Kafka的备份机制
Kafka的备份的单元是partition,也就是每个partition都都会有leader partiton和follow partiton。其中leader partition是用来进行和producer进行写交互,follow从leader副本进行拉数据进行同步,从而保证数据的冗余,防止数据丢失的目的。
如图:
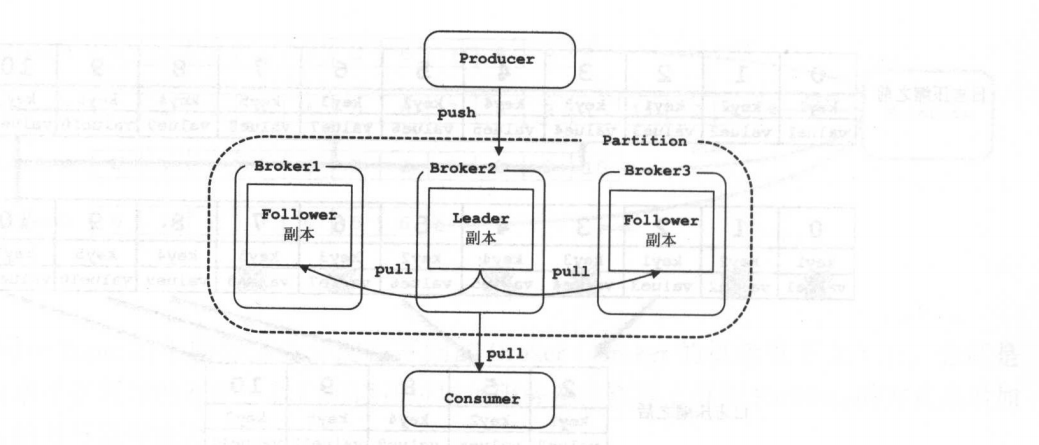
follow副本是如何实现和leader副本进行数据同步的
首先我们了解下一些必要的专有名词:
- ISR集合:ISR(In-Sync Replica)集合代表的是follow副本和leader副本消息相差不多的副本的集合。消息相差不到是一个比较模糊的概念。其实follow副本需要满足以下两个条件:
1:follow副本必须和zookeeper保持连接。
2:follow副本的最后的offset和leader中最新的数据之间的大小不能超过阈值。(也就是每个follow不能和leader副本消息相差太多)。
Note:由于网络原因和宕机等原因免不了试follow副本会不能满足其中以上的条件(我理解的为任意一个条件),那么该follow副本将会被T出ISR集合中。举例:如果follow副本不满足上面条件2,此刻会被T出ISR集合,但是这个follow副本依然会进行数据的拉取,并且进行追赶,如果最新的offset和leader副本之间的数据量小于了阈值,那么该follow副本会从新加入到ISR集合中。 - HW(HighWaterMark)顾名思义是一个标记。是用来标记当follow副本从leader副本中拉取消息并且同步到自身后,然后做在leader副本上做个HW来表明,此前的所有消息都在follow的副本上commit了。
- LEO(Log End Offset)简单粗暴的理解就是记录leader副本中最新的offset的位置,然后记录在自己的log日志里。
让我们通过图例来看下follow副本是如何进行复制数据的:
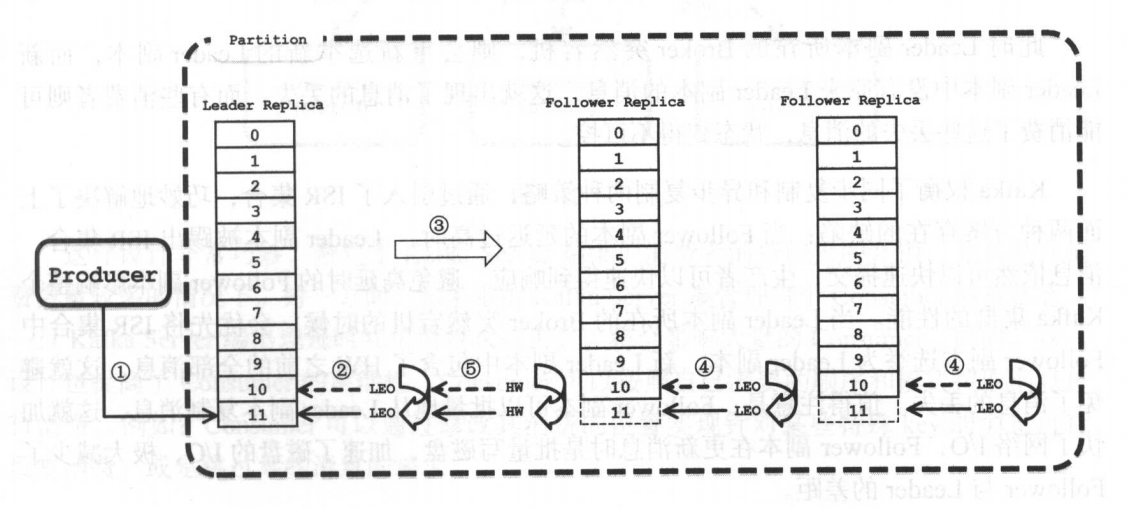
follow的同步和异步复制数据
同步复制:就是所有的follow副本都进行进行同步数据后才进行HW。这样就导致如果其中的一个follow副本不管因为网络还是其他原因导致的迟迟不能同步数据成功的话。那么HW永远也不会进行,这样直接导致follow副本复制不可用。
异步复制:异步复制避免了同步复制的缺点,但是不保证从leader副本拉取数据都同步到follow副本中。如图:
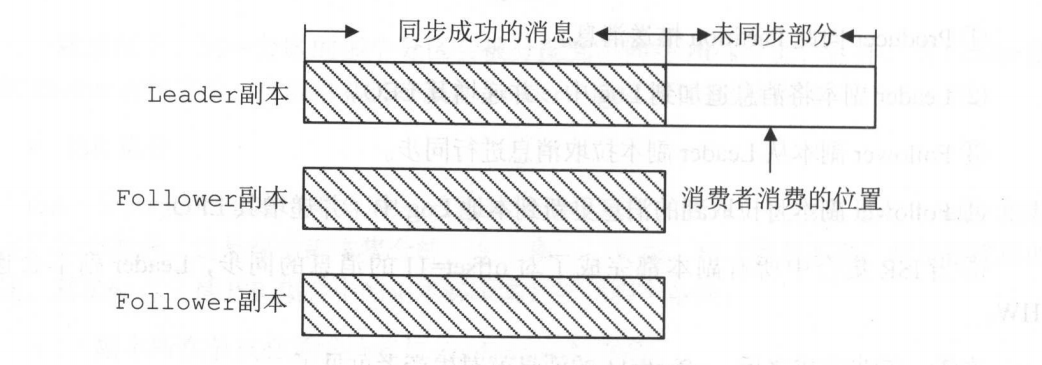
kafka采取同步和异步的共同优点,所以使用ISR的方法。把Follow中同步慢的数据进行T除,从而保证了复制数据的速度。一句话总结就是用同步的方法,如果其中有同步数据慢的follow的情况,直接把该follow给T除。如果leader副本宕机,那么从ISR中选举出来新的leader副本。因为follow副本中都有记录HW。这样也会减少数据的丢失。Follow副本能够从leader中批量的读取数据并批量写入,从而减少了I/0的开销。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: