1. 概述
分布式链路追踪系统,链路的追踪大体流程如下:
1、 Agent收集Trace数据;
2、 Agent发送Trace数据给Collector;
3、 Collector接收Trace数据;
4、 Collector存储Trace数据到存储器,例如,数据库;
本文主要分享【第一部分】 SkyWalking Agent 收集 Trace 数据。文章的内容顺序如下:
- Trace 的数据结构
- Context 收集 Trace 的方法
不包括插件对 Context 收集的方法的调用,后续单独文章专门分享,胖友也可以阅读完本文后,自己去看 apm-sdk-plugin 的实现代码。
本文涉及到的代码如下图:
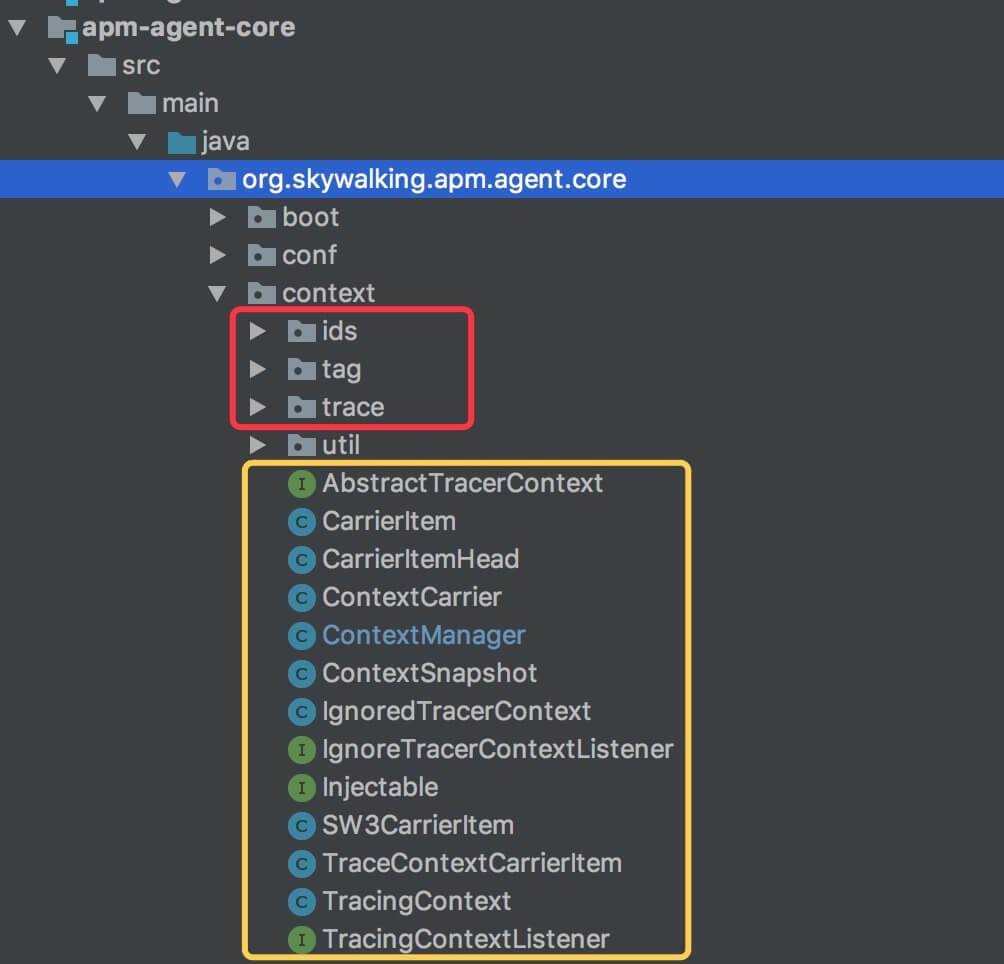
- 红框部分:Trace 的数据结构,在 「2. Trace」 分享。
- 黄框部分:Context 收集 Trace 的方法,在 「3. Context」 分享。
2. Trace
友情提示:胖友,请先行阅读 《OpenTracing语义标准》 。
本小节,笔者认为胖友已经对 OpenTracing 有一定的理解。
org.skywalking.apm.agent.core.context.trace.TraceSegment ,是一次分布式链路追踪( Distributed Trace ) 的一段。
- 一条 TraceSegment ,用于记录所在线程( Thread )的链路。
- 一次分布式链路追踪,可以包含多条 TraceSegment ,因为存在跨进程( 例如,RPC 、MQ 等等),或者垮线程( 例如,并发执行、异步回调等等 )。
TraceSegment 属性,如下:
-
traceSegmentId 属性,TraceSegment 的编号,全局唯一。在 「2.1 ID」 详细解析。
-
refs 属性,TraceSegmentRef 数组,指向的父 TraceSegment 数组。
-
为什么会有多个爸爸?下面统一讲。
-
TraceSegmentRef ,在 「2.3 TraceSegmentRef」 详细解析。
-
relatedGlobalTraces 属性,关联的 DistributedTraceId 数组。
-
为什么会有多个爸爸?下面统一讲。
-
DistributedTraceId ,在 「2.1.2 DistributedTraceId」 详细解析。
-
spans 属性,包含的 Span 数组。在 「2.2 AbstractSpan」 详细解析。这是 TraceSegment 的主体,总的来说,TraceSegment 是 Span 数组的封装。
-
ignore 属性,是否忽略该条 TraceSegment 。在一些情况下,我们会忽略 TraceSegment ,即不收集链路追踪,在下面 「3. Context」 部分内容,我们将会看到这些情况。
-
isSizeLimited 属性,Span 是否超过上限( Config.Agent.SPAN_LIMIT_PER_SEGMENT )。超过上限,不在记录 Span 。
为什么会有多个爸爸?
-
我们先来看看一个爸爸的情况,常见于 RPC 调用。例如,【服务 A】调用【服务 B】时,【服务 B】新建一个 TraceSegment 对象:
-
将自己的
refs指向【服务 A】的 TraceSegment 。 -
将自己的
relatedGlobalTraces设置为 【服务 A】的 DistributedTraceId 对象。 -
我们再来看看多个爸爸的情况,常见于 MQ / Batch 调用。例如,MQ 批量消费消息时,消息来自【多个服务】。每次批量消费时,【消费者】新建一个 TraceSegment 对象:
-
将自己的
refs指向【多个服务】的多个 TraceSegment 。 -
将自己的
relatedGlobalTraces设置为【多个服务】的多个 DistributedTraceId 。
友情提示:多个爸爸的故事,可能比较难懂,等胖友读完全文,在回过头想想。或者拿起来代码调试调试。
下面,我们来具体看看 TraceSegment 的每个元素,最后,我们会回过头,在 「2.4 TraceSegment」 详细解析它。
2.1 ID
org.skywalking.apm.agent.core.context.ids.ID ,编号。从类的定义上,这是一个通用的编号,由三段整数组成。
目前使用 GlobalIdGenerator 生成,作为全局唯一编号。属性如下:
-
part1 属性,应用实例编号。
-
part2 属性,线程编号。
-
part3 属性,时间戳串,生成方式为
${时间戳} * 10000 + 线程自增序列([0, 9999]) 。例如:15127007074950012 。具体生成方法的代码,在 GlobalIdGenerator 中详细解析。 -
encoding 属性,编码后的字符串。格式为 "
${part1}.${part2}.${part3}" 。例如,"12.35.15127007074950000" 。- 使用 #encode() 方法,编码编号。
-
isValid 属性,编号是否合法。
-
使用
ID(encodingString)构造方法,解析字符串,生成 ID 。
2.1.1 GlobalIdGenerator
org.skywalking.apm.agent.core.context.ids.GlobalIdGenerator ,全局编号生成器。
#generate() 方法,生成 ID 对象。代码如下:
-
第 67 行:获得线程对应的 IDContext 对象。
-
第 69 至 73 行:生成 ID 对象。
-
第 70 行:
ID.part1属性,应用编号实例。 -
第 71 行:
ID.part2属性,线程编号。- 第 72 行:ID.part3 属性,调用 IDContext#nextSeq() 方法,生成带有时间戳的序列号。
-
ps :代码比较易懂,已经添加完成注释。
2.1.2 DistributedTraceId
org.skywalking.apm.agent.core.context.ids.DistributedTraceId ,分布式链路追踪编号抽象类。
- id 属性,全局编号。
DistributedTraceId 有两个实现类:
- org.skywalking.apm.agent.core.context.ids.NewDistributedTraceId ,新建的分布式链路追踪编号。当全局链路追踪开始,创建 TraceSegment 对象的过程中,会调用 DistributedTraceId() 构造方法,创建 DistributedTraceId 对象。该构造方法内部会调用 GlobalIdGenerator#generate() 方法,创建 ID 对象。
- org.skywalking.apm.agent.core.context.ids.PropagatedTraceId ,传播的分布式链路追踪编号。例如,A 服务调用 B 服务时,A 服务会将 DistributedTraceId 对象带给 B 服务,B 服务会调用 PropagatedTraceId(String id) 构造方法 ,创建 PropagatedTraceId 对象。该构造方法内部会解析 id ,生成 ID 对象。
2.1.3 DistributedTraceIds
org.skywalking.apm.agent.core.context.ids.DistributedTraceIds ,DistributedTraceId 数组的封装。
- relatedGlobalTraces 属性,关联的 DistributedTraceId 链式数组。
#append(DistributedTraceId) 方法,添加分布式链路追踪编号( DistributedTraceId )。代码如下:
- 第 51 至 54 行:移除首个 NewDistributedTraceId 对象。为什么呢?在 「2.4 TraceSegment」 的构造方法中,会默认创建 NewDistributedTraceId 对象。在跨线程、或者跨进程的情况下时,创建的 TraceSegment 对象,需要指向父 Segment 的 DistributedTraceId ,所以需要移除默认创建的。
- 第 56 至 58 行:添加 DistributedTraceId 对象到数组。
2.2 AbstractSpan
org.skywalking.apm.agent.core.context.trace.AbstractSpan ,Span 接口( 不是抽象类 ),定义了 Span 通用属性的接口方法:
-
#getSpanId() 方法,获得 Span 编号。一个整数,在 TraceSegment 内唯一,从 0 开始自增,在创建 Span 对象时生成。
-
#setOperationName(operationName) 方法,设置操作名。
-
操作名,定义如下:
- #setOperationId(operationId) 方法,设置操作编号。考虑到操作名是字符串,Agent 发送给 Collector 占用流量较大。因此,Agent 会将操作注册到 Collector ,生成操作编号。在 《SkyWalking 源码分析 —— Agent DictionaryManager 字典管理》 有详细解析。
-
#setComponent(Component) 方法,设置 org.skywalking.apm.network.trace.component.Component ,例如:MongoDB / SpringMVC / Tomcat 等等。目前,官方在 org.skywalking.apm.network.trace.component.ComponentsDefine 定义了目前已经支持的 Component 。
- #setComponent(componentName) 方法,直接设置 Component 名字。大多数情况下,我们不使用该方法。
Only use this method in explicit instrumentation, like opentracing-skywalking-bridge.
It it higher recommend don’t use this for performance consideration. -
#setLayer(SpanLayer) 方法,设置 org.skywalking.apm.agent.core.context.trace.SpanLayer 。目前有,DB 、RPC_FRAMEWORK 、HTTP 、MQ ,未来会增加 CACHE 。
-
#tag(key, value) 方法,设置键值对的标签。可以调用多次,构成 Span 的标签集合。在 「2.2.1 Tag」 详细解析。
-
日志相关
- #log(timestampMicroseconds, fields) 方法,记录一条通用日志,包含 fields 键值对集合。
- #log(Throwable) 方法,记录一条异常日志,包含异常信息。
-
#errorOccurred() 方法,标记发生异常。大多数情况下,配置 #log(Throwable) 方法一起使用。
-
#start() 方法,开始 Span 。一般情况的实现,设置开始时间。
-
#isEntry() 方法,是否是入口 Span ,在 「2.2.2.1 EntrySpan」 详细解析。
-
#isExit() 方法,是否是出口 Span ,在 「2.2.2.2 ExitSpan」 详细解析。
2.2.1 Tag
2、 2.1.1AbstractTag;
org.skywalking.apm.agent.core.context.tag.AbstractTag<T> ,标签抽象类。注意,这个类的用途是将标签属性设置到 Span 上,或者说,它是设置 Span 的标签的工具类。代码如下:
- key 属性,标签的键。
- #set(AbstractSpan span, T tagValue) 抽象方法,设置 Span 的标签键 key 的值为 tagValue 。
2、 2.1.2StringTag;
org.skywalking.apm.agent.core.context.tag.StringTag ,值类型为 String 的标签实现类。
- #set(AbstractSpan span, String tagValue) 实现方法,设置 Span 的标签键 key 的值为 tagValue 。
2、 2.1.3Tags;
org.skywalking.apm.agent.core.context.tag.Tags ,常用 Tag 枚举类,内部定义了多个 HTTP 、DB 相关的 StringTag 的静态变量。
在《opentracing-specification-zh —— 语义惯例》 里,定义了标准的 Span Tag 。
2.2.2 AbstractSpan 实现类
AbstractSpan 实现类如下图:
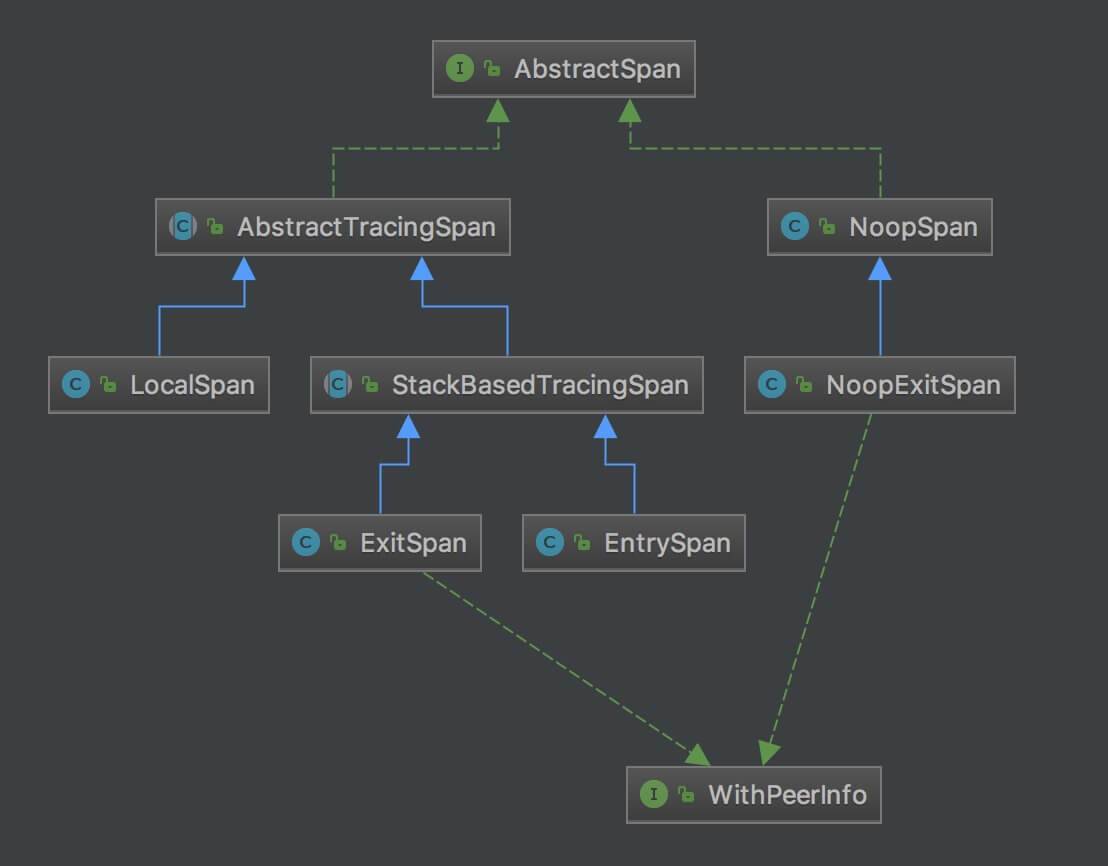
- 左半边的 Span 实现类:有具体操作的 Span 。
- 右半边的 Span 实现类:无具体操作的 Span ,和左半边的 Span 实现类相对,用于不需要收集 Span 的场景。
抛开右半边的 Span 实现类的特殊处理,Span 只有三种实现类:
- EntrySpan :入口 Span
- LocalSpan :本地 Span
- ExitSpan :出口 Span
下面,我们分小节逐步分享。
2、 2.2.1AbstractTracingSpan;
org.skywalking.apm.agent.core.context.trace.AbstractTracingSpan ,实现 AbstractSpan 接口,链路追踪 Span 抽象类。
在创建AbstractTracingSpan 时,会传入 spanId , parentSpanId , operationName / operationId 参数。参见构造方法:
- #AbstractTracingSpan(spanId, parentSpanId, operationName)
- #AbstractTracingSpan(spanId, parentSpanId, operationId)
大部分是 setting / getting 方法,或者类似方法,已经添加注释,胖友自己阅读。
#finish(TraceSegment) 方法,完成( 结束 ) Span ,将当前 Span ( 自己 )添加到 TraceSegment 。为什么会调用该方法,在 「3. Context」 详细解析。
2、 2.2.2StackBasedTracingSpan;
org.skywalking.apm.agent.core.context.trace.StackBasedTracingSpan ,实现 AbstractTracingSpan 抽象类,基于栈的链路追踪 Span 抽象类。这种 Span 能够被多次调用 #start(...) 和 #finish(...) 方法,在类似堆栈的调用中。在 「2.2.2.2.1 EntrySpan」 中详细举例子。代码如下:
-
stackDepth 属,栈深度。
-
#finish(TraceSegment) 实现方法,完成( 结束 ) Span ,将当前 Span ( 自己 )添加到 TraceSegment 。当且仅当 stackDepth == 0 时,添加成功。代码如下:
-
第 53 至 73 行:栈深度为零,出栈成功。调用 super#finish(TraceSegment) 方法,完成( 结束 ) Span ,将当前 Span ( 自己 )添加到 TraceSegment 。
-
第 55 至 72 行:当操作编号为空时,尝试使用操作名获得操作编号并设置。用于减少 Agent 发送 Collector 数据的网络流量。
-
-
第 74 至 76 行:栈深度非零,出栈失败。
2、 2.2.2.1EntrySpan;
重点
org.skywalking.apm.agent.core.context.trace.EntrySpan ,实现 StackBasedTracingSpan 抽象类,入口 Span ,用于服务提供者( Service Provider ) ,例如 Tomcat 。
EntrySpan 是 TraceSegment 的第一个 Span ,这也是为什么称为”入口“ Span 的原因。
那么为什么 EntrySpan 继承 StackBasedTracingSpan ?
例如,我们常用的 SprintBoot 场景下,Agent 会在 SkyWalking 插件在 Tomcat 定义的方法切面,创建 EntrySpan 对象,也会在 SkyWalking 插件在 SpringMVC 定义的方法切面,创建 EntrySpan 对象。那岂不是出现两个 EntrySpan ,一个 TraceSegment 出现了两个入口 Span ?
答案是当然不会!Agent 只会在第一个方法切面,生成 EntrySpan 对象,第二个方法切面,栈深度 + 1。这也是上面我们看到的 #finish(TraceSegment) 方法,只在栈深度为零时,出栈成功。通过这样的方式,保持一个 TraceSegment 有且仅有一个 EntrySpan 对象。
当然,多个 TraceSegment 会有多个 EntrySpan 对象 ,例如【服务 A】远程调用【服务 B】。
另外,虽然 EntrySpan 在第一个服务提供者创建,EntrySpan 代表的是最后一个服务提供者,例如,上面的例子,EntrySpan 代表的是 Spring MVC 的方法切面。所以,startTime 和 endTime 以第一个为准,componentId 、componentName 、layer 、logs 、tags 、operationName 、operationId 等等以最后一个为准。并且,一般情况下,最后一个服务提供者的信息也会更加详细。
ps:如上内容信息量较大,胖友可以对照着实现方法,在理解理解。HOHO ,良心笔者当然也是加了注释的。
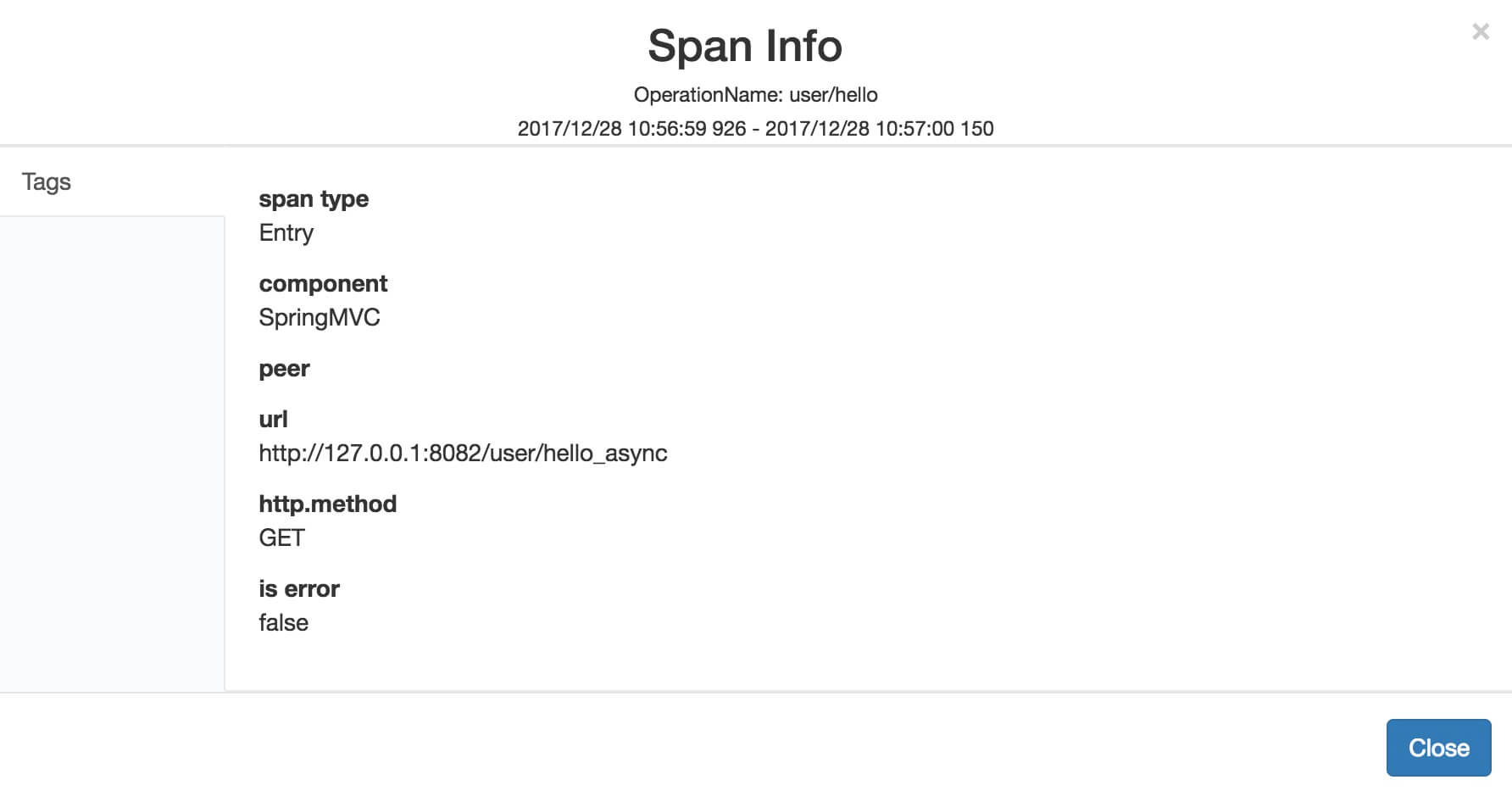
如下是一个 EntrySpan 在 SkyWalking 展示的例子:
2、 2.2.2.2ExitSpan;
重点
org.skywalking.apm.agent.core.context.trace.ExitSpan ,继承 StackBasedTracingSpan 抽象类,出口 Span ,用于服务消费者( Service Consumer ) ,例如 HttpClient 、MongoDBClient 。
ExitSpan 实现 org.skywalking.apm.agent.core.context.trace.WithPeerInfo 接口,代码如下:
- peer 属性,节点地址。
- peerId 属性,节点编号。
如下是一个 ExitSpan 在 SkyWalking 展示的例子:
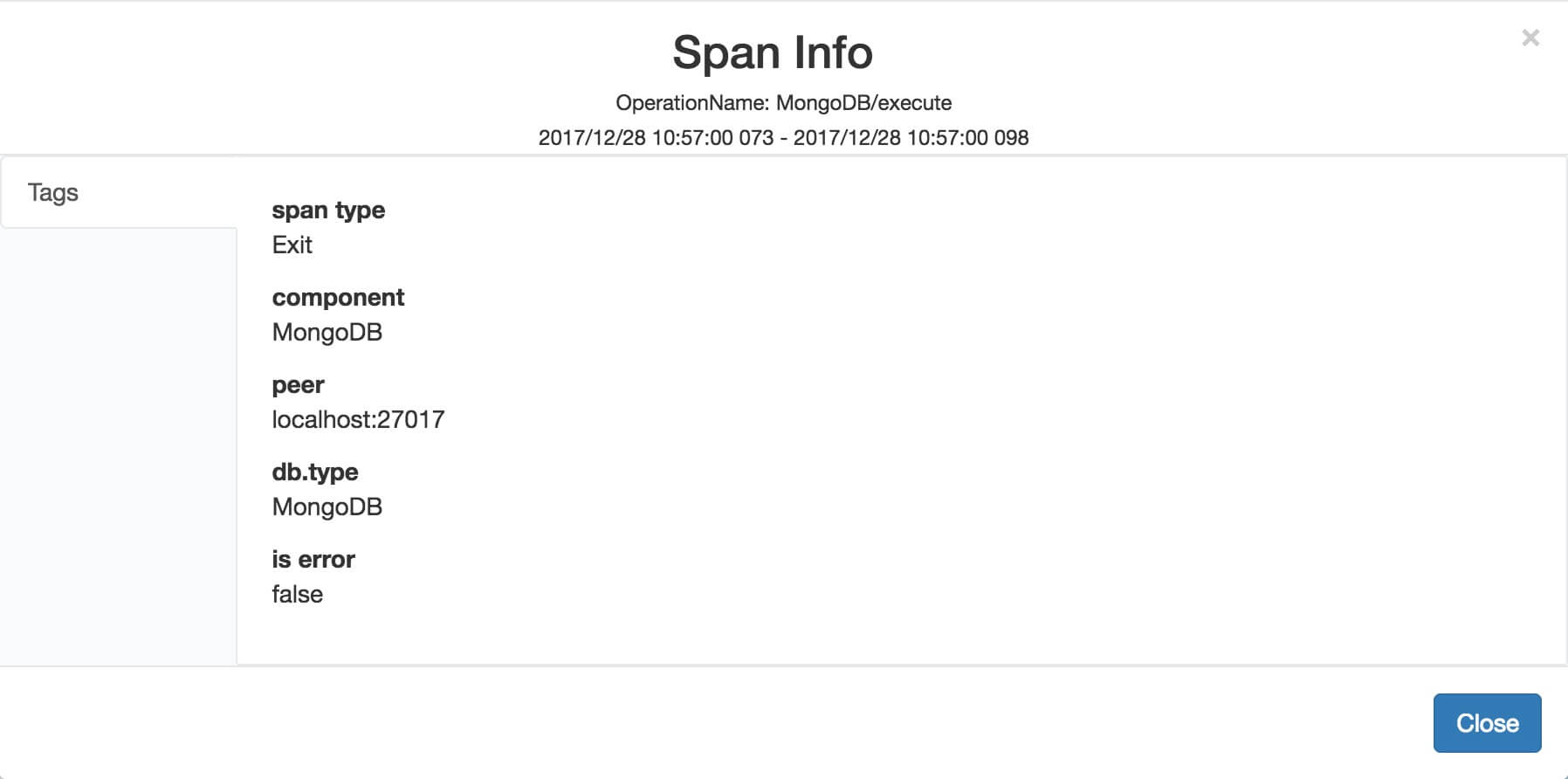
那么为什么 ExitSpan 继承 StackBasedTracingSpan ?
例如,我们可能在使用的 Dubbox 场景下,【Dubbox 服务 A】使用 HTTP 调用【Dubbox 服务 B】时,实际过程是,【Dubbox 服务 A】=》【HttpClient】=》【Dubbox 服务 B】。Agent 会在【Dubbox 服务 A】创建 ExitSpan 对象,也会在 【HttpClient】创建 ExitSpan 对象。那岂不是一次出口,出现两个 ExitSpan ?
答案是当然不会!Agent 只会在【Dubbox 服务 A】,生成 EntrySpan 对象,第二个方法切面,栈深度 + 1。这也是上面我们看到的 #finish(TraceSegment) 方法,只在栈深度为零时,出栈成功。通过这样的方式,保持一次出口有且仅有一个 ExitSpan 对象。
当然,一个 TraceSegment 会有多个 ExitSpan 对象 ,例如【服务 A】远程调用【服务 B】,然后【服务 A】再次远程调用【服务 B】,或者然后【服务 A】远程调用【服务 C】。
另外,虽然 ExitSpan 在第一个消费者创建,ExitSpan 代表的也是第一个服务提消费者,例如,上面的例子,ExitSpan 代表的是【Dubbox 服务 A】。
ps:如上内容信息量较大,胖友可以对照着实现方法,在理解理解。HOHO ,良心笔者当然也是加了注释的。
2、 2.2.3LocalSpan;
org.skywalking.apm.agent.core.context.trace.LocalSpan ,继承 AbstractTracingSpan 抽象类,本地 Span ,用于一个普通方法的链路追踪,例如本地方法。
如下是一个 EntrySpan 在 SkyWalking 展示的例子:
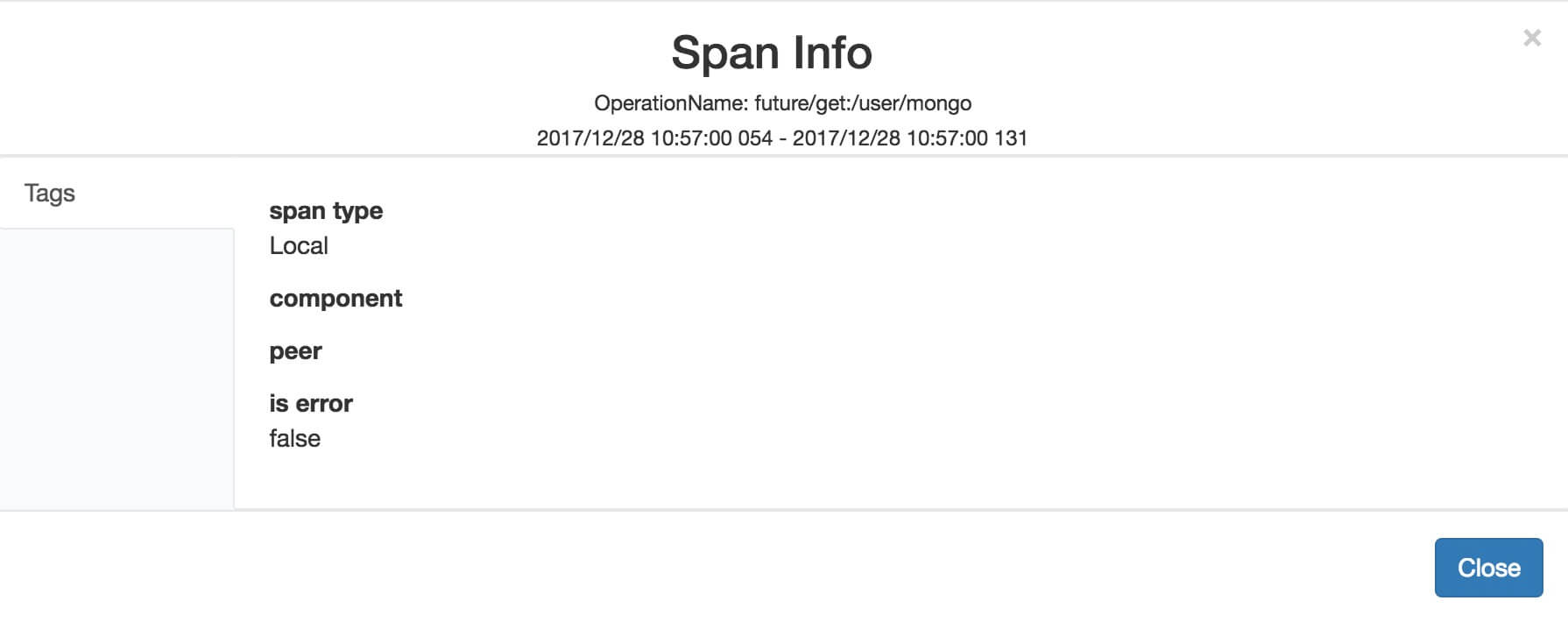
2、 2.2.4NoopSpan;
org.skywalking.apm.agent.core.context.trace.NoopSpan ,实现 AbstractSpan 接口,无操作的 Span 。配置 IgnoredTracerContext 一起使用,在 IgnoredTracerContext 声明单例 ,以减少不收集 Span 时的对象创建,达到减少内存使用和 GC 时间。
2、 2.2.3.1NoopExitSpan;
org.skywalking.apm.agent.core.context.trace.NoopExitSpan ,实现 org.skywalking.apm.agent.core.context.trace.WithPeerInfo 接口,继承 StackBasedTracingSpan 抽象类,出口 Span ,无操作的出口 Span 。和 ExitSpan 相对,不记录服务消费者的出口 Span 。
2.3 TraceSegmentRef
org.skywalking.apm.agent.core.context.trace.TraceSegmentRef ,TraceSegment 指向,通过 traceSegmentId 和 spanId 属性,指向父级 TraceSegment 的指定 Span 。
-
type 属性,指向类型( SegmentRefType ) 。不同的指向类型,使用不同的构造方法。
- CROSS_PROCESS ,跨进程,例如远程调用,对应构造方法 #TraceSegmentRef(ContextCarrier) 。
- CROSS_THREAD ,跨线程,例如异步线程任务,对应构造方法 #TraceSegmentRef(ContextSnapshot) 。
-
构造方法的代码,在 「3. Context」 中,伴随着调用过程,一起解析。
-
traceSegmentId 属性,父 TraceSegment 编号。重要
-
spanId 属性,父 Span 编号。重要
-
peerId 属性,节点编号。注意,此处的节点编号就是应用( Application )编号。
-
peerHost 属性,节点地址。
-
entryApplicationInstanceId 属性,入口应用实例编号。例如,在一个分布式链路 A->
B->C 中,此字段为 A 应用的实例编号。 -
parentApplicationInstanceId 属性,父应用实例编号。
-
entryOperationName 属性,入口操作名。
-
entryOperationId 属性,入口操作编号。
-
parentOperationName 属性,父操作名。
-
parentOperationId 属性,父操作编号。
2.4 TraceSegment
在看完了 TraceSegment 的各个元素,我们来看看 TraceSegment 内部实现的方法。
TraceSegment 构造方法,代码如下:
-
第 80 行:调用 GlobalIdGenerator#generate() 方法,生成 ID 对象,赋值给 traceSegmentId 。
-
第 81 行:创建 spans 数组。
- #archive(AbstractTracingSpan) 方法,被 AbstractSpan#finish(TraceSegment) 方法调用,添加到 spans 数组。
-
第 83 至 84 行:创建 DistributedTraceIds 对象,并添加 NewDistributedTraceId 到它。
-
注意,当 TraceSegment 是一次分布式链路追踪的首条记录,创建的 NewDistributedTraceId 对象,即为分布式链路追踪的全局编号。
- #relatedGlobalTraces(DistributedTraceId) 方法,添加 DistributedTraceId 对象。被 TracingContext#continued(ContextSnapshot) 或者 TracingContext#extract(ContextCarrier) 方法调用,在 「3. Context」 详细解析。
#ref(TraceSegmentRef) 方法,添加 TraceSegmentRef 对象,到 refs 属性,即指向父 Segment 。
3. Context
在「2. Trace」 中,我们看了 Trace 的数据结构,本小节,我们一起来看看 Context 是怎么收集 Trace 数据的。
3.1 ContextManager
org.skywalking.apm.agent.core.context.ContextManager ,实现了 BootService 、TracingContextListener 、IgnoreTracerContextListener 接口,链路追踪上下文管理器。
CONTEXT 静态属性,线程变量,存储 AbstractTracerContext 对象。为什么是线程变量呢?
一个 TraceSegment 对象,关联到一个线程,负责收集该线程的链路追踪数据,因此使用线程变量。
而一个 AbstractTracerContext 会关联一个 TraceSegment 对象,ContextManager 负责获取、创建、销毁 AbstractTracerContext 对象。
#getOrCreate(operationName, forceSampling) 静态方法,获取 AbstractTracerContext 对象。若不存在,进行创建。
- 要需要收集 Trace 数据的情况下,创建 TracingContext 对象。
- 不需要收集 Trace 数据的情况下,创建 IgnoredTracerContext 对象。
在下面的 #createEntrySpan(...) 、#createLocalSpan(...) 、#createExitSpan(...) 等等方法中,都会调用 AbstractTracerContext 提供的方法。这些方法的代码,我们放在 「3.2 AbstractTracerContext」 一起解析,保证流程的整体性。
另外,ContextManager 封装了所有 AbstractTracerContext 提供的方法,从而实现,外部调用者,例如 SkyWalking 的插件,只调用 ContextManager 的方法,而不调用 AbstractTracerContext 的方法。
#boot() 实现方法,启动时,将自己注册到 TracingContext.ListenerManager 和 IgnoredTracerContext.ListenerManager 中,这样一次链路追踪上下文( Context )完成时,从而被回调如下方法,清理上下文:
3.2 AbstractTracerContext
org.skywalking.apm.agent.core.context.AbstractTracerContext ,链路追踪上下文接口。定义了如下方法:
- #getReadableGlobalTraceId() 方法,获得关联的全局链路追踪编号。
- #createEntrySpan(operationName) 方法,创建 EntrySpan 对象。
- #createLocalSpan(operationName) 方法,创建 LocalSpan 对象。
- #createExitSpan(operationName, remotePeer) 方法,创建 ExitSpan 对象。
- #activeSpan() 方法,获得当前活跃的 Span 对象。
- #stopSpan(AbstractSpan) 方法,停止( 完成 )指定 AbstractSpan 对象。
- ——— 跨进程( cross-process ) ———
- #inject(ContextCarrier) 方法,将 Context 注入到 ContextCarrier ,用于跨进程,传播上下文。
- #extract(ContextCarrier) 方法,将 ContextCarrier 解压到 Context ,用于跨进程,接收上下文。
- ——— 跨线程( cross-thread ) ———
- #capture() 方法,将 Context 快照到 ContextSnapshot ,用于跨线程,传播上下文。
- #continued(ContextSnapshot) 方法,将 ContextSnapshot 解压到 Context ,用于跨线程,接收上下文。
3.2.1 TracingContext
org.skywalking.apm.agent.core.context.TracingContext ,实现 AbstractTracerContext 接口,链路追踪上下文实现类。
- segment 属性,上下文对应的 TraceSegment 对象。
- activeSpanStack 属性,AbstractSpan 链表数组,收集当前活跃的 Span 对象。正如方法的调用与执行一样,在一个调用栈中,先执行的方法后结束。
- spanIdGenerator 属性,Span 编号自增序列。创建的 Span 的编号,通过该变量自增生成。
TracingContext 构造方法 ,代码如下:
- 第 80 行:创建 TraceSegment 对象。
- 第 81 行:设置 spanIdGenerator = 0 。
#getReadableGlobalTraceId() 实现方法,获得 TraceSegment 的首个 DistributedTraceId 作为返回。
3、 2.1.1创建EntrySpan;
调用 ContextManager#createEntrySpan(operationName, carrier) 方法,创建 EntrySpan 对象。代码如下:
-
第 121 至 131 行:调用 #getOrCreate(operationName, forceSampling) 方法,获取 AbstractTracerContext 对象。若不存在,进行创建。
-
第 122 至 125 行:有传播 Context 的情况下,强制收集 Trace 数据。
- 第 127 行:调用 TracingContext#extract(ContextCarrier) 方法,将 ContextCarrier 解压到 Context ,跨进程,接收上下文。在 「3.2.3 ContextCarrier」 详细解析。
-
第 133 行:调用 TracingContext#createEntrySpan(operationName) 方法,创建 EntrySpan 对象。
调用 TracingContext#createEntrySpan(operationName) 方法,创建 EntrySpan 对象。代码如下:
-
第 223 至 227 行:调用 #isLimitMechanismWorking() 方法,判断 Span 数量超过上限,创建 NoopSpan 对象,并调用 #push(AbstractSpan) 方法,添加到 activeSpanStack 中。
-
第 229 至 231 行:调用 #peek() 方法,获得当前活跃的 AbstractSpan 对象。
-
第 232 至 249 行:若父 Span 对象不存在,创建 EntrySpan 对象。
-
第 235 至 244 行:创建 EntrySpan 对象。
- 第 247 行:调用 EntrySpan#start() 方法,开始 EntrySpan 。
- 第 249 行:调用 #push(AbstractSpan) 方法,添加到 activeSpanStack 中。
-
第 251 至 264 行:若父 EntrySpan 对象存在,重新开始 EntrySpan 。参见 「2.2.2.2.1 EntrySpan」 。
-
第 265 至 267 行:"The Entry Span can't be the child of Non-Entry Span" 。
3、 2.1.2创建LocalSpan;
调用 ContextManager#createLocalSpan(operationName) 方法,创建 LocalSpan 对象。
- 第 138 行:调用 #getOrCreate(operationName, forceSampling) 方法,获取 AbstractTracerContext 对象。若不存在,进行创建。
- 第 140 行:调用 TracingContext#createLocalSpan(operationName) 方法,创建 LocalSpan 对象。
调用 TracingContext#createLocalSpan(operationName) 方法,创建 LocalSpan 对象。代码如下:
- 第 280 至 283 行:调用 #isLimitMechanismWorking() 方法,判断 Span 数量超过上限,创建 NoopSpan 对象,并调用 #push(AbstractSpan) 方法,添加到 activeSpanStack 中。
- 第 284 至 286 行:调用 #peek() 方法,获得当前活跃的 AbstractSpan 对象。
- 第 288 至 300 行:创建 LocalSpan 对象。
- 第 302 行:调用 LocalSpan#start() 方法,开始 LocalSpan 。
- 第 304 行:调用 #push(AbstractSpan) 方法,添加到 activeSpanStack 中。
3、 2.1.3创建ExitSpan;
调用 ContextManager#createExitSpan(operationName, carrier, remotePeer) 方法,创建 ExitSpan 对象。
- 第 148 行:调用 #getOrCreate(operationName, forceSampling) 方法,获取 AbstractTracerContext 对象。若不存在,进行创建。
- 第 150 行:调用 TracingContext#createExitSpan(operationName, remotePeer) 方法,创建 ExitSpan 对象。
- 第 160 行:TracingContext#inject(ContextCarrier) 方法,将 Context 注入到 ContextCarrier ,跨进程,传播上下文。在 「3.2.3 ContextCarrier」 详细解析。
调用 TracingContext#createEntrySpan(operationName) 方法,创建 ExitSpan 对象。代码如下:
-
第 319 行:调用 #peek() 方法,获得当前活跃的 AbstractSpan 对象。
-
第 320 至 322 行:若 ExitSpan 对象存在,直接使用,不重新创建。参见 「2.2.2.2.2 ExitSpan」 。
-
第 324 至 377 行:创建 ExitSpan 对象,并添加到 activeSpanStack 中。
-
第 327 行:根据
remotePeer参数,查找peerId。注意,此处会创建一个 Application 对象,通过 ServiceMapping 表,和远程的 Application 进行匹配映射。后续有文章会分享这块。- 第 322 至 324 行 || 第 335 至 358 行:判断 Span 数量超过上限,创建 NoopExitSpan 对象,并调用 #push(AbstractSpan) 方法,添加到 activeSpanStack 中。
-
第 380 行:开始 ExitSpan 。
3、 2.1.4结束Span;
调用 ContextManager#stopSpan() 方法,结束 Span 。代码如下:
- 第 199 行:调用 TracingContext#stopSpan(AbstractSpan) 方法,结束 Span 。当所有活跃的 Span 都被结束后,当前线程的 TraceSegment 完成。
调用 TracingContext#stopSpan(AbstractSpan) 方法,结束 Span 。代码如下:
-
第 405 行:调用 #peek() 方法,获得当前活跃的 AbstractSpan 对象。
-
第 408 至 414 行:当 Span 为 AbstractTracingSpan 的子类,即记录链路追踪的 Span ,调用 AbstractTracingSpan#finish(TraceSegment) 方法,完成 Span 。
- 当完成成功时,调用 #pop() 方法,移除出 activeSpanStack 。
-
当完成失败时,原因参见 「2.2.2.2 StackBasedTracingSpan」 。
-
第 416 至 419 行:当 Span 为 NoopSpan 的子类,即不记录链路追踪的 Span ,调用 #pop() 方法,移除出 activeSpanStack 。
-
第 425 至 427 行:当所有活跃的 Span 都被结束后,调用 #finish() 方法,当前线程的 TraceSegment 完成。
调用 TracingContext#stopSpan(AbstractSpan) 方法,完成 Context 。代码如下:
-
第 436 行:调用 TraceSegment#finish(isSizeLimited) 方法,完成 TraceSegment 。
-
第 444 至 448 行:若满足条件,调用 TraceSegment#setIgnore(true) 方法,标记该 TraceSegment 忽略,不发送给 Collector 。
-
!samplingService.trySampling():不采样。 -
!segment.hasRef():无父 TraceSegment 指向。如果此处忽略采样,则会导致整条分布式链路追踪不完整。 -
segment.isSingleSpanSegment():TraceSegment 只有一个 Span 。 -
TODO 【4010】
-
第 450 行:调用 TracingContext.ListenerManager#notifyFinish(TraceSegment) 方法,通知监听器,一次 TraceSegment 完成。通过这样的方式,TraceSegment 会被 TraceSegmentServiceClient 异步发送给 Collector 。下一篇文章,我们详细分享发送的过程。
3.2.2 IgnoredTracerContext
org.skywalking.apm.agent.core.context.IgnoredTracerContext ,实现 AbstractTracerContext 接口,忽略( 不记录 )链路追踪的上下文。代码如下:
-
NOOP_SPAN 静态属性,NoopSpan 单例。
-
所有的创建 Span 方法,返回的都是该对象。
-
stackDepth 属性,栈深度。
-
不同于 TracingContext 使用链式数组来处理 Span 的出入栈,IgnoredTracerContext 使用
stackDepth来计数,从而实现出入栈的效果。 -
通过这两个属性和相应空方法的实现,以减少 NoopSpan 时的对象创建,达到减少内存使用和 GC 时间。
代码比较简单,胖友自己阅读该类的实现。
3.2.3 ContextCarrier
org.skywalking.apm.agent.core.context.ContextCarrier ,实现 java.io.Serializable 接口,跨进程 Context 传输载体。
3、 2.3.1解压;
我们来打开 #TraceSegmentRef(ContextCarrier) 构造方法,该方法用于将 ContextCarrier 转换成 TraceSegmentRef ,对比下两者的属性,基本一致,差异如下:
-
peerHost 属性,节点地址。
- 当字符串不以 # 号开头,代表节点编号,格式为
${peerId} ,例如 "123" 。 - 当字符串以 # 号开头,代表地址,格式为
${peerHost} ,例如 "192.168.16.1:8080" 。
- 当字符串不以 # 号开头,代表节点编号,格式为
-
entryOperationName 属性,入口操作名。
- 当字符串不以 # 号开头,代表入口操作编号,格式为 #
${entryOperationId} ,例如 "666" 。 - 当字符串以 # 号开头,代表入口操作名,格式为 #
${entryOperationName} ,例如 "#user/login" 。
- 当字符串不以 # 号开头,代表入口操作编号,格式为 #
-
parentOperationName 属性,父操作名。类似 entryOperationName 属。
-
primaryDistributedTraceId 属性,分布式链路追踪全局编号。它不在此处处理,而在 TracingContext#extract(ContextCarrier) 方法中。
在 ContextManager#createEntrySpan(operationName, carrier) 方法中,当存在 ContextCarrier 传递时,创建 Context 后,会将 ContextCarrier 解压到 Context 中,以达到跨进程传播。TracingContext#extract(ContextCarrier) 方法,代码如下:
- 第 148 行:将 ContextCarrier 转换成 TraceSegmentRef 对象,调用 TraceSegment#ref(TraceSegmentRef) 方法,进行指向父 TraceSegment。
- 第 149 行:调用 TraceSegment#relatedGlobalTraces(DistributedTraceId) 方法,将传播的分布式链路追踪全局编号,添加到 TraceSegment 中,进行指向全局编号。
另外,ContextManager 单独提供 #extract(ContextCarrier) 方法,将多个 ContextCarrier 注入到一个 Context 中,从而解决”多个爸爸“的场景,例如 RocketMQ 插件的 AbstractMessageConsumeInterceptor#beforeMethod(...) 方法。
3、 2.3.2注入;
在 ContextManager#createExitSpan(operationName, carrier, remotePeer) 方法中,当需要 Context 跨进程传递时,将 Context 注入到 ContextCarrier 中,为 「3.2.3.3 传输」 做准备。TracingContext#inject(ContextCarrier) 方法,代码比较易懂,胖友自己阅读理解。
3、 2.3.3传输;
友情提示:胖友,请先阅读 《Skywalking Cross Process Propagation Headers Protocol》 。
org.skywalking.apm.agent.core.context.CarrierItem ,传输载体项。代码如:
- headKey 属性,Header 键。
- headValue 属性,Header 值。
- next 属性,下一个项。
CarrierItem 有两个子类:
- CarrierItemHead :Carrier 项的头( Head ),即首个元素。
- SW3CarrierItem :header = sw3 ,用于传输 ContextCarrier 。
如下是Dubbo 插件,使用 CarrierItem 的代码例子:
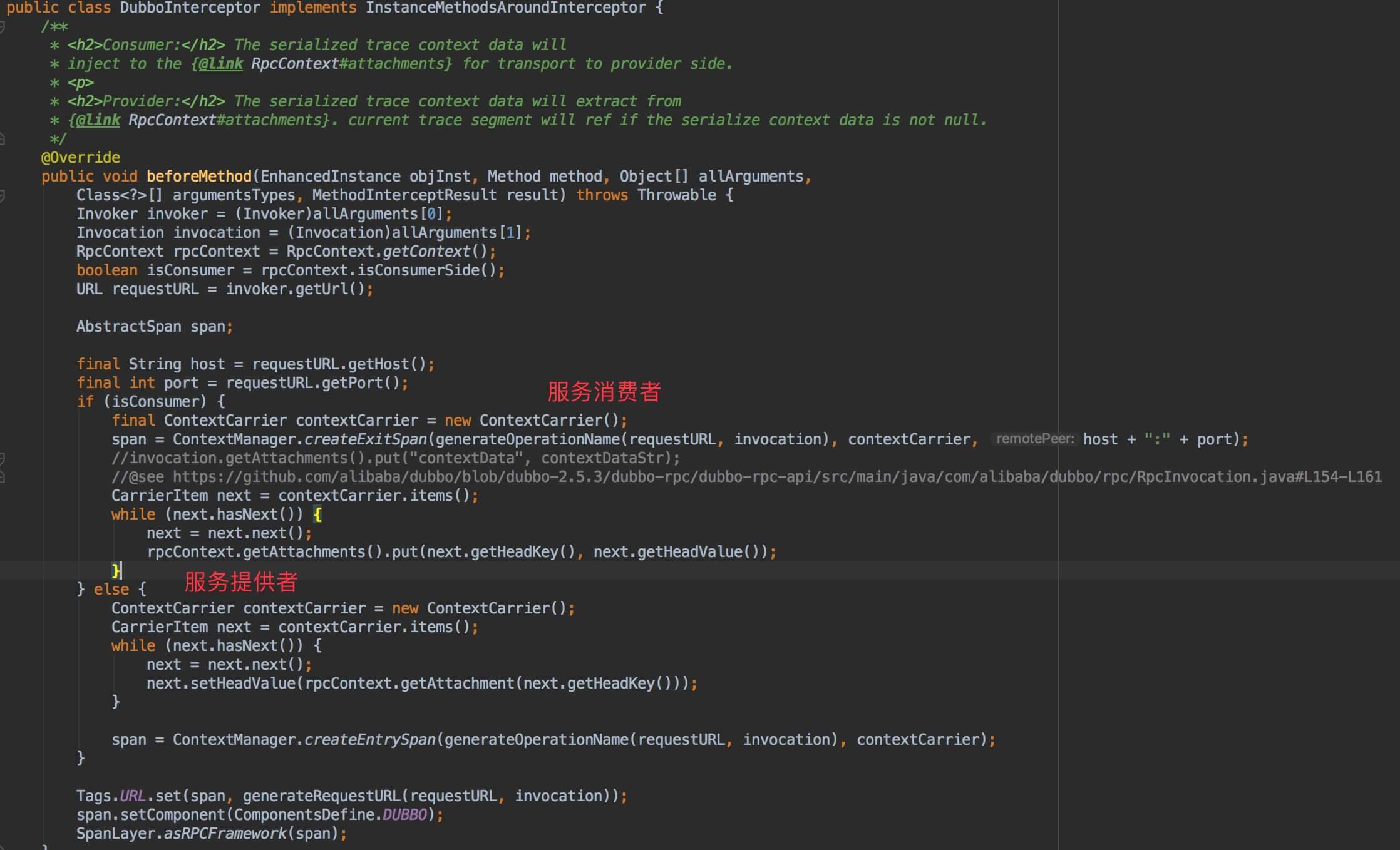
3.2.4 ContextSnapshot
org.skywalking.apm.agent.core.context.ContextSnapshot ,跨线程 Context 传递快照。和 ContextCarrier 基本一致,由于不需要跨进程传输,可以少传递一些属性:
- parentApplicationInstanceId
- peerHost
ContextSnapshot 和 ContextCarrier 比较类似,笔者就列举一些方法:
- #TraceSegmentRef(ContextSnapshot)
- TracingContext#capture()
- TracingContext#continued(ContextSnapshot)
3.3 SamplingService
org.skywalking.apm.agent.core.sampling.SamplingService ,实现 Service 接口,Agent 抽样服务。该服务的作用是,如何对 TraceSegment 抽样收集。考虑到如果每条 TraceSegment 都进行追踪,会带来一定的 CPU ( 用于序列化与反序列化 ) 和网络的开销。通过配置 Config.Agent.SAMPLE_N_PER_3_SECS 属性,设置每三秒,收集 TraceSegment 的条数。默认情况下,不开启抽样服务,即全部收集。
代码如下:
- on 属性,是否开启抽样服务。
- samplingFactorHolder 属性,抽样计数器。通过定时任务,每三秒重置一次。
- scheduledFuture 属性,定时任务。
- #boot() 实现方法,若开启抽样服务( Config.Agent.SAMPLE_N_PER_3_SECS >` 0 ) 时,创建定时任务,每三秒,调用一次 #resetSamplingFactor() 方法,重置计数器。
- #trySampling() 方法,若开启抽样服务,判断是否超过每三秒的抽样上限。若不是,返回 true ,并增加计数器。否则,返回 false 。
- #forceSampled() 方法,强制增加计数器加一。一般情况下,该方法用于链路追踪上下文传播时,被调用服务必须记录链路,参见调用处的代码。
- #resetSamplingFactor() 方法,重置计数器。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: