1. 概述
本文接《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》 ,主要分享 Collector Streaming 流式处理的第二部分。主要包含如下部分:
- AggregationWorker :聚合处理数据,后提交 Data 到 Next 节点们处理。
- PersistenceWorker :聚合处理数据,后存储 Data 。
2. Data
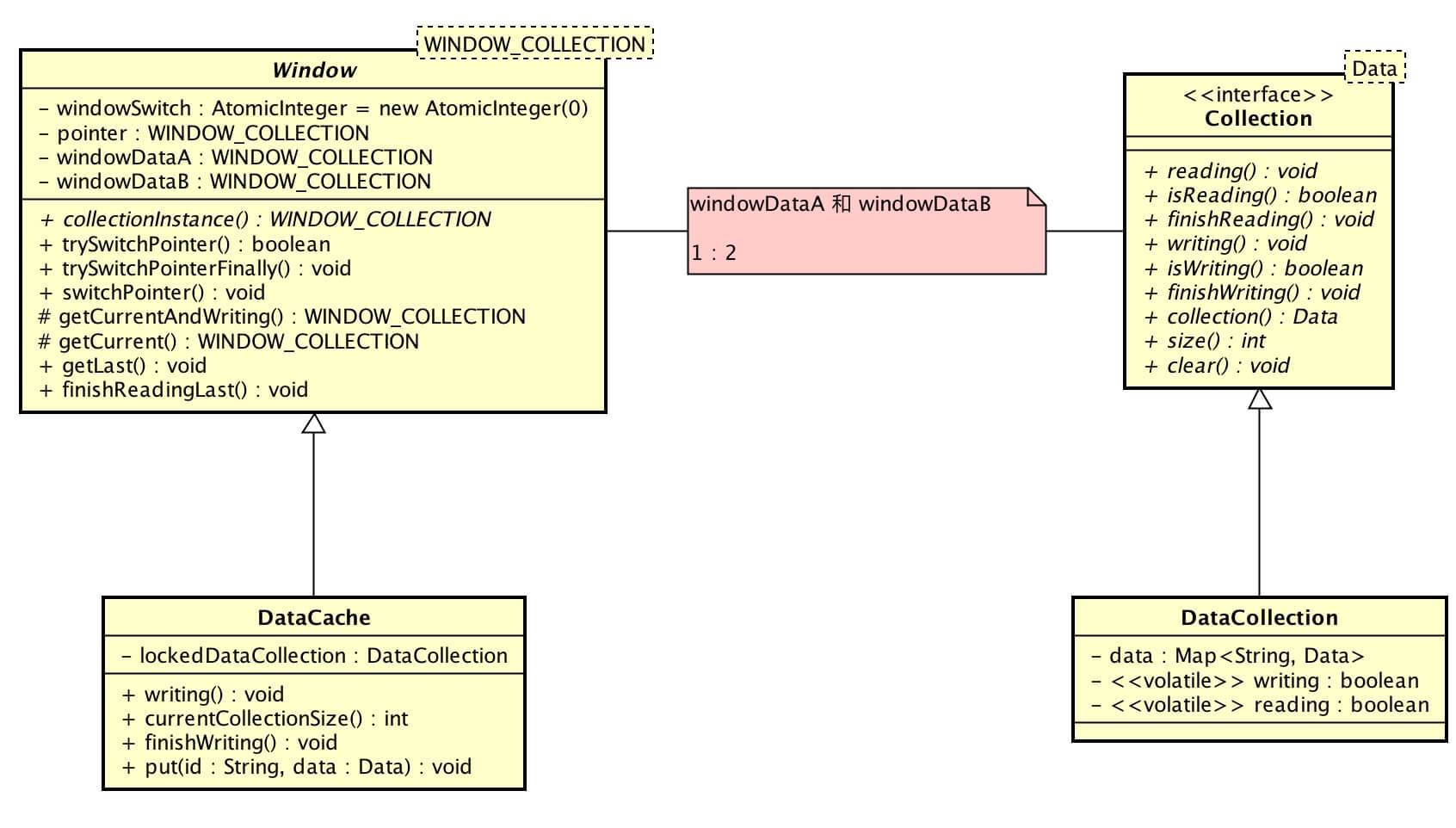
AggregationWorker 和 PersistenceWorker ,都先聚合处理数据,在进行各自的后续处理。那么聚合处理的数据结果,需要有容器进行缓存暂存:
- org.skywalking.apm.collector.core.cache :接口
- org.skywalking.apm.collector.stream.worker.impl.data :实现
类图如下:
-
Collection :数据采集,提供有读、写两个状态的数据容器。
-
Window :窗口( *这个解释怪怪的 ),内有两个 Collection。
-
一个 Collection ,负责写入数据数据
-
一个 Collection ,负责读出处理数据
-
当写的 Collection 符合处理的条件,读写 Collection 切换
2.1 Collection
org.skywalking.apm.collector.core.cache.Collection ,数据采集接口。
- 数据相关 :#collection() / #size() / #clear()
- 读相关 :#reading() / #isReading() / #finishReading()
- 写相关 :#writing() / #isWriting() / #finishWriting()
2.2 DataCollection
org.skywalking.apm.collector.stream.worker.impl.data.DataCollection ,实现 Collection 接口,数据采集实现类,使用 Map<String, Data> 作为数据容器。
2.3 Window
org.skywalking.apm.collector.core.cache.Window ,窗口抽象类。
构造方法 ,代码如下:
-
windowDataA 属性,窗口数据A 。
-
windowDataB 属性,窗口数据B 。
-
通过 #collectionInstance() 抽象方法,创建窗口数据( Collection )对象。
-
pointer 属性,数据指向 windowDataA 或 windowDataA。
- #getCurrent() 方法,获得现数据指向,即 pointer 。
- #getLast() 方法,获得原数据指向,即非 pointer 。
-
windowSwitch 属性,窗口切换计数。
切换 Collection 相关,方法如下:
-
#trySwitchPointer() 方法,返回是否可以切换 Collection 。可以切换需要满足如下条件:
-
只有一个调用方申请切换,通过
windowSwitch属性进行计数。 -
原数据指向不处于正在读取状态。如果切换,一边读一边写,可能会有并发问题。
- 无论是否可以切换 Collection ,需要调用 #trySwitchPointerFinally() 方法,释放 windowSwitch 的计数。
-
#switchPointer() 方法,切换数据指向,并标记原数据指向的 Collection 正在读取中。
-
#finishReadingLast() 方法,清空原数据指向的 Collection 数据,并标记原数据指向的 Collection 完成读取( 不在正在读取中 )。
写Collection 相关,方法如下:
- #getCurrentAndWriting() 方法,获得现数据指向,并标记正在写入中。通过正在写入标记,切换 Collection 完成后,可以判断该 Collection 正在写入中,若是,等待不在写入中,开始数据读取并处理。
2.4 DataCache
org.skywalking.apm.collector.stream.worker.impl.data.DataCache ,实现 Window 抽象类,数据缓存。
- #collectionInstance() 实现方法,创建 DataCollection 对象。
- #currentCollectionSize() 方法,获得当前数据指向( 写入 Collection )的数据数量。
写Collection 相关,方法如下:
-
#writing() 方法,调用 #getCurrentAndWriting() 方法,开始写入。即,获得现数据指向,并标记正在写入中。
-
lockedDataCollection属性,写入的窗口数据。- #put(id, data) 方法,向 lockedDataCollection 属性,写入 Data 。
- #get(id) 方法,向 lockedDataCollection 属性,根据 ID 获得 Data 。
- #containsKey(id) 方法,向 lockedDataCollection 属性,根据 ID 判断 Data 是否存在 。
-
#finishWriting() 方法,完成写入。即,标记 lockedDataCollection 不在正在写入中。
3. AggregationWorker
org.skywalking.apm.collector.stream.worker.impl.AggregationWorker ,实现 AbstractLocalAsyncWorker 抽象类,异步聚合 Worker,负责聚合处理数据,后提交 Data 到 Next 节点们处理。
构造方法 ,代码如下:
- dataCache 属性,数据缓存。
- messageNum 属性,消息计数。当超过一定数量( 目前是 100 ),重置计数归零。
#onWork(message) 实现方法,聚合处理数据,当满足条件时,提交 Data 到 Next 节点们处理。
- 第 53 行:messageNum 计数增加。
- 第 56 行:调用 #aggregate(message) 方法,聚合消息到数据。
- 第 59 至 62 行:messageNum >`= 100 时,调用 #sendToNext() ,提交缓存数据的读 Collection 的数据给 Next 节点们继续处理。
- 第 65 至 67 行:messageNum.endOfBatch == true 时,当消息是批处理的最后一条时,调用 #sendToNext() ,提交缓存数据的读 Collection 的数据给 Next 节点们继续处理。
#sendToNext() 方法,提交缓存数据的读 Collection 的数据给 Next 节点们继续处理。
- 第 72 行:直接调用 Window#switchPointer() 方法,切换数据指针,并标记原指向正在读取中。这里并未先调用 Window#trySwitchPointer() 方法,是否会有并发问题?目前这里是异步单线程,所以不会有问题,参见 《SkyWalking 源码分析 —— Collector Queue 队列组件》 。另外,在 「4. PersistenceWorker」 会看到并发的情况处理。
- 第 74 至 80 行:等待原指向不在读取中。
- 第 82 至 85 行:提交数据给 Next 节点们继续处理。
- 第 87 行:标记原指向完成读取。
4. PersistenceWorker
org.skywalking.apm.collector.stream.worker.impl.PersistenceWorker ,实现 AbstractLocalAsyncWorker 抽象类,异步批量存储 Worker,负责聚合处理数据,后存储 Data 。
考虑到需要保证存储的时效性,PersistenceWorker 使用 PersistenceTimer ,定时存储 Data ,在 「4.2 PersistenceWorker」 详细解析。
构造方法 ,代码如下:
- dataCache 属性,数据缓存。
- batchDAO 属性,批量操作 DAO ,在 《SkyWalking 源码分析 —— Collector Storage 存储组件》 有详细解析。
#needMergeDBData() 抽象方法,存储时,是否需要合并数据。一些 Data 只有新增操作,没有更新操作。
#persistenceDAO() 抽象方法,获得 Data 对应的持久化 DAO 接口的实现类对象。
上述两个抽象方法,用于 #prepareBatch(dataMap) 方法,生成批量操作对象数组,最终调用 IBatchDAO#batchPersistence(List<?>) 方法,通过执行批量操作对象数组,实现批量持久化数据,在 《SkyWalking 源码分析 —— Collector Storage 存储组件》 有详细解析。
#onWork(message) 实现方法,当满足条件时存储 Data ,而后聚合数据。这点和 AggregationWorker 相反的,因为要考虑并发问题。代码如下:
-
第 72 行:调用 DataCache#currentCollectionSize() 方法,获得当前写入 Collection 的数据数量,判断是否超过 5000 。
- 第 75 行:调用 DataCache#trySwitchPointer() 方法,判断是否可以切换 Collection 。通过该判断,保证和 PersistenceTimer 一起时,不会出现并发问题。
- 第 77 行:调用 Window#switchPointer() 方法,切换数据指针,并标记原指向正在读取中。
- 第 80 行:调用 #buildBatchCollection() 方法,创建批量操作对象数组。该方法和 AggregationWorker#sendToNext() 方法基本类似。
- 第 83 行:调用 IBatchDAO#batchPersistence(List
<?>) 方法,通过执行批量操作对象数组,实现批量持久化数据。 - 第 86 行:调用 DataCache#trySwitchPointerFinally() 方法,释放 DataCache.windowSwitch 的计数。
-
第 91 行:调用 #aggregate(message) 方法,聚合数据。该方法和 AggregationWorker#aggregate(message) 方法基本相似。
4.1 WorkerCreateListener
org.skywalking.apm.collector.stream.worker.base.WorkerCreateListener ,Worker 创建监听器。
Worker 在创建时,会调用 WorkerCreateListener#addWorker 方法,记录所有的 PersistenceWorker 对象。
记录下来有什么用呢?在 AgentStreamBootStartup 启动时,创建 PersistenceTimer 对象,并将 WorkerCreateListener 记录的 PersistenceWorker 对象集合传递给 PersistenceTimer 对象。这样,PersistenceTimer 能够”访问“到 PersistenceWorker 对象们的 DataCache ,定时存储数据。
4.2 PersistenceTimer
org.skywalking.apm.collector.stream.timer.PersistenceTimer ,持久化定时任务,负责定时、批量存储 PersistenceWorker 缓存的数据。
#start(IBatchDAO, List<PersistenceWorker>) 方法,创建延迟 1 秒,每 1 秒执行一次 #extractDataAndSave() 方法的定时任务,用于定时、批量存储 PersistenceWorker 缓存的数据。
#extractDataAndSave(IBatchDAO, List<PersistenceWorker>) 方法,代码如下:
-
第 55 至 68 行:获得所有 PersistenceWorker 读 Collection 缓存的数据。
- 第 60 行:调用 PersistenceWorker#flushAndSwitch() 切换数据指针,即切换读写 Collection 。
- 第 62 行:调用 PersistenceWorker#buildBatchCollection() 方法,创建批量操作对象数组。
- 怎么保证并发安全?通过 Window#trySwitchPointer() 方法,保证读 Collection 正在被读取中时,PersistenceWorker 和 PersistenceTimer 有且仅有一个切换队列,读取数据。当读取完成后,调用 Window#finishReadingLast() 方法,清空原数据指向,并标记原数据指向完成正在读取中。
-
第 71 行:调用 IBatchDAO#batchPersistence(List
<?>) 方法,执行批量操作,进行存储。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: