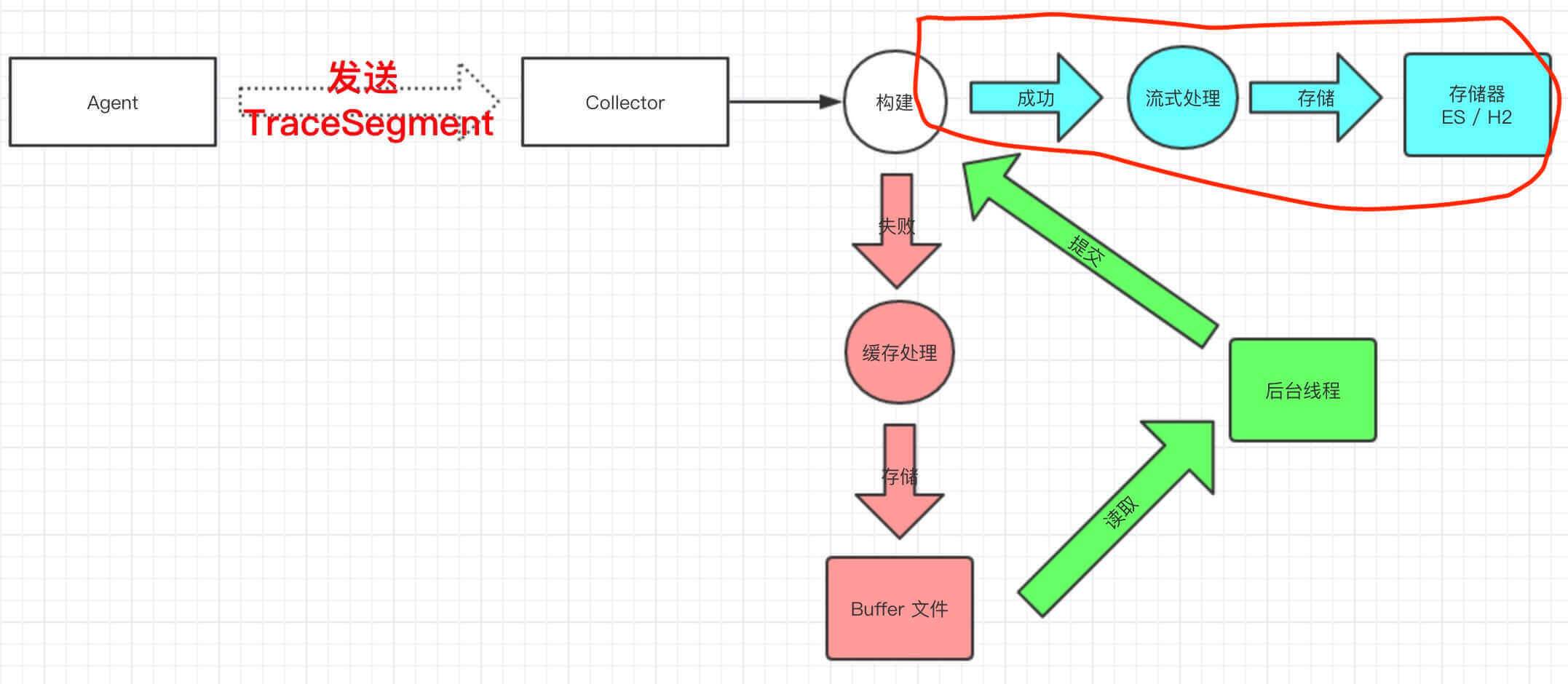
Collector 在接收到 Trace 数据后,经过流式处理,最终存储到存储器。如下图,红圈部分,为本文分享的内容:
2. SpanListener
在 《SkyWalking 源码分析 —— Collector 接收 Trace 数据》 一文中,我们看到 SegmentParse#parse(UpstreamSegment, Source) 方法中:
- 在 #preBuild(List
<UniqueId>, SegmentDecorator) 方法中,预构建的过程中,使用 Span 监听器们,从 TraceSegment 解析出不同的数据。 - 在预构建成功后,通知 Span 监听器们,去构建各自的数据,经过流式处理,最终存储到存储器。
org.skywalking.apm.collector.agent.stream.parser.SpanListener ,Span 监听器接口。
- 定义了 #build() 方法,构建数据,执行流式处理,最终存储到存储器。
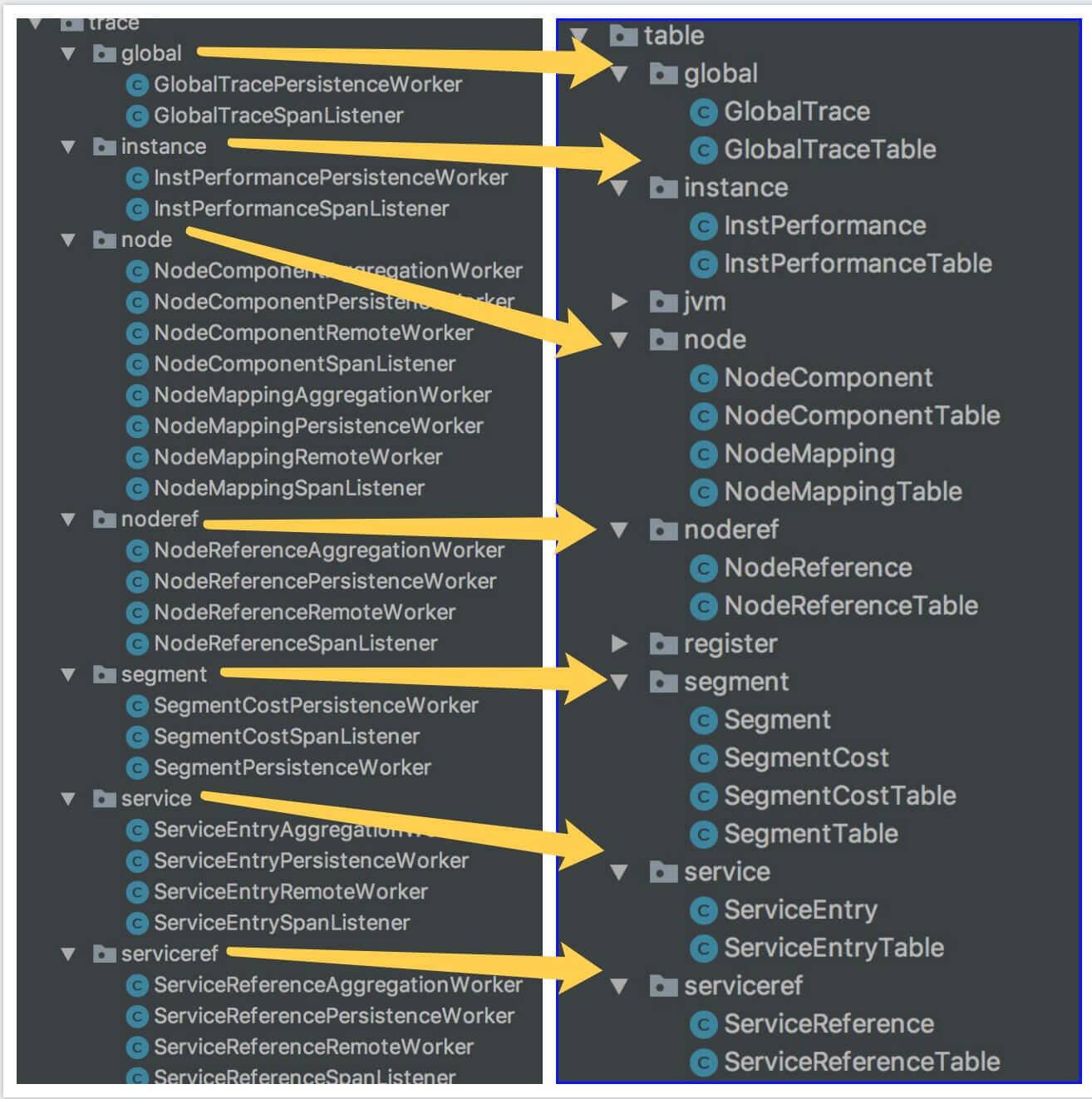
SpanListener 的子类如下图:

-
第一层,通用接口层,定义了从 TraceSegment 解析数据的方法。
-
① GlobalTraceSpanListener :解析链路追踪全局编号数组(
TraceSegment.relatedGlobalTraces)。 -
② RefsListener :解析父 Segment 指向数组(
TraceSegment.refs)。 -
③ FirstSpanListener :解析第一个 Span (
TraceSegment.spans[0]) 。 -
③ EntrySpanListener :解析 EntrySpan (
TraceSegment.spans)。 -
③ LocalSpanListener :解析 LocalSpan (
TraceSegment.spans)。 -
③ ExitSpanListener :解析 ExitSpan (
TraceSegment.spans)。 -
第二层,业务实现层,每个实现类对应一个数据实体类,一个 Graph 对象。如下图所示:
下面,我们以每个数据实体类为中心,逐个分享。
3. GlobalTrace
org.skywalking.apm.collector.storage.table.global.GlobalTrace ,全局链路追踪,记录一次分布式链路追踪,包括的 TraceSegment 编号。
-
GlobalTrace : TraceSegment = N : M ,一个 GlobalTrace 可以有多个 TraceSegment ,一个 TraceSegment 可以关联多个 GlobalTrace 。参见 《SkyWalking 源码分析 —— Agent 收集 Trace 数据》「2. Trace」 。
-
org.skywalking.apm.collector.storage.table.global.GlobalTraceTable , GlobalTrace 表( global_trace )。字段如下:
-
global_trace_id:全局链路追踪编号。 -
segment_id:TraceSegment 链路编号。 -
time_bucket:时间。 -
org.skywalking.apm.collector.storage.es.dao.GlobalTraceEsPersistenceDAO ,GlobalTrace 的 EsDAO 。
-
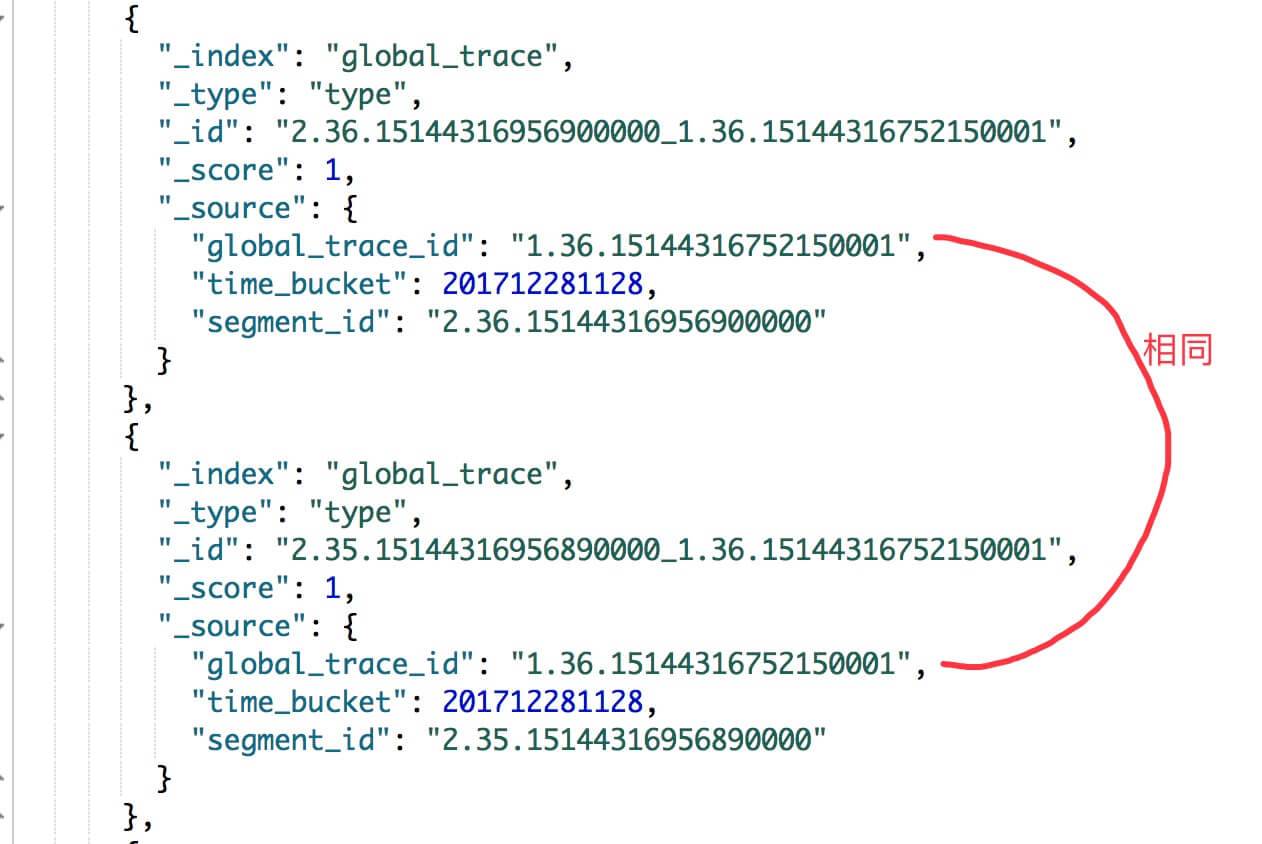
在 ES 存储例子如下图:
org.skywalking.apm.collector.agent.stream.worker.trace.global.GlobalTraceSpanListener ,GlobalTrace 的 SpanListener ,实现了 FirstSpanListener 、GlobalTraceIdsListener 接口,代码如下:
-
globalTraceIds 属性,全局链路追踪编号数组。
-
segmentId 属性,TraceSegment 链路编号。
-
timeBucket 属性,时间。
-
#parseFirst(SpanDecorator, applicationId, instanceId, segmentId) 方法,从 Span 中解析到 segmentId ,timeBucket 。
-
#parseGlobalTraceId(UniqueId) 方法,解析全局链路追踪编号,添加到 globalTraceIds 数组。
-
#build() 方法,构建,代码如下:
-
第 84 行:获取 GlobalTrace 对应的
Graph<GlobalTrace>对象。- 第 86 至 92 行:循环 globalTraceIds 数组,创建 GlobalTrace 对象,逐个调用 Graph#start(application) 方法,进行流式处理。在这过程中,会保存 GlobalTrace 到存储器。
在 TraceStreamGraph#createGlobalTraceGraph() 方法中,我们可以看到 GlobalTrace 对应的 Graph<GlobalTrace> 对象的创建。
-
org.skywalking.apm.collector.agent.stream.worker.trace.global.GlobalTracePersistenceWorker ,继承 PersistenceWorker 抽象类,GlobalTrace 批量保存 Worker 。
-
Factory 内部类,实现 AbstractLocalAsyncWorkerProvider 抽象类,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》「3.2.2 AbstractLocalAsyncWorker」 有详细解析。
-
PersistenceWorker ,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(二)》「4. PersistenceWorker」 有详细解析。
- #id() 实现方法,返回 120 。
- #needMergeDBData() 实现方法,返回 false ,存储时,不需要合并数据。GlobalTrace 只有新增操作,没有更新操作,因此无需合并数据。
4. InstPerformance
旁白君:InstPerformance 和 GlobalTrace 整体比较相似,分享的会比较简洁一些。
org.skywalking.apm.collector.storage.table.instance.InstPerformance ,应用实例性能,记录应用实例每秒的请求总次数,请求总时长。
-
org.skywalking.apm.collector.storage.table.instance.InstPerformanceTable , GlobalTrace 表( global_trace )。字段如下:
-
application_id:应用编号。 -
instance_id:应用实例编号。 -
calls:调用总次数。 -
cost_total:消耗总时长。 -
time_bucket:时间。 -
org.skywalking.apm.collector.storage.es.dao.InstPerformanceEsPersistenceDAO ,InstPerformance 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.instance.InstPerformanceSpanListener ,InstPerformance 的 SpanListener ,实现了 FirstSpanListener 、EntrySpanListener 接口。
在 TraceStreamGraph#createInstPerformanceGraph() 方法中,我们可以看到 InstPerformance 对应的 Graph<InstPerformance> 对象的创建。
-
org.skywalking.apm.collector.agent.stream.worker.trace.instance.InstPerformancePersistenceWorker ,继承 PersistenceWorker 抽象类,InstPerformance 批量保存 Worker 。
-
类似 GlobalTracePersistenceWorker ,… 省略其它类和方法。
- #needMergeDBData() 实现方法,返回 true ,存储时,需要合并数据。calls 、cost_total 需要累加合并。
5. SegmentCost
旁白君:SegmentCost 和 GlobalTrace 整体比较相似,分享的会比较简洁一些。
org.skywalking.apm.collector.storage.table.segment.SegmentCost ,TraceSegment 消耗时长,记录 TraceSegment 开始时间,结束时间,花费时长等等。
-
SegmentCost : TraceSegment = 1 : 1 。
-
org.skywalking.apm.collector.storage.table.instance.SegmentCostTable , SegmentCostTable 表( segment_cost )。字段如下:
-
segment_id:TraceSegment 编号。 -
application_id:应用编号。 -
start_time:开始时间。 -
end_time:结束时间。 -
service_name:操作名。 -
cost:消耗时长。 -
time_bucket:时间(yyyyMMddHHmm)。 -
org.skywalking.apm.collector.storage.es.dao.SegmentCostEsPersistenceDAO ,SegmentCost 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.segment.SegmentCostSpanListener ,SegmentCost 的 SpanListener ,实现了 FirstSpanListener 、EntrySpanListener 、ExitSpanListener 、LocalSpanListener 接口。
在 TraceStreamGraph#createSegmentCostGraph() 方法中,我们可以看到 SegmentCost 对应的 Graph<SegmentCost> 对象的创建。
-
org.skywalking.apm.collector.agent.stream.worker.trace.segment.SegmentCostPersistenceWorker ,继承 PersistenceWorker 抽象类,InstPerformance 批量保存 Worker 。
-
类似 GlobalTracePersistenceWorker ,… 省略其它类和方法。
6. NodeComponent
org.skywalking.apm.collector.storage.table.node.NodeComponent ,节点组件。
-
org.skywalking.apm.collector.storage.table.node.NodeComponentTable , NodeComponentTable 表( node_component )。字段如下:
-
component_id:组件编号,参见 ComponentsDefine 的枚举。 -
peer_id:对等编号。每个组件,或是服务提供者,有服务地址;又或是服务消费者,有调用服务地址。这两者都脱离不开服务地址。SkyWalking 将服务地址作为applicationCode,注册到 Application 。因此,此处的peer_id实际上是,服务地址对应的应用编号。 -
time_bucket:时间(yyyyMMddHHmm)。 -
org.skywalking.apm.collector.storage.es.dao.NodeComponentEsPersistenceDAO ,NodeComponent 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.node.NodeComponentSpanListener ,NodeComponent 的 SpanListener ,实现了 FirstSpanListener 、EntrySpanListener 、ExitSpanListener 接口,代码如下:
-
nodeComponents 属性,节点组件数组,一次 TraceSegment 可以经过个节点组件,例如 SpringMVC =>` MongoDB 。
-
segmentId 属性,TraceSegment 链路编号。
-
timeBucket 属性,时间( yyyyMMddHHmm )。
-
#parseEntry(SpanDecorator, applicationId, instanceId, segmentId) 方法,从 EntrySpan 中解析到 segmentId ,applicationId ,创建 NodeComponent 对象,添加到 nodeComponents 。注意,EntrySpan 使用 applicationId 作为 peerId 。
-
#parseExit(SpanDecorator, applicationId, instanceId, segmentId) 方法,从 ExitSpan 中解析到 segmentId ,peerId ,创建 NodeComponent 对象,添加到 nodeComponents 。注意,ExitSpan 使用 peerId 作为 peerId 。
-
#parseFirst(SpanDecorator, applicationId, instanceId, segmentId) 方法,从首个 Span 中解析到 timeBucket 。
-
#build() 方法,构建,代码如下:
-
第 84 行:获取 NodeComponent 对应的
Graph<NodeComponent>对象。- 第 86 至 92 行:循环 nodeComponents 数组,逐个调用 Graph#start(nodeComponent) 方法,进行流式处理。在这过程中,会保存 NodeComponent 到存储器。
在 TraceStreamGraph#createNodeComponentGraph() 方法中,我们可以看到 NodeComponent 对应的 Graph<NodeComponent> 对象的创建。
-
org.skywalking.apm.collector.agent.stream.worker.trace.node.NodeComponentAggregationWorker ,继承 AggregationWorker 抽象类,NodeComponent 聚合 Worker 。
-
NodeComponent 的编号生成规则为
${timeBucket}_${componentId}_${peerId},并且timeBucket是分钟级 ,可以使用 AggregationWorker 进行聚合,合并相同操作,减小 Collector 和 ES 的压力。 -
Factory 内部类,实现 AbstractLocalAsyncWorkerProvider 抽象类,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》「3.2.2 AbstractLocalAsyncWorker」 有详细解析。
-
AggregationWorker ,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(二)》「3. AggregationWorker」 有详细解析。
- #id() 实现方法,返回 106 。
-
org.skywalking.apm.collector.agent.stream.worker.trace.service.ServiceEntryRemoteWorker ,继承 AbstractRemoteWorker 抽象类,应用注册远程 Worker 。
-
Factory 内部类,实现 AbstractRemoteWorkerProvider 抽象类,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》「3.2.3 AbstractRemoteWorker」 有详细解析。
-
AbstractRemoteWorker ,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》「3.2.3 AbstractRemoteWorker」 有详细解析。
- #id() 实现方法,返回 10002 。
- #selector 实现方法,返回 Selector.HashCode 。将相同编号的 NodeComponent 发给同一个 Collector 节点,统一处理。在 《SkyWalking 源码分析 —— Collector Remote 远程通信服务》 有详细解析。
-
org.skywalking.apm.collector.agent.stream.worker.trace.service.ServiceEntryPersistenceWorker ,继承 PersistenceWorker 抽象类,NodeComponent 批量保存 Worker 。
-
类似 GlobalTracePersistenceWorker ,… 省略其它类和方法。
- #needMergeDBData() 实现方法,返回 true ,存储时,需要合并数据。
7. NodeMapping
org.skywalking.apm.collector.storage.table.node.NodeComponent ,节点匹配,用于匹配服务消费者与提供者。
-
org.skywalking.apm.collector.storage.table.node.NodeMappingTable , NodeMappingTable 表( node_mapping )。字段如下:
-
application_id:服务消费者应用编号。 -
address_id:服务提供者应用编号。 -
time_bucket:时间(yyyyMMddHHmm)。 -
org.skywalking.apm.collector.storage.es.dao.NodeMappingEsPersistenceDAO ,NodeMapping 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.node.NodeMappingSpanListener ,NodeMapping 的 SpanListener ,实现了 FirstSpanListener 、RefsListener 接口,代码如下:
-
nodeMappings 属性,节点匹配数组,一次 TraceSegment 可以经过个节点组件,例如调用多次远程服务,或者数据库。
-
timeBucket 属性,时间( yyyyMMddHHmm )。
-
#parseRef(SpanDecorator, applicationId, instanceId, segmentId) 方法,从 TraceSegmentRef 中解析到 applicationId ,peerId ,创建 NodeMapping 对象,添加到 nodeMappings 。
-
#parseFirst(SpanDecorator, applicationId, instanceId, segmentId) 方法,从首个 Span 中解析到timeBucket 。
-
#build() 方法,构建,代码如下:
-
第 84 行:获取 NodeMapping 对应的
Graph<NodeMapping>对象。- 第 86 至 92 行:循环 nodeMappings 数组,逐个调用 Graph#start(nodeMapping) 方法,进行流式处理。在这过程中,会保存 NodeMapping 到存储器。
在 TraceStreamGraph#createNodeMappingGraph() 方法中,我们可以看到 NodeMapping 对应的 Graph<NodeMapping> 对象的创建。
- 和 NodeComponent 的 Graph
<NodeComponent>基本一致,胖友自己看下源码。 - org.skywalking.apm.collector.agent.stream.worker.trace.node.NodeMappingAggregationWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.node.NodeMappingRemoteWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.node.NodeMappingPersistenceWorker
8. NodeReference
org.skywalking.apm.collector.storage.table.noderef.NodeReference ,节点调用统计,用于记录服务消费者对服务提供者的调用,基于应用级别的,以分钟为时间最小粒度的聚合统计。
-
org.skywalking.apm.collector.storage.table.noderef.NodeReference , NodeReference 表( node_reference )。字段如下:
-
front_application_id:服务消费者应用编号。 -
behind_application_id:服务提供者应用编号。 -
s1_lte:( 0, 1000 ms ] 的调用次数。 -
s3_lte:( 1000, 3000 ms ] 的调用次数。 -
s5_lte:( 3000, 5000ms ] 的调用次数 -
s5_gt:( 5000, +∞ ] 的调用次数。 -
error:发生异常的调用次数。 -
summary:总共的调用次数。 -
time_bucket:时间(yyyyMMddHHmm)。 -
org.skywalking.apm.collector.storage.es.dao.NodeReferenceEsPersistenceDAO ,NodeReference 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.noderef.NodeReferenceSpanListener ,NodeReference 的 SpanListener ,实现了 EntrySpanListener 、ExitSpanListener 、RefsListener 接口,代码如下:
-
references 属性,父 TraceSegment 调用产生的 NodeReference 数组。
-
nodeReferences 属性,NodeReference 数组,最终会包含 references 数组。
-
timeBucket 属性,时间( yyyyMMddHHmm )。
-
#parseRef(SpanDecorator, applicationId, instanceId, segmentId) 方法,代码如下:
-
第 106 至 109 行:使用父 TraceSegment 的应用编号作为服务消费者编号,自己的应用编号作为服务提供者应用编号,创建 NodeReference 对象。
-
第 111 行:将 NodeReference 对象,添加到
references。注意,是references,而不是nodeReference。 -
#parseEntry(SpanDecorator, applicationId, instanceId, segmentId) 方法,代码如下:
-
作为服务提供者,接受调用。
-
——- 父 TraceSegment 存在 ——–
- 第 79 至 85 行:references 非空,说明被父 TraceSegment 调用。因此,循环 references 数组,设置 id ,timeBucket 属性( 因为 timeBucket 需要从 EntrySpan 中获取,所以 #parseRef(...) 的目的,就是临时存储父 TraceSegment 的应用编号到 references 中 )。
- 第 87 行:调用 #buildserviceSum(...) 方法,设置调用次数,然后添加到 nodeReferences 中。
-
——- 父 TraceSegment 不存在 ——–
-
第 91 至 97 行:使用
USER_ID的应用编号( 特殊,代表 “用户“ )作为服务消费者编号,自己的应用编号作为服务提供者应用编号,创建 NodeReference 对象。- 第 99 行:调用 #buildserviceSum(...) 方法,设置调用次数,然后添加到 nodeReferences 中。
-
#parseExit(SpanDecorator, applicationId, instanceId, segmentId) 方法,代码如下:
-
作为服务消费者,发起调用。
-
第 64 至 71 行:使用自己的应用编号作为服务消费者编号,
peerId作为服务提供者应用编号,创建 NodeReference 对象。- 第 73 行:调用 #buildserviceSum(...) 方法,设置调用次数,然后添加到 nodeReferences 中。
-
#build() 方法,构建,代码如下:
-
第 84 行:获取 NodeReference 对应的
Graph<NodeReference>对象。- 第 86 至 92 行:循环 nodeReferences 数组,逐个调用 Graph#start(nodeReference) 方法,进行流式处理。在这过程中,会保存 NodeReference 到存储器。
在 TraceStreamGraph#createNodeReferenceGraph() 方法中,我们可以看到 NodeReference 对应的 Graph<NodeReference> 对象的创建。
- 和 NodeComponent 的 Graph
<NodeComponent>基本一致,胖友自己看下源码。 - org.skywalking.apm.collector.agent.stream.worker.trace.noderef.NodeReferenceAggregationWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.noderef.NodeReferenceRemoteWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.noderef.NodeReferencePersistenceWorker
9. ServiceEntry
org.skywalking.apm.collector.storage.table.service.ServiceEntry ,入口操作。
-
ServiceEntry 只保存分布式链路的入口操作,不同于 ServiceName 保存所有操作,即 ServiceEntry 是 ServiceName 的子集。
-
注意,子 TraceSegment 的入口操作也不记录。
-
org.skywalking.apm.collector.storage.table.service.ServiceEntryTable , ServiceEntry 表( service_entry )。字段如下:
-
application_id:应用编号。 -
entry_service_id:入口操作编号。 -
entry_service_name:入口操作名。 -
register_time:注册时间。 -
newest_time:最后调用时间。 -
org.skywalking.apm.collector.storage.es.dao.ServiceEntryEsPersistenceDAO ,ServiceEntry 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.service.ServiceEntrySpanListener ,ServiceEntry 的 SpanListener ,实现了 EntrySpanListener 、FirstSpanListener 、RefsListener 接口,代码如下:
-
hasReference 属性, 是否有 TraceSegmentRef 。
-
applicationId 属性,应用编号。
-
entryServiceId 属性,入口操作编号。
-
entryServiceName 属性,入口操作名。
-
hasEntry 属性,是否有 EntrySpan 。
-
timeBucket 属性,时间( yyyyMMddHHmm )。
-
#parseRef(SpanDecorator, applicationId, instanceId, segmentId) 方法,是否有 TraceSegmentRef 。
-
#parseFirst(SpanDecorator, applicationId, instanceId, segmentId) 方法,从首个 Span 中解析到 timeBucket 。
-
#parseEntry(SpanDecorator, applicationId, instanceId, segmentId) 方法,从 EntrySpan 中解析到 applicationId 、entryServiceId 、entryServiceName 、hasEntry 。
-
#build() 方法,构建,代码如下:
-
第 96 行:只保存分布式链路的入口操作。
-
第 98 至 103 行:创建 ServiceEntry 对象。
-
第 107 行:获取 ServiceEntry 对应的
Graph<ServiceEntry>对象。- 第 108 行:调用 Graph#start(serviceEntry) 方法,进行流式处理。在这过程中,会保存 ServiceEntry 到存储器。
在 TraceStreamGraph#createServiceEntryGraph() 方法中,我们可以看到 ServiceEntry 对应的 Graph<ServiceEntry> 对象的创建。
- 和 NodeComponent 的 Graph
<NodeComponent>基本一致,胖友自己看下源码。 - org.skywalking.apm.collector.agent.stream.worker.trace.service.ServiceEntryAggregationWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.service.ServiceEntryRemoteWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.service.ServiceEntryPersistenceWorker
10. ServiceReference
org.skywalking.apm.collector.storage.table.serviceref.ServiceReference ,入口操作调用统计,用于记录入口操作的调用,基于入口操作级别的,以分钟为时间最小粒度的聚合统计。
-
和 NodeReference 类似。
-
注意,此处的 “入口操作“ 不同于 ServiceEntry ,包含每一条 TraceSegment 的入口操作。
-
org.skywalking.apm.collector.storage.table.serviceref.ServiceReferenceTable , ServiceReference 表( service_reference )。字段如下:
-
entry_service_id:入口操作编号。 -
front_service_id:服务消费者操作编号。 -
behind_service_id:服务提供者操作编号。 -
s1_lte:( 0, 1000 ms ] 的调用次数。 -
s3_lte:( 1000, 3000 ms ] 的调用次数。 -
s5_lte:( 3000, 5000ms ] 的调用次数 -
s5_gt:( 5000, +∞ ] 的调用次数。 -
error:发生异常的调用次数。 -
summary:总共的调用次数。 -
cost_summary:总共的花费时间。 -
time_bucket:时间(yyyyMMddHHmm)。 -
org.skywalking.apm.collector.storage.es.dao.ServiceReference ,ServiceReference 的 EsDAO 。
-
在 ES 存储例子如下图:

org.skywalking.apm.collector.agent.stream.worker.trace.segment.ServiceReferenceSpanListener ,ServiceReference 的 SpanListener ,实现了 EntrySpanListener 、FirstSpanListener 、RefsListener 接口,代码如下:
-
referenceServices 属性,ReferenceDecorator 数组,记录 TraceSegmentRef 数组。
-
serviceId 属性,入口操作编号。
-
startTime 属性,开始时间。
-
endTime 属性,结束时间。
-
isError 属性,是否有错误。
-
hasEntry 属性,是否有 SpanEntry 。
-
timeBucket 属性,时间( yyyyMMddHHmm )。
-
#parseRef(SpanDecorator, applicationId, instanceId, segmentId) 方法,将 TraceSegmentRef 添加到 referenceServices 。
-
#parseFirst(SpanDecorator, applicationId, instanceId, segmentId) 方法,从首个 Span 中解析到 timeBucket 。
-
#parseEntry(SpanDecorator, applicationId, instanceId, segmentId) 方法,从 EntrySpan 中解析 serviceId 、startTime 、endTime 、isError 、hasEntry 。
-
#build() 方法,构建,代码如下:
-
第 114 行:判断
hasEntry = true,存在 EntrySpan 。 -
——— 有 TraceSegmentRef ———
-
第 117 至 120 行:创建 ServiceReference 对象,其中:
entryServiceId:TraceSegmentRef 的入口编号。frontServiceId:TraceSegmentRef 的操作编号。behindServiceId: 自己 EntrySpan 的操作编号。- 第 121 行:调用 #calculateCost(...) 方法,设置调用次数。
- 第 126 行:调用 #sendToAggregationWorker(...) 方法,发送 ServiceReference 给 AggregationWorker ,执行流式处理。
-
——— 无 TraceSegmentRef ———
-
第 117 至 120 行:创建 ServiceReference 对象,其中:
entryServiceId:自己 EntrySpan 的操作编号。frontServiceId:Const.NONE_SERVICE_ID对应的操作编号( 系统内置,代表【空】 )。behindServiceId: 自己 EntrySpan 的操作编号。- 第 121 行:调用 #calculateCost(...) 方法,设置调用次数。
- 第 126 行:调用 #sendToAggregationWorker(...) 方法,发送 ServiceReference 给 AggregationWorker ,执行流式处理。
在 TraceStreamGraph#createServiceReferenceGraph() 方法中,我们可以看到 ServiceReference 对应的 Graph<ServiceReference> 对象的创建。
- 和 NodeComponent 的 Graph
<NodeComponent>基本一致,胖友自己看下源码。 - org.skywalking.apm.collector.agent.stream.worker.trace.noderef.ServiceEntryAggregationWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.noderef.ServiceEntryRemoteWorker
- org.skywalking.apm.collector.agent.stream.worker.trace.noderef.ServiceEntryPersistenceWorker
11. Segment
不同于上述所有数据实体,Segment 无需解析,直接使用 TraceSegment 构建,参见如下方法:
org.skywalking.apm.collector.storage.table.segment.Segment ,全局链路追踪,记录一次分布式链路追踪,包括的 TraceSegment 编号。
-
org.skywalking.apm.collector.storage.table.global.GlobalTraceTable , Segment 表( segment )。字段如下:
-
_id:TraceSegment 编号。 -
data_binary:TraceSegment 链路编号。 -
time_bucket:时间(yyyyMMddHHmm)。 -
org.skywalking.apm.collector.storage.es.dao.SegmentEsPersistenceDAO ,GlobalTrace 的 EsDAO 。
-
在 ES 存储例子如下图:

在 TraceStreamGraph#createSegmentGraph() 方法中,我们可以看到 Segment 对应的 Graph<Segment> 对象的创建。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: