引言
分库分表相信大家都听说过,但(partitioning)表分区这个概念却鲜为人知,MySQL在5.1版本中开始支持了表分区技术,同时在MySQL5.5中进行了优化,自从MySQL支持的绝大部分引擎都开启了表分区功能。
但到底什么是表分区技术呢?这似乎之前没怎么听说过呀,对吗?
如果你之前还没接触过表分区技术,或者只是听说但接触不深入,那就可以跟随本章携手共探鲜为人知的表分区技术!一起Let's go~
PS:个人编写的《技术人求职指南》小册已完结,其中从技术总结开始,到制定期望、技术突击、简历优化、面试准备、面试技巧、谈薪技巧、面试复盘、选Offer方法、新人入职、进阶提升、职业规划、技术管理、涨薪跳槽、仲裁赔偿、副业兼职……,为大家打造了一套“从求职到跳槽”的一条龙服务,同时也为诸位准备了七折优惠码:3DoleNaE,近期需要找工作的小伙伴可以复制链接了解详情:https://s.juejin.cn/ds/USoa2R3/
一、何谓表分区技术?
经过之前《全解MySQL专栏》中多篇文章的熏陶,大家应该能够得知一个道理:MySQL中每个数据库实例的所有数据,都会放在磁盘上来存储,默认的存储位置可通过如下命令查看:
- • show variables like '%datadir%';
在默认的存储目录下,每个数据库实例之间都用不同的文件夹隔开,每个文件夹中存储着相应库中的所有表结构文件、表数据文件、索引数据文件等,如下:
 数据库实例
数据库实例
不同存储引擎的表,其文件格式也会存在些许差异,因此你可以在其中看到很多不同的文件后缀,但不管是何种存储引擎的表,如果表中的数据量过大,都会导致相应的磁盘文件过大,因此造成数据检索时效率变低(机械硬盘),因为每当从磁盘查找一条数据时,都需要从头遍历整个磁盘文件,毋庸置疑,其效率自然很低。
1.1、表分区的概念
原本的表文件都是以完整的形式存储在磁盘中,而表分区则是指将一张表的数据拆分成多个磁盘文件,然后放到磁盘中存储,这样做的好处在于:需要去检索一条数据时,无需对一个完整的数据文件从头到尾做扫描,而只需要对某个分区文件进行扫描,这样做能够在一定程度上提升性能。
同时还能打破存储容量的限制,因为无论是
Windows/Linux系统,都会存储磁盘分区的概念,在Windows中会分为C、D、E...盘,而Linux则会将磁盘划分为多个分区并挂载,一个盘符/分区的存储空间是有限的,当一张表数据增长到单个磁盘区中存不下时,就会出现相关的错误信息。
而通过表分区技术,可以将一张大表的数据,拆分到不同的磁盘分区中存放,这样可以打破存储容量的限制。
做了表分区之后,表在逻辑上还是同一张,只是磁盘中会划分为多个文件存储而已,所以表分区并不会影响原有的增删改查操作。简单来说,表分区前后的区别,就类似于数组和链表的区别:
- • 数组:逻辑上是连续的,并且物理空间上也是连续的,每个元素都是使用相邻的空间存放。
- • 链表:逻辑上是连续的,但物理空间上不一定连续,每个元素可以存到任何空间,相互之间用指针连接。
而分区之前的表文件,就类似于一个数组结构,所有的表数据都会放到同一个文件中存储,在磁盘空间上来说都是连续的。而分区之后的表文件,就类似于链表结构,表数据会分开存放到不同的磁盘空间中,在磁盘上会形成多个表数据文件,各分区之间用指针地址的方式产生关联,也就是上一个分区中,会存放下一个分区的磁盘地址,以便于提供CRUD时的数据支持。
1.2、表分区带来的优势
- • ①相较于使用单个文件存储表数据,表分区技术可以打破单个磁盘分区的容量限制。
- • ②对于一些失效数据,如三年前的数据,可以通过快速删除分区的方式清理,效率十分高。
- • ③能够在一定程度上提升磁盘IO时,检索数据的性能,毕竟只需对一小片磁盘表文件做寻道。
- • ④支持聚合函数的并行执行,比如sum()、count()这类函数,可以分别统计各分区的数据做汇总。
- • ⑤带来更好的数据管理性和可用性,当一个表文件受损时,不会影响其他分区文件中的表数据。
1.3、表分区的适用场景
所有基于数据库的业务大体可分为两类:
- • OLTP:在线事务处理,通常的C端项目都属于这类业务,负责基本的增删改查操作。
- • OLAP:在线分析处理,主要负责统计分析各类数据来做汇总,如用户画像分析、报表统计等。
对于OLAP类型的业务,表分区可以很好的提高查询性能,因为一般做在线分析都需要返回大量的数据,在这类业务中可以按时间分区,比如一个月用户行为等数据存在一个分区中,需要对相应的时间做分析时,只需扫描对应的时间分区即可。但在OLTP业务中,中小型项目中一般不会产生太多的数据,也不会一次性读取某张大表的10%以上的数据返回,大部分是通过索引返回几条数据就完事了,所以对于这类业务则要合理考虑分区到底值不值得,或者到底分区有没有必要。
二、表分区的方式与类型
简单的对表分区概念有了认知后,接着来聊一聊表分区的划分方式,表分区技术中只支持水平划分,啥叫水平划分呢?如下:
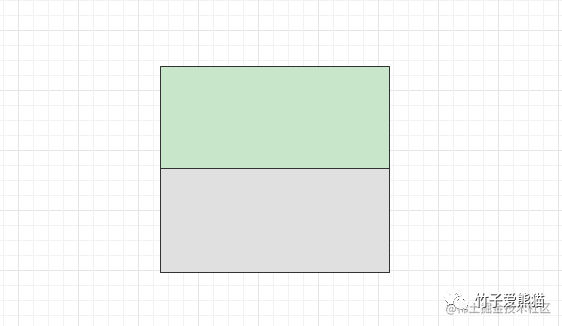 水平划分
水平划分
所谓的水平划分也就是指按照水平线,对某个内容进行横向切割,比如一张表的数据,假设有100条数据,将前面五十条放到一个分区中,后面五十条放入到另一个分区中,这也就是所谓的水平划分法。
表分区技术中,仅支持水平划分的方式,也就是只支持对数据表,以行作为粒度进行划分。
不过虽然只支持水平划分的模式,但分区技术也会分为多种分区类型,在MySQL数据库中总共支持range、list、hash、key、sub、columns这六种分区类型,官网介绍为>>>戳我访问<<<,其中最为常用的是range分区,接着一起简单介绍一下每种分期类型的特性。
2.1、RANGE分区
range分区的含义也就是按照范围去分区,比如现在有一个整数主键,我们可以把主键作为分区键,然后实现如下分区:
- • -∞ ~ 100000:无穷小到十万之间的主键记录,放入第一个分区中。
- • 100001 ~ 200000:十万零一到二十万之间的主键记录,放入到第二个分区中。
- • 200001 ~ +∞:二十万零一到无穷大之间的主键记录,放入到第三个分区中。
不过要记住,这里是以主键作为了分区键,也就是一条数据究竟会被放入到哪个分区中,需要依据主键的值来决定,比如主键值为12345,那与之对应的行数据会一起被放入到第一个分区中存储。
但是这种分区类型,仅支持以整数型字段作为分区键,如果想要以日期字段来做数据分区,需要先将其转换为
int格式的时间戳,《MySQL官网-range分区》。
2.2、LIST分区
list分区实际上是一种枚举分区,也就是为每个分区分配指定值,当插入的一条数据是这个分区的指定值时,最终这条数据就会插入到对应的分区中,好比以性别字段为例,0表示男,1表示女,创建两个分区如下:
- • 0:性别为男的数据落入到第一个分区中存储。
- • 1:性别为女的数据落入到第二个分区中存储。
当插入一条数据时,在所有分区中找不到对应的值,比如插入一条性别为2的数据,此时会报错。
这种分区类型同样只支持整数字段作为分区键,也就是在为每个分区分配指定值时,只能分配整数型的值,好比拿上面的性别字段为例,可以用
0、1来表示男、女,但不能直接指定成男、女这类字符串值。因此对于想要使用list分区类型的场景中,请记住要先将其字段值转换为数值类型的状态码,《MySQL官网-list分区》。
2.3、HASH分区
hash分区和前面两种存在略微的不同,因为哈希分区中支持两种哈希分区法,一种叫做常规哈希,另一种叫做线性哈希,释义如下:
- • 常规哈希:基于某个整数型字段,直接做取模,最后根据余数来决定数据的分区。
- • 线性哈希:基于某个字段哈希之后的哈希值,进行取模运算,最后根据余数来决定数据的分区。
两者之间的区别主要在于:前者只能基于整数型字段对数据做划分,后者则可以不限制字段的类型,只要能够通过MySQL哈希函数,转换出哈希值的字段类型都可以作为分区键(但本质上MySQL中好像没有提供将字符串转换为数值类型的哈希函数)。
这种分区类型,由于支持线性哈希的分区方式,所以基本上不限制字段类型,但凡任何能够使用哈希函数,转换出哈希值的类型,都可以使用这种哈希分区,《MySQL官网-hash分区》。
2.4、KEY分区
key分区很前面聊到的hash分区十分类似,两者之间的区别主要在于:**key分区不在限制字段的数据类型**,在hash分区中,想要使用一个字段作为分区键,要么这个字段本身是整数类型,要么这个字段经过哈希函数处理后,能够得到一个整数的哈希值才行。但在key分区中,除开不支持text、blob两种类型外,其他类型的字段都可以作为分区键。
在key分区中也可以不显式指定分区键,MySQL会自动选择,但不管是自己显式声明分区键,亦是MySQL自动选取分区键,都会遵循如下规则:
- • 表中只存在主键或唯一字段时,分区键必须为主键/唯一键的部分或全部字段,不允许选择其他字段。
- • 表中主键、唯一字段同时存在时,分区键必须为主键和唯一键共有的部分或全部字段。
- • 当表中不存在主键或唯一键时,分区键可以是除text、blob类型外的任意单个或多个字段。
如果在使用
key分区时,不主动指定分区键,MySQL会优先选择主键字段,如果主键不存在,会选择一个非空的唯一字段,如果不存在唯一字段,会选择除text、blob类型外的任意字段,《MySQL官网-key分区》。
2.5、SUB分区(子分区、复合分区)
Sub分区又称子分区,所谓的子分区是指基于表分区后的结果,进一步做分区处理,也就是基于一个分区再做分区,好比一张表可以基于日期中的年份做分区,基于年份做了分区后,还可以基于年分区进一步做月分区。
这种方式要求每个一级分区下的二级分区数量都一致,同时二级分区的类型只能为
hash、key类型,《MySQL官网-Sub分区》。
2.6、COLUMNS分区(列分区)
cloumns分区实际上是range、list分区的变种,在之前聊到过的这两种分区中,仅支持使用一个整数型字段作为分区键,而cloumns分区可以使得range、list的分区键由多个字段来组成,同时支持的字段类型也相对更丰富一些,但这种分区法一般用的极少,具体可参考《MySQL官网-cloumns分区》。
2.7、表分区的使用限制
在了解了表分区的概念和类型后,再一起来看看表分区使用的一些限制:
- • ①单张表最多只能创建1024个分区,MySQL5.6版本中拓展到8192个。
- • ②MySQL5.1及之前的版本中,分区键只能选择整数型字段,或支持哈希函数处理的字段。
- • ③所有的表分区必须保持相同的存储引擎,Merge、CSV、Federated...等引擎不支持表分区。
- • ④对一个表做了分区后,后续使用表的过程中,无法对表上的其他字段建立唯一索引。
- • ⑤分区表中无法创建外键,不过一般情况下表也不允许创建外键,都是靠逻辑上维护主外关系。
- • ⑥表中存在主键、唯一键的情况下,分区键的字段必须为主键或唯一键的部分或全部字段。
2.8、为何分区键要选用主键或唯一键?
这个问题其实仔细思索后就能得到答案,一方面是主键/唯一键通常情况下都不允许为空,比较如果一个null去做分区运算,好比哈希分区中的取模运算:null/n,这绝对会报空指针异常,所以选用主键和唯一键就能够防止这种异常情况出现。
同时还有第二个原因,先来想想:如果在表中存在主键/唯一键的情况下,分区键不选择主键/唯一键会出现什么情况呢?为了防止唯一字段重复,需要把所有分区中的数据全部遍历一次,最终才能确定唯一字段有没有重复。
但当分区键选用了主键/唯一键之后,首先对相应的字段做分区运算,然后定位到对应的分区,最后只需要判断这个分区中,对应的唯一字段值有没有重复即可,毕竟相同的值做相同的分区运算,永远都会被划分到同一个分区中存储。
三、表分区的落地实践
前面说了一大堆理论,对于表分区的各方面理论基础基本上都做了介绍,那接下来也做一下表分区的实践,毕竟编程光说不练永远是花架子,纸上谈兵无意义,编程讲究的是实践实操出真理!
创建表分区一般有两种方式,一种是直接在创建表时声明,另一种则是通过
alter方式创建。
3.1、range分区实践
--*创建一张*zz_range*表,同时依据*r_id*字段划分四个分区
createtablezz_range(
r_idintnotnull,
r_namevarchar(10),
primary*key*(r_id)using*btree
)
partitionbyrange(r_id)(
partition*p1*values*less*than*(100000),
partition*p2*values*less*than*(200000),
partition*p3*values*less*than*(300000),
partition*p4*values*less*than*maxvalue
);
--*向表中分别插入四条不同范围值的数据
insertintozz_rangevalues
(1,"竹子"),
(100001,"熊猫"),
(200001,"子竹"),
(999999,"猫熊");
--*查询*zz_range*表中不同分区的数据量
select
****partition_name,table_rows*
from
****information_schema.partitions*
where
****table_name*='zz_range';
依次执行上述代码,最终效果如下:
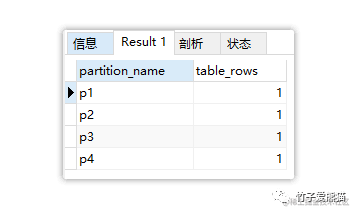 range分区
range分区
从中可明显看出,前面插入的四条数据分别落入到了不同的分区中,逻辑如下:
- • p1分区:负责存储-∞ ~ 100000之间的所有数据,id=1的数据落入p1分区。
- • p2分区:负责存储100001 ~ 200000之间的所有数据,id=100001的数据落入p2分区。
- • p3分区:负责存储200001 ~ 300000之间的所有数据,id=200001的数据落入p3分区。
- • p4分区:负责存储100001 ~ +∞之间的所有数据,id=999999的数据落入p4分区。
最后来看看本地磁盘中的表数据文件会发生什么变化呢?如下:
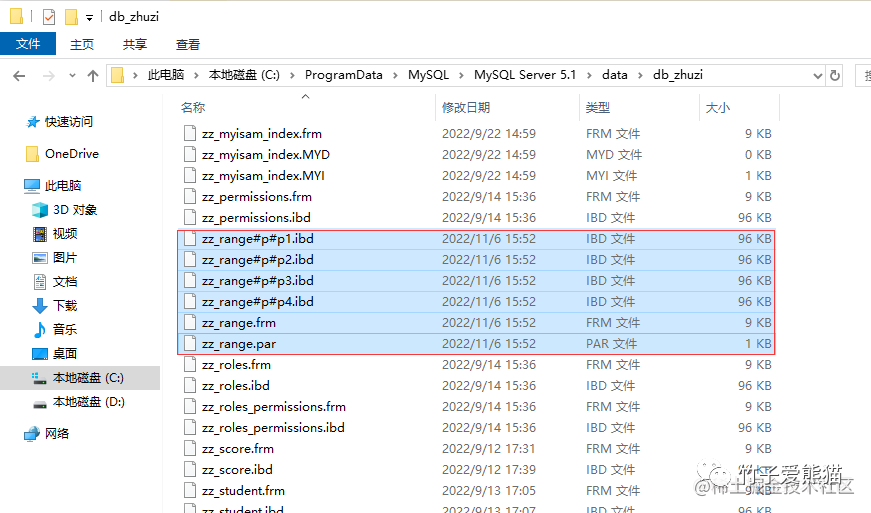 表分区文件
表分区文件
从中可以看到,存储表数据的.ibd文件从原先的1个,变成了现在的四个,与咱们最初推测的无异,同时你也可以将这些分区文件指定到不同的目录下存储,和更改表数据文件的存储位置方法相同,即通过data directory = "/xxx/xxx/xxx"的方式指定存储目录。
3.2、list分区实操
前面简单的对range分区有了实操经验后,接着来实操一下list分区,这种分区在前面的介绍中聊到过,属于一种枚举的分区类型,如下:
--*创建一张*zz_list*表,同时根据*l_sex*性别字段做分区
createtablezz_list(
l_idintnotnull,
l_namevarchar(10),
l_sexintnotnull
)
partitionby*list(l_sex)(
partition*p1*valuesin(0),
partition*p2*valuesin(1)
);
--*插入两条性别为男(l_sex=0)、一条性别为女(l_sex=1)的数据
insertintozz_listvalues(1,"竹子",0),(2,"熊猫",1),(3,"子竹",0);
--*查询*zz_list*表中不同分区的数据量
select
****partition_name*as"分区名称",table_rows*as"数据行数"
from
****information_schema.partitions*
where
****table_name*='zz_list';
最终上述代码依次运行后的结果如下:
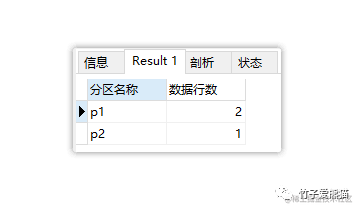 list分区
list分区
同时简单推算一下插入时,数据分区的过程,如下:
- • p1分区:负责存储性别为男(l_sex=0)的数据,竹子、子竹两条数据会落入p1分区。
- • p2分区:负责存储性别为女(l_sex=1)的数据,熊猫这条数据会落入p2分区。
如果插入一条分区键范围中,不存在的数据时,就会抛出错误信息,如下:
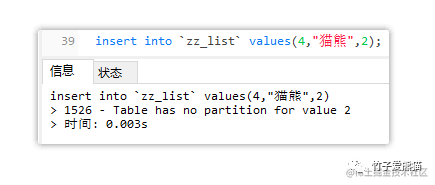 list分区报错
list分区报错
从上述的错误信息中可得知:此时在插入数据时,无法找到负责存储l_sex=2的分区,因此抛出了1526的错误信息。
3.3、hash分区实战
在前面说过,哈希分区法可细分为两种,一类为常规哈希分区,另一类为线性哈希分区,接下来分别做一下实战演练。
3.3.1、常规哈希分区
--*创建一张*zz_hash*表,并选用*h_id*作为分区键,划分为三个分区
create*table*zz_hash(
h_idintnotnull,
h_name*varchar(10)
)
partition*by*hash(h_id)
partitions*3;
--插入四条数据进行测试
insert*intozz_hash*values(1,"竹子"),(2,"熊猫"),(3,"子竹"),(4,"猫熊");
--查询各个分区中的数据量
select
****partition_name*as"分区名称",table_rows*as"数据行数"
from
****information_schema.partitions*
where
****table_name*='zz_hash';
上述代码运行后结果如下:
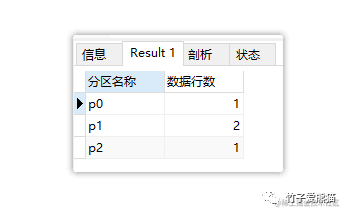 hash-常规分区
hash-常规分区
这个结果是怎么来的呢?其过程如下:
| 分区键值 | 取模过程 | 取模余数 | 目标分区 |
h_id=1 |
1%3 |
1 |
p1 |
h_id=2 |
2%3 |
2 |
p2 |
h_id=3 |
3%3 |
0 |
p0 |
h_id=4 |
4%3 |
1 |
p1 |
最终可以得知各分区中的数据为{p0:[h_id=3]}、{p1:[h_id=1、h_id=4]}、{p2:[h_id=2]},如果有新的数据插入,则会继续基于分区键进行取模运算,从而最终得到新数据该落入哪个分区中。
但是要注意:哈希分区中无法手动指定分区名称,
MySQL会默认以pn作为分区名称的格式,n会从0开始依次增长,n的最大值取决于最初创建分区时,给定的partitions 3;数-1。
3.3.2、线性哈希分区
如果你想要使用线性哈希分区,实际上只需要在之前的基础上,加上一个linear关键字即可,如下:
create*table*zz_linear_hash(
****lh_id*int*not*null,
****lh_name*varchar(10)
)*
partition*by*linear*hash(lh_id)
partitions*3;
其他过程与常规哈希分区无异,就不再过多介绍了,如果想要使用字符串作为分区键,那么必须要找一个能够将字符串转换为整数哈希值的函数,也就是类似于这样的逻辑:hash(哈希值函数(字符串字段))。
3.4、key分区实操
hash类型的分区中,基本上强制无法使用整数类型之外的字段作为分区键,而key分区的推出则是为了解决这个痛点,如下:
--*创建一张 zz_key 表,选用字符串类型的字段:k_name 作为分区键
createtablezz_key(
k_idint,
k_namevarchar(10)notnull
)
partitionby*key(k_name)
partitions*3;
--*插入四条数据进行测试
insertintozz_keyvalues(1,"竹子"),(2,"熊猫"),(3,"子竹"),(4,"猫熊");
--*查询各个分区中的数据量
select
****partition_name*as"分区名称",table_rows*as"数据行数"
from
****information_schema.partitions*
where
****table_name*='zz_key';
大家可以尝试运行上述代码,其实会发现并不会报错,最终结果如下:
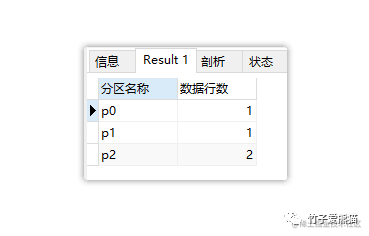 key分区
key分区
那这是如何实现的呢?大致伪逻辑如下:
| 分区键值 | 运算过程 |
k_name=竹子 |
内部哈希函数(竹子)%3 |
k_name=熊猫 |
内部哈希函数(熊猫)%3 |
k_name=子竹 |
内部哈希函数(子竹)%3 |
k_name=猫熊 |
内部哈希函数(猫熊)%3 |
最终根据计算出的哈希函数,再取模分区总数,最终得到了每条数据该落入到的分区。
key类型的分区中也支持线性哈希类型,本质上也只需要在原有的基础上,多加上一个linear关键字即可。
3.5、sub分区实操
前面聊到过,sub子分区类型实际就是分区嵌套,基于一次分区的结果上再次进行分区,下面实操一下:
--*创建一张*zz_sub*表,基于年份进行范围分区,再基于月份进行哈希分区
createtablezz_sub(
****register_time*datetime*
)
partitionbyrange(year(register_time))
subpartition*by*hash(month(register_time))
(
partition*p1*values*less*than*(2000)(
********subpartition*p1_s1,
********subpartition*p1_s2
),
partition*p2*values*less*than*(2020)(
********subpartition*p2_s1,
********subpartition*p2_s2
),
partition*p3*values*less*than*maxvalue(
********subpartition*p3_s1,
********subpartition*p3_s2
)
);
--*插入八条测试数据
insertinto*zz_sub*values
("1998-11-02*23:22:59"),
("2000-08-11*14:14:39"),
("2001-10-27*13:33:14"),
("2008-04-22*12:44:25"),
("2009-06-15*00:24:58"),
("2019-12-07*01:21:24"),
("2022-04-01*17:11:14"),
("2025-01-09*16:36:01");
--*查询各个子分区中的数据行数
select
****partition_name*as"父分区名称",
****subpartition_name*as"子分区名称",
****table_rows*as"子分区行数"
from
****information_schema.partitions*
where
****table_name*='zz_sub';
上述的Sub分区比之前聊到的几种都看着复杂一些,一起先来看看结果:
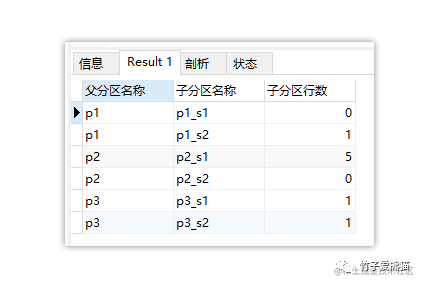 sub分区
sub分区
总共插入了8条测试数据,所有子分区的行数加起来也是八条数据,从数据量方面来看是没有任何问题的,但具体是如何将数据划分到每个分区中的呢?如下:
- • p1分区:负责存储年份-∞ ~ 2000之间的所有数据。
- • p2分区:负责存储年份2001 ~ 2020之间的所有数据。
- • p3分区:负责存储年份2021 ~ +∞之间的所有数据。
基于上述各分区存储数据的范围,最终插入的各条数据落入的范围如下:
 数据落区
数据落区
确定了数据要落入的父分区后,接着会基于月份做取模运算,然后确定具体要落入的子分区,各日期的月份如下:
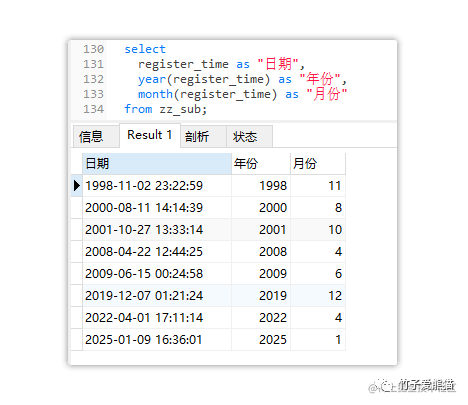 日期-年月
日期-年月
接着会使用这些月份做取模运算,由于每个分区中只划分了两个子分区,所以就是用月份取模2,如下:
| 日期月份 | 取模过程 | 取模余数 | 目标分区 |
11 |
11%2 |
1 |
p1-s2 |
08 |
08%2 |
0 |
p2-s1 |
10 |
10%2 |
0 |
p2-s1 |
04 |
04%2 |
0 |
p2-s1 |
06 |
06%2 |
0 |
p2-s1 |
12 |
12%2 |
0 |
p2-s1 |
04 |
04%2 |
0 |
p3-s1 |
01 |
01%2 |
1 |
p3-s2 |
因为每个分区中具备两个子分区,在MySQL内部会用一个数组来存储,大体关系如下:
{
****"p1"*:*["p1-s1","p1-s2"],
****"p2"*:*["p2-s1","p2-s2"],
****"p3"*:*["p3-s1","p3-s2"]
}
因此当取模的余数为0时,会选择放入到第一个子分区中,当取模的余数为1时,会放入到第二个子分区。OK~,至此就讲明白了复合分区类型中,数据分区的具体过程。
3.6、表分区相关的命令
--*创建范围分区
createtable表名(
xxx*xxx*notnull,
....
)
partitionbyrange(xxx)(
partition分区名1values*less*than*(范围)*data*directory*="/xxx/xxx/xxx",
partition分区名2values*less*than*(范围)*data*directory*="/xxx/xxx/xxx",
......
);
--*创建枚举分区
createtable表名(
xxx*xxx*notnull,
....
)
partitionby*list(xxx)(
partition分区名1valuesin(枚举值1,枚举值2...),
partition分区名2valuesin(枚举值),
......
);
--*创建常规哈希分区
createtable表名(
xxx*xxx*notnull,
....
)
partitionby*hash(xxx)
partitions*分区数量;
--*创建线性哈希分区
createtable表名(
xxx*xxx*notnull,
....
)
partitionby*linear*hash(xxx)
partitions*分区数量;
--*创建Key键分区
createtable表名(
xxx*xxx*notnull,
....
)
partitionby*key(xxx)
partitions*分区数量;
--*创建Sub子分区
createtable表名(
xxx*xxx*notnull,
....
)
partitionbyrange(父分区键)
subpartition*by*hash(子分区键)(
partition分区名1values*less*than*(范围1)(
********subpartition*子分区名1,
********subpartition*子分区名2,
......
),
partition分区名2values*less*than*(范围2)(
********subpartition*子分区名1,
********subpartition*子分区名2,
......
),
......
);
--*查询一张表各个分区的数据量
select
****partition_name*as"分区名称",table_rows*as"数据行数"
from
****information_schema.partitions*
where
****table_name*='表名';
--*查询一张表父子分区的数据量
select
****partition_name*as"父分区名称",
********subpartition_name*as"子分区名称",
********table_rows*as"子分区行数"
from
****information_schema.partitions*
where
****table_name*='表名';
--*查询MySQL中所有表分区的信息
select*from*information_schema.partitions;
--*查询一张表某个分区中的所有数据
select*from表名partition(分区名);
--*对于一张已存在的表添加分区
altertable表名*reorganize*partition分区名into(
partition分区名1values*less*than*(范围)*data*directory*="/xxx/xxx/xxx",
partition分区名2values*less*than*(范围)*data*directory*="/xxx/xxx/xxx",
......
);
--*将多个分区合并成一个分区
altertable表明*reorganize*partition分区名1,分区名2...into(
partition新分区名values*less*than*(范围)
);
--*清空一个分区中的所有数据
altertable表名truncatepartition分区名;
--*删除一个表的指定分区
altertable表名droppartition分区名;
--*重建一张表的分区
altertable表名*rebuild*partition分区名;
--*分析一个表分区
altertable表名*analyze*partition分区名;
--*优化一个表分区
altertable表名*optimize*partition分区名;
--*检查一个表分区
altertable表名checkpartition分区名;
--*修复一个表分区
altertable表名*repair*partition分区名;
--*减少hash、key分区方式的*n*个分区
altertable表名*coalesce*partition*n;
--*将一张表的分区切换到另一张表
altertable表名1*exchange*partition分区名withtable表名2;
--*移除一张表的所有分区
altertable表名*remove*partitioning;
OK,到这里就列出了一些表分区相关的操作命令,大家可自行根据需求去查找自己需要的命令~
四、表分区技术总结
如果你看到了这里,那首先恭喜你:无用的知识又增加啦!为啥说表分区技术没用呢?其实作用还是有的,不过一般情况下都会有更好的选择代替,比如采用分表技术来划分表数据,不仅仅支持水平切分,甚至还可以做垂直切分。当单库的数据过多时,表分区技术其实派不上太大的用场,因为当数据达到一定量级时,要么会选择分库分表,要么会选择上分布式数据库,如TiDB,最后再配合大数据技术辅助,做历史数据归档。
所以表分区技术没有太多的人知道也是有原因的,毕竟地位也比较尴尬,要用它的时候,往往有更好的选择替换,而小型的项目中又没有必要去使用它,所以关于这项技术,掌不掌握其实影响都不大。不过多懂一些总是好事,陌生的知识永远都能给人增长认知~
这里提到了一句话:要用它的时候,往往有更好的选择替换,也就是指分表技术,这块内容本章就不再展开叙述了,后面会单开一章《MySQL库内分表篇》,结合个人之前做过的一个业务,来全面的剖析它。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: