引言
本篇也是MySQL索引机制的终章,在经过《索引初识篇》、《索引应用篇》两篇后,已经对索引有了很高的掌握度了,但MySQL的索引机制,自始至终对于我们都是一个黑盒般的存在,我们并不清楚建立索引后MySQL会发生什么,也并不清楚使用索引查询时会如何检索......。甚至在前两篇文章中,对于索引咱们也留下了很多很多的疑惑:
 中上两篇留下的疑惑
中上两篇留下的疑惑
那么!《索引原理篇》它现在终于来了!但对于索引原理及底层实现,相信大家多多少少都有了解过,毕竟这也是面试过程中出现次数较为频繁的一个技术点。在本文中就来一窥MySQL索引底层的神秘面纱!
一、MySQL索引为何使用B+树结构?
MySQL的索引机制中,有一点可谓是路人皆知,既默认使用B+Tree作为底层的数据结构,但为什么要选择B+树呢?有人会说树结构是以二分法查找数据,所以会在很大程度上提升检索性能,这点确实没错,但树结构有那么多,MySQL为什么不选二叉树、AVL树、红黑树或B树呢?下面一起先聊一聊这个话题。
对于索引为什么不支持数组、链表、队列等结构就不做过多解释了,因为这些结构中的元素都是按序并排存储,如果选择这些结构来实现索引,那走索引依旧等价于走全表,并未带来查询时的效率提升,反而带来了额外的存储开销,这是没有意义的。
1.1、普通SQL的全表扫描过程
想要真正理解MySQL为何选B+树结构之前,你必须要先了解一条普通SQL的全表扫描过程,否则你很难真正切身感受出有索引和没索引的区别。当然,这里就不再以伪逻辑的形式讲解全表扫描了,而是真正的为大家讲解MySQL全表扫描的实际过程。以下面这张用户表为例:
 表数据
表数据
首先假设表中不存在任何索引,此时来执行下述这条SQL:
SELECT***FROM*zz_user*WHERE*name*=*"黑熊";
因为表中不具备索引,所以这里会走全表扫描的形式检索数据,但不管是走全表亦或索引,本质上由于数据都存储在磁盘中,因此首先都会触发磁盘IO,所以先来说说磁盘寻道的过程:
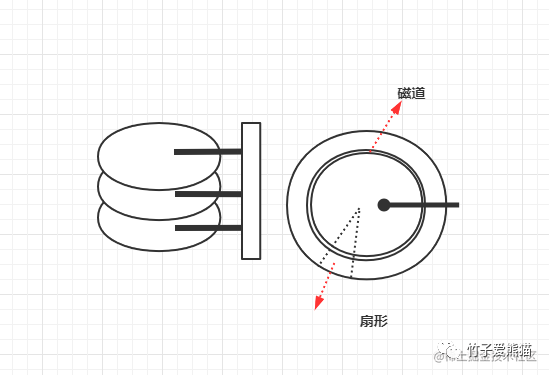 磁盘寻道
磁盘寻道
如果磁盘不是SSD类型,大致长上面这个样子,里面有一个个的盘面和磁针,当发生磁盘IO时,首先会根据给出的磁盘地址,在盘面上寻道。这个寻道过程是怎么回事呢?就跟小时候VCD、DVD放光碟类似,盘面会开始转圈圈,在盘面上有一个磁道的概念,当转到了对应的地址时,磁道和磁针会相互吸引,然后以一上一下的方式读取0、1二进制数据,最终从磁盘中将目标地址中的数据读取出来。
磁盘寻道的大致过程如上,具体的细节没写出来,重点是大家要感受这个过程即可。
当走全表扫描时,会发生磁盘IO,但是磁盘寻道是需要有一个地址的,这个地址最开始就是本地表数据文件中的起始地址,也就是从表中的第一行数据开始读,读到数据后会载入内存,然后MySQL-Server会根据SQL条件对读到的数据做判断,如果不符合条件则继续发生磁盘IO读取其他数据(如果表比较大,这里不会以顺序IO的形式走全表检索,而是会触发随机的磁盘IO)。
那来看一下,上面给出的用户表中,「黑熊」这条数据位于表的第五行,那这里会发生五次磁盘IO吗?答案是NO,为什么呢?因为OS、MySQL中都有一个优化措施,叫做局部性读取原理。
1.1.1、局部性原理
局部性原理的思想比较简单,比如目前有三块内存页x、y、z是相连的,CPU此刻在操作x页中的数据,那按照计算机的特性,一般同一个数据都会放入到物理相连的内存地址上存储,也就是当前在操作x页的数据,那么对于y,z这两页内存的数据也很有可能在接下来的时间内被操作,因此对于y,z这两页数据则会提前将其载入到高速缓冲区(L1/L2/L3),这个过程叫做利用局部性原理“预读”数据。
但是一次性到底预读多大的数据放入到高速缓冲区中呢?
这个是由缓存行大小决定的,比如因特尔的MESI协议中,缓存行的默认大小为64Bytes,也就是说在因特尔的CPU中,一次性会将“当前操作数据”附近的64Bytes数据(2页数据)提前载入进高速缓冲区。
OK~,上述内容讲的是操作系统高速缓冲区的知识,在
CPU中利用局部性原理,提前将数据从内存先放入L1/L2/L3三级缓冲区中,主要是为了减小CPU寄存器与内存之间的性能差异。
OK~,由于CPU寄存器和内存之间的性能差异太大,所以逐个读数据的形式会导致CPU工作期间的大量时间会处于等待数据状态,所以利用局部性原理将数据“预读”到高速区。而对于MySQL而言,亦是同理,存储数据的磁盘和内存之间的性能差异也是巨大的,因为MySQL也会利用局部性原理,提前“预读”数据。
这是什么意思呢?其实就是指
MySQL一次磁盘IO不仅仅只会读取一条表数据,而是会读取多条数据,那到底读多少条数据呢?在InnoDB引擎中,一次默认会读取16KB数据到内存。
1.1.2、全表扫描过程
回到前面分析全表扫描的阶段,由于MySQL中会使用局部性原理的思想,所以对于给出的用户表数据而言,可能只需发生一次磁盘IO就能将前五条数据全部读到内存,然后会在内存中对本次读取的数据逐条判断,看一下每条数据的姓名字段是否为「黑熊」:
- • 如果发现不符合SQL条件的行数据,则会将当前这条数据放弃,同时在本次SQL执行过程中会排除掉这条数据,不会对其进行二次读取。
- • 如果发现当前的数据符合SQL条件要求,则会将当前数据写入到结果集中,然后继续判断其他数据。
当本次磁盘IO读取到的所有数据全部筛选完成后,紧接着会看一下表中是否还有其他数据,如果还有则继续触发磁盘IO检索数据,如果没有则将内存中的结果集返回。
有人或许会疑惑,为什么这里已经读到了符合条件的数据,还需要继续发生磁盘
IO呢?因为表中的字段没有建立唯一索引或唯一约束,因此MySQL不确定是否还有其他同名的数据,所以需要将整个表全部扫描一遍,才能得到最终结论。
好的,到这里就将MySQL全表扫描的过程讲明白了,紧着来看看全表扫描有什么问题呢?
其实按目前的情况来看,似乎不会有太大的问题,因此表中数据不多,一次磁盘
IO几乎就能读完。但思考一下,如果当表的数据量变为百万级别、千万级别呢?假设表中一条数据大小为512Byte,一次磁盘IO也只能读32条,假设表中有320w条数据,一次全表就有可能会触发10W次磁盘IO,每次都需要在硬件上让那个盘面转啊转,其过程的开销可想而知.....
因此建立索引的原因就在于此处,为了避免查询时走全表扫描,因此全表扫描的开销会随着数据量增长而越来越大。
1.2、索引为何不选择二叉树?
数据结构与算法,这门学科从诞生到现在,自始至终都让人难以理解,但国外有一个比较厉害的程序员,为了帮助他人更好的理解数据结构,自己搭建了一个数据结构的动画演示平台,里面提供了非常多丰富的数据结构类型,我们在其中能以动画的形式观测数据结构的变化。
回归话题本身,全表扫描由于走的是线性查询,因此数据越多,开销越大,此时先来看看二叉搜索树。
Binary Search Tree二叉搜索树是遵守二分搜索法实现的一种数据结构,咱们先来看看这种数据结构为何不适合用来做索引结构呢?
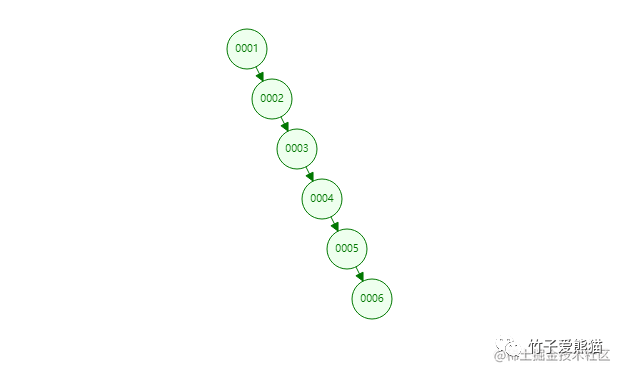 二叉搜索树
二叉搜索树
上图是我提前构建的二叉树,其中存在6个节点,按咱们前面给出的案例,「黑熊」这条数据位于表的第五行,那假设以二叉树作为索引结构,想要定位到第五行数据,需要经过几次磁盘IO呢?来看动图演示效果:
 二叉树查找动画
二叉树查找动画
从动画中可以明显看到,想要查到第五条数据,需要经过五次查询,由于树结构在磁盘中存储的位置也不连续,因此无法利用局部性原理读取后续的节点,所以最终需要发生五次磁盘IO才能读取到数据。
- • 二叉树不适合作为索引结构的原因:
- • ①如果索引的字段值是按顺序增长的,二叉树会转变为链表结构。
- • ②由于结构转变成了链表结构,因此检索的过程和全表扫描无异。
- • ③由于树结构在磁盘中,各节点的数据并不连续,因此无法利用局部性原理。
1.3、索引为何不选择红黑树?
上面简单的分析二叉树后,很明显的可以看出,二叉树并不适合作为索引结构,那接下来再看看大名鼎鼎的Red-Black Tree红黑树:
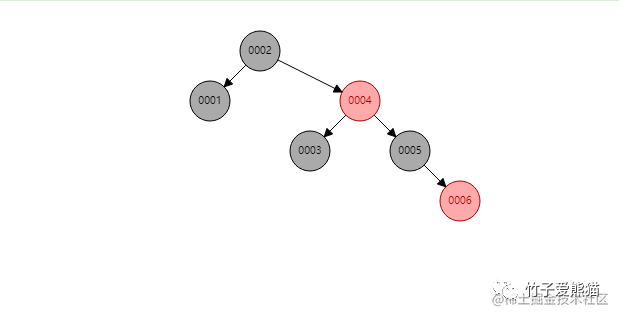 红黑树
红黑树
同样提前先构建好了六个节点,相较于之前的二叉树,红黑树则进一步做了优化,它是一种自适应的平衡树,会根据插入的节点数量以及节点信息,自动调整树结构来维持平衡,从树的高度上来看,明显比之前的6层减少到了4层,那此时再来看看检索的过程:
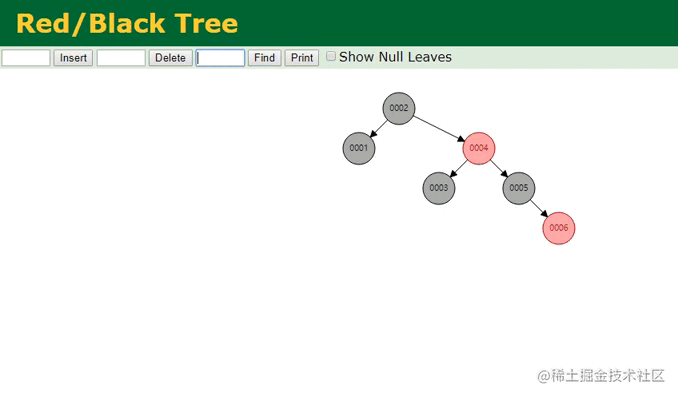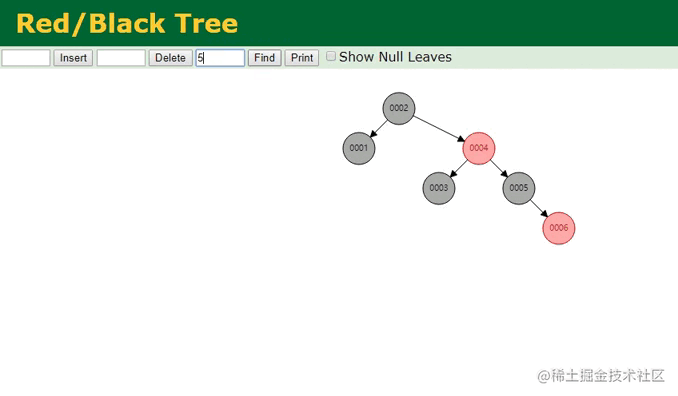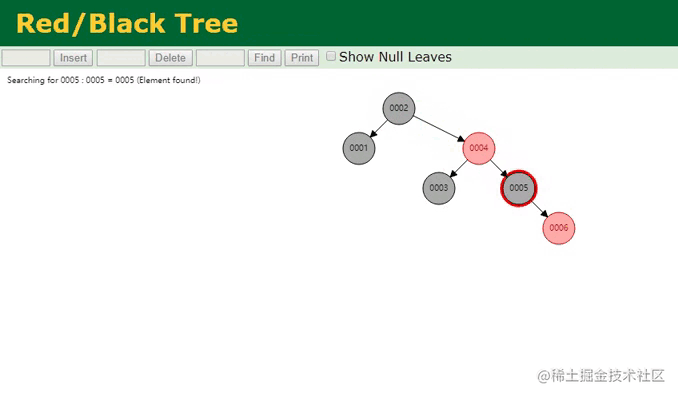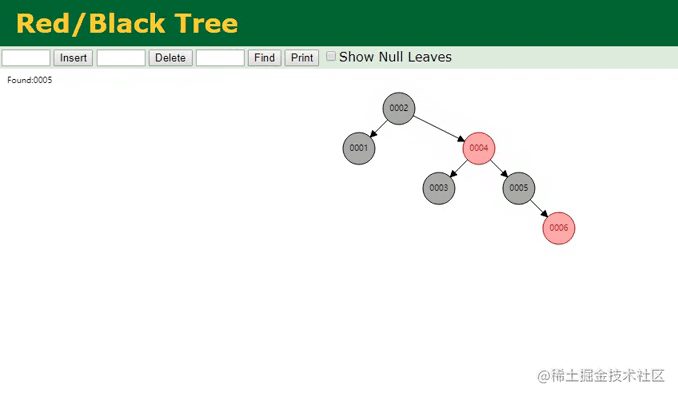 红黑树查找动画
红黑树查找动画
由于树变矮了,其效果也很明显,在红黑树中只需要经过三次查找,就能定位到第五个节点,似乎看起来还不错对嘛?但MySQL为啥不用这颗名声远扬的红黑树呢?
- • 红黑树不适合作为索引结构的原因:
- • ①虽然对比二叉树来说,树高有所降低,但数据量一大时,依旧会有很大的高度。
- • ②每个节点中只存储一个数据,节点之间还是不连续的,依旧无法利用局部性原理。
对于上述两个缺点罗列的很明白,其本质上的原因就在于:单个节点中只能存储一个数据,因此一方面树会随着数据量增长越来越高,第二方面也无法利用局部性原理减少磁盘IO。
那是不是把红黑树稍微改造一下,让其单个节点中可存储多个数据是不是可以了呢?
B树就是这样干的,一起来看看。
1.4、索引为何不选择B-Tree?
在前面提到过,将红黑树稍微改造一下,让其单节点可容纳多个数据,就能在很大程度上改善其性能,事实上B-Tree就是这么做的,B树可以理解成红黑树的一个变种,如下:
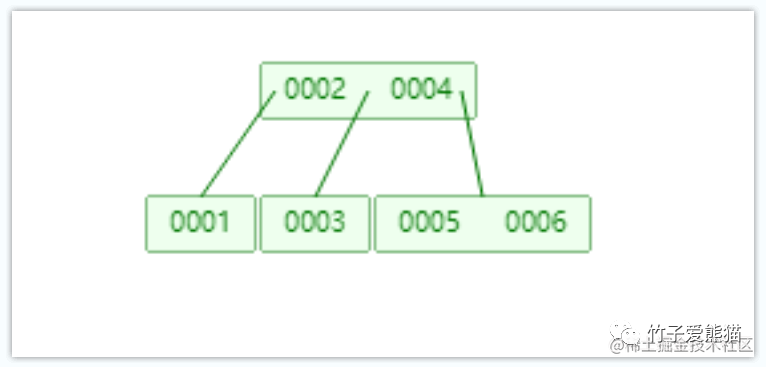 B树
B树
此时给B树结构也添加了6个节点,此时观测上述结构,一方面树仅有2层,同时一个节点中也存储了多个数据,再来看看B树的查找过程:
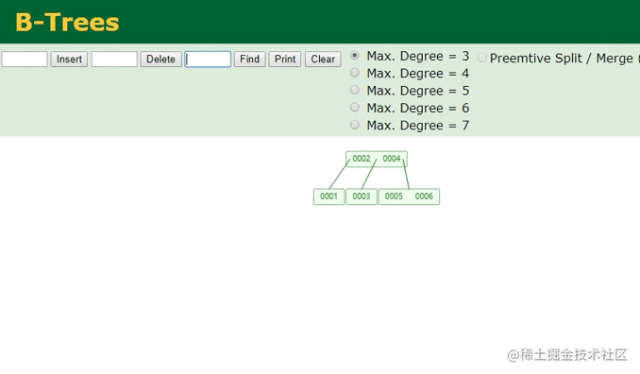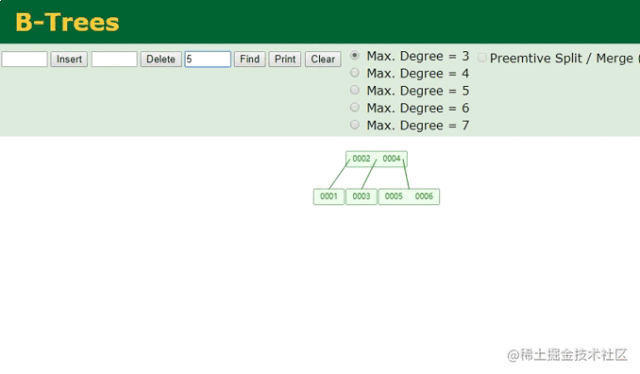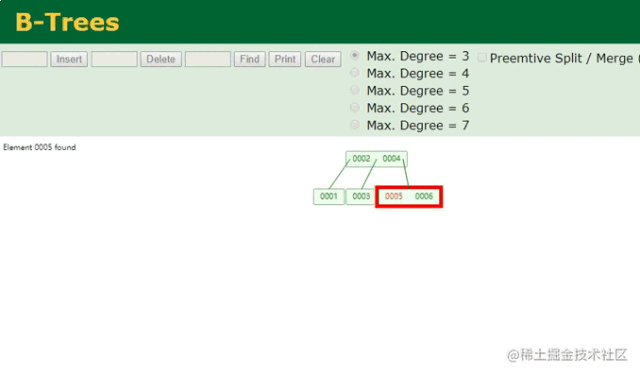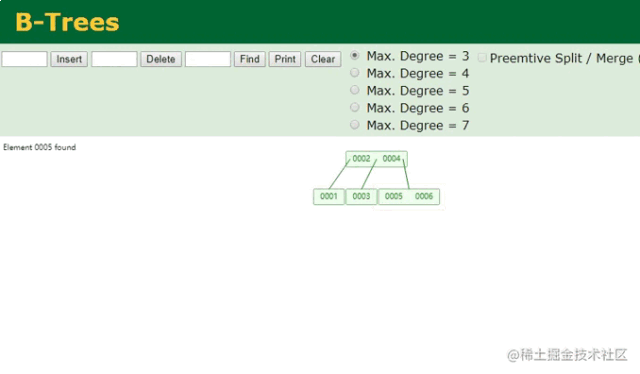 B树查找动画
B树查找动画
哦吼吼吼,完美完美,两次就查到了数据,同时一个节点中还能存储多个数据,可充分利用局部性原理,让一次磁盘IO读取多个数据!!但有人可能会问,上面的一个节点也只存两个数据啊,没太大的区别似乎。但你要这么想就错了,B树中一个节点可容纳的数据个数,可以自己控制的,例如:

在这里将Max.Degree更改后,B树单节点的容量也会随之更改,从上图中可清晰看到一个节点同时将6个数据全存储进去了,这也就代表着只需要一次磁盘IO就能检索出5这个数据,是不是很完美?先别急着下定律,毕竟咱们目前是站在索引设计者的角度来看待问题的,此时虽然看起来很美好了,但想一个问题:
MySQL由于是关系型数据库,因此经常会碰到范围查询的需求,举例:
SELECT * FROM zz_user WHERE ID BETWEEN 2 AND 5;
比如上述这条SQL语句,需要查询表中ID在2~5的所有数据,那也就代表着需要查四条数据,在这里因为2~5在同一个节点中,因此仅触发一次IO就可拿到数据,但实际业务中往往不会有这么小的范围查询,假设此时是查ID=2~1000之间的数据呢?这么多数据定然不会在一个节点中,因此这里又会触发多次磁盘IO!
- • B树不适合作为索引结构的原因:
- • 虽然对比之前的红黑树更矮,检索数据更快,也能够充分利用局部性原理减少IO次数,但对于大范围查询的需求,依旧需要通过多次磁盘IO来检索数据。
1.5、索引为何要选择B+Tree?
上面聊到的B-Tree相对来说已经较为完美了,但最后也谈到:它并不适合用于范围查询,但这种查询需求在关系型数据库中又很常见,那这里怎么优化呢?一起来看看B+Tree:
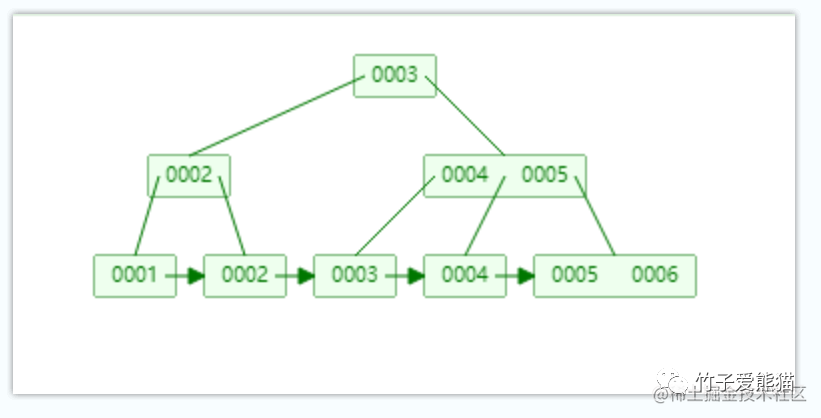 B+树
B+树
相较于B树而言,B+树的结构又出现了新的变化,一方面节点分为了叶节点和叶子节点两类,这里先有这两个概念即可,后续介绍这两类节点在索引中的作用。B+树中除开节点分为两类外,还有一个最大的变化就是:最下面的一排节点之间,都存在一个单向指针,指向下一个节点所在的位置,这也是B+树对B树的最大改造点:
前面讲过,由于
B树不适合于大范围查询操作,因此B+树中多了个指针,当需要做范围查询时,只需要定位第一个节点,然后就可以直接根据各节点之间的指针,获取到对应范围之内的所有节点,也就是只需要发生一次IO,就能够确定所查范围之内的所有数据位置。
OK~,到现在为止,B+树以接近完美的形式解决之前其他数据结构中的所有问题,因此B+Tree正式成为了MySQL默认的索引结构,因此对于MySQL索引为何要选择B+Tree的原因大家应该也懂了,MySQL的设计者在研发时,也绝对是对比了多种数据结构后,逐步推导其缺陷,然后采用更好的数据结构代替,从而最终推导出了B+Tree。
OK~,接下来再说一下前面抛出的一个问题:叶节点和叶子节点在
MySQL索引中的作用。
要弄明白这个问题,首先得搞清楚叶节点和叶子节点是什么?其实很简单:
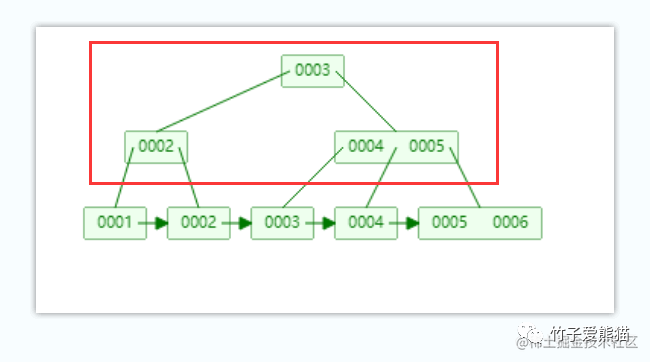 B+树-叶节点
B+树-叶节点
B+Tree上面这些节点则被称为叶节点,在MySQL中不会存储数据,仅存储指向叶子节点的指针,这样做的好处在于能够让一个叶节点中存储更多的元素,从而确保树的高度不会由于数据增长而变得很高。
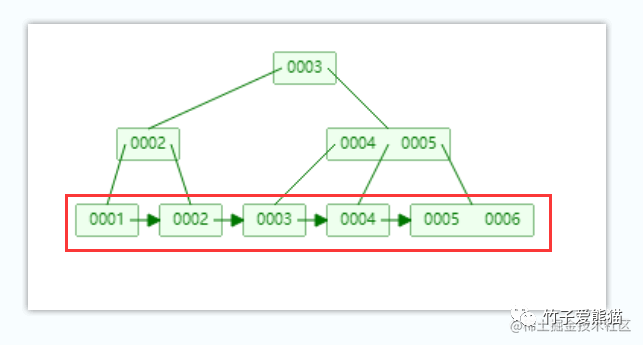 B+树-叶子节点
B+树-叶子节点
同时,B+Tree最下面这排节点则被称为叶子节点,这些节点中会存储实际的数据,例如聚簇索引中就直接存储对应的行数据,非聚簇索引中则存储指向主键/聚簇索引的字段值。同时每个叶子节点之间都有一根单向指针指向下一个节点,从而使得最下面的一排叶子节点之间又形成了一个单向链表结构,方便范围取值。
1.5.1、B+Tree结构为何会存在叶节点呢?
其实在之前的数据结构中,从来没有叶节点的这个概念出现,每个节点信息在整棵树结构中只会存储一份,但为什么B+树中会用叶节点,同时冗余一份节点信息呢?因为你从前面的B+Tree结构中,也能明显观测到2、3、4、5节点都会出现了两次。在这里如果想要搞明白为什么要冗余节点,你得想明白一个问题:
能不能将所有的索引数据、表数据全部放入到一个节点中存储呢?这样树的高度永远为
1呀,是不是只需要经过一次磁盘IO啊?
其实乍一听似乎有道理,实则是行不通的,因为一次磁盘IO读取的数据量是有限制的,如果将所有的数据全放入到一个节点中存储,那一次磁盘IO只能读取节点的一部分数据,将整个节点读完,本质上就和之前走一次全表没区别了。
理解这个点之后,再来看看抛出的问题:
B+Tree为何会有叶节点冗余数据呢?
因为B+Tree的每个节点大小会有限制,所以如果将数据存储在叶节点上,会导致单个树节点存的索引键很少。但如果树的叶节点不存实际的行数据,就代表单个节点可以存更多的索引键,单个节点存的越多也就代表着树的高度会越小,树的高度越小就等价于查询时会发生的磁盘IO次数越少,IO次数越少就相当于数据检索速度会更快,到这里相信大家应该能明白为什么会有叶节点冗余索引键了。
但索引中除开索引键外,也必须要存数据,如果不存数据索引就失去了意义,因此
B+tree最下面一排的叶子节点,其中就会存储对应的索引键与行数据/聚簇索引字段值。
一句话来概述,B+Tree的叶节点仅是作为一个“过渡者”的角色,主要是为了提升索引效率的,实际的数据会保存在最下面的叶子节点中,叶节点中仅有一个指针指向罢了。
1.5.2、千万级别的表B+Tree会有多高?
搞清楚B+Tree的一些疑惑后,此时来倒推一个问题,MySQL中一张千万级别的数据表,如果基于自增ID的主键字段建立B+树索引,那此时树会有多高呢?有人或许会认为,虽然B+Tree结构很优异,但千万级别的表至少有1000W条数据,再怎么样应该也有几十、几百的树高吧?但实际上答案会让你大吃一惊。
想要科学的弄懂这个问题,那必须建立在实际的依据上来计算,想要计算出树高,首先得有三个值:
①索引字段值的大小。
②MySQL中B+Tree单个节点的大小。
③MySQL中单个指针的大小。
如何计算索引字段值的大小呢?
这点要依据字段所使用的数据类型来决定。假设此时表的自增ID,创建表时使用的int类型,int类型在计算机中占4Bytes,那此时基于ID字段建立主键索引时,B+Tree每个节点的索引键大小就为4Bytes。
如何得知MySQL中B+树单个节点的大小呢?
对于索引单个节点的容量是多少呢?在MySQL中默认使用引擎的一页大小作为单节点的容量,假设此时表的存储引擎为InnoDB,就可以通过下述这条命令查询:
SHOW*GLOBAL*STATUS*LIKE*"Innodb_page_size";
+------------------+-------+
|*Variable_name****|*Value*|
+------------------+-------+
|*Innodb_page_size*|*16384*|
+------------------+-------+
从上述查询结果来看,InnoDB引擎的一页大小为16384Bytes,也就是16KB,此时也就代表着B+Tree的每个节点容量为16KB。
MySQL中的指针是多大呢?
一般来说,操作系统的指针为了方便寻址,一般都与当前的操作系统位数对应,例如32位的系统,指针就是32bit/4Bytes,64位的操作系统指针则为64bit/8Bytes,但由于64bit的指针寻址范围太大,目前的计算机根本用不上这么大的寻址范围,因此在MySQL-InnoDB引擎的源码中,单个指针被缩小到6Bytes大小。
千万级别的索引树高计算
从上述三条可得知:单个索引节点容量为16KB,主键字段值为4B,指针大小为6B,一个完整的索引信息是由主键字段值+指针组成的,也就是4+6=10B,那此时先来计算一下单个节点中可存储多少个索引信息呢?
16KB / 10B ≈ 1638个。
那此时来计算一下,对于一颗高度为2的B+树,根节点可存储1638个叶子节点指针,也就代表着B+Tree的第二层有1638个叶子节点,因为叶子节点要存储实际的行数据,假设表中每行数据为1KB,这也就是代表着一个叶子节点中可存储16条行数据,那么一颗高度为2的B+树可存储的索引信息为:1638 * 16 = 26208条数据。
再来算算树高为
3的B+树可以存多少呢?因为最下面一排才是叶子节点,此时树高为3,也就代表着中间一排是叶节点,只存储指针并不存储数据,而每个节点可容纳1638个索引键+指针信息,因此计算过程是:1638 * 1638 * 16 = 42928704条。
是不是很令你惊讶?树高为3的B+Tree,竟然可以存储四千多万条数据,也就代表着千万级别的表,走索引查询的情况下,大致只需要发生三次磁盘IO即可获取数据。
当然,上述的这个数据是基于主键为
int类型、表的一行数据为1KB来计算的,实际情况中会不一样,因为主键有可能是bigint类型或其他类型,而一行数据也可能不仅仅只有1KB。因此对于一张实际的千万级别表,它的主键索引实际树高有多少,你结合主键的数据类型以及一行数据的大小,也可以计算出来,它同时不会太高。
对实际的千万表索引树高感兴趣的,我提供一个计算公式:索引键大小=索引字段类型所占的空间、一行表数据大小=所有表字段的类型+隐藏字段(20Bytes)所占大小总和,得到这两个值之后,再套入前面的例子中既可得知。
看到这里,对于索引凭啥那么快?为啥能够提升查询性能?相信大家也有了答案,毕竟索引树高才是个位数,发生的磁盘IO次数也那么少,检索数据的速度不快才来了个鬼~
不过B+Tree中的每个索引页中,还会存储页头(页号、指针、伪记录等)、页目录、页尾等信息,大概一共占用128Bytes左右,因此想要真正的计算出来接近实际情况的索引树高,还需要把这点考虑在内~
1.5.3、MySQL索引底层的真正结构
以为B+Tree就是索引的终点了嘛?实则不然,MySQL的追求可不止于此,虽然B+Tree已经特别特别优秀了,但B+Tree的叶子节点之间是单向指针组成的链表结构,这对于倒排序查询时,显然并不友好,因为只有单向指针,那么只能先正序获取数据后再倒排一次,因此MySQL真正的索引结构还对B+Tree做了变种设计!
啥意思呢?也就是
MySQL在设计索引结构时,对于原始的B+Tree又一次做了改造,叶子节点之间除开一根单向的指针之外,又多新增了一根指针,指向前面一个叶子节点,也就是MySQL索引底层的结构,实际是B+Tree的变种,叶子节点之间是互存指针的,所有叶子节点是一个双向链表结构。
这样做的好处在于:即可以快速按正序进行范围查询,而可以快速按倒序进行范围操作,在某些业务场景下又能进一步提升整体性能!
1.5.4、前缀索引为何能提升索引性能?
这个问题是在之前的《索引初识篇》中抛出的问题,到这里答案也就呼之欲出了,因为前缀索引可以选用一个字段的前N个字符来创建索引,相较于使用完整字段值做为索引键,前缀索引的索引键,显然占用的空间更少,一个索引键越小,代表一个B+Tree节点中可以存储更多的索引键,等价于树高会越小,也就代表磁盘IO更少,检索数据时自然效率更高。
二、建立索引时那些不为人知的内幕
弄明白了索引的底层数据结构后,再一起来聊一聊创建索引后会发生什么事情呢?一般我们都会以下述方式创建索引:
--*①通过CREATE语句创建
CREATE*INDEX*indexName*ON*tableName*(columnName(length)*[ASC|DESC]);
--*②通过ALTER语句创建
ALTER*TABLE*tableName*ADD*INDEX*indexName(columnName(length)*[ASC|DESC]);
--*③建表时通过DML语句创建
CREATE*TABLE*tableName(**
**columnName1*INT(8)*NOT*NULL,***
**columnName2*....,
**.....,
**INDEX*[indexName]*(columnName(length))**
);
在咱们通过SQL命令创建索引时,MySQL首先会判断一下当前表的存储引擎,因为在《索引初识篇》中提到过,索引机制本身是由存储引擎层提供实现的,不同的引擎实现的索引也不同,因此创建索引时第一步就会先判断存储引擎,然后根据不同的存储引擎创建索引,这里重点聊一下常用的MyISAM、InnoDB。
2.1、常用存储引擎的数据存储
首先为了能够实际观察到两个引擎之间的区别,分别使用MyISAM、InnoDB两个引擎创建两张表:
--*创建一张使用MyISAM引擎的表:zz_myisam_index
CREATE*TABLE*zz_myisam_index**(
**z_m_id*int(8)*NOT*NULL,
**z_m_name*varchar(255)*NULL*DEFAULT*''
)*
ENGINE*=*MyISAM*
CHARACTER*SET*=*utf8*
COLLATE*=*utf8_general_ci*
ROW_FORMAT*=*Compact;
--*创建一张使用InnoDB引擎的表:zz_innodb_index
CREATE*TABLE*zz_innodb_index**(
**z_i_id*int(8)*NOT*NULL,
**z_i_name*varchar(255)*NULL*DEFAULT*''
)*
ENGINE*=*InnoDB*
CHARACTER*SET*=*utf8*
COLLATE*=*utf8_general_ci*
ROW_FORMAT*=*Compact;
上述过程中创建了两张表:zz_myisam_index、zz_innodb_index,分别使用了不同的引擎,而MySQL中对于所有的数据都会放入到磁盘中存储,因此先来找一下这两张表的本地位置,默认位于C:\ProgramData\MySQL\MySQL Server 5.x\data这个目录中,在这里保存着所有已创建的数据库磁盘文件,首先从这里面找到对应的数据库并进入目录,如下:
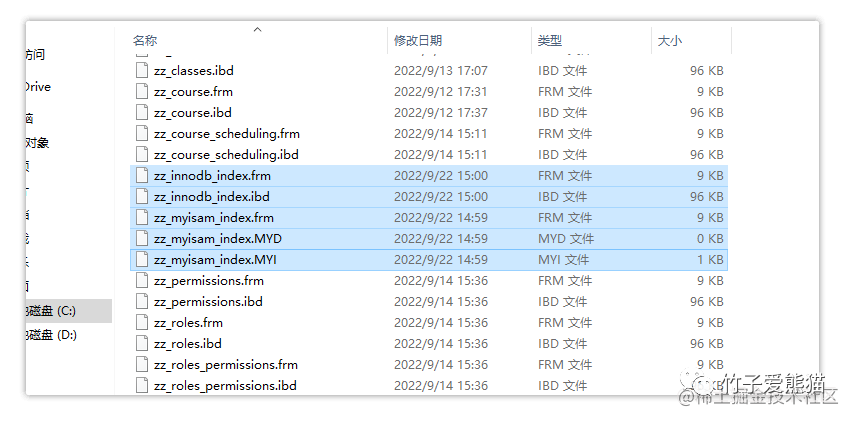 磁盘文件
磁盘文件
对于这几个文件相信大家一定不陌生,毕竟在《MySQL架构篇-文件系统层》中曾介绍过,此时分别来看看使用不同引擎的两张表有何不同。
2.1.1、使用MyISAM引擎的表
zz_myisam_index这张表是使用MyISAM引擎的表,在磁盘中有三个文件:
- • zz_myisam_index.frm:该文件中存储表的结构信息。
- • zz_myisam_index.MYD:该文件中存储表的行数据。
- • zz_myisam_index.MYI:该文件中存储表的索引数据。
也就是说,MyISAM引擎的表数据和索引数据,是分别放在两个不同的磁盘文件中存储的,这也意味着MyISAM引擎并不支持聚簇索引,因为聚簇索引要求表数据和索引数据一起存储在同一块空间,而MyISAM的.MYI索引文件中,存储的是表数据所在的地址指针。
2.1.2、使用InnoDB引擎的表
zz_innodb_index这张表是使用InnoDB引擎的表,在磁盘中仅有两个文件:
- • zz_innodb_index.frm:该文件中存储表的结构信息。
- • zz_innodb_index.ibd:该文件中存储表的行数据和索引数据。
因为InnoDB引擎中,表数据和索引数据都一起放在.ibd文件中,也就代表着索引数据和表数据是处于同一块空间存储的,这符合聚簇索引的定义,因此InnoDB支持聚簇索引。
同时也正由于这个原因,所以如果使用
InnoDB引擎的表未主动创建聚簇索引,它会自动选择表中的主键字段,作为聚簇索引的字段。但如果表中未声明主键字段,那则会选择一个非空唯一索引来作为聚簇索引。但如果表中依旧没有非空的唯一索引,InnoDB则会隐式定义一个主键来作为聚簇索引(这个列在上层是不可见的,是一个按序自增的值)。
OK~,搞明白两种常用引擎的底层存储区别后,接下来再聊聊手动创建索引后究竟会发生什么?
2.2、手动创建索引后发生的事情
当手动创建索引后,MySQL会先看一下当前表的存储引擎是谁,接着会判断一下表中是否存在数据,如果表中没有数据,则直接构建一些索引的信息,例如索引字段是谁、索引键占多少个字节、创建的是啥类型索引、索引的名字、索引归属哪张表、索引的数据结构.....,然后直接写入对应的磁盘文件中,比如MyISAM的表则写入到.MYI文件中,InnoDB引擎的表则写入到.ibd文件中。
上述这个过程,是表数据为空时,创建索引会干的工作,还算比较简单,但当表中有数据时,过程也一样吗?
NO,会多出很多步骤。
当表中有数据时,首先MySQL-Server会先看一下目前要创建什么类型的索引,然后基于索引的类型对索引字段的值,进行相应的处理,比如:
- • 唯一索引:判断索引字段的每个值是否存在重复值,如果有则抛出错误码和信息。
- • 主键索引:判断主键字段的每个值是否重复、是否有空值,有则抛出错误信息。
- • 全文索引:判断索引字段的数据类型是否为文本,对索引字段的值进行分词处理。
- • 前缀索引:对于索引字段的值进行截取工作,选用指定范围的值作为索引键。
- • 联合索引:对于组成联合索引的多个列进行值拼接,组成多列索引键。
- • ........
根据索引类型做了相应处理后,紧接着会再看一下当前索引的数据结构是什么?是B+Tree、Hash亦或是其他结构,然后根据数据结构对索引字段的值进行再次处理,如:
- • B+Tree:对索引字段的值进行排序,按照顺序组成B+树结构。
- • Hash:对索引字段的值进行哈希计算,处理相应的哈希冲突,方便后续查找。
- • .......
到这一步为止,已经根据索引结构,对索引字段的值处理好了,此时就会准备将内存中处理好的字段数据,写入到本地相应的磁盘文件中,但如果此时为InnoDB引擎,那在写入前还会做最后一个判断,也就是判断当前的索引是否为主键/聚簇索引:
- • 如果当前创建索引的字段是主键字段,则在写入时重构.ibd文件中的数据,将索引键和行数据调整到一块区域中存储。
当然,如果这里创建的不是主键/聚簇索引,或者目前是MyISAM引擎,则意味着现在需要创建的是非聚簇索引,因此会先会为每个索引键(索引字段值)寻找相应的行数据,找到之后与索引键关联起来,不过InnoDB、MyISAM引擎两者之间的非聚簇索引也会存在些许差异,所以在这里也会有一点点不同:
- • InnoDB:因为有聚簇索引存在,所以非聚簇索引在与行数据建立关联时,存放的是主键/聚簇索引的字段值。
- • MyISAM:由于表数据在单独的.MYD文件中,因此可以直接以指针的形式关联起来。
也就是说,InnoDB引擎中的非聚簇索引,都是主键/聚簇索引的“附庸”,因此每个索引信息中是以「索引键:聚簇字段值」这种形式关联的。
但MyISAM引擎中由于表数据和索引数据都是分开存储的,所以MyISAM的每个非聚簇索引都是独立的,因此每个索引信息则是以「索引键:行数据的地址指针」这种形式关联。
由于
MyISAM引擎的非聚簇索引,关联的是行数据的指针,而InnoDB引擎关联的是聚簇索引的索引键,所以InnoDB的非聚簇索引在查询时需要回表,再查一次聚簇索引才能得到数据。而MyISAM每个非聚簇索引都能直接获取到行数据的地址,可以直接根据指针获取数据,从整体而言,MyISAM检索数据的效率会比InnoDB快上不少。
到这里,索引键和行数据关联好之后,就会开始根据引擎的不同,将内存中的索引信息分别写入到不同的磁盘文件中。写完完成后,B+Tree的根节点会放到内存中维护,以便于后续索引查询时再次从磁盘读取根节点信息。
到这里为止,大家也应该明白了为什么创建表之后,立马建索引会很快,但当表中有不少数据时创建索引会很慢的原因,就是因为表中有数据时,创建索引要做一系列判断、处理工作。
OK,最后再放上一个聚簇索引和非聚簇索引的结构区别:

在上图中给出了一张用户表,然后基于ID字段建立主键/聚簇索引,基于name字段建立普通/非聚簇索引,最终索引结构如图中所示。
- • 在InnoDB聚簇索引的示意图中,由于不方便画出每行数据,就用row_data代替行数据。
- • 在InnoDB非聚簇索引中,每个索引信息中存储聚簇索引的ID值。
- • MyISAM非聚簇索引中,每个索引信息中则直接存储行数据的指针。
当然,这里也是画出的伪结构,因为不可能按照
MySQL单节点16KB的尺寸1:1还原,毕竟画不下这么大(实际MySQL对于上述这些数据,一个节点就全放下了)。
索引键的大小会随着值长度变化吗?
这个问题很有趣,比如现在基于一个int类型的字段建立了一个索引,但目前的字段值是1,按理来说这个值只占1bits对不对?那在索引键中,或数据库中占多少呢?答案是4Bytes/32bits,这是因为一个int类型在操作系统中就会占用32bit空间,不会根据实际值而减少占用空间。
但大家也都知道,数据库中还有不少文本类型,例如
varchar类型,它是固定的长度吗?并不是,它是一个变长类型,而非一个定长类型,也就是一个varchar字段值,占用的空间会随着实际所存储的数据而变化。
所以对于一个索引键的大小是否会发生变化,这要取决于你是基于什么字段类型建立的索引,如果是定长类型就不会变化,但如果是变长类型就会随之发生改变。
三、索引内部查询与维护的过程
建立索引时会发生的内部过程,上一段落已经阐述明白了,接着再来说说查询SQL执行时,如果选中了索引,索引内部的检索过程是什么样的呢?也包括当写类型的SQL更改表中数据后,MySQL又会如何维护索引的内部结构呢?
当然,在此之前,如若对于
SQL执行前会发生的工作还不了解的,可参考《SQL执行篇》。
3.1、聚簇索引查找数据的过程
在《SQL执行篇》中聊到过,当查询SQL来到MySQL后,经过一系列处理后,最终会来到优化器,此时会由优化器来为SQL语句选择出一个合适的索引,当然,你也可以手动强制指定索引。那当SQL命中索引时,索引内部是如何查找对应的行数据的?
工作线程执行查询SQL时,首先会先看一下当前索引的结构,如果是Hash索引就很简单了,直接对索引字段的值进行哈希计算,然后直接根据哈希值,从索引中找到相应的索引信息,最后获取数据即可。
但如果索引结构是默认的
B+Tree呢?内部又会发生什么工作?
如果当前SQL使用的是主键/聚簇索引,比如:
SELECT***FROM*zz_user*WHERE*ID*=*12;
此时首先会根据条件字段,去内存中找到聚簇索引的根节点,然后根据节点中记录的地址去找次级的叶节点,最后再根据叶节点中的指针地址,找到最下面的叶子节点,从而获取其中的行数据,动画过程如下:
图片地址(过大无法上传):https://p6-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4bf555145bbb4077af7bc27fb557f170~tplv-k3u1fbpfcp-watermark.image? B+树查找动画
B+Tree结构的索引似乎查找过程也并不复杂对不对?但有一个细节点需要注意,B+Tree的单个节点可存储多个数据,也就是当磁盘IO发生后,MySQL一次读取的数据中有多个索引信息,此时MySQL会如果查找单个节点中的索引信息呢?全部判断一次嘛?
其实并不会全部判断一次,因为B+Tree是一种有序的数据结构,小的会放左边,大的会放右边,单个节点中的索引信息,同样遵循这个原理。既然单个节点中的数据也是有序的,所以MySQL同样会采用二分查找法去检索数据。对于单个节点中的索引信息,先从索引中间开始查询,然后判断一下当前SQL中ID=12这个条件,是大于还是小于最中间的索引键,小于则去节点左边取中间的索引键继续判断,大于则去右边.....,以此类推直至定位到单节点中对应索引键为止。
OK,如果是范围取值,比如取
ID>=2的所有数据,则会先定位到ID=2的索引键,然后通过叶子节点之后的指针,直接将2之后的数据全部取出。
聚簇索引中,定位到了索引键,即代表着取到了数据,毕竟索引和行数据是一起存储的。
3.2、非聚簇索引查找数据的过程
相较于聚簇索引而言,非聚簇索引前面的步骤都是相同的,仅是最后一步有些许不同罢了,非聚簇索引经过一系列查询步骤后,最终会取到一个聚簇索引的字段值,然后再做一次回表查询,也就是再去聚簇索引中查一次才能取到数据。
如果是
MyISAM引擎,则直接根据索引树中记录的指针地址,直接触发磁盘IO再次读取数据即可。
3.3、写SQL执行时索引的维护过程
前面分析了查询SQL执行时,索引查找数据的过程,那当出现增、删、改SQL时呢?索引会怎么维护呢?其实这里也要分索引类型,如果是Hash结构的索引,直接增删改对应的索引键即可,但B+Tree结构的索引,因为要内部节点是有序的,所以需要维护有序性。
也就是代表着,插入、更改、删除数据时,都会对
B+Tree索引造成影响。
但先说清一个误区,表中不同的索引在本地有不同的索引记录,比如ID、Name字段分别建立了两个索引,那么就会有两颗不同的索引树写入到本地磁盘文件中。
3.3.1、插入数据时索引的变化
B+Tree索引是有序的,对于这点在前面已经反复提到了,但如果索引字段是数值类型,例如int、bigint、long等,本身就能区分大小顺序,此时可以直接做排序工作。但如果是基于字符串或其他类型的字段建立索引呢?又该如何排序呀?其实对于这个问题也并不难回答,大家还记得在建库建表时,干的一件事情嘛?
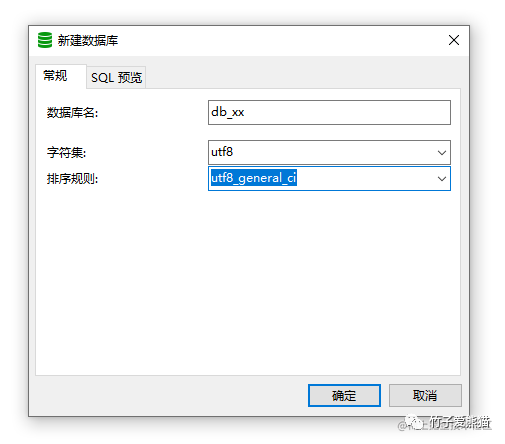 排序规则
排序规则
在创建库表时,咱们通常都会指定一个排序规则,而这个规则就是MySQL对非数值类型字段的排序规则,比如字符串类型的字段,MySQL就会基于该规则对值先做计算处理,然后得到一个数值用于排序。
当然,具体排序处理的过程暂且不去纠结,重点只需搞清楚一点:数据库中任何字段都能排序即可。
OK~,那此时像数据库中插入一条数据时,还是以之前的用户表为例,比如:
INSERT*INTO*zz_user*VALUES(6,"上海市黄浦区xx街道666号","棕熊","男",30);
同样假设用户表上有两个索引,一是基于自增ID建立的主键索引,第二个则是基于姓名字段建立的普通索引。当表中插入这条数据后,索引又会发生什么变化呢?咱们分开聊聊。
主键/聚簇索引的变化
因为主键索引字段,也就是ID字段是顺序递增的,因此只需要在本地索引文件的B+Tree结构中,按照树结构找到最后的位置,将当前插入的ID:6作为索引键,以当前插入的行数据作为索引值,然后插入到最后的节点中即可。如下:
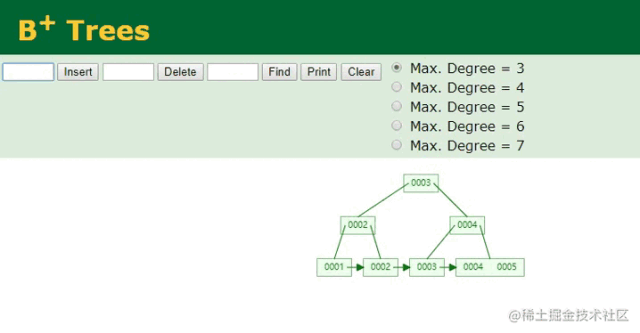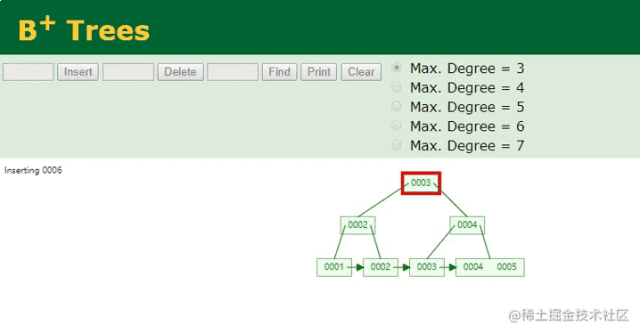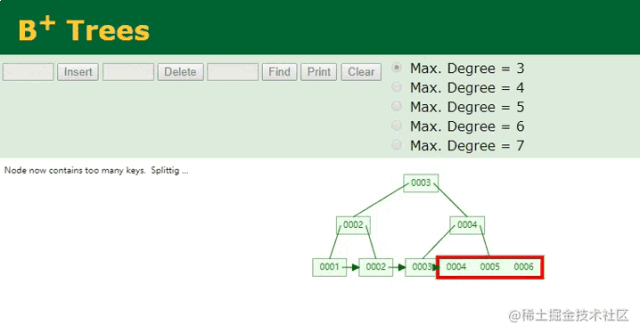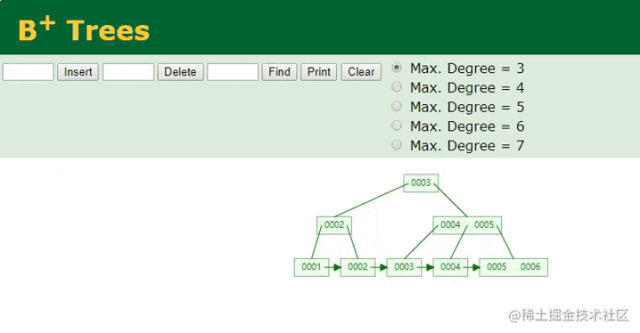 B+树插入ID动画
B+树插入ID动画
按序递增的索引维护,就是这么简单~
普通/非聚簇索引的变化
因为姓名字段本身的数据类型是字符串,与数值型字段天生的有序不同,字符串类型是无序的,因此首先需要根据已经配置好的排序规则,先对插入的name:棕熊这个值进行计算,然后根据计算出的值,决定当前数据在B+Tree中的索引位置,计算好之后再执行插入工作,过程如下:
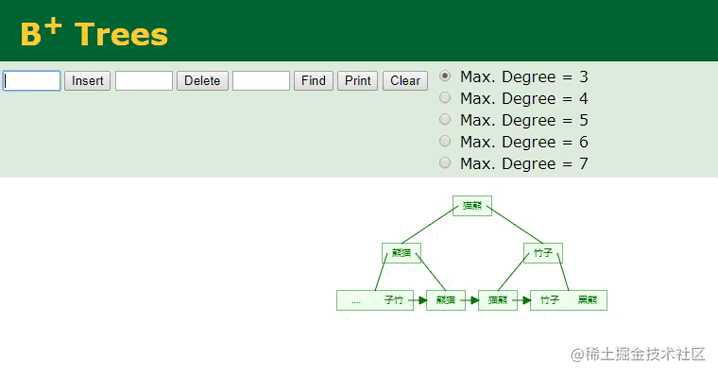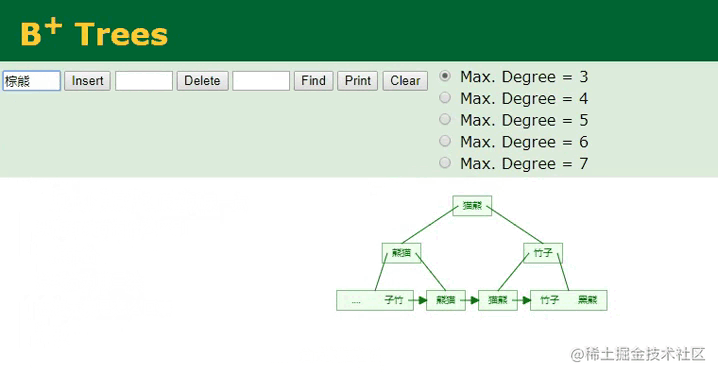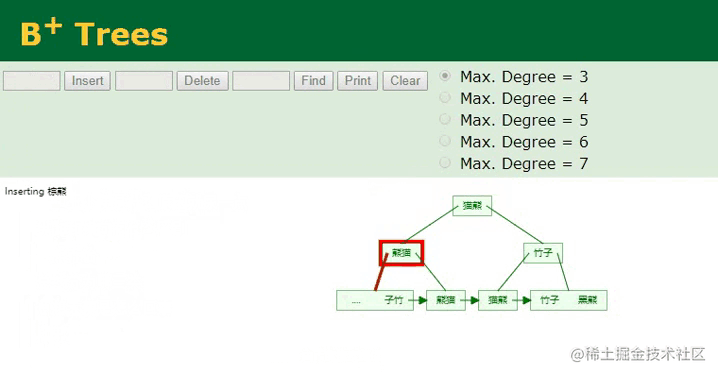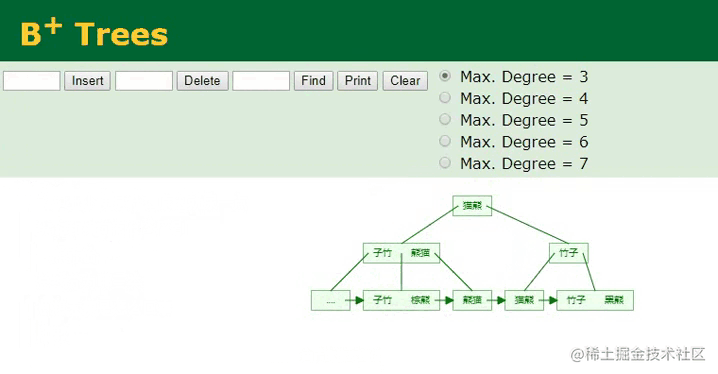 B+树插入字符串
B+树插入字符串
相较于主键字段的顺序ID,插入字符串类型的name值会复杂一些,因为从这里可以明显看到,插入的“棕熊”数据经过计算后,它并不排最后面,而是排中间,所以要将这个值插入到对应的位置,此时树的节点就会发生裂变,后续的所有叶子节点都需要往后移动,这个开销是较大的。
同时,在插入索引信息时,会以“棕熊”作为索引键,以
ID:6作为索引值,然后一同插入,也就是要与行数据建立关联(MyISAM引擎则是行数据的地址指针)。
3.3.2、删除数据时索引的变化
DELETE*FROM*zz_user*WHERE*ID*=*5;
例如上述这条删除语句,当执行后则会先根据ID在索引树中查找索引信息,然后先删除非聚簇索引上的索引信息,紧接着再去聚簇索引上删除主键索引信息和行数据。
过程大致是相同的,就不再制作动图演示其过程了,重点要记住的是:先删非聚簇索引信息,再删聚簇索引的信息,因为聚簇索引上存放着行数据,如果先把聚簇索引删了,就无法找到非聚簇索引上的信息了。
3.3.3、更改数据时索引的变化
UPDATE*zz_user*SET*name*=*"狗熊"*WHERE*ID*=*6;
对于上述这条修改语句,索引维护的过程相信大家自己也能推测出来,毕竟修改的本质就是先删再插入,首先在聚簇索引上查到ID=6这条数据,获取原本的name字段值:“棕熊”,然后以该值去非聚簇索引上找到对应的索引信息,然后先将聚簇索引中的数据行改掉,接着删除次级(非聚簇)索引的信息,最后再插入一个“狗熊”的次级索引信息。
会先更新数据行,再修改次级索引的值,但次级索引的修改是先删后改,而聚簇索引不会删数据,因为聚簇索引上保存着行数据,是直接对行数据进行修改(先读到内存中,改完覆盖原本的数据)。
修改聚簇索引数据行的过程:首先会在聚簇索引上根据ID=6找到对应的行数据,然后将行数据中的name字段更新为“狗熊”。
至此,对于写
SQL执行后,索引的维护过程就做了简单分析,实际上也并不难。
PS:实际索引更新数据时,具体的过程也会复杂一些,会牵扯到锁机制,也包括会判断修改的新值与原值的大小,如果大小相同则直接在原空间做修改(直接插入覆盖),如果不同才会先删再改。
3.4、主键为何推荐使用自增整数ID?
在《索引应用篇-主键的陷阱》中,我曾推荐大家使用自增的整数ID作为主键,而并不是使用随机的UUID这类字符串等类型,这是为何呢?因为观察前面name索引字段的插入过程,能够很明显的观察到一个现象,字符串是无序的,当使用字符串作为主键字段时,在插入数据的时候会频繁破坏原有的树结构,造成树分裂以及后续节点的挪动,一两个条数据插入倒还没关系,但是每一条插入的数据都有可能导致树的结构调整一次,这个过程的开销可想而知.....
但是自增的整数
ID就不会有这个问题,因为插入的ID本身就是按序递增的,因此插入的每一条新数据,都会直接放到B+Tree最后的节点中存储。
同时,除开上述原因外,还有一个原因就是UUID比整数自增ID长,UUID至少占位32字节,但int类型只占4字节,存储一个UUID的空间,可以存8个自增整数ID。也就代表着单个节点中,能存储的自增ID会比UUID多很多,单个节点存储的索引键越多.....(后面这一排就不讲了,前面复述过两次了,大家应该也懂哈~)
四、索引原理篇总结
到目前而言,对于MySQL的索引底层实现,大多数内容就全面讲明白了,从最开始的全表扫描过程,到磁盘IO实现、局部性原理、索引为什么默认是B+Tree结构、建立索引后发生的一系列事情、写类型的SQL对索引的影响.....等一系列内容进行了深入剖析。
看完本章后,对于之前两章中抛出的一些疑惑,你稍加思考后也能彻底明悟,最后再简单说说聚簇索引和非聚簇索引的区别。
聚簇索引和非聚簇索引的根本区别:
- • 聚簇索引中,表数据和索引数据是按照相同顺序存储的,非聚簇索引则不是。
- • 聚簇索引在一张表中是唯一的,只能有一个,非聚簇索引则可以存在多个。
- • 聚簇索引在逻辑+物理上都是连续的,非聚簇索引则仅是逻辑上的连续。
- • 聚簇索引中找到了索引键就找到了行数据,但非聚簇索引还需要做一次回表查询。
InnoDB-非聚簇索引与MyISAM-非聚簇索引的区别:
- • InnoDB中的非聚簇索引是以聚簇索引的索引键,与具体的行数据建立关联关系的。
- • MyISAM中的非聚簇索引是以行数据的地址指针,与具体的行数据建立关联关系的。
一般来说,由于MyISAM引擎中的索引可以根据指针直接获取数据,不需要做二次回表查询,因此从整体查询效率来看,会比InnoDB要快上不少。
其实也不仅仅跟索引有关系,如果考虑的更加深入来说,其实跟锁的粒度以及事务也有关系,但对于具体的原因,在后续的《MySQL锁篇》、《MySQL事务篇》、《MySQL引擎篇》讲完后,大家自然就理解啦~
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: