引言
在《MySQL锁机制》这篇文章中,咱们全面剖析了MySQL提供的锁机制,对于并发事务通常可以通过其提供的各类锁,去确保各场景下的线程安全问题,从而能够防止脏写、脏读、不可重复读及幻读这类问题出现。
不过成也萧何败也萧何,虽然
MySQL提供的锁机制确实能解决并发事务带来的一系列问题,但由于加锁后会让一部分事务串行化,而MySQL本身就是基于磁盘实现的,性能无法跟内存型数据库娉美,因此并发事务串行化会使其效率更低。
也正是由于上述原因,因此MySQL官方在设计时,抓破脑袋的想:有没有办法再快一点!!最终,MVCC机制就诞生了,相较于加锁串行化执行,MVCC机制的出现,则以另一种形式解决了并发事务造成的问题。
PS:个人编写的《技术人求职指南》小册已完结,其中从技术总结开始,到制定期望、技术突击、简历优化、面试准备、面试技巧、谈薪技巧、面试复盘、选Offer方法、新人入职、进阶提升、职业规划、技术管理、涨薪跳槽、仲裁赔偿、副业兼职……,为大家打造了一套“从求职到跳槽”的一条龙服务,同时也为诸位准备了七折优惠码:3DoleNaE,近期需要找工作的小伙伴可以复制链接了解详情:https://s.juejin.cn/ds/USoa2R3/
一、并发事务的四种场景
并发事务中又会分为四种情况,分别是读-读、写-写、读-写、写-读,这四种情况分别对应并发事务执行时的四种场景,为了后续分析MVCC机制时方便理解,因此先将这几种情况说明,咱们首先来看看读-读场景。
1.1、读-读场景
读-读场景即是指多个事务/线程在一起读取一个相同的数据,比如事务T1正在读取ID=88的行记录,事务T2也在读取这条记录,两个事务之间是并发执行的。
广为人知的一点:
MySQL执行查询语句,绝对不会对引起数据的任何变化,因此对于这种情况而言,不需要做任何操作,因为不改变数据就不会引起任何并发问题。
1.2、写-写场景
写-写场景也比较简单,也就是指多个事务之间一起对同一数据进行写操作,比如事务T1对ID=88的行记录做修改操作,事务T2则对这条数据做删除操作,事务T1提交事务后想查询看一下,哦豁,结果连这条数据都不见了,这也是所谓的脏写问题,也被称为更新覆盖问题,对于这个问题在所有数据库、所有隔离级别中都是零容忍的存在,最低的隔离级别也要解决这个问题。
1.3、读-写、写-读场景
读-写、写-读实际上从宏观角度来看,可以理解成同一种类型的操作,但从微观角度而言则是两种不同的情况,读-写是指一个事务先开始读,然后另一个事务则过来执行写操作,写-读则相反,主要是读、写发生的前后顺序的区别。
并发事务中同时存在读、写两类操作时,这是最容易出问题的场景,脏读、不可重复读、幻读都出自于这种场景中,当有一个事务在做写操作时,读的事务中就有可能出现这一系列问题,因此数据库才会引入各种机制解决。
1.4、各场景下解决问题的方案
在《MySQL锁机制》中,对于写-写、读-写、写-读这三类场景,都是利用加锁的方案确保线程安全,但上面说到过,加锁会导致部分事务串行化,因此效率会下降,而MVCC机制的诞生则解决了这个问题。
先来设想一个问题:加锁的目的是什么?防止脏写、脏读、不可重复读及幻读这类问题出现。
对于脏写问题,这是写-写场景下会出现的,写-写场景必须要加锁才能保障安全,因此先将该场景排除在外。再想想:对于读-写并存的场景中,脏读、不可重复读及幻读问题都出自该场景中,但实际项目中,出现这些问题的几率本身就比较小,为了防止一些小概念事件,就将所有操纵同一数据的并发读写事务串行化,这似乎有些不讲道理呀,就好比:
为了防止自家保险柜中的
3.25元被偷,所以每天从早到晚一直守着保险柜,这合理吗?并不合理,毕竟只有千日做贼,那有千日防贼的道理。
因此MySQL就基于读-写并存的场景,推出了MVCC机制,在线程安全问题和加锁串行化之间做了一定取舍,让两者之间达到了很好的平衡,即防止了脏读、不可重复读及幻读问题的出现,又无需对并发读-写事务加锁处理。
咋做到的呢?接下来一起来好好聊一聊大名鼎鼎的
MVCC机制。
二、MySQL-MVCC机制综述
MVCC机制的全称为Multi-Version Concurrency Control,即多版本并发控制技术,主要是为了提升数据库并发性能而设计的,其中采用更好的方式处理了读-写并发冲突,做到即使有读写冲突时,也可以不加锁解决,从而确保了任何时刻的读操作都是非阻塞的。
但与其说是
MySQL-MVCC机制,还不如说是InnoDB-MVCC机制,因为在MySQL众多的开源存储引擎中,几乎只有InnoDB实现了MVCC机制,类似于MyISAM、Memory等引擎中都未曾实现,那其他引擎为何不实现呢?不是不想,而是做不到,这跟MVCC机制的实现原理有关,这点放在后续详细讲解~
不过为了更好的理解啥叫MVCC多版本并发控制,先来看一个日常生活的例子~
2.1、MVCC技术在日常生活中的体现
不知道各位小伙伴中,是否有人做过论坛这类业务的项目,或者类似审核的业务需求,以掘金的文章为例,此时来思考一个场景:
假设我发布了一篇关于《MySQL事务机制》的文章,发布后挺受欢迎的,因此有不少小伙伴在看,其中有一位小伙伴比较细心,文中存在两三个错别字,被这位小伙伴指出来了,因此我去修正错别字后重新发布。
问题来了,对于文章首次发布也好,重新发布也罢,绝对要等审核通过后才会正式发布的,那我修正文章后重新发布,文章又会进入「审核中」这个状态,此时对于其他正在看、准备看的小伙伴来说,文章是不是就不见了?毕竟文章还在审核撒,因此对这个业务需求又该如何实现呢?多版本!
啥意思呢?也就是说,对于首次发布后通过审核的文章,在后续重新发布审核时,用户可以看到更新前的文章,也就是看到老版本的文章,当更新后的文章审核通过后,再使用新版本的文章代替老版本的文章即可。
这样就能做到新老版本的兼容,也能够确保文章修正时,其他正在阅读的小伙伴不会受影响,而MySQL-MVCC机制的思想也大致相同。
2.2、MySQL-MVCC多版本并发控制
MySQL中的多版本并发控制,也和上面给出的例子类似,毕竟回想一下,脏读、不可重复读、幻读问题都是由于多个事务并发读写导致的,但这些问题都是基于最新版本的数据并发操作才会出现,那如果读、写的事务操作的不是同一个版本呢?比如写操作走新版本,读操作走老版本,这样是不是无论执行写操作的事务干了啥,都不会影响读的事务?答案是Yes。
不过要稍微记住,
MySQL中仅在RC读已提交级别、RR可重复读级别才会使用MVCC机制,Why?
因为如果是RU读未提交级别,既然都允许存在脏读问题、允许一个事务读取另一个事务未提交的数据,那自然可以直接读最新版本的数据,因此无需MVCC介入。
同时如若是Serializable串行化级别,因为会将所有的并发事务串行化处理,也就是不论事务是读操作,亦或是写操作,都会被排好队一个个执行,这都不存在所谓的多线程并发问题了,自然也无需MVCC介入。
因此要牢记:
MVCC机制在MySQL中,仅有InnoDB引擎支持,而在该引擎中,MVCC机制只对RC、RR两个隔离级别下的事务生效。当然,RC、RR两个不同的隔离级别中,MVCC的实现也存在些许差异,对于这点后续详细讲解。
三、MySQL-MVCC机制实现原理剖析
OK~,简单理解了啥叫MVCC机制后,接着一起来看看InnoDB引擎是如何实现它的,MVCC机制主要通过隐藏字段、Undo-log日志、ReadView这三个东西实现的,因而这三玩意儿也被称为“MVCC三剑客”!废话不多说,一起来看看。
3.1、InnoDB表的隐藏字段
通常而言,当你基于InnoDB引擎建立一张表后,MySQL除开会构建你显式声明的字段外,通常还会构建一些InnoDB引擎的隐藏字段,在InnoDB引擎中主要有DB_ROW_ID、DB_Deleted_Bit、DB_TRX_ID、DB_ROLL_PTR这四个隐藏字段,挨个简单介绍一下。
3.1.1、隐藏主键 - ROW_ID(6Bytes)
在之前介绍《索引原理篇》的时候聊到过一点,对于InnoDB引擎的表而言,由于其表数据是按照聚簇索引的格式存储,因此通常都会选择主键作为聚簇索引列,然后基于主键字段构建索引树,但如若表中未定义主键,则会选择一个具备唯一非空属性的字段,作为聚簇索引的字段来构建树。
当两者都不存在时,
InnoDB就会隐式定义一个顺序递增的列ROW_ID来作为聚簇索引列。
因此要牢记一点,如果你选择的引擎是InnoDB,就算你的表中未定义主键、索引,其实默认也会存在一个聚簇索引,只不过这个索引在上层无法使用,仅提供给InnoDB构建树结构存储表数据。
3.1.2、删除标识 - Deleted_Bit(1Bytes)
在之前讲《SQL执行篇-写SQL执行原理》时,咱们只粗略的过了一下大体流程,其中并未涉及到一些细节阐述,在这里稍微提一下:对于一条delete语句而言,当执行后并不会立马删除表的数据,而是将这条数据的Deleted_Bit删除标识改为1/true,后续的查询SQL检索数据时,如果检索到了这条数据,但看到隐藏字段Deleted_Bit=1时,就知道该数据已经被其他事务delete了,因此不会将这条数据纳入结果集。
OK~,但设计
Deleted_Bit这个隐藏字段的好处是什么呢?主要是能够有利于聚簇索引,比如当一个事务中删除一条数据后,后续又执行了回滚操作,假设此时是真正的删除了表数据,会发生什么情况呢?
- • ①删除表数据时,有可能会破坏索引树原本的结构,导致出现叶子节点合并的情况。
- • ②事务回滚时,又需重新插入这条数据,再次插入时又会破坏前面的结构,导致叶子节点分裂。
综上所述,如果执行
delete语句就删除真实的表数据,由于事务回滚的问题,就很有可能导致聚簇索引树发生两次结构调整,这其中的开销可想而知,而且先删除,再回滚,最终树又变成了原状,那这两次树的结构调整还是无意义的。
所以,当执行delete语句时,只会改变将隐藏字段中的删除标识改为1/true,如果后续事务出现回滚动作,直接将其标识再改回0/false即可,这样就避免了索引树的结构调整。
但如若事务删除数据之后提交了事务呢?总不能让这条数据一直留在磁盘吧?毕竟如果所有的
delete操作都这么干,就会导致磁盘爆满~,显然这样是不妥的,因此删除标识为1/true的数据最终依旧会从磁盘中移除,啥时候移呢?
在之前讲《Nginx-缓存清理》时,曾经提到过purger这一系列的参数,通过配置该系列参数后,Nginx后台中会创建对应的purger线程去自动删除缓存数据。而MySQL中也不例外,同样存在purger线程的概念,为了防止“已删除”的数据占用过多的磁盘空间,purger线程会自动清理Deleted_Bit=1/true的行数据。
当然,为了确保清理数据时不会影响
MVCC的正常工作,purger线程自身也会维护一个ReadView,如果某条数据的Deleted_Bit=true,并且TRX_ID对purge线程的ReadView可见,那么这条数据一定是可以被安全清除的(即不会影响MVCC工作)。
对于上述最后一段大家可能会有些许疑惑,这是因为还未曾介绍ReadView,因此有些不理解可先跳过,后续理解了ReadView后再回来看会好很多。
3.1.3、最近更新的事务ID - TRX_ID(6Bytes)
TRX_ID全称为transaction_id,翻译过来也就是事务ID的意思,MySQL对于每一个创建的事务,都会为其分配一个事务ID,事务ID同样遵循顺序递增的特性,即后来的事务ID绝对会比之前的ID要大,比如:
此时事务
T1准备修改表字段的值,MySQL会为其分配一个事务ID=1,当事务T2准备向表中插入一条数据时,又会为这个事务分配一个ID=2......
但有一个细节点需要记住:MySQL对于所有包含写入SQL的事务,会为其分配一个顺序递增的事务ID,但如果是一条select查询语句,则分配的事务ID=0。
不过对于手动开启的事务,
MySQL都会为其分配事务ID,就算这个手动开启的事务中仅有select操作。
表中的隐藏字段TRX_ID,记录的就是最近一次改动当前这条数据的事务ID,这个字段是实现MVCC机制的核心之一。
3.1.4、回滚指针 - ROLL_PTR(7Bytes)
ROLL_PTR全称为rollback_pointer,也就是回滚指针的意思,这个也是表中每条数据都会存在的一个隐藏字段,当一个事务对一条数据做了改动后,都会将旧版本的数据放到Undo-log日志中,而rollback_pointer就是一个地址指针,指向Undo-log日志中旧版本的数据,当需要回滚事务时,就可以通过这个隐藏列,来找到改动之前的旧版本数据,而MVCC机制也利用这点,实现了行数据的多版本。
3.2、InnoDB引擎的Undo-log日志
在之前《事务篇》中分析事务实现原理时,咱们得知了MySQL事务机制是基于Undo-log实现的,同时在刚刚在聊回滚指针时,聊到了Undo-log日志中会存储旧版本的数据,但要注意:Undo-log中并不仅仅只存储一条旧版本数据,其实在该日志中会有一个版本链,啥意思呢?举个例子:
SELECT***FROM*zz_users*WHERE*user_id*=*1;
+---------+-----------+----------+----------+---------------------+
|*user_id*|*user_name*|*user_sex*|*password*|*register_time*******|
+---------+-----------+----------+----------+---------------------+
|*******1*|*熊猫******|*女*******|*6666*****|*2022-08-14*15:22:01*|
+---------+-----------+----------+----------+---------------------+
UPDATE*zz_users*SET*user_name*=*"竹子"*WHERE*user_id*=*1;
UPDATE*zz_users*SET*user_sex*=*"男"*WHERE*user_id*=*1;
比如上述这段SQL隶属于trx_id=1的T1事务,其中对同一条数据改动了两次,那Undo-log日志中只会存储一条旧版本数据吗?NO,答案是两条旧版本的数据,如下图:
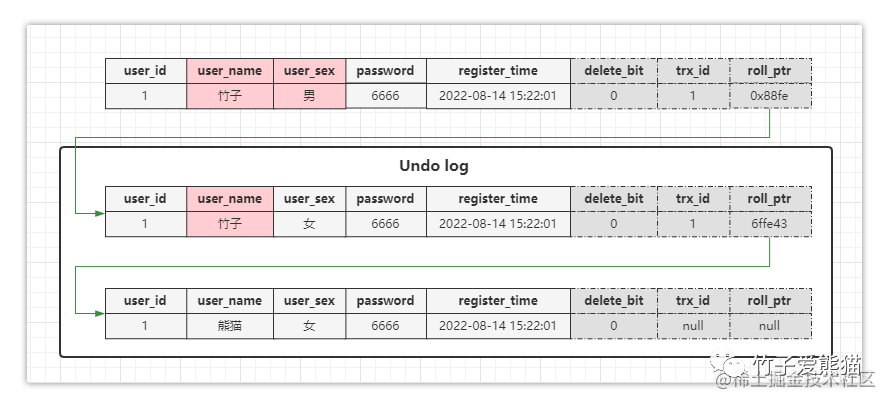 Undo版本链
Undo版本链
从上图中可明显看出:不同的旧版本数据,会以roll_ptr回滚指针作为链接点,然后将所有的旧版本数据组成一个单向链表。但要注意一点:最新的旧版本数据,都会插入到链表头中,而不是追加到链表尾部。
细说一下执行上述
update语句的详细过程:
①对ID=1这条要修改的行数据加上排他锁。
②将原本的旧数据拷贝到Undo-log的rollback Segment区域。
③对表数据上的记录进行修改,修改完成后将隐藏字段中的trx_id改为当前事务ID。
④将隐藏字段中的roll_ptr指向Undo-log中对应的旧数据,并在提交事务后释放锁。
为什么Undo-log日志要设计出版本链呢?两个好处:一方面可以实现事务点回滚(这点回去参考事务篇),另一方面则可以实现MVCC机制(这点后面聊)。
与之前的删除标识类似,一条数据被
delete后并提交了,最终会从磁盘移除,而Undo-log中记录的旧版本数据,同样会占用空间,因此在事务提交后也会移除,移除的工作同样由purger线程负责,purger线程内部也会维护一个ReadView,它会以此作为判断依据,来决定何时移除Undo记录。
3.3、MVCC核心 - ReadView
MVCC在前面聊到过,它翻译过来就是多版本并发控制的意思,对于这个名词中的多版本已经通过Undo-log日志实现了,但再思考一个问题:如果T2事务要查询一条行数据,此时这条行数据正在被T1事务写,那也就代表着这条数据可能存在多个旧版本数据,T2事务在查询时,应该读这条数据的哪个版本呢?此时就需要用到ReadView,用它来做多版本的并发控制,根据查询的时机来选择一个当前事务可见的旧版本数据读取。
那究竟什么是
ReadView呢?就是一个事务在尝试读取一条数据时,MVCC基于当前MySQL的运行状态生成的快照,也被称之为读视图,即ReadView,在这个快照中记录着当前所有活跃事务的ID(活跃事务是指还在执行的事务,即未结束(提交/回滚)的事务)。
当一个事务启动后,首次执行select操作时,MVCC就会生成一个数据库当前的ReadView,通常而言,一个事务与一个ReadView属于一对一的关系(不同隔离级别下也会存在细微差异),ReadView一般包含四个核心内容:
- • creator_trx_id:代表创建当前这个ReadView的事务ID。
- • trx_ids:表示在生成当前ReadView时,系统内活跃的事务ID列表。
- • up_limit_id:活跃的事务列表中,最小的事务ID。
- • low_limit_id:表示在生成当前ReadView时,系统中要给下一个事务分配的ID值。
上面四个值很简单,值得一提的是low_limit_id,它并不是目前系统中活跃事务的最大ID,因为之前讲到过,MySQL的事务ID是按序递增的,因此当启动一个新的事务时,都会为其分配事务ID,而这个low_limit_id则是整个MySQL中,要为下一个事务分配的ID值。
下面上个ReadView的示意图,来好好理解一下它:
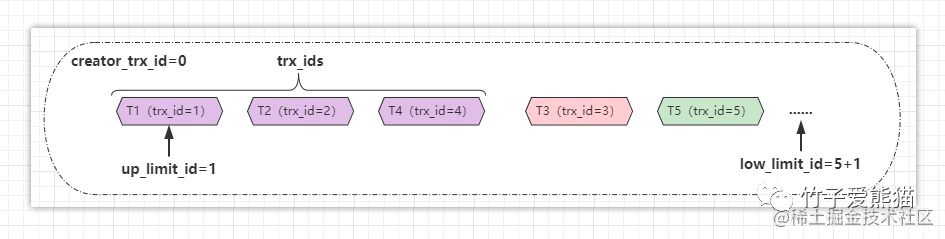 ReadView
ReadView
假设目前数据库中共有T1~T5这五个事务,T1、T2、T4还在执行,T3已经回滚,T5已经提交,此时当有一条查询语句执行时,就会利用MVCC机制生成一个ReadView,由于前面讲过,单纯由一条select语句组成的事务并不会分配事务ID,因此默认为0,所以目前这个快照的信息如下:
{
****"creator_trx_id"*:*"0",
****"trx_ids"*:*"[1,2,4]",
****"up_limit_id"*:*"1",
****"low_limit_id"*:*"6"
}
OK~,简单明白ReadView的结构后,接着一起来聊一聊MVCC机制的实现原理。
3.4、MVCC机制实现原理
将“MVCC三剑客”的概念阐述完毕后,再结合三者来谈谈MVCC的实现,其实也比较简单,经过前面的讲解后已得知:
- • ①当一个事务尝试改动某条数据时,会将原本表中的旧数据放入Undo-log日志中。
- • ②当一个事务尝试查询某条数据时,MVCC会生成一个ReadView快照。
其中Undo-log主要实现数据的多版本,ReadView则主要实现多版本的并发控制,还是以之前的例子来举例说明:
--*事务T1:trx_id=1
UPDATE*zz_users*SET*user_name*=*"竹子"*WHERE*user_id*=*1;
UPDATE*zz_users*SET*user_sex*=*"男"*WHERE*user_id*=*1;
--*事务T2:trx_id=2
SELECT***FROM*zz_users*WHERE*user_id*=*1;
目前存在T1、T2两个并发事务,T1目前在修改ID=1的这条数据,而T2则准备查询这条数据,那么T2在执行时具体过程是怎么回事呢?如下:
- • ①当事务中出现select语句时,会先根据MySQL的当前情况生成一个ReadView。
- • ②判断行数据中的隐藏列trx_id与ReadView.creator_trx_id是否相同:
- • 相同:代表创建ReadView和修改行数据的事务是同一个,自然可以读取最新版数据。
• 不相同:代表目前要查询的数据,是被其他事务修改过的,继续往下执行。
- • ③判断隐藏列trx_id是否小于ReadView.up_limit_id最小活跃事务ID:
- • 小于:代表改动行数据的事务在创建快照前就已结束,可以读取最新版本的数据。
• 不小于:则代表改动行数据的事务还在执行,因此需要继续往下判断。
- • ④判断隐藏列trx_id是否小于ReadView.low_limit_id这个值:
- • 大于或等于:代表改动行数据的事务是生成快照后才开启的,因此不能访问最新版数据。
• 小于:表示改动行数据的事务ID在up_limit_id、low_limit_id之间,需要进一步判断。
- • ⑤如果隐藏列trx_id小于low_limit_id,继续判断trx_id是否在trx_ids中:
- • 在:表示改动行数据的事务目前依旧在执行,不能访问最新版数据。
• 不在:表示改动行数据的事务已经结束,可以访问最新版的数据。
说简单一点,就是首先会去获取表中行数据的隐藏列,然后经过上述一系列判断后,可以得知:目前查询数据的事务到底能不能访问最新版的数据。如果能,就直接拿到表中的数据并返回,反之,不能则去Undo-log日志中获取旧版本的数据返回。
注意:假设
Undo-log日志中存在版本链怎么办?该获取哪个版本的旧数据呢?
如果Undo-log日志中的旧数据存在一个版本链时,此时会首先根据隐藏列roll_ptr找到链表头,然后依次遍历整个列表,从而检索到最合适的一条数据并返回。但在这个遍历过程中,是如何判断一个旧版本的数据是否合适的呢?条件如下:
- • 旧版本的数据,其隐藏列trx_id不能在ReadView.trx_ids活跃事务列表中。
因为如果旧版本的数据,其trx_id依旧在ReadView.trx_ids中,就代表着产生这条旧数据的事务还未提交,自然不能读取这个版本的数据,以前面给出的例子来说明:
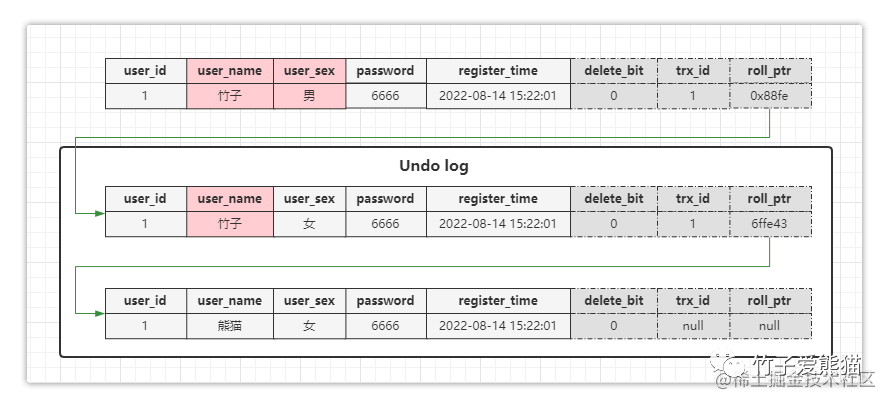 Undo版本链
Undo版本链
这是由事务T1生成的版本链,此时T2生成的ReadView如下:
{
****"creator_trx_id"*:*"0",
****"trx_ids"*:*"[1]",
****"up_limit_id"*:*"1",
****"low_limit_id"*:*"2"
}
结合这个ReadView信息,经过前面那一系列判断后,最终会得到:不能读取最新版数据,因此需要去Undo-log的版本链中读数据,首先根据roll_ptr找到第一条旧数据:
 第一条旧数据
第一条旧数据
此时发现其trx_id=1,位于ReadView.trx_ids中,因此不能读取这条旧数据,接着再根据这条旧数据的roll_ptr找到第二条旧版本数据:
 第二条旧数据
第二条旧数据
这时再看其trx_id=null,并不位于ReadView.trx_ids中,null表示这条数据在上次MySQL运行时就已插入了,因此这条旧版本的数据可以被T2事务读取,最终T2就会查询到这条数据并返回。
OK~,最后再来看一个场景!即范围查询时,突然出现新增数据怎么办呢?如下:
SELECT***FROM*zz_users;
+---------+-----------+----------+----------+---------------------+
|*user_id*|*user_name*|*user_sex*|*password*|*register_time*******|
+---------+-----------+----------+----------+---------------------+
|*******1*|*熊猫******|*女*******|*6666*****|*2022-08-14*15:22:01*|
|*******2*|*竹子******|*男*******|*1234*****|*2022-09-14*16:17:44*|
|*******3*|*子竹******|*男*******|*4321*****|*2022-09-16*07:42:21*|
|*******4*|*猫熊******|*女*******|*8888*****|*2022-09-27*17:22:59*|
|*******9*|*黑竹******|*男*******|*9999*****|*2022-09-28*22:31:44*|
+---------+-----------+----------+----------+---------------------+
-- T1事务:查询ID >= 3 的所有用户信息
select***from**zz_users*where*user_id*>`=*3;
-- T2事务:新增一条 ID = 6 的用户记录
INSERT*INTO*zz_users*VALUES(6,"棕熊","男","7777","2022-10-02*16:21:33");
此时当T1事务查询数据时,突然蹦出来一条ID=6的数据,经过判断之后会发现新增这条数据的事务还在执行,所以要去查询旧版本数据,但此时由于是新增操作,因此roll_ptr=null,即表示没有旧版本数据,此时会不会读取最新版的数据呢?答案是NO,如果查询数据的事务不能读取最新版数据,同时又无法从版本链中找到旧数据,那就意味着这条数据对T1事务完全不可见,因此T1的查询结果中不会包含ID=6的这条新增记录。
附加说明:如果这个一个修改数据的事务正好快照生成结束后才开启的,并且多次修改了目前
select操作要读取的目标数据行,因此在Undo版本链中会产生一系列旧数据,但根据前面的一系列判断,最终select事务会去版本链中找数据,此时后面这个修改事务的ID,恰巧不在快照到trx_ids列表中怎么办呢?
面对于这种情况,当MVCC发现旧版本的数据,其隐藏列的trx_id大于目前快照的最大事务ID时,MVCC会自动跳过该版本的数据,Why?因为MySQL在分配事务ID时,都是以递增的顺序分配,所以当旧版本上的trx_id大于快照的最大事务ID时,说明这条旧版本数据是在快照生成之后产生的,所以会跳过对应的旧版本数据不读取。
3.5、RC、RR不同级别下的MVCC机制
3.4阶段已经将MVCC机制的具体实现过程剖析了一遍,接下来再思考一个问题:
ReadView是一个事务中只生成一次,还是每次select时都会生成呢?
这个问题的答案跟事务的隔离机制有关,不同级别的隔离机制也并不同,如果此时MySQL的事务隔离机制处于RC读已提交级别,那此时来看一个例子:
--*开启一个事务T1:主要是修改两次ID=1的行数据
begin;
UPDATE*zz_users*SET*user_name*=*"竹子"*WHERE*user_id*=*1;
UPDATE*zz_users*SET*user_sex*=*"男"*WHERE*user_id*=*1;
--*再开启一个事务T2:主要是查询ID=1的行数据
SELECT***FROM*zz_users*WHERE*user_id*=*1;
--*此时先提交事务T1
commit;
--*再次在事务T2中查一次ID=1的行数据
SELECT***FROM*zz_users*WHERE*user_id*=*1;
先说明一点,为了方便理解,因此我将两个事务的代码贴在了一块,但如若你要做实际的实验,请切记将
T1、T2用两个连接来写。
OK~,再来看看上述这个案例,如果是处于RC级别的情况下,T2事务中的查询结果如下:
SELECT***FROM*zz_users*WHERE*user_id*=*1;
+---------+-----------+----------+----------+---------------------+
|*user_id*|*user_name*|*user_sex*|*password*|*register_time*******|
+---------+-----------+----------+----------+---------------------+
|*******1*|*熊猫******|*女*******|*6666*****|*2022-08-14*15:22:01*|
+---------+-----------+----------+----------+---------------------+
SELECT***FROM*zz_users*WHERE*user_id*=*1;
+---------+-----------+----------+----------+---------------------+
|*user_id*|*user_name*|*user_sex*|*password*|*register_time*******|
+---------+-----------+----------+----------+---------------------+
|*******1*|*竹子******|*男*******|*6666*****|*2022-08-14*15:22:01*|
+---------+-----------+----------+----------+---------------------+
为什么两次查询结果不一样呢?因为RC级别下,MVCC机制是会在每次select语句执行前,都会生成一个ReadView,由于T2事务中第二次查询数据时,T1已经提交了,所以第二次查询就能读到修改后的数据,这是啥问题?不可重复读问题。
接着再来看看
RR可重复级别下的MVCC机制,SQL代码和上述一模一样,但查询结果如下:
SELECT***FROM*zz_users*WHERE*user_id*=*1;
+---------+-----------+----------+----------+---------------------+
|*user_id*|*user_name*|*user_sex*|*password*|*register_time*******|
+---------+-----------+----------+----------+---------------------+
|*******1*|*熊猫******|*女*******|*6666*****|*2022-08-14*15:22:01*|
+---------+-----------+----------+----------+---------------------+
SELECT***FROM*zz_users*WHERE*user_id*=*1;
+---------+-----------+----------+----------+---------------------+
|*user_id*|*user_name*|*user_sex*|*password*|*register_time*******|
+---------+-----------+----------+----------+---------------------+
|*******1*|*熊猫******|*女*******|*6666*****|*2022-08-14*15:22:01*|
+---------+-----------+----------+----------+---------------------+
这又是为啥?为啥明明在T2事务第二次查询前,T1已经提交了,T2依旧查询出的结果和第一次相同呢?这是因为在RR级别中,一个事务只会在首次执行select语句时生成快照,后续所有的select操作都会基于这个ReadView来判断,这样也就解决了RC级别中存在的不可重复问题。
最后简单提一嘴:实际上
InnoDB引擎中,是可以在RC级别解决脏读、不可重复读、幻读这一系列问题的,但是为了将事务隔离级别设计的符合DBMS规范,因此在实现时刻意保留了这些问题,然后放在更高的隔离级别中解决~
四、MVCC机制篇总结
MVCC多版本并发控制,听起来似乎蛮高大上的,但实际研究起来会发现它并不复杂,其中的多版本主要依赖Undo-log日志来实现,而并发控制则通过表的隐藏字段+ReadView快照来实现,通过Undo-log日志、隐藏字段、ReadView快照这三玩意儿,就实现了MVCC机制,过程还蛮简单的~
到这里,其实对于
MySQL的事务隔离机制,已经拨开一部分迷雾了,下篇《MySQL事务与锁机制原理篇》中,则会彻底讲清楚MySQL锁是怎么实现的,以及不同的事务隔离级别,又是如何借助锁+MVCC处理客户端SQL的,那么咱们下篇见~
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: