文章目录
- 生猛干货
- 范式与反范式
-
- 范式
-
- 第一范式
- 第二范式
- 第三范式
- 第二范式 VS 第三范式
- 设计符合 2NF 的表
- 范式优缺点
- 反范式
- 范式 VS 反范式
- MySQL 使用原则和设计规范
-
- 基本设置规则
-
- 线上系统转不区分大小写
- 不建议使用的功能
- 规范命名
- InnoDB 表的注意事项
- 备份表/临时表等常见表的设计规范
- 字段设计要求
-
- int(3) int(5) 区别
- 浮点数与定点数区别
- N 解释
- Char 与 Varchar 类型

生猛干货
带你搞定MySQL实战,轻松对应海量业务处理及高并发需求,从容应对大场面试
范式与反范式
范式
范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。数据库的设计范式是数据库设计所需要满足的规范。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
满足最低要求的叫第一范式,简称 1NF。在第一范式基础上进一步满足一些要求的为第二范式,简称 2NF。其余依此类推。各种范式呈递次规范,越高的范式数据库冗余越小。通常所用到的只是前三个范式,即:第一范式(1NF),第二范式(2NF),第三范式(3NF)。
第一范式
第一范式无重复的列,表中的每一列都是拆分的基本数据项,即列不能够再拆分成其他几列,强调的是列的原子性.。
如果在实际场景中,一个联系人有家庭电话和公司电话,那么以“姓名、性别、电话”为表头的表结构就没有达到 1NF。要符合 1NF 我们只需把电话列拆分,让表头变为姓名、性别、家庭电话、公司电话即可。
第二范式
第二范式属性完全依赖于主键,首先要满足它符合 1NF,另外还需要包含两部分内容
- 表必须有一个主键;
- 没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。即要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
第三范式
第三范式属性不传递依赖于其他非主属性,首先需要满足 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
第二范式 VS 第三范式
- 第二范式:非主键列是否依赖主键(包括一列通过某一列间接依赖主键),要是有依赖关系就是第二范式;
- 第三范式:非主键列是否直接依赖主键,不能是那种通过传递关系的依赖。要是符合这种依赖关系就是第三范式。
通过对前三个范式的了解,我们知道 3NF 是 2NF 的子集,2NF 是 1NF 的子集。
设计符合 2NF 的表
以订单信息表为例,讲述如何设计一个符合 2NF 的表
首先,我们看原始的订单信息表,如下图所示

图中,以订单编号和商品编号作为联合主键,商品名称、单位、价格等信息不与主键相关,只与编号相关,违反了第二范式。 应该对订单信息表进行拆分,商品信息单独一张表,订单项目一张表,如下所示,拆分分成 3 张表。
- 包含客户信息的订单信息表
- 包含商品详情的商品信息表
- 包含订单详情的订单详情表
范式优缺点
【优点】
- 避免数据冗余,减少维护数据完整性的麻烦;
- 减少数据库的空间;
- 数据变更速度快
【缺点】
- 按照范式的规范设计的表,等级越高的范式设计出来的表数量越多。
- 获取数据时,表关联过多,性能较差。
表的数量越多,查询所需要的时间越多。也就是说所用的范式越高,对数据操作的性能越低。
反范式
范式是普适的规则,满足大多数的业务场景的需求。对于一些特殊的业务场景,范式设计的表,无法满足性能的需求。此时,就需要根据业务场景,在范式的基础之上进行灵活设计,也就是反范式设计。
反范式设计主要从三方面考虑:
- 业务场景
- 响应时间
- 字段冗余
反范式设计就是用空间来换取时间,提高业务场景的响应时间,减少多表关联。主要的优点如下
- 允许适当的数据冗余,业务场景中需要的数据几乎都可以在一张表上显示,避免关联
- 可以设计有效的索引
范式 VS 反范式
范式化模型:
- 数据没有冗余,更新容易
- 当表的数量比较多,查询数据需要多表关联时,会导致查询性能低下
反范式化模型:
- 冗余将带来很好的读取性能,因为不需要 join 很多表
- 虽然需要维护冗余数据,但是对磁盘空间的消耗是可以接受的
MySQL 使用原则和设计规范
聊完范式,接下来我们看看 MySQL 使用中的一些使用原则和设计规范。
MySQL 虽然具有很多特性并提供了很多功能,但是有些特性会严重影响它的性能,比如,在数据库里进行计算,写大事务、大 SQL、存储大字段等。
想要发挥 MySQL 的最佳性能,需要遵循 3 个基本使用原则
- 首先是需要让 MySQL 回归存储的基本职能:MySQL 数据库只用于数据的存储,不进行数据的复杂计算,不承载业务逻辑,确保存储和计算分离
- 其次是查询数据时,尽量单表查询,减少跨库查询和多表关联
- 还有就是要杜绝大事务、大 SQL、大批量、大字段等一系列性能杀手。
大事务,运行步骤较多,涉及的表和字段较多,容易造成资源的争抢,甚至形成死锁。一旦事务回滚,会导致资源占用时间过长
- 大 SQL,复杂的 SQL 意味着过多的表的关联,MySQL 数据库处理关联超过 3 张表以上的 SQL 时,占用资源多,性能低下
- 大批量,意味着多条 SQL 一次性执行完成,必须确保进行充分的测试,并且在业务低峰时段或者非业务时段执行
- 大字段,blob、text 等大字段,尽量少用。必须要用时,尽量与主业务表分离,减少对这类字段的检索和更新
基本设置规则
- 必须指定默认存储引擎为 InnoDB,并且禁用 MyISAM 存储引擎,随着 MySQL 8.0 版本的发布,所有的数据字典表都已经转换成了 InnoDB,MyISAM 存储引擎已成为了历史。
- 默认字符集 UTF8mb4,以前版本的 UTF8 是 UTF8mb3,未包含个别特殊字符,新版本的 UTF8mb4 包含所有字符,官方强烈建议使用此字符集。
- 关闭区分大小写功能。设置 lower_case_tables_name=1,即可关闭区分大小写功能,即大写字母 T 和小写字母 t 一样
线上系统转不区分大小写
如何让系统中区分大小写的库表转换为不区分大小写的库表呢?因为要修改底层数据,还是比较麻烦的,操作步骤如下。
1、 MySQLdump导出数据库;
2、 修改参数lower_case_tables_name=1;
3、 导入备份数据时,必须停止数据库,停止业务,影响非常大;
4、 开启per-table表空间,开启后,每张业务表会单独创建一个独立于系统表空间的表空间,便于空间的回收,数据的迁移;
不建议使用的功能
1、 存储过程、触发器、视图、event为了存储计算分离,这类功能尽量在程序中实现这些功能非常不完整,调试、排错、监控都非常困难,相关数据字典也不完善,存在潜在的风险一般在生产数据库中,禁止使用;
2、 lob、text、enum、set这些字段类型,在MySQL数据库的检索性能不高,很难使用索引进行优化如果必须使用这些功能,一般采取特殊的结构设计,或者与程序结合使用其他的字段类型替代比如:set可以使用整型(0,1,2,3)、注释功能和程序的检查功能集合替代;
规范命名
命名规范如下,命名时的字符取值范围为:az,09 和 _(下画线)。
- 所有表名小写,不允许驼峰式命名;
- 允许使用 -(横线)和 (空格);如下图所示,当使用 -(横线),后台默认会转化成 @002d;
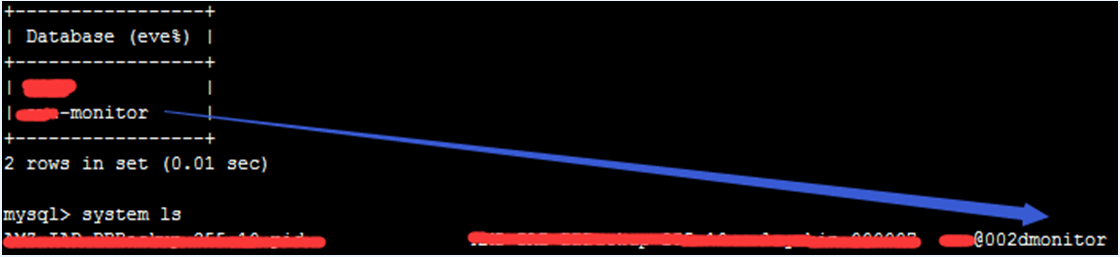
- 不允许使用其他特殊字符作为名称,减少潜在风险。
数据库库名的命名规则必须遵循“见名知意”的原则,即库名规则为“数据库类型代码 + 项目简称 + 识别代码 + 序号”。
表名的命名规则分为:
- 单表仅使用 a~z、_;
- 分表名称为“表名_编号”;
- 业务表名代表用途、内容:子系统简称_业务含义_后缀。
常见业务表类型有:
- 临时表,tmp;
- 备份表,bak;
- 字典表,dic;
- 日志表,log。
字段名精确,遵循“见名知意”的原则,格式:名称_后缀。
- 避免普遍简单、有歧义的名称。
- 用户表中,用户名的字段为 UserName 比 Name 更好。
- 布尔型的字段,以助动词(has/is)开头。
用户是否有留言 hasmessage,用户是否通过检查 ischecked 等。
常见后缀如下:
- 流水号/无意义主键,后缀为 id,比如 task_id;
- 时间,后缀为 time,insert_time。
程序账号与数据库名称保持一致。如果所有的程序账号都是 root@‘%’,密码也一样,很容易错连到其他的数据库,造成误操作。
索引命名格式,主要为了区分哪些对象是索引:
- 前缀_表名(或缩写)_字段名(或缩写);
- 主键必须使用前缀“pk_”;
- UNIQUE 约束必须使用前缀“uk_”;
- 普通索引必须使用前缀“idx_”。
数据库规范库表字段的命名,能够提高数据库的易读性,为数据库表设计打下基础。下面我们具体看看表设计的一些规则。
- 显式指定需要的属性;
创建表时显示指定字符集、存储引擎、注释信息等。
- 不同系统之间,统一规范;
不同表之间的相同字段或者关联字段,字段类型/命名要保持一致;库表字符集和前端程序、中间件必须保持一致的 UTF8mb4。
InnoDB 表的注意事项
1、 主键列,UNSIGNED整数,使用auto_increment;禁止手动更新auto_increment,可以删除;
2、 必须添加comment注释;
3、 必须显示指定的engine;
4、 表必备三字段:id、xxx_create、xxx_modified;
- id 为主键,类型为 unsigned bigint 等数字类型;
- xxx_create、xxx_modified 的类型均为 datetime 类型,分别记录该条数据的创建时间、修改时间。
备份表/临时表等常见表的设计规范
1、 备份表,表名必须添加bak和日期,主要用于系统版本上线时,存储原始数据,上线完成后,必须及时删除;
2、 临时表,用于存储中间业务数据,定期优化,及时降低表碎片;
3、 日志类表,首先考虑不入库,保存成文件,其次如果入库,明确其生命周期,保留业务需求的数据,定期清理;
4、 大字段表,把主键字段和大字段,单独拆分成表,并且保持与主表主键同步,尽量减少大字段的检索和更新;
5、 大表,根据业务需求,从垂直和水平两个维度进行拆分;
垂直拆分:
- 按列关联度
水平拆分:
- 按照时间、地域、范围等;
- 冷热数据(历史数据归档)
字段设计要求
- 根据业务场景需求,选择合适的类型,最短的长度;确保字段的宽度足够用,但也不要过宽。所有字段必须为 NOT NULL,空值则指定 default 值,空值难以优化,查询效率低。比如:人的年龄用 unsigned tinyint(范围 0~255,人的寿命不会超过 255 岁);海龟就必须是 smallint,但如果是太阳的年龄,就必须是 int;如果是所有恒星的年龄都加起来,那么就必须使用 bigint。
- 表字段数少而精,尽量不加冗余列。
- 单实例表个数必须控制在 2000 个以内。
- 单表分表个数必须控制在 1024 个以内。
- 单表字段数上限控制在 20~50 个
【禁用ENUM、SET 类型】
- 兼容性不好,性能差。
解决方案:使用 TINYINT,在 COMMENT 信息中标明被枚举的含义。is_disable TINYINT UNSIGNED DEFAULT ‘0’ COMMENT '0:启用 1:禁用 2:异常’。
【禁用列为 NULL 】
- MySQL 难以优化 NULL 列;
- NULL 列加索引,需要额外空间;
- 含 NULL 复合索引无效。
解决方案:在列上添加 NOT NULL DEFAULT 缺省值
【禁止VARBINARY、BLOB 存储图片、文件等】
- 禁止在数据库中存储大文件,例如照片,可以将大文件存储在对象存储系统中,数据库中存储路径。
不建议使用 TEXT/BLOB:
- 处理性能差;
- 行长度变长;
- 全表扫描代价大。
解决方案:拆分成单独的表
存储字节越小,占用空间越小。尽量选择合适的整型,如下图所示。
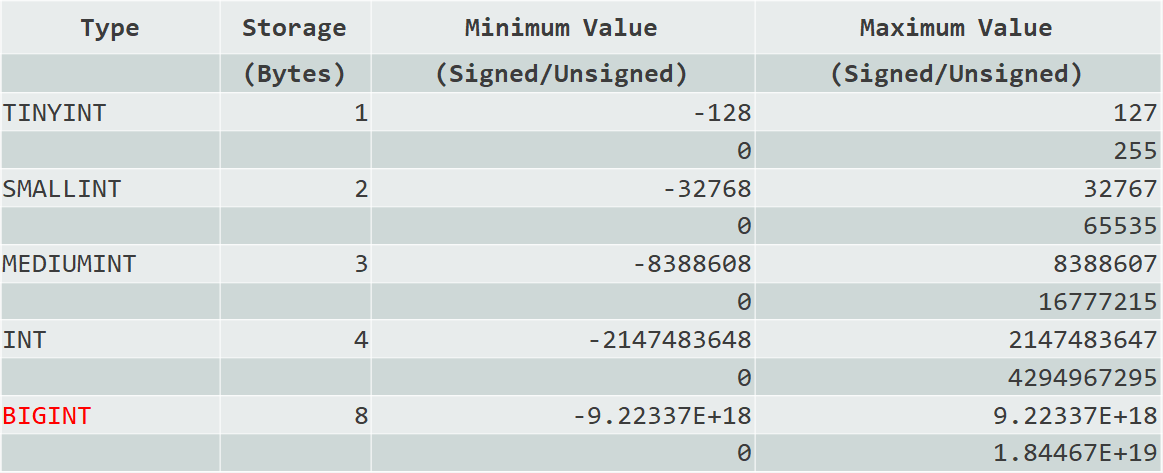
- 主键列,无负数,建议使用 INT UNSIGNED 或者 BIGINT UNSIGNED;预估字段数字取值会超过 42 亿,使用 BIGINT 类型。
- 短数据使用 TINYINT 或 SMALLINT,比如:人类年龄,城市代码。
- 使用 UNSIGNED 存储非负数值,扩大正数的范围。
int(3) int(5) 区别
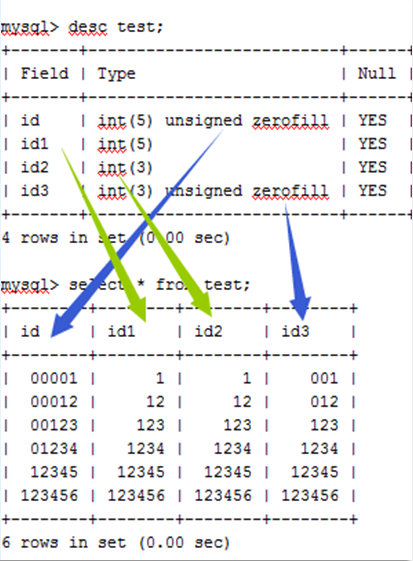
- 正常显示没有区别。
- 3 和 5 仅是最小显示宽度而已。
- 有 zerofill 等扩展属性时则显示有区别。
浮点数与定点数区别
浮点数与定点数区别,如下图所示。
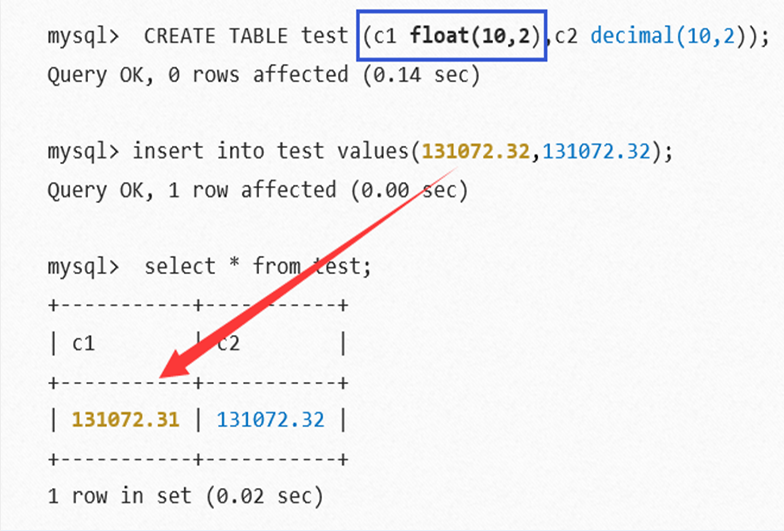
1、 浮点数:float、double(或real);
2、 定点数:decimal(或numberic);
从上图中可以观察到:
- 浮点数存在误差问题;
- 尽量避免进行浮点数比较;
- 对货币等对精度敏感的数据,应该使用定点数
N 解释
字符集都为 UTF8mb4,中文存储占三个字节,而数据或字母,则只占一个字节。
下面看一下字符类型中 N 的解释。
- CHAR(N) 和 VARCHAR(N) 的长度 N,不是字节数,是字符数。
- username 列可以存多少个汉字,占用多少个字节
- username 最多能存储 40 个字符,占用 120 个字节
Char 与 Varchar 类型
存储字符串长度相同的全部使用 Char 类型;字符长度不相同的使用 Varchar 类型,不预先分配存储空间,长度不要超过 255。
Char 和 Varchar 占用空间的对比,如下图所示。
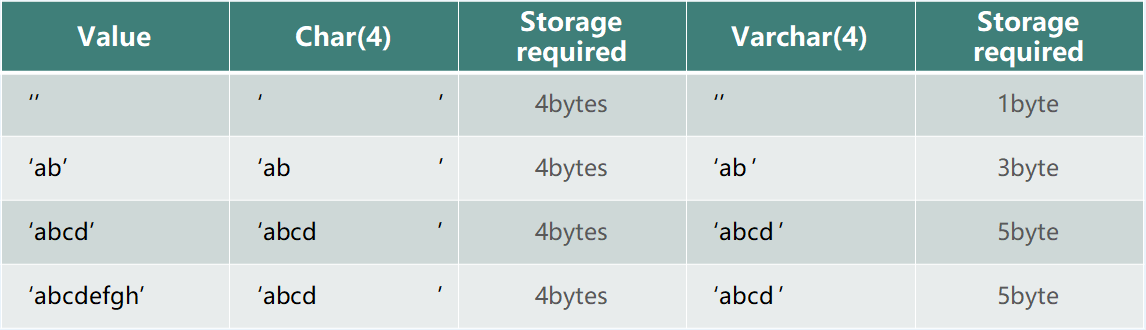
Varchar 值存储为 1 字节或 2 字节长度前缀加数据
如果值不超过 255 个字节,则列使用一个字节长度
如果值可能需要超过 255 个字节,则列使用两个字节长度
为什么超过 255 个字节时,必须使用两个字节长度。
- 2的8次方=256,1 个字节是 8 位;
- 2的16次方=65535,2 个字节是 16 位。

版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: