引言
MySQL是一款支持拔插式引擎的数据库,在开发过程中你可以根据业务特性,从支持的诸多引擎中选择一款适合的,例如MyISAM、InnoDB、Merge、Memory(HEAP)、BDB(BerkeleyDB)、Example、Federated、Archive、CSV、Blackhole.....
 存储引擎
存储引擎
不过虽然各款引擎都各有千秋,但其中最为常用的就只有
MyISAM、InnoDB这两款引擎。
MyISAM引擎是MySQL官方基于早期的ISAM引擎改良而来的,它是一款“苗根正红”的引擎,由于其不错的性能表现,再加上丰富的特性支持(全文索引、压缩机制、空间索引/函数等),在MySQL5.5版本之前,也一直是MySQL默认的存储引擎。
但随着时间慢慢推移,MySQL官方渐渐有了“新欢”,开始主推使用InnoDB作为表的引擎,甚至到了MySQL5.6及以后版本中,直接用InnoDB代替了MyISAM,作为了MySQL默认的存储引擎,这是啥原因呢?
MyISAM引擎整个实现都由官方一点点开发,甚至MySQL-Server中的不少功能都是为MyISAM而量身定制,其地位在MySQL体系中可以看成是“亲儿子”,而InnoDB由于是其他公司开源的原因,因此其地位可以算作一个“外来子”,但为何“外来子”接替了“亲生子”的职责呢?是MySQL官方始乱终弃嘛?这背后一切的一切到底发生了什么,咱们现在展开来聊一聊这个话题:半道出家的InnoDB为何能替换官方的MyISAM引擎?
不过在正式聊这个话题之前,咱们先对比一下MyISAM、InnoDB这两款最为常用的存储引擎。
PS:个人编写的《技术人求职指南》小册已完结,其中从技术总结开始,到制定期望、技术突击、简历优化、面试准备、面试技巧、谈薪技巧、面试复盘、选Offer方法、新人入职、进阶提升、职业规划、技术管理、涨薪跳槽、仲裁赔偿、副业兼职……,为大家打造了一套“从求职到跳槽”的一条龙服务,同时也为诸位准备了七折优惠码:3DoleNaE,近期需要找工作的小伙伴可以复制链接了解详情:https://s.juejin.cn/ds/USoa2R3/
一、MyISAM引擎 vs InnoDB引擎
前面介绍了一下MyISAM引擎的背景,那现在也先简单介绍一下InnoDB引擎的背景吧,InnoDB由Innobase Oy公司所开发,其创始人是Heikki Tuuri,提这个名字大家估计不太熟,但提另外一个名字大家绝对知道,也就是Linux操作系统之父Linus,InnoDB的创始人和他正是校友关系,但InnoDB这款引擎的历程也比较艰辛,这里就不做过多介绍了,总之最终在2006.05月也被甲骨文公司并购。
以最经典、最主流的MySQL5.7版本为例,两款引擎各自支持的特性如下:
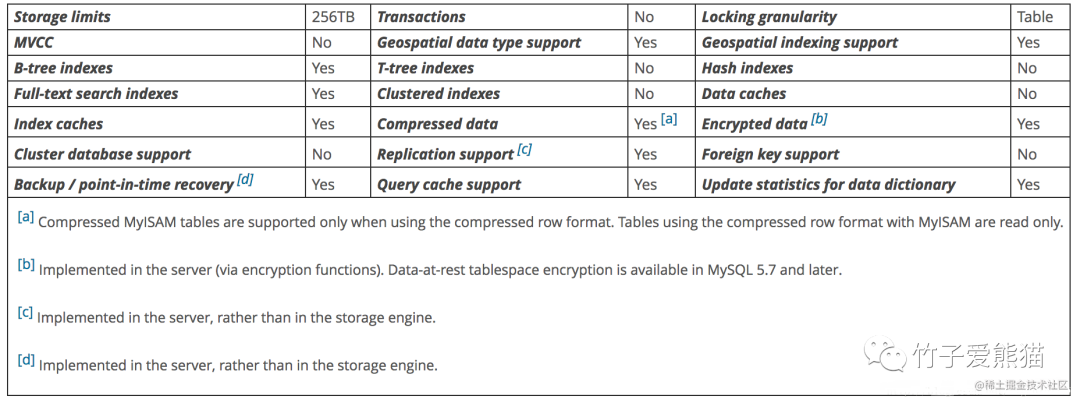 MyISAM引擎特性
MyISAM引擎特性
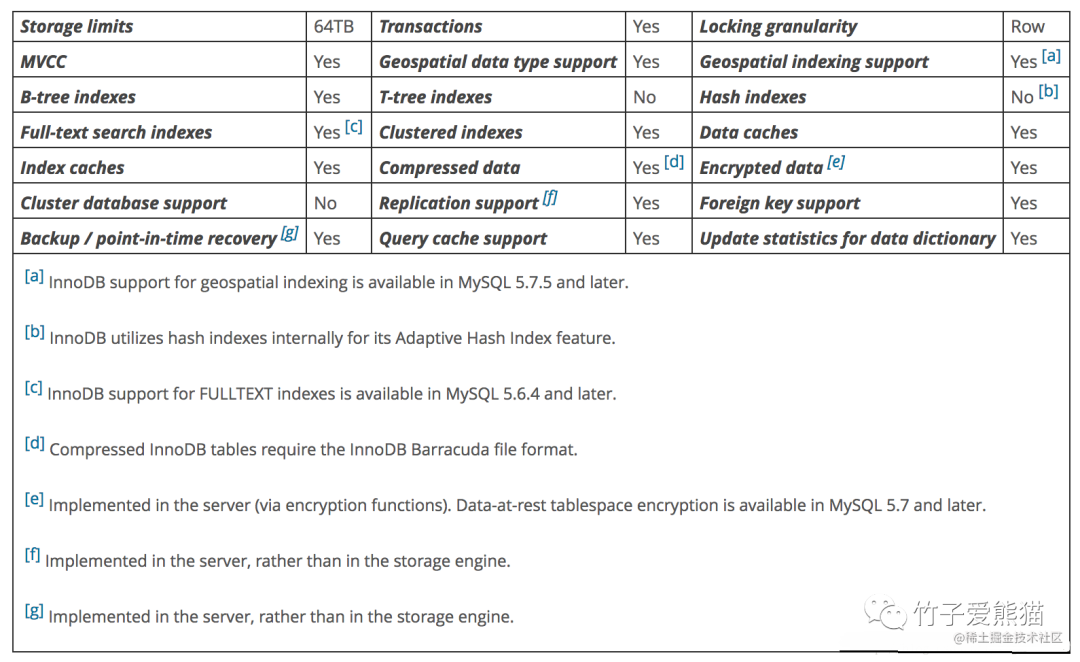 InnoDB引擎特性
InnoDB引擎特性
从上述这摘自官网的两张图中,咱们也很难去对比两者之间的差异,所以还是直接一点吧,以目前已更新的《全解MySQL数据库》系列的文章作为基础,从各个维度及特性支持来做个简单的对比。
2.1、磁盘文件的对比
在《MySQL架构篇-文件系统层》中曾首次简单的聊到过关于不同文件格式的含义,其中就提到过MyISAM、InnoDB两款引擎在存储数据时,本地文件的不同点。同时在《索引原理篇-常规引擎的索引存储》这篇文章中,曾分别使用MyISAM、InnoDB创建了两张表zz_innodb_index、zz_myisam_index,并且也从本地观察了两张表的磁盘文件,如下:
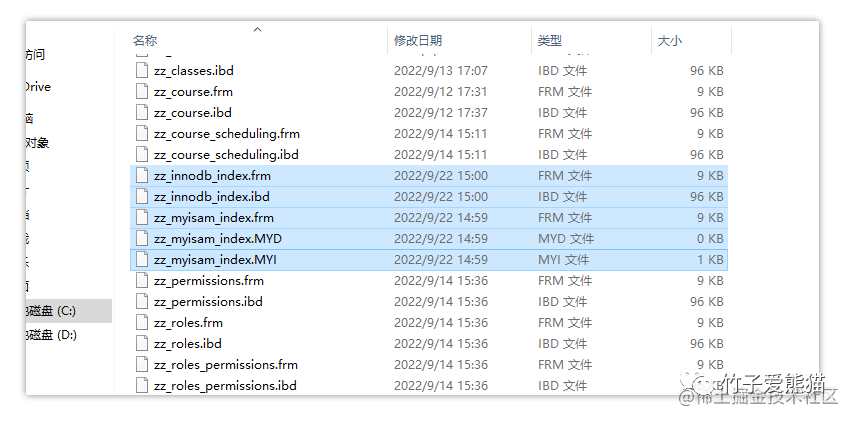 磁盘文件
磁盘文件
其中使用MyISAM引擎的表:zz_myisam_index,会在本地生成三个磁盘文件:
- • zz_myisam_index.frm:该文件中存储表的结构信息。
- • zz_myisam_index.MYD:该文件中存储表的行数据。
- • zz_myisam_index.MYI:该文件中存储表的索引数据。
从这里可得知一点:MyISAM引擎的表数据和索引数据,会分别放在两个不同的文件中存储。
而反观使用InnoDB引擎的表:zz_innodb_index,在磁盘中仅有两个文件:
- • zz_innodb_index.frm:该文件中存储表的结构信息。
- • zz_innodb_index.ibd:该文件中存储表的行数据和索引数据。
为啥要对比磁盘文件的区别呢?因为这点关乎着后续索引的支持性,咱们接着往下聊。
2.2、索引支持的对比
因为MyISAM引擎在设计之初,会将表分为.frm、.MYD、.MYI三个文件放在磁盘存储,表数据和索引数据是分别放在.MYD、.MYI文件中,所以注定了MyISAM引擎只支持非聚簇索引。而InnoDB引擎的表数据、索引数据都放在.ibd文件中存储,因此InnoDB是支持聚簇索引的。
为啥索引数据和表数据分开存储就不支持聚簇索引呢?这里可参考《索引初识篇-存储方式层次划分索引类型》中给出的定义:
 非聚簇和聚簇
非聚簇和聚簇
聚簇索引的要求是:索引键和行数据必须在物理空间上也是连续的,而MyISAM表数据和索引数据,分别位于两个磁盘文件中,这也就注定了它无法满足聚簇索引的要求。
一种引擎支不支持聚簇索引很重要,这涉及到了后面的很多技术实现,而
MyISAM把表数据和索引数据分开存了,也就意味着MyISAM相较于InnoDB来说,这小子天生就带有缺陷~
但不支持聚簇索引也有好处,也就是无论走任何索引,都只需要一遍查询即可获得数据,而InnoDB引擎的表中,如果不走聚簇(主键)索引查询数据,走其他索引的情况下,都需要经过两遍(回表)查询才能获得数据。
但这也不意味着
MyISAM引擎查数据就比InnoDB快,如果看过《高性能MySQL》这本书的小伙伴,应该会知道在其中有一句话:“不要轻易相信「MyISAM比InnoDB快」之类的经验之谈,这个结论往往不是绝对的”。
这句话的原因是啥呢?这点在后面再说,接着再聊一聊其他方面的对比。
2.3、事务机制的对比
认真阅读过《MySQL日志篇》的小伙伴应该知道,InnoDB引擎中有两个自己专享的日志,即undo-log、redo-log,先来说说undo-log日志,InnoDB在MySQL启动后,会在内存中构建一个undo_log_buffer缓冲区,同时在磁盘中也有相应的undo-log日志文件。
那
undo缓冲区和磁盘文件有啥用呢?还记得在《MySQL事务篇》中讲过的事务实现原理嘛?
 事务提交与回滚
事务提交与回滚
一条写入类型的SQL语句,在正式执行前都会先记录redo-log、undo-log日志,undo-log中会记录变更前的旧数据,当一个事务提交时,MySQL会正常的将数据落盘,而当一个事务碰到rollback命令需要回滚时,就会找到undo-log中记录的旧数据,接着用来覆盖变更过的新数据,以此做到将数据回滚到变更前的“样貌”。
使用
InnoDB存储引擎的表,可以借助undo-log日志实现事务机制,支持多条SQL组成一个事务,可以保证发生异常的情况下,组成这个事务的SQL到底回滚还是提交。而MyISAM并未设计类似的技术,在启动时不会在内存中构建undo_log_buffer缓冲区,磁盘中也没有相应的日志文件,因此MyISAM并不支持事务机制。
一个引擎是否支持事务,这点尤为重要,因为业务开发过程中,咱们需要关注数据的安全性,拿最为经典的下单为例,用户把钱都付了,总不能由于程序Bug,然后不给用户新增订单、物流信息吧?再不济至少也要把钱退回给用户,因此就需要用到事务机制来保证原子性。
而
MyISAM不支持事务,也就意味着当用户付钱之后,如果程序出现了异常,就会导致用户付的钱不会退回,订单信息也不会生成,因为程序都抛异常了,自然不会继续往下执行增加订单、物流信息的SQL语句。
所以,如果表结构用了MyISAM引擎,想要解决这类问题,就只能在客户端做事务补偿,比如上面这个情况,当用户付钱后执行出现异常了,就在客户端中记录一下,然后再向MySQL发送一条相应的反SQL,以此来保障数据的一致性。
2.4、故障恢复的对比
前面简单的聊了undo-log日志,InnoDB借助它保证了事务的原子性,接着再来看看redo-log日志,InnoDB在启动时,同样会在内存中构建一个redo_log_buffer缓冲区,在磁盘中也会有相应的redo-log日志文件,所以当一条或多条SQL语句执行成功后,不论MySQL在何时宕机,只要这个事务提交了,InnoDB引擎都能确保该事务的数据不会丢失,也就以此保障了事务的持久性。
InnoDB引擎由于redo-log日志的存在,因此只要事务提交,机器断电、程序宕机等各种灾难情况,都可以用redo-log日志来恢复数据。但MyISAM引擎同样没有redo-log日志,所以并不支持数据的故障恢复,如果表是使用MyISAM引擎创建的,当一条SQL将数据写入到了缓冲区后,SQL还未被写到bin-log日志,此时机器断电、DB宕机了,重启之后由于数据在宕机前还未落盘,所以丢了也就无法找回。
从这一点来说,
MyISAM并没有InnoDB引擎可靠,在InnoDB中只要事务提交,它就能确保数据永远不丢失,但MyISAM不行。这就好比咱们去银行存钱,去InnoDB银行存,你只需要把钱送到它那里,它就能确保你的财产安全,但如若去MyISAM银行存钱,你必须要把钱送到银行的保险库中才行,否则有可能会因为在送往保险库的过程中“丢失”财产。
2.5、锁粒度的对比
锁的实现粒度其实跟索引有关,大家应该都知道,MySQL的存储引擎中,MyISAM仅支持表锁,而InnoDB同时支持表锁、行锁,但为啥MyISAM引擎不支持行锁呢?不是不想,而是做不到!还记得前面聊索引的那个对比项嘛?我说过:“MyISAM由于不支持聚簇索引,因此对比InnoDB来说,这小子天生存在缺陷”!为啥这样说呢,接着来展开聊一聊。
select**from*zz_students;
+------------+--------+------+--------+
|*student_id*|*name***|*sex**|*height*|
+------------+--------+------+--------+
|1|竹子|男|185cm|
|...|....|..|.....|
+------------+--------+------+--------+
上述这张学生表中,假设使用的是MyISAM引擎,同时对student_id字段建立了主键索引,name字段建立了普通索引,sex、height字段建立了联合索引,此时先不管索引合不合理,以目前情况为例,来推导一下MyISAM表为啥无法实现行锁。
这张表中存在三个索引,那在本地的
.MYI索引文件中,肯定存在三颗B+树,同时由于MyISAM不支持聚簇索引,所以这三个索引是平级的,每棵B+树的索引键,都直接指向.MYD数据文件中的行数据地址。
假设MyISAM要实现行锁,当要对一行数据加锁时,可以锁定一棵树中某一个数据,但无法锁定其他树的行数据,啥意思呢?举个例子:
select***from*zz_students*where*student_id*=*1*for*update;
这条SQL必然会走主键索引命中数据,那假设此时对主键索引树上,ID=1的数据加锁,接着再来看一种情况:
select***from*zz_students*where*name*=*"竹子"*for*update;
此时这条SQL又会走name字段的普通索引查询数据,那此时又对普通索引树上的「竹子」数据加锁。
到这里,发现问题没有?上面的案例中,
MyISAM如果想要实现行锁,就会遇到这个问题,基于不同索引查询数据时,可能会导致一行数据上加多个锁!这样又会导致多条线程同时操作一个数据,所以又会因为多线程并发执行的原因,造成脏读、幻读、不可重复读这系列问题出现。
但InnoDB引擎呢?因为支持聚簇索引,表中就算没有显式定义主键,内部依旧会用一个隐藏列来作为聚簇索引的索引字段,所以InnoDB表中的索引,是有主次之分的,所有的次级索引,其索引值都存储聚簇索引的索引键,因此想要对一行数据加锁时,只需要锁定聚簇索引的数据即可。
--*通过主键索引查询数据
select***from*zz_students*where*student_id*=*1*for*update;
--*通过普通索引查询数据
select***from*zz_students*where*name*=*"竹子"*for*update;
依旧是前面的这个例子,通过主键索引查询的SQL语句,会直接定位到聚簇索引的数据,然后对ID=1的数据加锁。而第二条通过普通索引查询数据的SQL语句,经过查询后会得到一个值:ID=1,然后会拿着这个ID=1的值再去回表,在聚簇索引中再次查询ID=1的数据,找到之后发现上面已经有线程加锁了,当前线程就会阻塞等待上一个线程释放锁。
看到这里,相信大家也就理解了我前面说的那句:“
MyISAM由于不支持聚簇索引,因此对比InnoDB来说,这小子天生存在缺陷”的含义。
因为MyISAM引擎不支持聚簇索引,所以无法实现行锁,出现多条线程同时读写数据时,只能锁住整张表。而InnoDB由于支持聚簇索引,每个索引最终都会指向聚簇索引中的索引键,因此出现并发事务时,InnoDB只需要锁住聚簇索引的数据即可,而不需要锁住整张表,因此并发性能更高。
同时,
InnoDB引擎构建的缓冲区中,会专门申请一块内存作为锁空间,同时再结合InnoDB支持事务,所以InnoDB是基于事务来生成锁对象,相较于SQL Server的行锁来说,InnoDB的行锁会更节约内存,对锁底层实现感兴趣的小伙伴,可参考*《MySQL锁机制的实现原理》*。
2.6、并发性能的对比
MyISAM仅支持表锁,InnoDB同时支持表锁、行锁,由于这点原因,其实InnoDB引擎的并发支持性早已远超MyISAM了,毕竟锁的粒度越小,并发冲突的概率也就越低,因此并发支撑就越高。
但是
InnoDB不仅仅只满足于此,为了提升读-写并存场景下的并发度,InnoDB引擎又基于undo-log日志的版本链+事务快照,又推出了MVCC多版本并发控制技术,因此对于读-写共存的场景支持并发执行。
但MyISAM只支持表锁,因此当一条SQL在写数据时,其他SQL就算是来读数据的,也需要阻塞等待,为啥呢?因为写数据时需要加排他锁,这是一种独占类型的锁,会排斥一切尝试获取锁的线程,反过来也是同理,当一条线程在读数据时,另一条线程来写数据,依旧会陷入阻塞等待,毕竟写数据要获取排他锁,也就意味着整张表只允许这一个线程操作。
2.7、内存利用度的对比
在上章关于《MySQL内存篇》的讲解中,咱们详细的阐述了MySQL运行期间内存的方方面面,尤其是对于InnoDB的Buffer Pool做了全面剖析,其实看完会发现:InnoDB几乎将内存开发到了极致,虽然InnoDB不像Memory引擎那样完全基于内存运行,但它将所有能够在内存完成的操作,全部都放在了内存中完成,无论是读写数据、维护索引结构也好,记录日志也罢,各类操作全部都在内存完成。
只要你机器的内存够大,为缓冲池分配的内存够多,MySQL在线上运行的时间够久,InnoDB甚至会将磁盘中的所有数据,全部载入内存,然后所有客户端的读写请求,基本上无需再走磁盘来完成,都采用异步IO的方式完成,即先写内存+后台线程刷写的方式执行,后台线程的刷盘动作,对客户端而言不会有任何感知,在写完内存之后就会直接向客户端返回。
因为随着时代的进步,计算机硬件也在不断改进,虽然磁盘由起初的机械磁盘,演化到了如今的固态磁盘(
SSD),但内存的发展更为迅猛,DDR1、DDR2、DDR3、DDR4、DDR5不断迭代,内存频率从起初的100~200MHz,到800MHz、1000MHz....、2400MHz、4800MHz....甚至到现在的上万兆赫,慢慢的内存读写速率遥遥领先于磁盘,所以再基于磁盘执行业务SQL,其效率虽然不低,但对整个业务系统而言依旧是较慢的。
而InnoDB引擎的创始人Heikki Tuuri早早想到了这点,通过缓冲池结合异步IO技术,活生生将一款基于磁盘的引擎,演变成了半内存式的引擎。反观MyISAM引擎,内部虽然也有缓冲池以及异步IO技术,但对内存的开发度远不足于InnoDB引擎,运行期间大量操作依旧会走磁盘完成。
其实这也不能怪
MyISAM引擎,而是由于它出身的原因导致的,因为MySQL官方最初以为:MySQL Server + MyISAM这套组合能长久不衰,所以很多功能都放在了MySQL Server中实现,比如:
InnoDB缓冲池的数据页,可以当做数据缓存使用,如果数据页中有的数据,可以直接从内存中读取返回,而MyISAM则没有相应实现,完全依赖于MySQL Server的「查询缓存」做到这个功能。
InnoDB引擎专门设计了redo-log日志,可以用于故障恢复,而MyISAM也没有类似的实现,而是企图通过MySQL Server的bin-log日志实现这个功能。
InnoDB创造了一个插入缓冲区,也就是后来的写入缓冲区,用于减少写操作执行时磁盘IO,MyISAM引擎同样没有相应实现,而是依赖于MySQL Server在工作线程中设计的bulk_insert_buffer批量插入缓冲区来实现类似的功能。
类似于上述的情况,在MyISAM引擎中还有不少,例如Key Buffer等,但在这里就不一一例举了~
其实除开上述列出的几个对比项外,还有是否支持外键的对比、删除数据时的区别等.....,但这些不重要的对比项就不展开叙说了,后面会讲一下
MyISAM引擎中一些好的特性。
二、为什么InnoDB代替了MyISAM?
经过上述的一系列对比后,对于为何使用InnoDB替换了MyISAM引擎的原因,相信各位小伙伴也能感受出来,这里就等价于稍微做个总结:
- • ①存储方式:MyISAM引擎会将表数据和索引数据分成两个文件存储。
- • ②索引支持:因为MyISAM引擎的表数据和索引数据是分开的,因此不支持聚簇索引。
- • ③事务支持:由于MyISAM引擎没有undo-log日志,所以不支持多条SQL组成事务并回滚。
- • ④故障恢复:MyISAM引擎依靠bin-log日志实现,bin-log中未写入的数据会永久丢失。
- • ⑤锁粒度支持:因为MyISAM不支持聚簇索引,因此无法实现行锁,所有并发操作只能加表锁。
- • ⑥并发性能:MyISAM引擎仅支持表锁,所以多条线程出现读-写并发场景时会阻塞。
- • ⑦内存利用度:MyISAM引擎过于依赖MySQL Server,对缓冲池、异步IO技术开发度不够。
上述这些MyISAM不支持的,InnoDB引擎全都支持,也正由于这方方面面的原因,InnoDB引擎开始崭露锋芒,而作为MySQL亲生子的MyISAM自此之后跌落神坛,最终到了MySQL5.6版本时,MyISAM彻底让出了MySQL默认存储引擎的宝座。
但成也萧何败也萧何,
MySQL官方费尽心血打造的MyISAM虽然败给了InnoDB,但自从将默认的存储引擎替换成InnoDB后,由于其丰富的特性,支持事务机制、支持行级锁、可靠的故障恢复机制、优异的并发性能支持、超高的内存利用度.....等一系列优点,这使得MySQL在数据库市场的占用率直线上升。
更换默认存储引擎后的下一个版本,即MySQL5.7,在其中优化了更换引擎带来的一些遗留问题,也成为了MySQL数据库有史以来最受欢迎的版本,在MySQL发布的众多版本中一直保持统治地位,基本上只有多年后发布的MySQL8.0版本才能与之聘美。
三、MyISAM引擎真的一无是处吗?
迄今为止,本章一直在痛贬MyISAM引擎,似乎MyISAM引擎那那儿都不行,但MySQL官方倾尽心血打造的一款引擎,难道真的一文不值、一无是处吗?答案并非如此,用它来跟InnoDB比较,看起来确实差劲一些,但对比MySQL一些其他的引擎,实则也还算是众多引擎中的佼佼者。
也包括相较于InnoDB引擎而言,它拥有的一些特性、一些优势在InnoDB中也不曾具备,所以接下来也稍微说一说MyISAM引擎的一些优良点~
3.1、统计总数的优化
一般来说,在日常业务开发过程中,咱们有一个操作会经常在数据库中进行,即:
select*count(*)*from*table_name;
好比要统计订单数、平台用户总数、会员数.....各类需求,基本上都会在数据库中执行count()操作,对于count()统计行数的操作,在MyISAM引擎中会记录表的行数,也就是当执行count()时,如果表是MyISAM引擎,则可以直接获取之前统计的值并返回。
但这个特性在
InnoDB引擎中是不具备的,当你在InnoDB中统计一张表的总数时,会触发全表扫描,InnoDB会一行行的去统计表的行数。
但是MyISAM的这个特性也仅仅只适用于统计全表数据量,如果后面跟了where条件:
select*count(*)*from*table_name*where*xxx*=*"xxx";
如果是这种情况,那InnoDB、MyISAM的工作模式是相同的,先根据where后的条件查询数据,再一行行统计总数。
3.2、删除数据/表的优化
当使用delete命令清空表数据时,如下:
delete*from*table_name;
MyISAM会直接重新创建表数据文件,而InnoDB则是一行行删除数据,因此对于清空表数据的操作,MyISAM比InnoDB快上无数倍。同时MyISAM引擎的表,对于delete过的数据不会立即删除,而且先隐藏起来,后续定时删除或手动删除,手动强制清理的命令如下:
optimize*table*table_name;
这样做有一点好处,就是当你误删一张表的大量数据时,只要你手速够快,手动将本地的.MYD、.MYI文件拷贝出去,就可以直接基于这两个数据文件恢复数据,而不需要通过日志或第三方工具修复数据。
3.3、CRUD速度更快
因为InnoDB支持聚簇索引,因此整个表数据都会和聚簇索引一起放在一颗B+树中存储,就算当你没有定义主键时,InnoDB也会定义一个隐式字段ROW_ID来作为聚簇索引字段,这也就意味着:在InnoDB的表中,这个聚簇索引你不要也得要!
聚簇索引带来的好处很明显,可以借助它来实现行级别的锁,但凡事有利有弊,鱼和熊掌不可兼得。
当查询数据时,如果在基于非聚簇索引查找数据,就算查到了也需要经过一次回表才能得到数据,同时插入数据、修改数据时,都需要维护聚簇索引和非聚簇索引之间的关系,对于这点可参考:《索引原理篇-写SQL执行时索引的维护过程》。
一句话来概述就是:InnoDB的聚簇索引,会影响读写数据的性能。
而MyISAM引擎中,所有已创建的索引都是非聚簇索引,每个索引之间都是独立的,在索引中存储的是直接指向行数据的地址,而并非聚簇索引的索引键,因此无论走任何索引,都仅需一次即可获得数据,无需做回表查询。
同时写数据时,也不需要维护不同索引之间的关系,毕竟每个索引都是独立的,因此MyISAM在理论上,读写数据的效率会高于InnoDB引擎。
不过理论终归是理论,放在实际的生产环境中,这条理论是行不通的,Why?咱们一起来聊聊这个话题。
3.4、MyISAM真的比InnoDB快吗?
如果是对比单个客户端连接的读写性能,那自然MyISAM远超于InnoDB引擎,毕竟InnoDB需要维护聚簇索引,而MyISAM因为每个索引都是独立的,因此插入表数据时都是直接追加在表数据文件的末尾即可,而且修改数据也不需要维护其他索引和聚簇索引的关系。
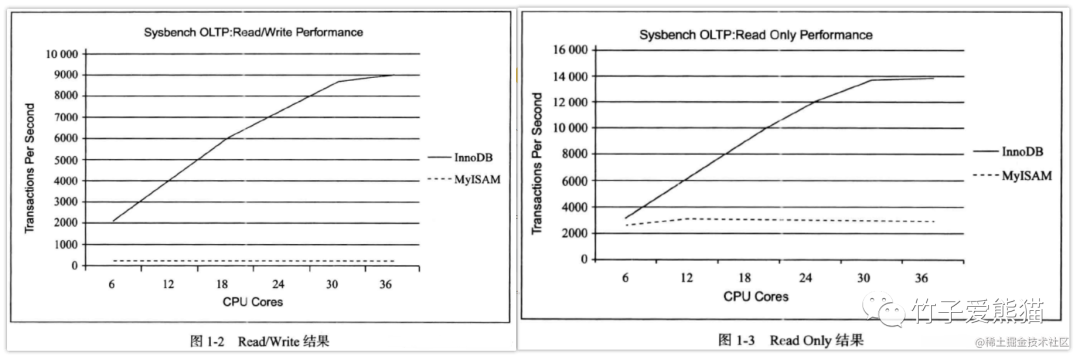
但把测试的环境换到多个客户端连接的场景时,会出现不同的现象,先看看官网上的测试图:
 性能测试
性能测试
观察上图可明显发现,随着连接数的增加,工作线程会不断增加,CPU使用核数也会不断增加,而InnoDB的性能会逐步上升,但MyISAM引擎基本上没有太大变化,基本上从头到尾一直都很低,这是啥原因造成的呢?答案是由于锁机制导致的。
之前聊到过,
MyISAM引擎仅支持表锁,也就意味着无论有多少个客户端连接到来,对于同一张表永远只能允许一条线程操作,除非多个连接都是在读数据,才不会相互排斥。
反观InnoDB引擎,由于支持行锁,所以并发冲突很小,在高并发、多连接的场景中,性能会更加出色,而MyISAM引擎基本上在并发读写场景中,一张表只允许单线程操作,因此并发冲突很大,吞吐量会因此严重下降。
到这里应该大家也理解了《高性能MySQL》的那句话:不要轻易相信「
MyISAM比InnoDB快」之类的经验之谈,这个结论往往不是绝对的,在很多情况下,InnoDB的性能往往会远超MyISAM。
但如果以单连接的方式测试,确实MyISAM会远超InnoDB,毕竟单个连接意味着只有一条线程,一条线程就不会出现锁竞争,表锁会一直由这条线程持有。
3.5、MyISAM的压缩机制
如今的数据库随着业务发展,数据量的增长一天一个新变化,时间不断推移,数据只会越来越大,这时就很容易出现以下两个问题:
- • IO瓶颈:DB数据量过大,导致内存无法载入太多数据,会触发大量磁盘IO,让DB整体性能降低。
- • 磁盘空间不足:随着业务的发展,部署数据库的机器磁盘无法存储数据,需要不断扩容硬件。
而MyISAM引擎为了解决这个问题,可以通过myisampack工具对数据表进行压缩,压缩的效果至少能让数据缩小一半,但压缩后的数据只可读,不可写,这点要牢记!
到了MySQL5.7版本中,该特性也被移植到了InnoDB引擎中,相关的压缩参数如下:
- • innodb_compression_level:调整压缩的级别,可控范围在1~9,越高压缩效果越好,但压缩速度也越慢。
- • innodb_compression_failure_threshold_pct:当压缩失败的数据页超出该比例时,会加入数据填充来减小失败率,为0表示禁止填充。
- • innodb_compression_pad_pct_max:一个数据页中最大允许填充多少比例的空白数据。
- • innodb_log_compressed_pages:控制是否对redo-log日志的数据也开启压缩机制。
- • innodb_cmp_per_index_enabled:是否对索引文件开启压缩机制。
当然,对于这些压缩机制仅需了解即可,毕竟现在分布式技术十分成熟了,因此很少会让单库承载特别大的数据量,一般当数据达到一定级别时,都会采用分库分表的方案来均摊数据,避免单库数据量过大而影响性能。
3.6、MyISAM引擎的适用场景
对于MyISAM引擎一些其他方面的特性就不做过多介绍了,大家感兴趣可自行查阅相关资料了解,现在来简单的聊一聊:什么场景下,适合选用MyISAM引擎呢?
结合
MyISAM引擎的特性而言,它适用于一些不需要事务、并发冲突低、读操作多的表,例如文章表、帖子表、字典表....
但实际上这种表在一个系统中占比很少,但有一种场景时,特别适合使用MyISAM引擎,即MySQL利用主从架构,实现读写分离时的场景,一般从库会承载select请求,而主库会承载insert/update/delete请求。读写分离的场景中,从库的表结构可以改为MyISAM引擎,因为基于MyISAM的索引查询数据,不需要经过回表查询,速度更快!
同时,由于做了读写分离,因此从库上只会有读请求,不会存在任何外部的写请求,所以支持并发读取。
而且从库的数据是由后台线程来从主库复制的,因此从库在写入数据时,只会有少数几条线程执行写入工作,因而造成的冲突不会太大,不会由于表锁引起大量阻塞。
3.7、关于引擎的一些命令
- • show create table table_name:查看一张表的存储引擎。
- • create table .... ENGINE=InnoDB:创建表时指定存储引擎。
- • alter table table_name set ENGINE=MyISAM:修改一张表的存储引擎。
还有一条批量修改一个库所有表的存储引擎命令,如下:
mysql_convert_table_fromat*--user=user_name*--password=user_pwd*--engine=MyISAM*database_name;
使用时需要使用root账户来执行,最后跟上数据库的名字即可。
四、MySQL引擎篇总结
本篇虽然是讲MySQL的存储引擎层,但咱们更多的是在讲InnoDB、MyISAM引擎,毕竟MySQL中风华正茂的引擎就这两款,同时我对其他引擎也没有过多研究,因此重点阐述的就是这两款引擎,其实在MySQL还有另外一款引擎比较有特色,也就是Memory引擎,这款引擎在MySQL启动之后会完全基于内存工作,对比Redis这类K-V数据库,Memory引擎则是关系型的内存引擎,在有些场景下也会带来意想不到的额外收获~
MySQL能够崛起的根本原因,也在于它的引擎是支持可拔插式的,并且同一个数据库中,对于不同业务属性的表,可以选用、设置不同的存储引擎,这样能够集百家之长。相较于SQL Server、Oracle等这类数据库,功能更加多样化。
但并非所有
MySQL引擎都具备优良的特性,不同引擎之间对数据的存储方式、查询数据的速度、支持的并发度也不同,虽然MySQL的可拔插式引擎,造就了MySQL特性的多样化,但其中各类引擎也参差不齐,所以如若对各款引擎没有太过深入的研究,最好还是根据业务在InnoDB、MyISAM两者之间做抉择!
最后,虽然MySQL的一个数据库中支持使用多种存储引擎,但也不要盲目使用,毕竟使用的存储引擎越多,对于每个引擎可分配的资源也就越少,拿典型的内存资源为例,如果一个库中使用了七八种引擎,那内存资源需要划分给这七八个引擎,这必然会导致各引擎之间相互影响,从而降低MySQL的整体吞吐量。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: