文章目录
-
- 一、导入maven包
- 二、编写第一个Streams应用程序:将一个topic写入另一个topic
- 三、Line Split
- 四、单行映射成多行
一、导入maven包
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>2.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.1.1</version>
</dependency>
二、编写第一个Streams应用程序:将一个topic写入另一个topic
编写Streams应用程序的第一步是创建一个java.util.Properties映射,以指定不同的Streams执行配置值StreamsConfig。您需要设置的几个重要配置值是:StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,它指定用于建立与Kafka集群的初始连接的主机/端口对的列表,并且StreamsConfig.APPLICATION_ID_CONFIG它提供Streams应用程序的唯一标识符以区别于其他应用程序与同一Kafka集群通信:
//程序的唯一标识符以区别于其他应用程序与同一Kafka集群通信
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"zj");
//用于建立与Kafka集群的初始连接的主机/端口对的列表
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.137:9092");
此外,您可以在同一映射中自定义其他配置,例如,记录键值对的默认序列化和反序列化库:
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
接下来,我们将定义Streams应用程序的计算逻辑。在Kafka Streams中,该计算逻辑被定义为topology连接的处理器节点之一。我们可以使用拓扑构建器来构建这样的拓扑
final StreamsBuilder builder = new StreamsBuilder();
builder.stream("demo3").to("test2");
并将其描述打印到标准输出为
System.out.println(topology.describe());
如果我们停在这里,编译并运行程序,它将输出以下信息:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [my-replicated-topic])
--> KSTREAM-SINK-0000000001
Sink: KSTREAM-SINK-0000000001 (topic: skindow-toptic)
<-- KSTREAM-SOURCE-0000000000
如上所示,它说明构造的拓扑具有两个处理器节点,源节点KSTREAM-SOURCE-0000000000和汇聚节点KSTREAM-SINK-0000000001。 KSTREAM-SOURCE-0000000000连续读取Kafka主题的记录my-replicated-topic并将它们传送到下游节点KSTREAM-SINK-0000000001; KSTREAM-SINK-0000000001将写入每个接收到的记录以便另一个Kafka主题skindow-toptic (–>和<–箭头指示该节点的下游和上游处理器节点,即拓扑图中的“子节点”和“父节点”)。它还说明了这个简单的拓扑没有与之关联的全局状态存储 java.util.Properties 实例中指定的配置映射和的Topology对象。
final KafkaStreams stream = new KafkaStreams(topo,prop);
通过调用它的start()函数,我们可以触发该客户端的执行。close()在此客户端上调用之前,执行不会停止。例如,我们可以添加带倒计时锁存器的关闭钩子来捕获用户中断并在终止此程序时关闭客户端:
final CountDownLatch latch = new CountDownLatch(1);
// 附加关闭处理程序来捕获control-c
Runtime.getRuntime().addShutdownHook(new Thread("zj01"){
@Override
public void run(){
stream.close();
latch.countDown();
}
});
try {
stream.start();
latch.await();
}catch (InterruptedException e){
//是非正常退出,就是说无论程序正在执行与否,都退出
System.exit(1);
}
//正常退出,程序正常执行结束退出
System.exit(0);
}
}
完整的代码如下所示:
package com.njbdqn.services;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class MyStream {
public static void main(String[] args) {
Properties prop = new Properties();
//程序的唯一标识符以区别于其他应用程序与同一Kafka集群通信
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"zj");
//用于建立与Kafka集群的初始连接的主机/端口对的列表
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.137:9092");
//记录键值对的默认序列化和反序列化库
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//定义Streams应用程序的计算逻辑,计算逻辑被定义为topology连接的处理器节点之一,构建流构建工具
final StreamsBuilder builder = new StreamsBuilder();
//将demo3写入另一个Kafka toptic(test2) 类似于算子组成的图模型
builder.stream("demo3").to("test2");
//构建Topology对象
final Topology topo = builder.build();
//构建 kafka流 API实例 将算子以及操作的服务器配置到kafka流
final KafkaStreams stream = new KafkaStreams(topo,prop);
final CountDownLatch latch = new CountDownLatch(1);
// 附加关闭处理程序来捕获control-c
Runtime.getRuntime().addShutdownHook(new Thread("zj01"){
@Override
public void run(){
stream.close();
latch.countDown();
}
});
try {
stream.start();
latch.await();
}catch (InterruptedException e){
//是非正常退出,就是说无论程序正在执行与否,都退出
System.exit(1);
}
//正常退出,程序正常执行结束退出
System.exit(0);
}
}
三、Line Split
由于每个源流的记录都是一个String键入的键值对,让我们将值字符串视为文本行,并将其拆分为带有FlatMapValues运算符的单词:
builder.stream("demo3").flatMapValues(new ValueMapper<Object, Iterable<Object>>() {
@Override
public Iterable<Object> apply(Object s) {
return Arrays.asList(s.toString().split(","));
}
});
完整的代码如下所示:
package com.njbdqn.services;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.ValueMapper;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class MyStream {
public static void main(String[] args) {
Properties prop = new Properties();
//程序的唯一标识符以区别于其他应用程序与同一Kafka集群通信
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"zj");
//用于建立与Kafka集群的初始连接的主机/端口对的列表
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.137:9092");
//记录键值对的默认序列化和反序列化库
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//定义Streams应用程序的计算逻辑,计算逻辑被定义为topology连接的处理器节点之一,构建流构建工具
final StreamsBuilder builder = new StreamsBuilder();
builder.stream("demo3").flatMapValues(new ValueMapper<Object, Iterable<Object>>() {
@Override
public Iterable<Object> apply(Object s) {
return Arrays.asList(s.toString().split(","));
}
});
//构建Topology对象
final Topology topo = builder.build();
//打印算子结果
System.out.println(topo.describe().toString());
//构建 kafka流 API实例 将算子以及操作的服务器配置到kafka流
final KafkaStreams stream = new KafkaStreams(topo,prop);
final CountDownLatch latch = new CountDownLatch(1);
// 附加关闭处理程序来捕获control-c
Runtime.getRuntime().addShutdownHook(new Thread("zj01"){
@Override
public void run(){
stream.close();
latch.countDown();
}
});
try {
stream.start();
latch.await();
}catch (InterruptedException e){
//是非正常退出,就是说无论程序正在执行与否,都退出
System.exit(1);
}
//正常退出,程序正常执行结束退出
System.exit(0);
}
}
四、单行映射成多行
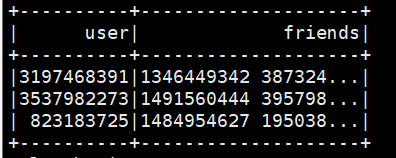
package com.njbdqn.services;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.ValueMapper;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class MyStream {
public static void main(String[] args) {
Properties prop = new Properties();
//程序的唯一标识符以区别于其他应用程序与同一Kafka集群通信
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"zj");
//用于建立与Kafka集群的初始连接的主机/端口对的列表
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.122:9092");
//记录键值对的默认序列化和反序列化库
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//定义Streams应用程序的计算逻辑,计算逻辑被定义为topology连接的处理器节点之一,构建流构建工具
final StreamsBuilder builder = new StreamsBuilder();
builder.stream("demo4").filter((k,v)->v.toString().split(",").length==2)
.flatMap((k,v)->{
List<KeyValue<String,String>> keyValues = new ArrayList<>();
String[] info = v.toString().split(",");
String[] friends = info[1].split(" ");
for (String friend:friends){
keyValues.add(new KeyValue<String, String>(info[0].toString(),friend));
}
return keyValues;
}).foreach(((k,v)-> System.out.println(k+"======="+v)));
//构建Topology对象
final Topology topo = builder.build();
//打印算子结构
// System.out.println(topo.describe().toString());
//构建 kafka流 API实例 将算子以及操作的服务器配置到kafka流
final KafkaStreams stream = new KafkaStreams(topo,prop);
final CountDownLatch latch = new CountDownLatch(1);
// 附加关闭处理程序来捕获
Runtime.getRuntime().addShutdownHook(new Thread("zj01"){
@Override
public void run(){
stream.close();
latch.countDown();
}
});
try {
stream.start();
latch.await();
}catch (InterruptedException e){
//是非正常退出,就是说无论程序正在执行与否,都退出
System.exit(1);
}
//正常退出,程序正常执行结束退出
System.exit(0);
}
}
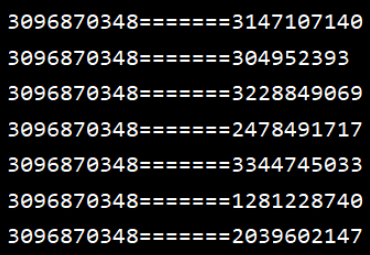
得出转换后的结果
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: