1. 概述
分布式链路追踪系统,链路的追踪大体流程如下:
1、 Agent收集Trace数据;
2、 Agent发送Trace数据给Collector;
3、 Collector接收Trace数据;
4、 Collector存储Trace数据到存储器,例如,数据库;
本文主要分享【第三部分】 SkyWalking Collector 接收 Trace 数据。
友情提示:Collector 接收到 TraceSegment 的数据,对应的类是 Protobuf 生成的。考虑到更加易读易懂,本文使用 TraceSegment 相关的原始类。
大体流程如下:
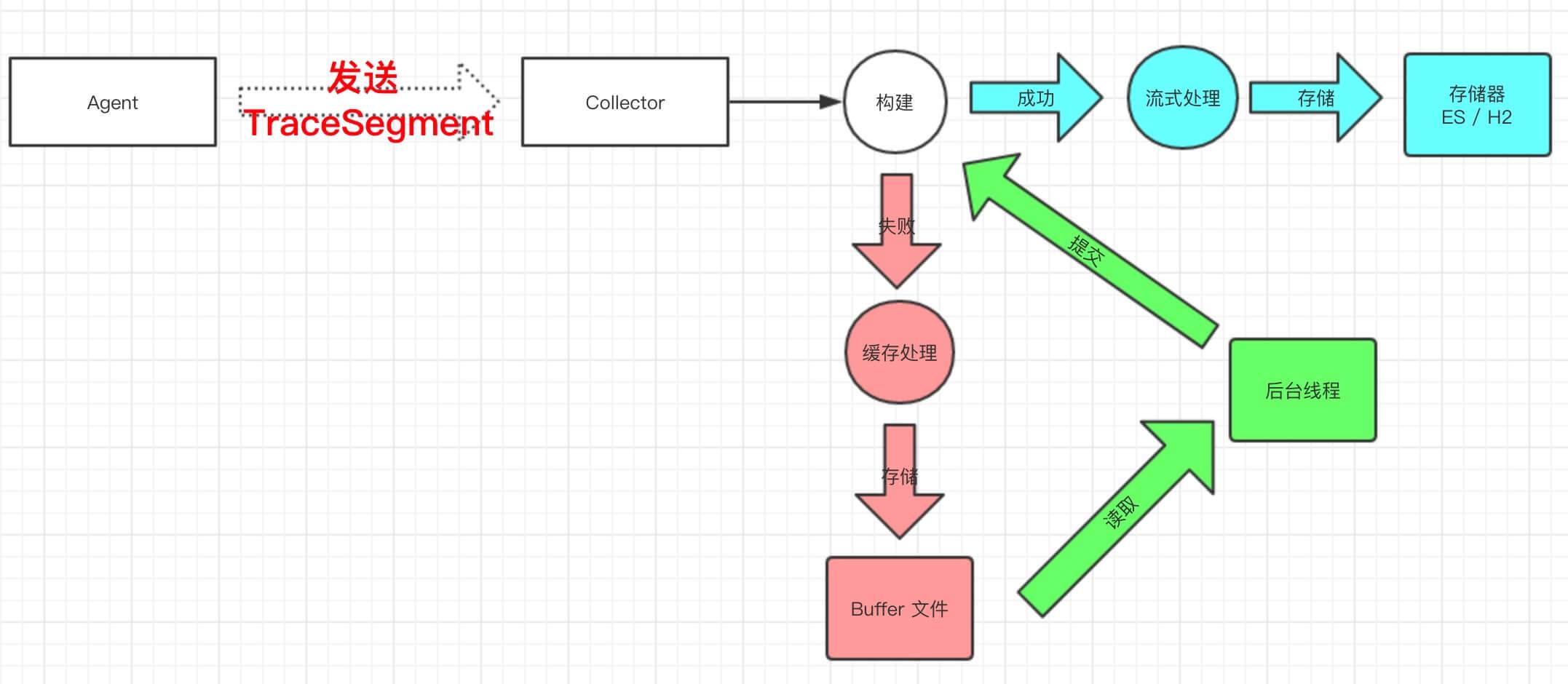
- Collector 接收到 TraceSegment 数据后,进行构建。
- 【蓝色流程】构建成功,进行流式处理,最终存储到存储器( 例如,ES / H2 )。
- 【粉色流程】构建失败,写入 Buffer 文件进行暂存。
- 【绿色流程】后台线程,定时读取 Buffer 文件,重新提交构建。
什么是构建?
从TraceSegment 数据中,会构建出更多的数据维度,如下图所示:
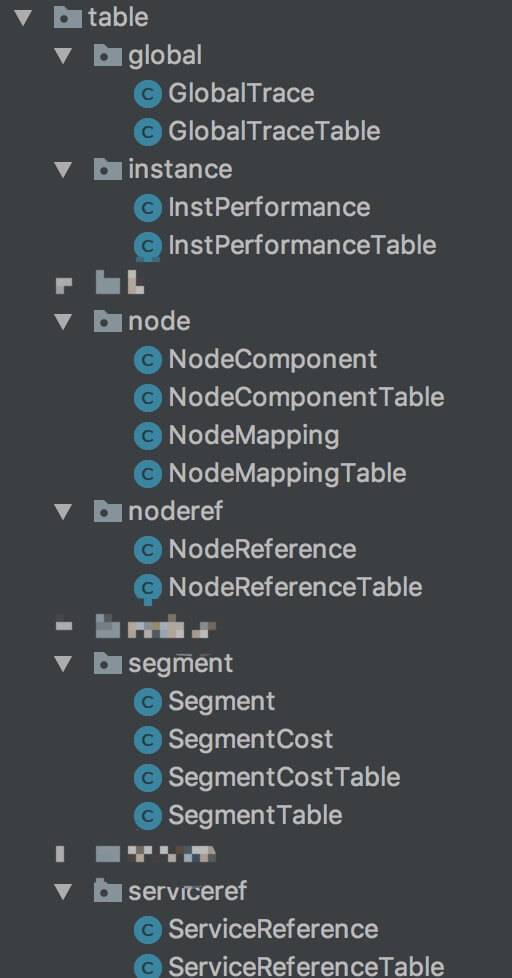
构建的过程,本文只分享调用的过程,具体怎么生成新的数据,数据的流式处理与存储,在 《SkyWalking 源码解析 —— Collector 存储 Trace 数据》 详细解析。
为什么构建会失败?
在TraceSegment 里的数据结构,例如操作名( operationName )和操作编号( operationId ) ,在 《SkyWalking 源码分析 —— Agent 收集 Trace 数据》 中我们可以看到,考虑到网络传输,优先使用 operationId ,若不存在( 例如操作还未注册,或者注册了 Agent 未同步到本地 ),则使用 operationName 。
但是,Collector 构建过程时,要求的是 operationId ,如果传递的是 operationName 时,需要将 operationName 转换成 operationId 。若此时 operationName 未注册时,则无法获取到 operationId ,导致构建失败。
那么有胖友可能有疑惑,在构建过程中,注册 operationName 呢?答案是不行,
在《SkyWalking 源码分析 —— Agent DictionaryManager 字典管理》「2.2 操作的同步 API」 中,我们可以看到,operationName 的注册,是异步的过程。因而,即使构建的过程中,调用注册,也无法获得 operationId 。
涉及的逻辑点比较多,如果胖友理解不能,下面我们可以直接看代码。
2. TraceSegmentServiceHandler
我们先来看看 API 的定义,TraceSegmentService.proto ,如下图所示:
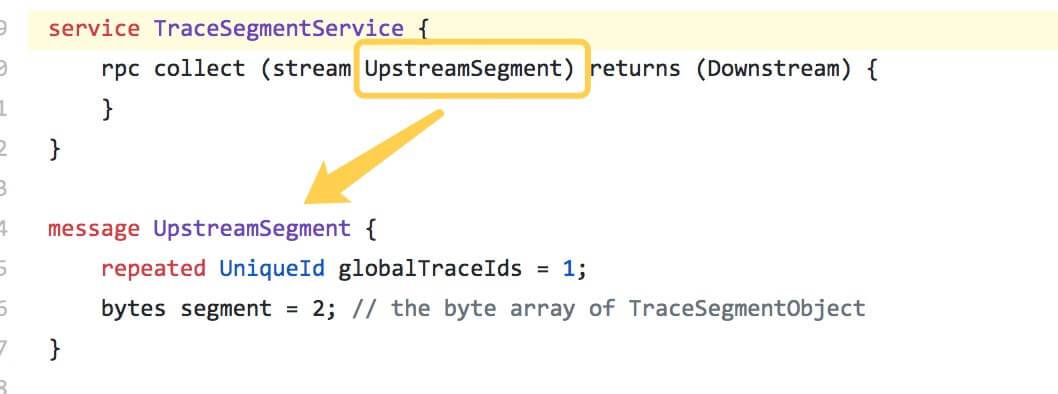
TraceSegmentServiceHandler#collect(Application, StreamObserver<ApplicationMapping>), 代码如下:
- 第 51 行:调用 ITraceSegmentService#send(UpstreamSegment) 方法,处理一条 TraceSegment 。
2.1 TraceSegmentService
org.skywalking.apm.collector.agent.stream.service.trace.ITraceSegmentService ,继承 Service 接口,TraceSegment 服务接口。
- 定义了 #send(UpstreamSegment) 接口方法,处理一条 TraceSegment 。
org.skywalking.apm.collector.agent.stream.worker.trace.ApplicationIDService ,实现 IApplicationIDService 接口,TraceSegment 服务实现类。
-
实现了 #send(UpstreamSegment) 方法,代码如下:
- 第 40 至 41 行:创建 SegmentParse 对象,后调用 SegmentParse#parse(UpstreamSegment, Source) 方法,解析并处理 TraceSegment 。
2.2 SegmentParse
org.skywalking.apm.collector.agent.stream.parser.SegmentParse ,Segment 解析器。属性如下:
- spanListeners 属性,Span 监听器集合。通过不同的监听器,对 TraceSegment 进行构建,生成不同的数据。在 #SegmentParse(ModuleManager) 构造方法 ,会看到它的初始化。
- segmentId 属性,TraceSegment 编号,即 TraceSegment.traceSegmentId 。
- timeBucket 属性,第一个 Span 的开始时间。
#parse(UpstreamSegment, Source) 方法,解析并处理 TraceSegment 。在该方法里,我们会看到,本文开头提到的【构造】。整个构造的过程,实际分成两步:1)预构建;2)执行构建。代码如下:
-
第 88 至 89 行:从 segment 参数中,解析出 :
-
traceIds,关联的链路追踪全局编号。 -
segmentObject,TraceSegmentObject 对象。 -
第 91 行:创建 SegmentDecorator 对象。该对象的用途,在 「2.3 Standardization 标准化」 统一解析。
-
——– 构建失败 ——–
-
第 94 行:调用 #preBuild(List
<UniqueId>, SegmentDecorator) 方法,预构建。 -
第 97 至 99 行:调用 #writeToBufferFile() 方法,将 TraceSegment 写入 Buffer 文件暂存。为什么会判断 source == Source.Agent 呢?#parse(UpstreamSegment, Source) 方法的调用,共有两个 Source :
-
目前我们看到 TraceSegmentService 的调用使用的是
Source.Agent。 -
而后台线程,定时调用该方法重新构建使用的是
Source.Buffer,如果不加盖判断,会预构建失败重复写入。 -
第 100 行:返回 false ,表示构建失败。
-
——– 构建成功 ——–
-
第 106 行:调用 #notifyListenerToBuild() 方法,通知 Span 监听器们,执行构建各自的数据。在 《SkyWalking 源码解析 —— Collector 存储 Trace 数据》 详细解析。
-
第 109 行:调用 buildSegment(id, dataBinary) 方法,执行构建 TraceSegment 。
-
第 110 行:返回 true ,表示构建成功。
-
第 112 至 115 行:发生 InvalidProtocolBufferException 异常,返回 false ,表示构建失败。
2.2.1 预构建
#preBuild(List<UniqueId>, SegmentDecorator) 方法,前置构建,用于通过不同的监听器,对 TraceSegment 进行构建,生成不同的数据。在该过程中,会发生我们在文章头所说的,”为什么构建会失败“。代码如下:
-
第 120 至 128 行:拼接生成 segmentId 。
-
第 131 至 133 行:调用 #notifyGlobalsListener(...) 方法,使用 GlobalTraceSpanListener 处理链路追踪全局编号数组( TraceSegment.relatedGlobalTraces )。
-
第 139 至 147 行:调用 #notifyRefsListener(...) 方法,使用 RefsListener 处理父 Segment 指向数组( TraceSegment.refs )。
- 第 140 至 144 行:调用 ReferenceIdExchanger#exchange(ReferenceDecorator, applicationId) 方法,将 TraceSegmentRef 未生成编号的属性,进行兑换处理。若兑换失败,返回构造失败。在 「2.3 Standardization 标准化」 详细解析。
-
第 149 至 172 行:处理 TraceSegment.spans 属性。
-
第 150 至 154 行:将 Span 未生成编号的属性,进行兑换处理。若兑换失败,返回构造失败。在 「2.3 Standardization 标准化」 详细解析。
- 第 157 至 160 行:调用 #notifyFirstListener(...) ,使用 FirstSpanListener 处理第一个 Span 。
- 第 164 行:若是 ExitSpan ,调用 #notifyExitListener(...) ,使用 ExitSpanListener 处理。
- 第 166 行:若是 EntrySpan ,调用 #notifyEntryListener(...) ,使用 EntrySpanListener 处理。
- 第 168 行:若是 LocalSpan ,调用 #notifyLocalListener(...) ,使用 LocalSpanListener 处理。
-
第 174 行:返回 true ,预构建成功。
2.2.2 写入 Buffer 文件
#writeToBufferFile(id, upstreamSegment) 方法,将 TraceSegment 写入 Buffer 文件。代码如下:
- 第 193 行:创建 193 至 194 行:创建 org.skywalking.apm.collector.agent.stream.parser.standardization.SegmentStandardization 对象,并设置 TraceSegment 属性。
- 第 195 行:获得 TraceStreamGraph.SEGMENT_STANDARDIZATION_GRAPH_ID 对象的 Graph 对象。在 TraceStreamGraph#createSegmentStandardizationGraph() 方法中,我们可以看到,该 Graph 对象只有一个 SegmentStandardizationWorker 。
- 第 196 行:调用 Graph#start(INPUT) 方法,执行该 Graph 实现的流式处理,将 TraceSegment 写到 Buffer 文件。
org.skywalking.apm.collector.agent.stream.parser.standardization.SegmentStandardizationWorker ,继承 AbstractLocalAsyncWorker 抽象类,TraceSegment 标准化 Worker ,负责将接收到的 TraceSegment 异步写到 Buffer 文件。
-
Factory 内部类,实现 AbstractLocalAsyncWorkerProvider 抽象类,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》「3.2.2 AbstractLocalAsyncWorker」 有详细解析。
-
AbstractLocalAsyncWorker ,在 《SkyWalking 源码分析 —— Collector Streaming Computing 流式处理(一)》「3.2.2 AbstractLocalAsyncWorker」 有详细解析。
-
#id() 实现方法,返回 108 。
-
#onWork(SegmentStandardization) 实现方法,将接收到的 TraceSegment 异步写到 Buffer 文件。。代码如下:
- 第 52 行:调用 SegmentBufferManager#writeBuffer(UpstreamSegment) 方法,将接收到的 TraceSegment 写到 Buffer 文件。在 「3. Buffer 文件」 详细解析。
-
Factory#workerInstance(ModuleManager) 方法,创建 SegmentStandardizationWorker 后,会调用 #startTimer(SegmentStandardizationWorker) 方法,创建定时任务。该定时任务调用 #flushAndSwitch() 方法,定时将 Buffer 文件 flush 。目前 SegmentBufferManager#flush() 是个空方法。为什么不这里不需要 flush 呢?因为 SegmentBufferManager#writeBuffer(UpstreamSegment) 已经进行 flush 。
2.3 Standardization 标准化
本小节涉及到的类如下图:
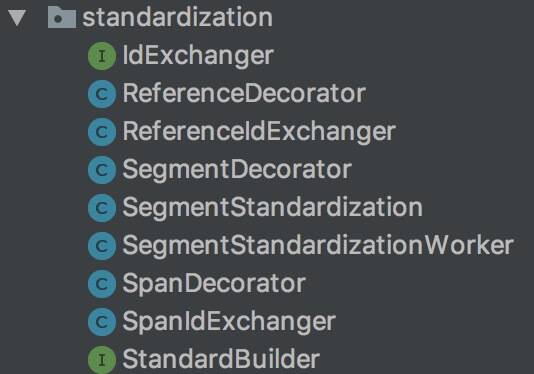
我们先来说说,什么叫 standardization 标准化?其实就是我们在文章开头说的”例如将 operationName 转换成 operationId“。
2.3.1 StandardBuilder
org.skywalking.apm.collector.agent.stream.parser.standardization.StandardBuilder ,标准化 Builder 接口。
- 定义了 #toBuilder() 接口方法,转换成 Builder 。感觉这个接口方法怪怪的?不要捉急,等会看一个实现类就明白了。
StandardBuilder 有三个实现类:
- SegmentDecorator ,TraceSegment 装饰者。
- ReferenceDecorator ,ReferenceDecorator 装饰者。
- SpanDecorator ,Span 装饰者。
怎么都是装饰者呢,而且恰好和一个数据结构对应?以 SpanDecorator 为例子,代码如下:
-
spanObject 属性,SpanObject ,Span 的 Protobuf 数据对象。
-
standardBuilder 属性,SpanObject 的 Builder 对象。
-
isOrigin 属性,是否是原始对象。
-
isOrigin = true,使用spanObject属性 。 -
isOrigin = false,使用standardBuilder属性。 -
在 Protobuf 里,数据修改值时,需要使用对应的 Builder 对象。通过使用装饰者设计模式,对使用者屏蔽细节,调用也更加方便。下面在来看看如下方法,是不是就更加明白了:
-
#toBuilder() 实现方法,创建 SpanObject 对应的 Builder ,并修改 isOrigin = false 。另外,会调用 standardBuilder 属性的 #toBuilder() 方法,目前在项目里,此处的 standardBuilder 属性为 SegmentDecorator 。
SegmentDecorator 、ReferenceDecorator 和 SpanDecorator 目的一致。
2.3.2 IdExchanger
org.skywalking.apm.collector.agent.stream.parser.standardization.IdExchanger ,编号兑换器接口。
- 定义了 #exchange(standardBuilder, applicationId) 接口方法,兑换 standardBuilder 里的属性,并返回是否兑换成功。
IdExchanger 有三个实现类:
- ReferenceIdExchanger :TraceSegmentRef 编号兑换器。
- SpanIdExchanger :Span 编号兑换器。
ReferenceIdExchanger#exchange(standardBuilder, applicationId) 方法,代码如下:
-
第 60 至 73 行:TraceSegmentRef.entryOperationId 为空,将 TraceSegmentRef.entryOperationName 进行兑换。
- 第 61 行:调用 ServiceNameService#getOrCreate(applicationId, serviceName) 方法,根据应用编号和操作名获得或创建操作编号。
-
第 62 至 67 行:获得不到,因为创建的过程是异步的。返回
false。- 第 68 至 72 行:获得到,调用 ReferenceDecorator#toBuilder() 方法,创建 Builder ,然后设置操作编号。
-
第 75 至 89 行:TraceSegmentRef.parentApplicationInstanceId 为空,将 TraceSegmentRef.parentOperationName 进行兑换。
-
第 92 至 104 行:TraceSegmentRef.entryOperationName 为空,将 TraceSegmentRef.peerHost 进行兑换。在【第 93 行】,我们可以看到,调用 ApplicationIDService#getOrCreate(applicationCode) 方法,将服务地址作为 applicationCode 使用。
SpanIdExchanger#exchange(standardBuilder, applicationId) 方法,类似,已经添加代码注释,胖友自己阅读理解。
3. Buffer 文件
本小节涉及到的类如下图:
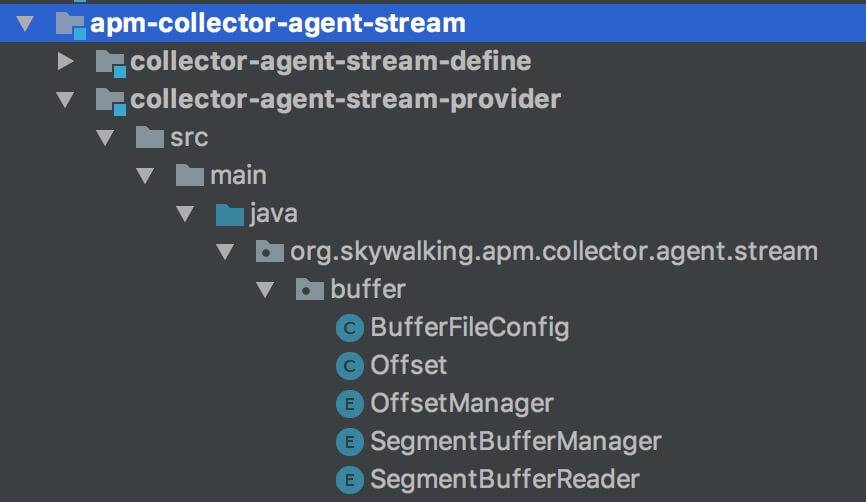
我们先来看看 Buffer 包括哪些文件:
|
- Data 文件,记录 TraceSegment 具体数据,通过 SegmentBufferManager 管理。
- Offset 文件,记录偏移,包括写入文件的名字和偏移,读取文件的名字和偏移,通过 OffsetManager 管理。
- 从命名上,我们可以看出,这两种文件,文件名字格式为 类型_
${时间}.sw ,并且相同类型,同时可以存在多个。
org.skywalking.apm.collector.agent.stream.buffer.BufferFileConfig ,Buffer 文件配置 。
org.skywalking.apm.collector.agent.stream.buffer.Offset ,偏移 。
下面,我们来一起看看 Buffer 文件的初始化、写入、读取的三种操作过程。
3.1 初始化
SegmentBufferManager#initialize(ModuleManager) 方法,初始化 Offset 文件、Data 文件、定期读取 Buffer 文件的任务。代码如下:
-
第 58 行:调用 OffsetManager#initialize() 方法,初始化 Offset 文件。
-
第 60 至 63 行:创建 Buffer 文件夹成功( 意味着该文件夹不存在 ),调用 #newDataFile() ,创建 Data 文件。代码如下:
-
第 116 至 119 行:创建新的 Data 文件。文件名格式为,
data_${yyyyMMddHHmmss}.sw。- 第 121 行:调用 OffsetManager#setWriteOffset(writeFileName, writeFileOffset) 方法,设置 Offset 的写入的文件名和偏移。
-
第 124 至 126 行:关闭老的 Data 文件的
outputStream。 -
第 129 至 130 行:创建新的 Data 文件的
outputStream。 -
第 66 至 77 行:获得 Offset 的写入的 Data 文件,并创建对应的 outputStream 。
-
第 80 行:调用 SegmentBufferReader#initialize(ModuleManager) 方法,初始化定期读取 Buffer 文件的任务。
OffsetManager#initialize() 方法,初始化 Offset 文件。代码如下:
-
第 74 行:创建 Offer 对象。该对象包含了当前分别写入和读取的文件名与偏移量。
-
第 60 至 63 行:创建 Buffer 文件夹成功( 意味着该文件夹不存在 ),调用 #createOffsetFile() ,创建 Data 文件。代码如下:
-
第 114 至 116 行:创建新的 Offset 文件。文件名格式为,
offset_${yyyyMMddHHmmss}.sw。 -
第 118 至 121 行:设置 Offset 对象的写入和读取的文件名与偏移量都为空。在上面的方法,此处的【空】,在 Data 文件创建时,会重新设置 Offset 。
-
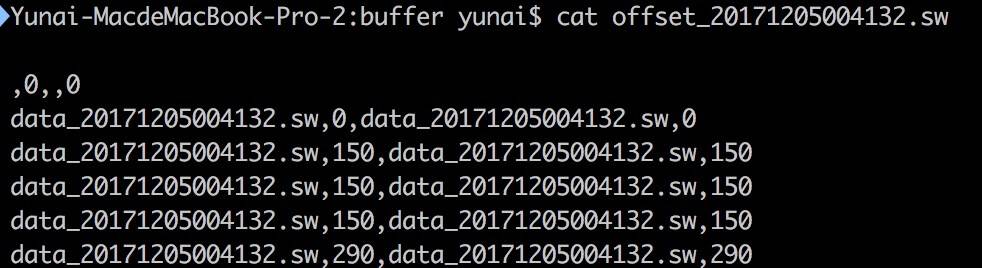
第 123 行:调用 #flush() 方法,写入 Offset 对象到 Offset 文件。代码如下:
- 第 131 行:调用 Offset#serialize() 方法,序列化读写偏移,格式为
${读取文件名},${读取文件偏移量},${写入文件名},${写入文件偏移量} 。
- 第 131 行:调用 Offset#serialize() 方法,序列化读写偏移,格式为
-
第 133 至 142 行:写入 Offset 对象到 Offset 文件。写入方式为整行,如下图所示:
-
-
第 82 至 94 行:获得所有 Offset 文件,删除老的 Offset 文件,保留最后一个。若不存在 Offset 文件,则调用 #createOffsetFile() 方法,创建新的 Offset 文件。
-
第 98 至 99 行:从 Offset 文件的最后一行读取,反序列化到 Offset 对象。
-
第 103 行:创建定义任务,延迟 10 秒,间隔 3 秒,调用 #flush() 方法,定时写入 Offset 对象到 Offset 文件。注意,所以 Offset 改变时,不是立即写入 Offset 文件,而是周期性刷盘。
SegmentBufferReader#initialize(ModuleManager) 方法,初始化定期读取 Buffer 文件的任务。代码如下:
- 第 56 行:创建定时任务,延迟 3 秒,间隔 3 秒,调用 #preRead() 方法,读取 Buffer 文件,将 TraceSegment 提交给 SegmentParse 重新解析与构建处理。
3.2 写入
SegmentBufferManager#writeBuffer(UpstreamSegment) 方法,将 TraceSegment 写入 Buffer 文件,包括两个步骤:1)将 TraceSegment 写入 Data 文件;2)更新 Offset 文件的偏移。代码如下:
- 第 94 至 95 行:调用 AbstractMessageLite#writeDelimitedTo(OutputStream) 方法,将 TraceSegment 写入 Data 文件。该方法包括 flush 操作,代码如下:
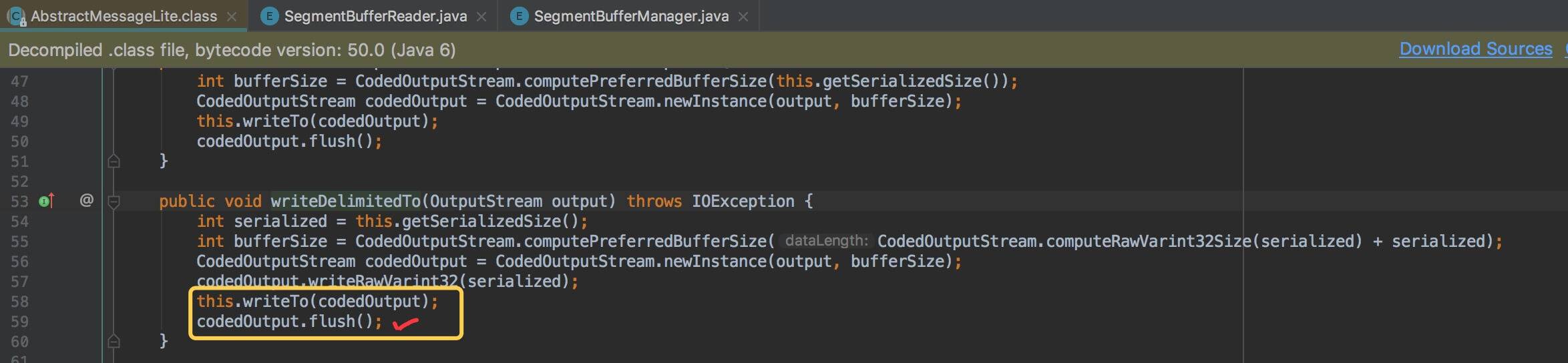
- 第 97 至 98 行:超过 Buffer 单文件容量上限,调用 #newDataFile() ,创建 Data 文件。
- 第 99 至 102 行:调用 OffsetManager#setWriteOffset(position) 方法,设置 Offset 对象的写入偏移。
3.3 读取
SegmentBufferReader#preRead() 方法,读取 Buffer 文件,将 TraceSegment 提交给 SegmentParse 重新解析与构建处理。另外该方法,会删除已经读取完成的 Data 文件。代码如下:
-
——– 读取文件存在
-
该情况发生于,Data 文件未被读取完成
-
第 65 行:调用 #deleteTheDataFilesBeforeReadFile(readFileName) 方法,删除比指定文件早创建的 Data 文件,基于文件名带有创建时间。
-
第 67 至 68 行:调用 #read() 方法,读取 Buffer 文件,将 TraceSegment 提交给 SegmentParse 重新解析与构建处理。另外,返回 true ,文件被全部读取完成、处理并删除。返回 false ,文件未被全部读取完成。
-
第 133 至 134 行:创建 FileInputStream 对象,并跳转到读取位置。
-
第 137 至 141 行:获取读取结束的位置。
-
第 143 至 159 行:循环读取处理,直到到达读取文件上限位置
- 第 144 至 146 行:从 Data 文件,读取一条 TraceSegment 。
- 第 149 至 152 行:将 TraceSegment 提交给 SegmentParse 重新解析与构建处理。若解析处理失败,返回
false,结束循环,等待下次读取处理。 - 第 155 至 158 行:设置 Offset 对象的读取偏移。
-
第 161 至 165 行:全部读取处理完成,关闭 InputStream ,同时删除读取的 Data 文件。
-
第 166 至 169 行:发生 IOException 异常,返回
false。 -
第 170 行:返回
true,文件被全部读取完成、处理并删除。 -
第 75 行:调用 #readEarliestCreateDataFile() 方法,循环顺序读取 Data 文件,直到有一个没读完。
- 第 112 至 118 行:若第一个 Data 文件和 Offset 读取的文件相同,返回。说明,在上一次 #read() 方法里,没有读完。
- 第 121 至 127 行:循环顺序调用 #read(readFile, readFileOffset) 方法,读取 Data 文件,直到有一个没读完。
-
——– 读取文件不存在 ——–
-
该情况发生于,Data 文件被全部读取完成,并且删除。
-
第 73 行:调用 #deleteTheDataFilesBeforeReadFile(readFileName) 方法,删除比指定文件早创建的 Data 文件。
-
第 75 行:调用 #readEarliestCreateDataFile() 方法,循环顺序读取 Data 文件,直到有一个没读完。
-
——– 没有可读取的文件 ——–
-
该情况发生于,Data 文件、Buffer 文件首次初始化创建,未设置可读文件名。
-
第 79 行:调用 #readEarliestCreateDataFile() 方法,循环顺序读取 Data 文件,直到有一个没读完。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: