**作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
*上期文章:Redis:原理速成+项目实战——Redis实战14(BitMap实现用户签到功能)
*订阅专栏:Redis:原理速成+项目实战
希望文章对你们有所帮助
这篇是实战部分的终结篇,其实Redis的核心操作,主要是在实战部分的秒杀业务的,这里面有很多的细节:缓存、分布式锁、异步线程实现秒杀,这里面有很多的细节,可以去看这几篇文章:
Redis:原理速成+项目实战——Redis实战7(优惠券秒杀+细节解决超卖、一人一单问题)
Redis:原理速成+项目实战——Redis实战8(基于Redis的分布式锁及优化)
Redis:原理速成+项目实战——Redis实战9(秒杀优化)
Redis:原理速成+项目实战——Redis实战10(Redis消息队列实现异步秒杀)
本文只是对这个项目再拓展一个基于Redis的功能。
目前为止虽然项目功能上比较完善了,但是用到的Redis基本都是单结点的,多结点的我只是简单演示过demo。
这篇结束后要单独开一个专栏了,实现Redis的高级操作:Redis持久化、Redis主从模式、Redis哨兵机制以及Redis的分片集群
除此之外,还会进行Redis原理的更深入的剖析,将会自己做一点总结,为了将来的面试。
但是想冲好实习的话,除了Redis高级部分以及其底层原理,还非常需要快点将技术栈叠高一点,因此,后面的总结可能进度会很慢了。
Redis企业级项目实战终结篇(HyperLogLog实现UV统计)
- HyperLogLog的用法
- 测试百万数据的统计
HyperLogLog的用法
先搞懂两个概念:
1、 UV:全称UniqueVisitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人1天内同一个用户多次访问该网站,只记录1次;
2、 PV:全称PageView,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV往往用来衡量网站的流量;
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
HyperLogLog是LogLog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储器所有值,具体的原理涉及了很多数学,大家可以自行去了解。
Redis中的HLL是基于String结构实现的,单个HLL的内存永远小于16kb,内存占用非常低,其代价就是测量结果是存在概率性的,有0.8%的误差,这个误差其实也是很小了。如果能忍受这个误差就可以去用。
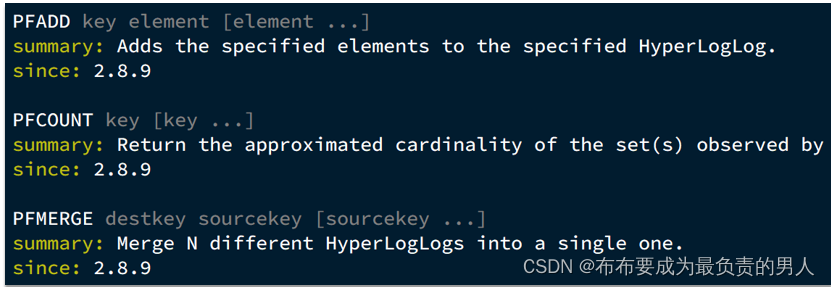
不管用PFADD添加多少个重复元素,用PFCOUNT都不会重复计数,天生就适合用来做UV统计。
测试百万数据的统计
百万用户访问的数据,这可并不好搞,所以直接用单元测试,向HyperLogLog中添加100万条数据,查看内存占用以及统计的效果。
首先利用命令查看当前内存使用情况:

测试类如下:
@Test
void testHyperLogLog(){
String[] values = new String[1000];
int j = 0;
for(int i = 0; i < 1000000 ; ++i){
j = i % 1000;
values[j] = "user_" + i;
if(j == 999){
//发送到Redis
stringRedisTemplate.opsForHyperLogLog().add("hl2", values);
}
}
//统计数量
Long count = stringRedisTemplate.opsForHyperLogLog().size("hl2");
System.out.println("count = " + count);
}
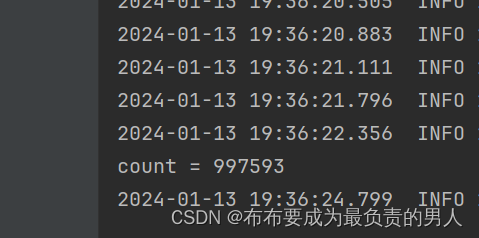
准确率还是很高的。
内存占用情况:

可以发现,这并没有牺牲太多的内存。
这种准确率已经非常的好了,以后要做UV统计,直接把数据往里面塞就可以了,真的遇到很多的用户,要这么去存储用户的时候,也是很容易做出来的。
到这里,Redis的所有实战都已经完成了,目前为止我已经算是完成了一个比较企业级的项目了,虽然这个功能只是做了个功能测试。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: