文章目录
- 生猛干货
- Pre
- 锁的分类
- InnoDB 中的锁
-
- 行锁
- InnoDB 行锁的三种算法实现
-
- Record Lock 锁
- Gap Lock 锁
- Next-key Lock 锁
- 表锁
-
- 表锁的分类 IS | IX | AUTO-INC Locks
- InnoDB 自增锁
- InnoDB 锁关系矩阵
- InnoDB死锁问题排查思路
-
- 基于资源争用导致死锁的情况
- Metadata lock(即元数据锁)导致的死锁的情况
- 开发建议
- InnoDB 加锁行为验证
-
- 主键 + RR
- 唯一键 + RR
- 非唯一键 + RR
- 无索引 + RR
- 搞定MySQL

生猛干货
带你搞定MySQL实战,轻松对应海量业务处理及高并发需求,从容应对大场面试
Pre
锁的分类
在MySQL 中有三种级别的锁:页级锁、表级锁、行级锁
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 会发生在:MyISAM、memory、InnoDB、BDB 等存储引擎中
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。会发生在:InnoDB 存储引擎
- 页级锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。会发生在:BDB 存储引擎
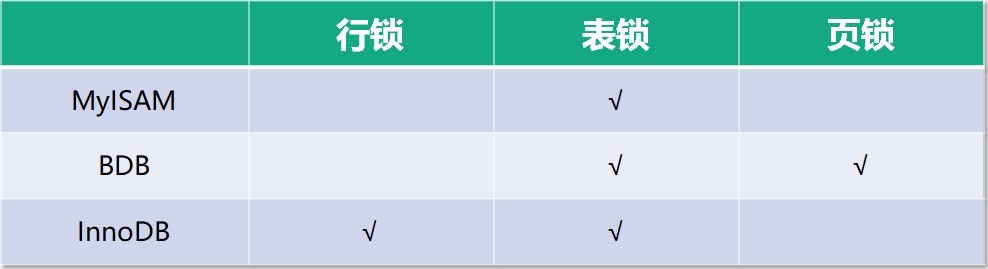
三种级别的锁分别对应存储引擎关系如上图。
Note:MySQL 中的表锁包括读锁和写锁
InnoDB 中的锁
在MySQL InnoDB 存储引擎中,锁分为行锁和表锁。
行锁
其中行锁包括两种锁
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
InnoDB 行锁的三种算法实现
InnoDB 行锁是通过对索引数据页上的记录(record)加锁实现的。主要实现算法有 3 种:Record Lock、Gap Lock 和 Next-key Lock。
Record Lock 锁
- Record Lock 锁:单个行记录的锁(锁数据,不锁 Gap)。
Gap Lock 锁
- Gap Lock 锁:间隙锁,锁定一个范围,不包括记录本身(不锁数据,仅仅锁数据前面的Gap)。
Next-key Lock 锁
- Next-key Lock 锁:同时锁住数据,并且锁住数据前面的 Gap。
表锁
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
表锁的分类 IS | IX | AUTO-INC Locks
表锁又分为三种
- 意向共享锁(IS):事务计划给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁
- 自增锁(AUTO-INC Locks):特殊表锁,自增长计数器通过该“锁”来获得子增长计数器最大的计数值
在加行锁之前必须先获得表级意向锁,否则等待 innodb_lock_wait_timeout 超时后根据innodb_rollback_on_timeout 决定是否回滚事务。
InnoDB 自增锁
在MySQL InnoDB 存储引擎中,我们在设计表结构的时候,通常会建议添加一列作为自增主键。
这里就会涉及一个特殊的锁:自增锁(即:AUTO-INC Locks),它属于表锁的一种,在 INSERT 结束后立即释放。
我们可以执行 show engine innodb status\G 来查看自增锁的状态信息。
在自增锁的使用过程中,有一个核心参数,需要关注,即 innodb_autoinc_lock_mode,它有0、1、2 三个值。保持默认值即可。

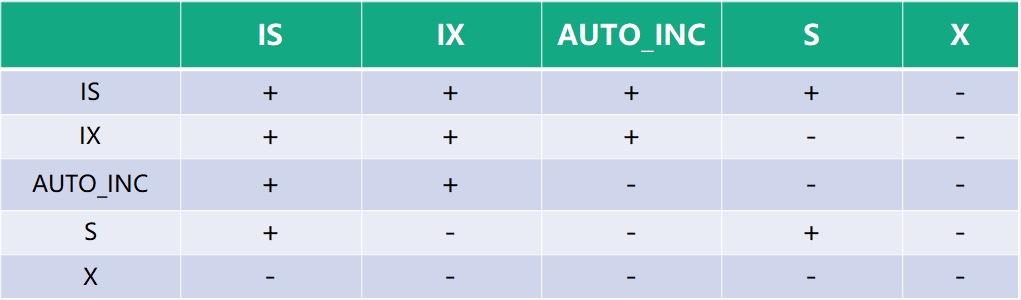
InnoDB 锁关系矩阵
+ 表示兼容,- 表示不兼容
InnoDB死锁问题排查思路
在MySQL 中死锁不会发生在 MyISAM 存储引擎中,但会发生在 InnoDB 存储引擎中,因为 InnoDB 是逐行加锁的,极容易产生死锁。那么死锁产生的四个条件是什么呢?
- 互斥条件:一个资源每次只能被一个进程使用;
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
- 不剥夺条件:进程已获得的资源,在没使用完之前,不能强行剥夺;
- 循环等待条件:多个进程之间形成的一种互相循环等待资源的关系。
在发生死锁时,InnoDB 存储引擎会自动检测,并且会自动回滚代价较小的事务来解决死锁问题。但很多时候一旦发生死锁,InnoDB 存储引擎的处理的效率是很低下的或者有时候根本解决不了问题,需要人为手动去解决。
排查InnoDB 锁问题通常有 2 种方法。
- 打开 innodb_lock_monitor 表,注意使用后记得关闭,否则会影响性能。
- 在 MySQL 5.5 版本之后,可以通过查看 information_schema 库下面的 innodb_locks、innodb_lock_waits、innodb_trx 三个视图排查 InnoDB 的锁问题
基于资源争用导致死锁的情况
【基于资源争用导致死锁的情况】

session1 首先拿到 id=1 的锁,session2 同期拿到了 id=5 的锁后,两者分别想拿到对方持有的锁,于是产生死锁。
Metadata lock(即元数据锁)导致的死锁的情况
【Metadata lock(即元数据锁)导致的死锁的情况】

session1 和 session2 都在抢占 id=1 和 id=6 的元数据的资源,产生死锁。
查看MySQL 数据库中死锁的相关信息,可以执行 show engine innodb status\G 来进行查看,重点关注 “LATEST DETECTED DEADLOCK” 部分。
开发建议
- 更新 SQL 的 where 条件时尽量用索引
- 加锁索引准确,缩小锁定范围
- 减少范围更新,尤其非主键/非唯一索引上的范围更新
- 控制事务大小,减少锁定数据量和锁定时间长度 (innodb_row_lock_time_avg)
- 加锁顺序一致,尽可能一次性锁定所有所需的数据行
更多案例参考:MySQL - 锁等待及死锁初探
InnoDB 加锁行为验证
下面举一些例子分析 InnoDB 不同索引的加锁行为。分析锁时需要跟隔离级别联系起来,我们以 RR 为例,主要是从四个场景分析。
主键 + RR
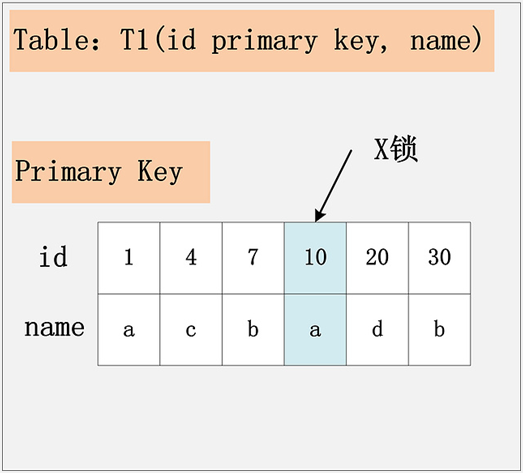
假设条件是:
- update t1 set name=‘XX’ where id=10
- id 为主键索引。
加锁行为:仅在 id=10 的主键索引记录上加 X锁。
唯一键 + RR
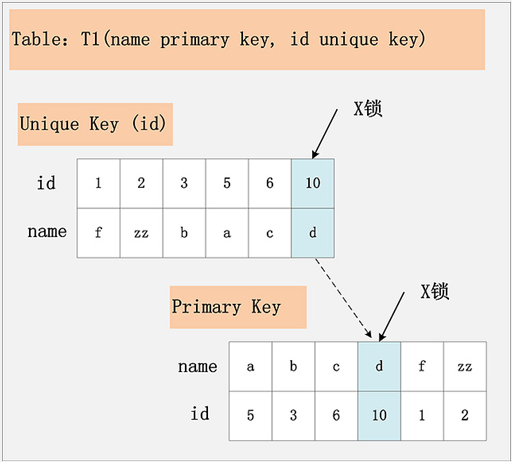
假设条件是:
- update t1 set name=‘XX’ where id=10
- id 为唯一索引。
加锁行为:
- 先在唯一索引 id 上加 id=10 的 X 锁。
- 再在 id=10 的主键索引记录上加 X 锁,若 id=10 记录不存在,那么加间隙锁。
非唯一键 + RR
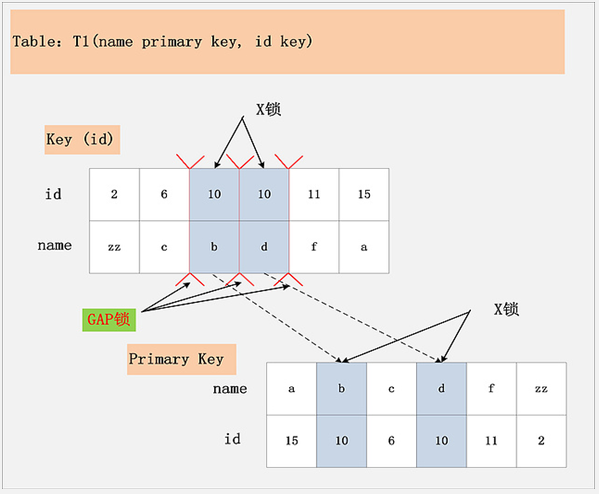
假设条件是:
- update t1 set name=‘XX’ where id=10
- id 为非唯一索引
加锁行为:
- 先通过 id=10 在 key(id) 上定位到第一个满足的记录,对该记录加 X 锁,而且要在 (6,c)~(10,b) 之间加上 Gap lock,为了防止幻读。然后在主键索引 name 上加对应记录的X 锁;
- 再通过 id=10 在 key(id) 上定位到第二个满足的记录,对该记录加 X 锁,而且要在(10,b)~(10,d)之间加上 Gap lock,为了防止幻读。然后在主键索引 name 上加对应记录的X 锁;
- 最后直到 id=11 发现没有满足的记录了,此时不需要加 X 锁,但要再加一个 Gap lock: (10,d)~(11,f)。
无索引 + RR
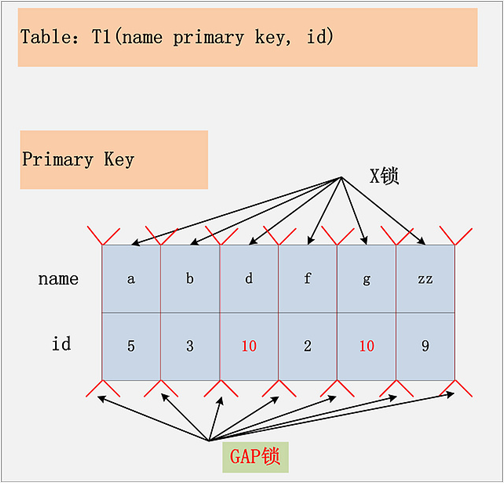
假设条件是:
- update t1 set name=‘XX’ where id=10。
- id 列无索引。
加锁行为:
表里所有行和间隙均加 X 锁。
搞定MySQL

版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: