有道无术,术尚可求,有术无道,止于术。
资料整理来自Nacos架构与原理电子书,下载地址:https://developer.aliyun.com/ebook/36?spm=a2c6h.20345107.ebook-index.18.152c2984fsi5ST
文章目录
- Nacos ⼀致性协议
-
- 为什么 Nacos 需要⼀致性协议
- 为什么 Nacos 选择了 Raft 以及 Distro
-
- 从服务注册发现来看
- 从配置管理来看
- 为什么是 Raft 和 Distro 呢
- 早期的 Nacos ⼀致性协议
- 当前 Nacos 的⼀致性协议层
- Nacos 如何做到⼀致性协议下沉的
-
- ⼀致性协议抽象
- 数据存储抽象
- Nacos 自研 Distro 协议
-
- 背景
- 设计思想
-
- 数据初始化
- 数据校验
- 写操作
- 读操作
- 小结
Nacos ⼀致性协议
为什么 Nacos 需要⼀致性协议
Nacos 在开源支持就定下了⼀个目标,尽可能的减少用户部署以及运维成本,做到用户只需要⼀个 程序包,就可以快速以单机模式启动 Nacos 或者以集群模式启动 Nacos。而 Nacos 是⼀个需要 存储数据的⼀个组件,因此,为了实现这个目标,就需要在 Nacos 内部实现数据存储。
单机下其 实问题不大,简单的内嵌关系型数据库即可;但是集群模式下,就需要考虑如何保障各个节点之间 的数据⼀致性以及数据同步,而要解决这个问题,就不得不引入共识算法,通过算法来保障各个节 点之间的数据的⼀致性。
为什么 Nacos 选择了 Raft 以及 Distro
为什么Nacos 会在单个集群中同时运行 CP 协议以及 AP 协议呢?这其实要从 Nacos 的场景出 发的:Nacos 是⼀个集服务注册发现以及配置管理于⼀体的组件,因此对于集群下,各个节点之间 的数据⼀致性保障问题,需要拆分成两个方面。
从服务注册发现来看
服务发现注册中心,在当前微服务体系下,是十分重要的组件,服务之间感知对方服务的当前可正 常提供服务的实例信息,必须从服务发现注册中心进行获取,因此对于服务注册发现中心组件的可 用性,提出了很高的要求,需要在任何场景下,尽最大可能保证服务注册发现能力可以对外提供服 务;同时 Nacos 的服务注册发现设计,采取了心跳可自动完成服务数据补偿的机制。如果数据丢 失的话,是可以通过该机制快速弥补数据丢失。
因此,为了满足服务发现注册中心的可用性,强⼀致性的共识算法这里就不太合适了,因为强⼀致 性共识算法能否对外提供服务是有要求的,如果当前集群可用的节点数没有过半的话,整个算法直 接“罢工”,而最终⼀致共识算法的话,更多保障服务的可用性,并且能够保证在⼀定的时间内各 个节点之间的数据能够达成⼀致。
上述的都是针对于 Nacos 服务发现注册中的非持久化服务而言(即需要客户端上报心跳进行服务实 例续约)。而对于 Nacos 服务发现注册中的持久化服务,因为所有的数据都是直接使用调用 Nacos 服务端直接创建,因此需要由 Nacos 保障数据在各个节点之间的强⼀致性,故而针对此类型的服务数据,选择了强⼀致性共识算法来保障数据的⼀致性。
从配置管理来看
配置数据,是直接在 Nacos 服务端进行创建并进行管理的,必须保证大部分的节点都保存了此配 置数据才能认为配置被成功保存了,否则就会丢失配置的变更,如果出现这种情况,问题是很严重 的,如果是发布重要配置变更出现了丢失变更动作的情况,那多半就要引起严重的现网故障了,因 此对于配置数据的管理,是必须要求集群中大部分的节点是强⼀致的,而这里的话只能使用强⼀致 性共识算法。
为什么是 Raft 和 Distro 呢
对于强⼀致性共识算法,当前工业生产中,最多使用的就是 Raft 协议,Raft 协议更容易让人理解, 并且有很多成熟的工业算法实现,比如蚂蚁金服的 JRaft、Zookeeper 的 ZAB、Consul 的 Raft、 百度的 braft、Apache Ratis;因为 Nacos 是 Java 技术栈,因此只能在 JRaft、ZAB、Apache Ratis 中选择,但是 ZAB 因为和 Zookeeper 强绑定,再加上希望可以和 Raft 算法库的支持团队 随时沟通交流,因此选择了 JRaft,选择 JRaft 也是因为 JRaft 支持多 RaftGroup,为 Nacos 后 面的多数据分片带来了可能。
而Distro 协议是阿里巴巴自研的⼀个最终⼀致性协议,而最终⼀致性协议有很多,比如 Gossip、 Eureka 内的数据同步算法。而 Distro 算法是集 Gossip 以及 Eureka 协议的优点并加以优化而出 来的,对于原生的 Gossip,由于随机选取发送消息的节点,也就不可避免的存在消息重复发送给同 ⼀节点的情况,增加了网络的传输的压力,也给消息节点带来额外的处理负载,而 Distro 算法引入 了权威 Server 的概念,每个节点负责⼀部分数据以及将自己的数据同步给其他节点,有效的降低 了消息冗余的问题。
早期的 Nacos ⼀致性协议
我们先来看看早起的 Naocs 版本的架构
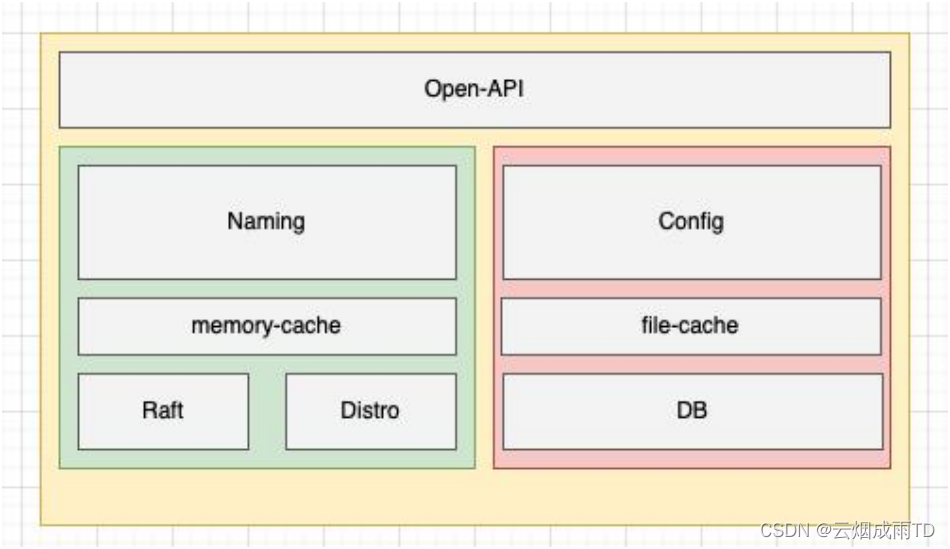
在早期的 Nacos 架构中,服务注册和配置管理⼀致性协议是分开的,没有下沉到 Nacos 的内核模 块作为通用能力演进,服务发现模块⼀致性协议的实现和服务注册发现模块的逻辑强耦合在⼀起, 并且充斥着服务注册发现的⼀些概念。这使得 Nacos 的服务注册发现模块的逻辑变得复杂且难以 维护,耦合了⼀致性协议层的数据状态,难以做到计算存储彻底分离,以及对计算层的无限水平扩 容能力也有⼀定的影响。因此为了解决这个问题,必然需要对 Nacos 的⼀致性协议做抽象以及下沉,使其成为 Core 模块的能力,彻底让服务注册发现模块只充当计算能力,同时为配置模块去外 部数据库存储打下了架构基础。
当前 Nacos 的⼀致性协议层
正如前面所说,在当前的 Nacos 内核中,我们已经做到了将⼀致性协议的能力,完全下沉到了内 核模块作为 Nacos 的核心能力,很好的服务于服务注册发现模块以及配置管理模块,我们来看看当 前 Nacos 的架构。
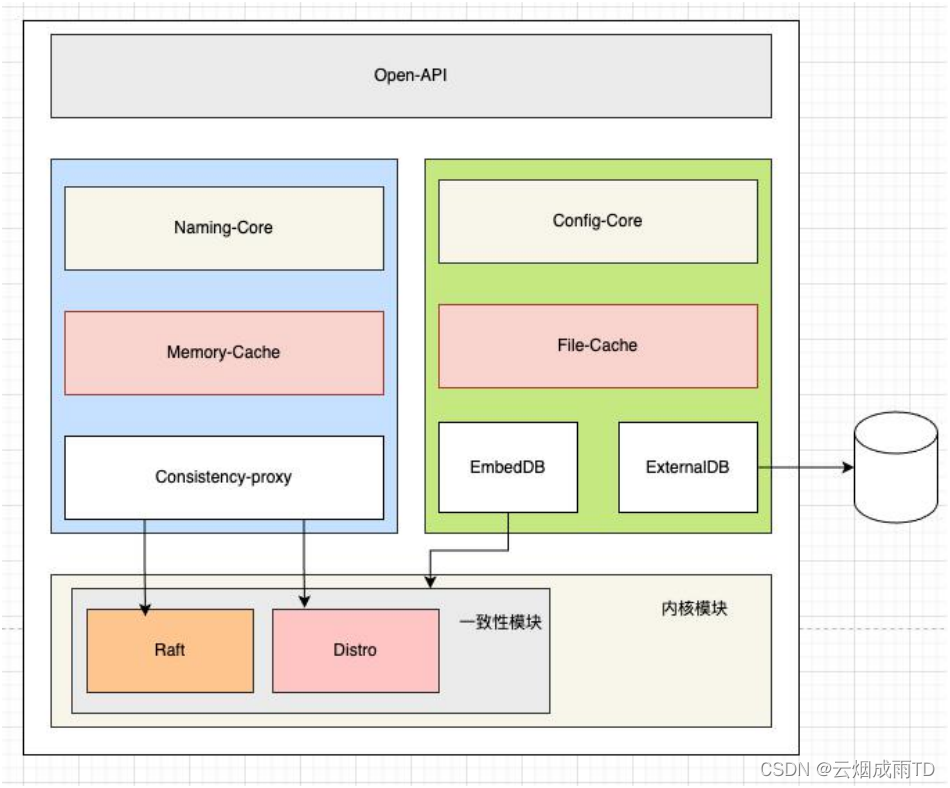
可以发现,在新的 Nacos 架构中,已经完成了将⼀致性协议从原先的服务注册发现模块下沉到了 内核模块当中,并且尽可能的提供了统⼀的抽象接口,使得上层的服务注册发现模块以及配置管理。模块,不再需要耦合任何⼀致性语义,解耦抽象分层后,每个模块能快速演进,并且性能和可用性 都大幅提升。
Nacos 如何做到⼀致性协议下沉的
既然Nacos 已经做到了将 AP、CP 协议下沉到了内核模块,而且尽可能的保持了⼀样的使用体验。 那么这个⼀致性协议下沉,Nacos 是如何做到的呢?
⼀致性协议抽象
其实,⼀致性协议,就是用来保证数据⼀致的,而数据的产生,必然有⼀个写入的动作;同时还要 能够读数据,并且保证读数据的动作以及得到的数据结果,并且能够得到⼀致性协议的保障。因此, ⼀致性协议最最基础的两个方法,就是写动作和读动作
public interface ConsistencyProtocol<T extends Config, P extends RequestProcessor> extends CommandOperations {
/*** Obtain data according to the request.
** @param request request
* @return data {@link Response}
* @throws Exception {@link Exception} */
Response getData(ReadRequest request) throws Exception;
/**
* Data operation, returning submission results synchronously.
* ** @param request {@link com.alibaba.nacos.consistency.entity.WriteRequest}
* * @return submit operation result {@link Response} * @throws Exception {@link Exception}
*/
Response write(WriteRequest request) throws Exception;
}
任何使用⼀致性协议的,都只需要使用 getData 以及 write 方法即可。同时,⼀致性协议已经被 抽象在了 consistency 的包中,Nacos 对于 AP、CP 的⼀致性协议接口使用抽象都在里面,并且 在实现具体的⼀致性协议时,采用了插件可插拔的形式,进⼀步将⼀致性协议具体实现逻辑和服务 注册发现、配置管理两个模块达到解耦的目的。
public class ProtocolManager extends MemberChangeListener implements DisposableBean {
private void initAPProtocol() {
ApplicationUtils.getBeanIfExist(APProtocol.class, protocol -> {
Class configType = ClassUtils.resolveGenericType(protocol.getClass());
Config config = (Config) ApplicationUtils.getBean(configType);
injectMembers4AP(config);
protocol.init((config));
ProtocolManager.this.apProtocol = protocol;
});
}
private void initCPProtocol() {
ApplicationUtils.getBeanIfExist(CPProtocol.class, protocol -> {
Class configType = ClassUtils.resolveGenericType(protocol.getClass());
Config config = (Config) ApplicationUtils.getBean(configType);
injectMembers4CP(config);
protocol.init((config));
ProtocolManager.this.cpProtocol = protocol;
});
}
}
其实,仅做完⼀致性协议抽象是不够的,如果只做到这里,那么服务注册发现以及配置管理,还是 需要依赖⼀致性协议的接口,在两个计算模块中耦合了带状态的接口;并且,虽然做了比较高度的 ⼀致性协议抽象,服务模块以及配置模块却依然还是要在自己的代码模块中去显示的处理⼀致性协 议的读写请求逻辑,以及需要自己去实现⼀个对接⼀致性协议的存储,这其实是不好的,服务发现 以及配置模块,更多应该专注于数据的使用以及计算,而非数据怎么存储、怎么保障数据⼀致性, 数据存储以及多节点⼀致的问题应该交由存储层来保证。为了进⼀步降低⼀致性协议出现在服务注 册发现以及配置管理两个模块的频次以及尽可能让⼀致性协议只在内核模块中感知,Nacos 这里又 做了另⼀份工作——数据存储抽象。
数据存储抽象
正如前面所说,⼀致性协议,就是用来保证数据⼀致的,如果利用⼀致性协议实现⼀个存储,那么 服务模块以及配置模块,就由原来的依赖⼀致性协议接口转变为了依赖存储接口,而存储接口后面 的具体实现,就比⼀致性协议要丰富得多了,并且服务模块以及配置模块也无需为直接依赖⼀致性 协议而承担多余的编码工作(快照、状态机实现、数据同步)。使得这两个模块可以更加的专注自己的核心逻辑。对于数据抽象,这里仅以服务注册发现模块为例。
public interface KvStorage {
enum KvType {
/*** Local file storage. */
File,
/*** Local memory storage. */
Memory,
/*** LSMTree storage. */
LSMTree,
AP,
CP,
}
// 获取⼀个数据
byte[] get(byte[] key) throws KvStorageException;
// 存入⼀个数据
void put(byte[] key, byte[] value) throws KvStorageException;
// 删除⼀个数据
void delete(byte[] key) throws KvStorageException;
}
由于Nacos 的服务模块存储,更多的都是根据单个或者多个唯⼀ key 去执行点查的操作,因此 Key-Value 类型的存储接口最适合不过。而 Key-Value 的存储接口定义好之后,其实就是这个 KVStore 的具体实现了。可以直接将 KVStore 的实现对接 Redis,也可以直接对接 DB ,或者直 接根据 Nacos 内核模块的⼀致性协议,在此基础之上,实现⼀个内存或者持久化的分布式强(弱) ⼀致性 KV。通过功能边界将 Nacos 进程进⼀步分离为计算逻辑层和存储逻辑层,计算层和存储层 之间的交互仅通过⼀层薄薄的数据操作胶水代码,这样就在单个 Nacos 进程里面实现了计算和存储 二者逻辑的彻底分离。
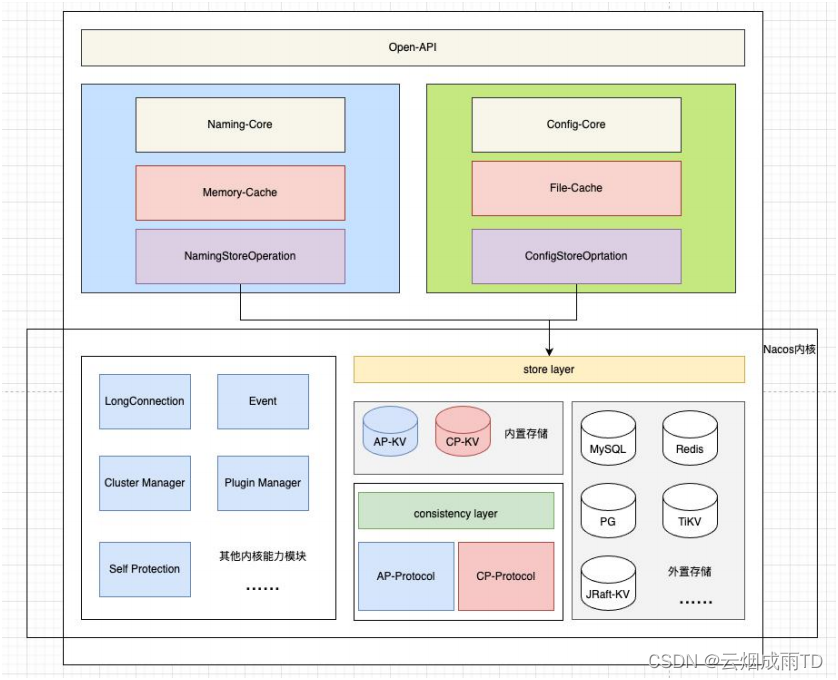
同时,针对存储层,进⼀步实现插件化的设计,对于中小公司且有运维成本要求的话,可以直接使 用 Nacos 自带的内嵌分布式存储组件来部署⼀套 Nacos 集群,而如果服务实例数据以及配置数据 的量级很大的话,并且本身有⼀套比较好的 Paas 层服务,那么完全可以复用已有的存储组件,实 现 Nacos 的计算层与存储层彻底分离。
Nacos 自研 Distro 协议
背景
Distro 协议是 Nacos 社区自研的⼀种 AP 分布式协议,是面向临时实例设计的⼀种分布式协议, 其保证了在某些 Nacos 节点宕机后,整个临时实例处理系统依旧可以正常工作。作为⼀种有状态 的中间件应用的内嵌协议,Distro 保证了各个 Nacos 节点对于海量注册请求的统⼀协调和存储。
设计思想
Distro 协议的主要设计思想如下:
- Nacos 每个节点是平等的都可以处理写请求,同时把新数据同步到其他节点。
- 每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据⼀致性。
- 每个节点独立处理读请求,及时从本地发出响应。
下面几节将分为几个场景进行 Distro 协议工作原理的介绍。
数据初始化
新加入的 Distro 节点会进行全量数据拉取。具体操作是轮询所有的 Distro 节点,通过向其他的机 器发送请求拉取全量数据。
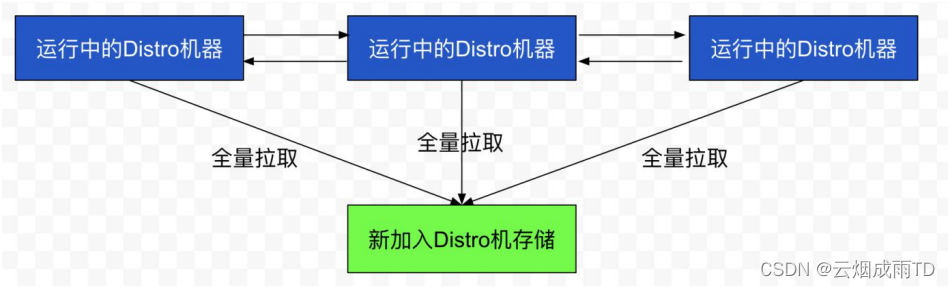
在全量拉取操作完成之后,Nacos 的每台机器上都维护了当前的所有注册上来的非持久化实例数 据。
数据校验
在Distro 集群启动之后,各台机器之间会定期的发送心跳。心跳信息主要为各个机器上的所有数据 的元信息(之所以使用元信息,是因为需要保证网络中数据传输的量级维持在⼀个较低水平)。这 种数据校验会以心跳的形式进行,即每台机器在固定时间间隔会向其他机器发起⼀次数据校验请求。

⼀旦在数据校验过程中,某台机器发现其他机器上的数据与本地数据不⼀致,则会发起⼀次全量拉 取请求,将数据补齐。
写操作
对于⼀个已经启动完成的 Distro 集群,在⼀次客户端发起写操作的流程中,当注册非持久化的实例 的写请求打到某台 Nacos 服务器时,Distro 集群处理的流程图如下。
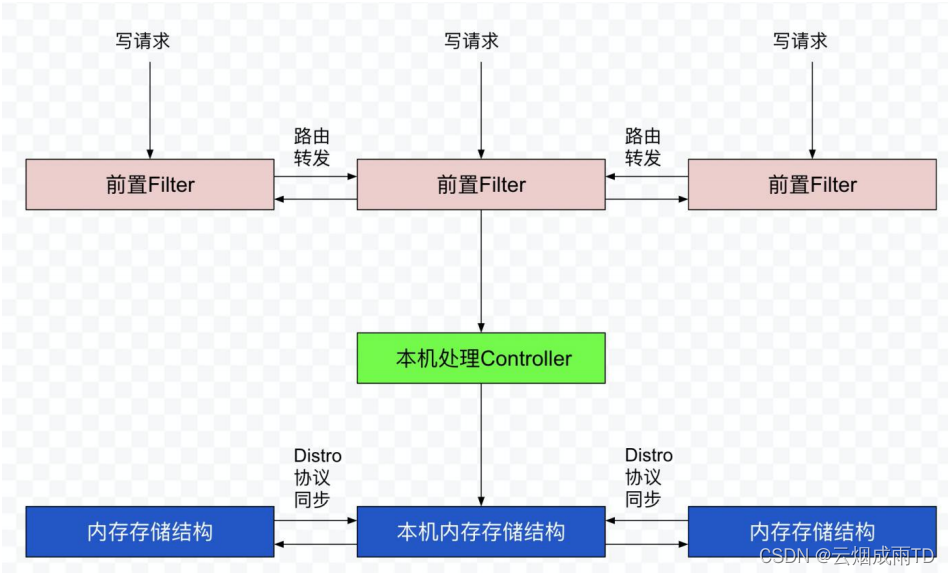
整个步骤包括几个部分(图中从上到下顺序):
- 前置的 Filter 拦截请求,并根据请求中包含的 IP 和 port 信息计算其所属的 Distro 责任节点, 并将该请求转发到所属的 Distro 责任节点上。
- 责任节点上的 Controller 将写请求进行解析。
- Distro 协议定期执行 Sync 任务,将本机所负责的所有的实例信息同步到其他节点上。
读操作
由于每台机器上都存放了全量数据,因此在每⼀次读操作中,Distro 机器会直接从本地拉取数据。 快速响应。
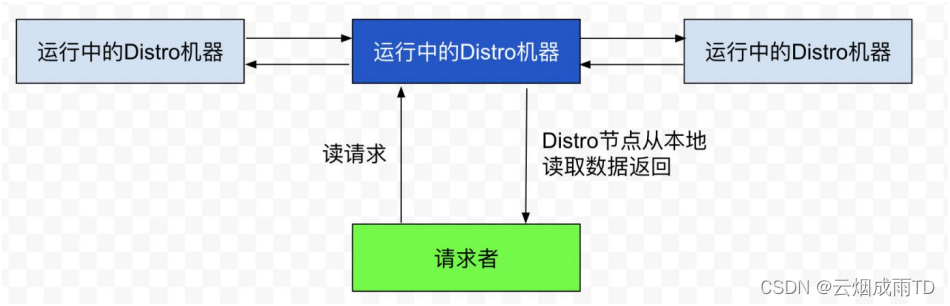
这种机制保证了 Distro 协议可以作为⼀种 AP 协议,对于读操作都进行及时的响应。在网络分区 的情况下,对于所有的读操作也能够正常返回;当网络恢复时,各个 Distro 节点会把各数据分片的 数据进行合并恢复。
小结
Distro 协议是 Nacos 对于临时实例数据开发的⼀致性协议。其数据存储在缓存中,并且会在启动 时进行全量数据同步,并定期进行数据校验。
在Distro 协议的设计思想下,每个 Distro 节点都可以接收到读写请求。所有的 Distro 协议的请 求场景主要分为三种情况:
1、 当该节点接收到属于该节点负责的实例的写请求时,直接写入;
2、 当该节点接收到不属于该节点负责的实例的写请求时,将在集群内部路由,转发给对应的节点,从而完成读写;
3、 当该节点接收到任何读请求时,都直接在本机查询并返回(因为所有实例都被同步到了每台机器上);
Distro 协议作为 Nacos 的内嵌临时实例⼀致性协议,保证了在分布式环境下每个节点上面的服务 信息的状态都能够及时地通知其他节点,可以维持数十万量级服务实例的存储和⼀致性。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: