文章目录
- 生猛干货
- DB Version
- Table
- Case 1 : 联合索引第一个字段用范围不一定会走索引
-
- 优化一 强制走索引 force index(idx_name_age_position)
- 优化二 覆盖索引优化
- Case 2 : in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
- Case 3 : like KK% 一般情况都会走索引
-
- 特殊例子
- 搞定MySQL

生猛干货
带你搞定MySQL实战,轻松对应海量业务处理及高并发需求,从容应对大场面试
DB Version
mysql> select version();
+------------+
| version() |
+------------+
| 5.7.29-log |
+------------+
1 row in set
默认隔离级别 RR 可重复读
Table
CREATE TABLE employees (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
age int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
position varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
hire_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (id),
KEY idx_name_age_position (name,age,position) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
重点
1、 主键idPRIMARYKEY(id);
2、 联合索引KEYidx_name_age_position(name,age,position)USINGBTREE;
我们向表里写入10万来条数据
Case 1 : 联合索引第一个字段用范围不一定会走索引

mysql> EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 74 | NULL | 1 | 5 | Using index condition |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set
mysql> EXPLAIN SELECT * FROM employees WHERE name > 'Artisan' AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 100175 | 0.5 | Using where |
+----+-------------+-----------+------------+------+-----------------------+------+---------+------+--------+----------+-------------+
1 row in set
mysql>
当然了,也不是所有的情况都不走索引, MySQL会基于Cost选择一个合适的 ,如果没有走索引,可能mysql内部可能觉得第一个字段就用范围,结果集应该很大,回表效率不高,还不如就全表扫描
如果没有走索引想要去优化的话怎么办呢?
优化一 强制走索引 force index(idx_name_age_position)
mysql> EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'Artisan' AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 74 | NULL | 50087 | 1 | Using index condition |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+-------+----------+-----------------------+
1 row in set

优化二 覆盖索引优化
mysql> EXPLAIN SELECT name , age , position FROM employees WHERE name > 'Artisan' AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+-------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+-------+----------+--------------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 74 | NULL | 50087 | 1 | Using where; Using index |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+-------+----------+--------------------------+
1 row in set
mysql>

name , age , position 是联合索引,在索引树上,同时索引树上的叶子节点还会关联一个主键id , 如果查询 * 的话,还要根据id去主键索引上去查找其他字段,需要回表, 如果仅查询二级索引树idx_name_age_position上的字段,那就无需回表操作了,效率自然高一些。
Case 2 : in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
mysql> EXPLAIN SELECT * FROM employees WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 140 | NULL | 3 | 100 | Using index condition |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set
mysql> EXPLAIN SELECT * FROM employees WHERE (name = 'LiLei' or name = 'HanMeimei') AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 140 | NULL | 2 | 100 | Using index condition |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set

再搞个小表 ,和 employees 一模一样哈,连索引也得一样,插入3条数据 。
CREATE TABLE employees_2 (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
age int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
position varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
hire_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (id),
KEY idx_name_age_position (name,age,position) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees_2(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees_2(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees_2(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());

mysql> EXPLAIN SELECT * FROM employees_2 WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position ='manager';
+----+-------------+-------------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees_2 | NULL | ALL | idx_name_age_position | NULL | NULL | NULL | 3 | 100 | Using where |
+----+-------------+-------------+------------+------+-----------------------+------+---------+------+------+----------+-------------+
1 row in set
mysql>
为什么呢? 就几条数据的话, 结合B+树的结构, MySQL认为从根节点开始向下找,还不如直接从叶子节点从头开始扫描快呢
Case 3 : like KK% 一般情况都会走索引
结合索引树 , like KK% 可以理解为就是按照 = KK 查询
mysql> EXPLAIN SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager';
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees | NULL | range | idx_name_age_position | idx_name_age_position | 140 | NULL | 1 | 5 | Using index condition |
+----+-------------+-----------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set
mysql> EXPLAIN SELECT * FROM employees_2 WHERE name like 'LiLei%' AND age = 22 AND position ='manager';
+----+-------------+-------------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | employees_2 | NULL | range | idx_name_age_position | idx_name_age_position | 140 | NULL | 1 | 33.33 | Using index condition |
+----+-------------+-------------+------------+-------+-----------------------+-----------------------+---------+------+------+----------+-----------------------+
1 row in set
原因:索引下推 MySQL -索引下推 Index Condition Pushdown 初探
特殊例子
一般情况 ,但也不绝对。看下面这个例子
假设你这个表 的name字段 是以Artisan开头的,从Artisan1 到Artisan100000
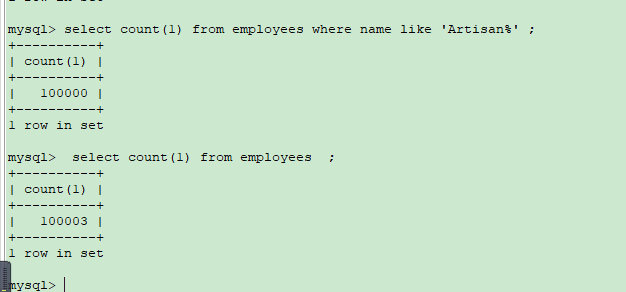
再去like的话 ,mysql会基于cost,自主选择 ,比如如下走了全表扫描。

搞定MySQL

版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: