一 序
看源码的过程,有两个维度,主要是根据执行过程去看。好处是可以有个大的流程图。对于有遗漏的点,可以按照宝结构再扫一遍,查漏补缺。上一篇主要整理了分库分表及主要暴露的API。本边继续从jdbc规范整理,从jdbc的实现,柔性事务,读写分离,路由,结果合并。最后整理模块最多也是核心的SQL解析。感谢芋道源码。http://www.iocoder.cn/Sharding-JDBC/jdbc-implement-and-read-write-splitting/
对于jdbc的规范,shardignjdbc我理解就是封装了规范的类,然后将对象的方法进行重写,而ShardingDataSource、ShardingConnection、ShardingStatement、ShardingPreparedStament类可以看作一个代理对象,它们内部完成了根据逻辑sql语句,转化成真实sql语句,路由找到对应数据源,并根据数据源产生真实的Connection对象,然后执行真实sql语句,并将结果归并返回给应用层的功能。
二 包结构
看一下源码的总体结构:
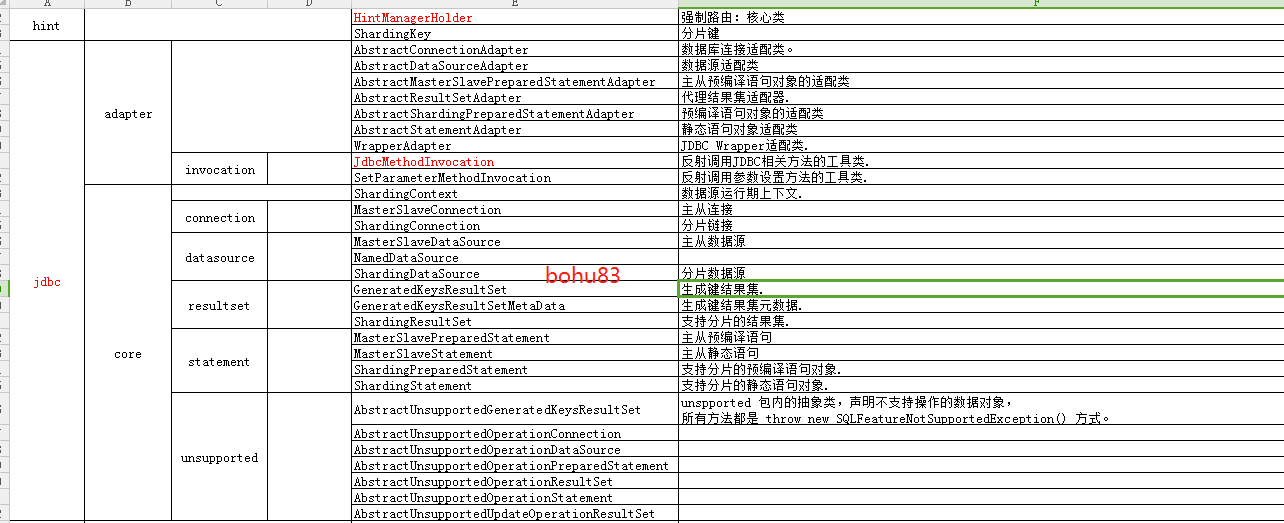
unsupported:声明不支持的数据操作方法
adapter:适配类,实现和分库分表无关的方法
core:核心类,实现和分库分表相关的方法。下面是子包封装的DataSource、Connection、resultset、Statement。
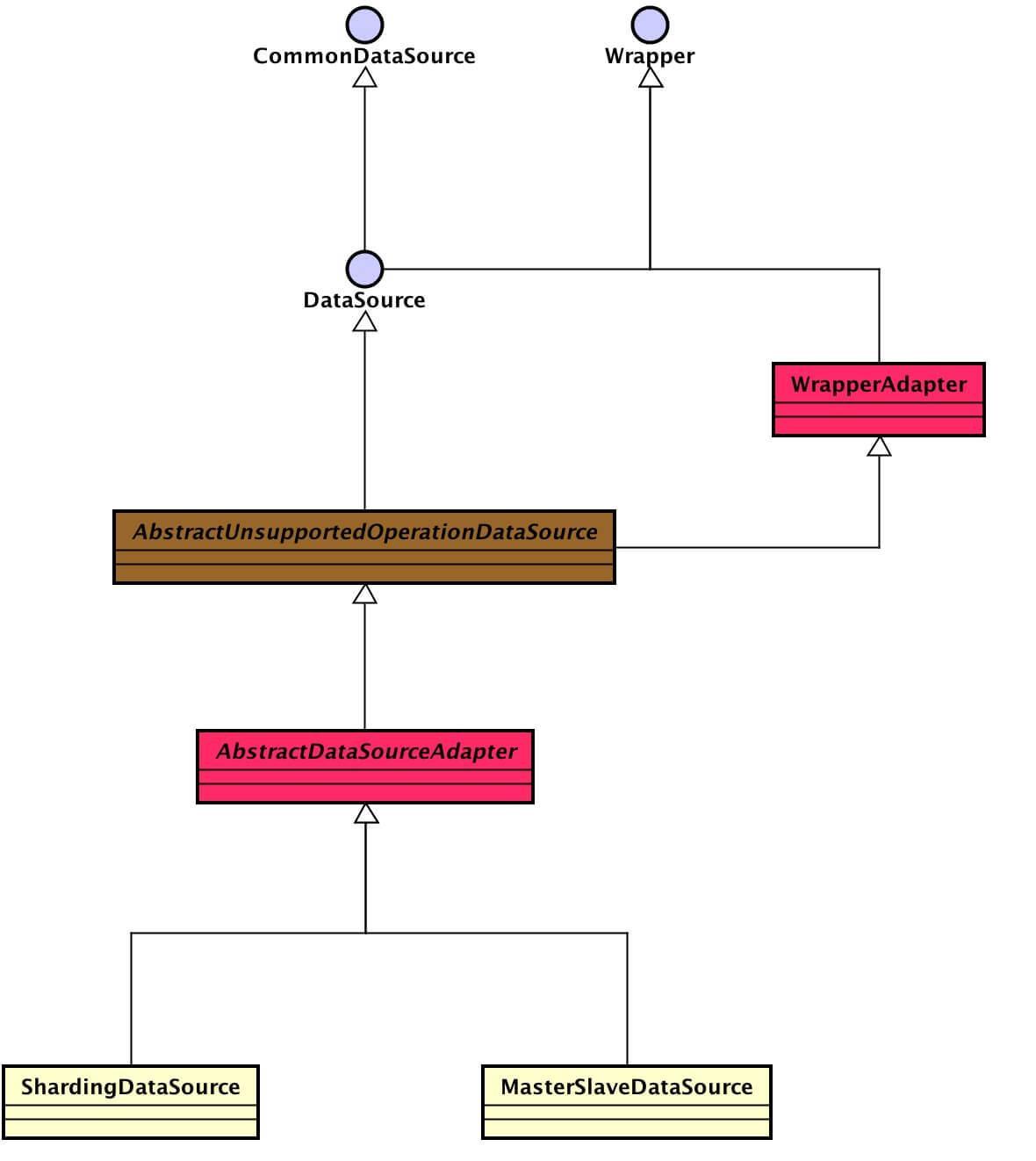
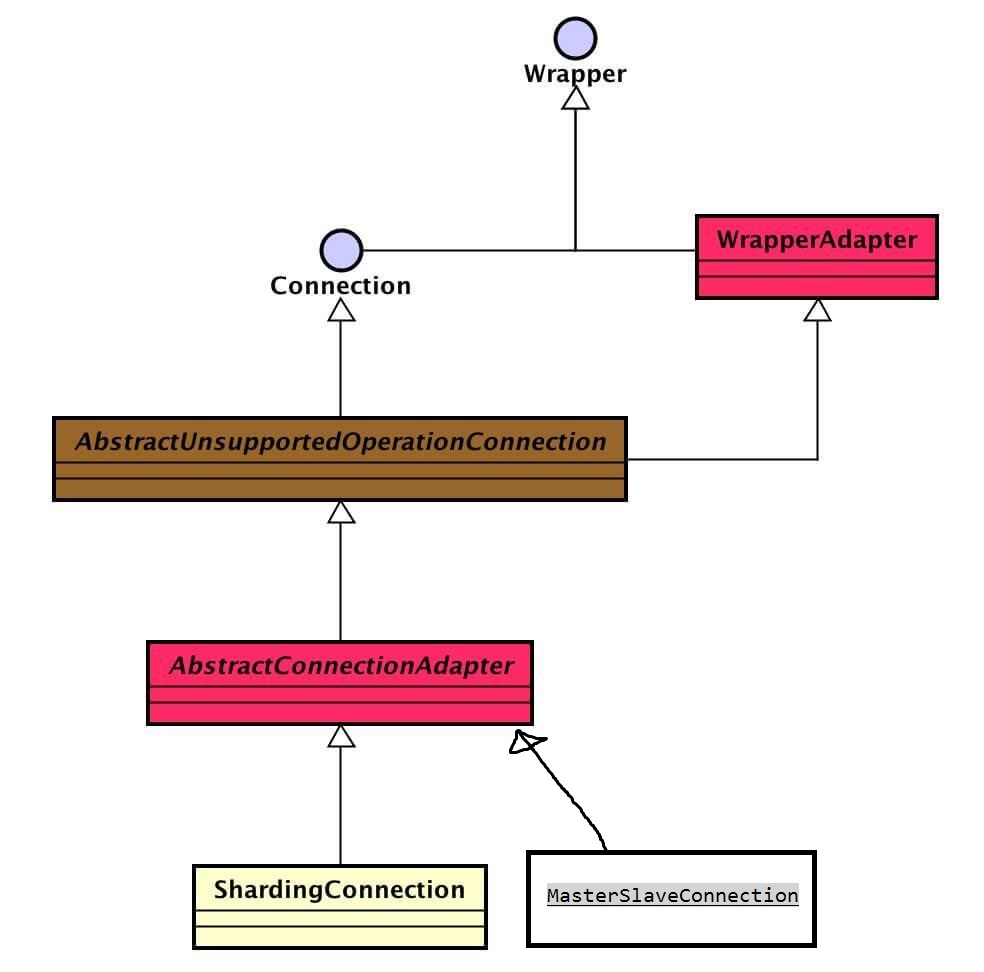
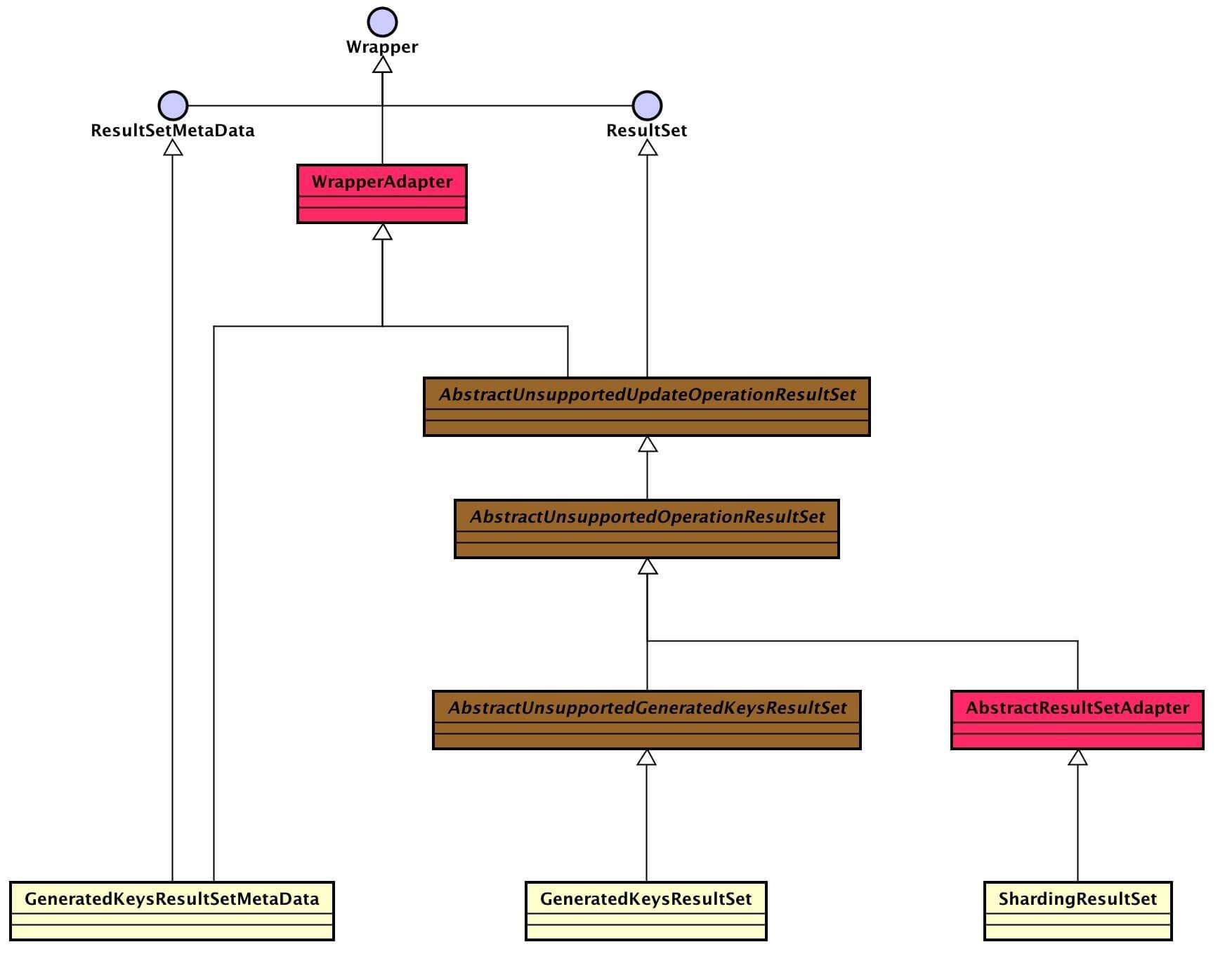
以下图片来自芋道的博客:
datasource:
Connection
resultset
statement
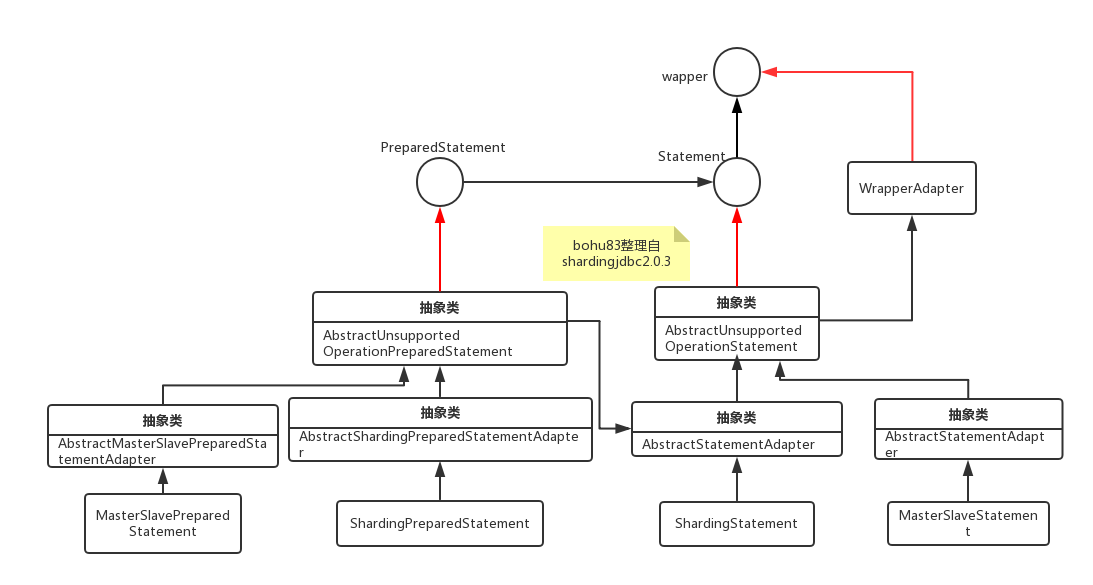
看着层级比较多。实现层级关系:JDBC 接口 <=(继承)== unsupported抽象类 <=(继承)== unsupported抽象类 <=(继承)== core类。
三 核心Jdbc方法
3.1 unspported 包
unspported 包内的抽象类,声明不支持操作的数据对象,所有方法都是 throw new SQLFeatureNotSupportedException() 方式。
public abstract class AbstractUnsupportedOperationPreparedStatement extends AbstractStatementAdapter implements PreparedStatement {
public AbstractUnsupportedOperationPreparedStatement() {
super(PreparedStatement.class);
}
@Override
public final ResultSetMetaData getMetaData() throws SQLException {
throw new SQLFeatureNotSupportedException("getMetaData");
}
3.2 WrapperAdapter
对Wrapper 接口实现如下两个方法:
@SuppressWarnings("unchecked")
@Override
public final <T> T unwrap(final Class<T> iface) throws SQLException {
if (isWrapperFor(iface)) {
return (T) this;
}
throw new SQLException(String.format("[%s] cannot be unwrapped as [%s]", getClass().getName(), iface.getName()));
}
@Override
public final boolean isWrapperFor(final Class<?> iface) throws SQLException {
return iface.isInstance(this);
}
核心方法:提供子类 #recordMethodInvocation() 记录方法调用,#replayMethodsInvocation() 回放记录的方法调用:
private final Collection<JdbcMethodInvocation> jdbcMethodInvocations = new ArrayList<>();
/**
* 记录方法调用.
*
* @param targetClass 目标类
* @param methodName 方法名称
* @param argumentTypes 参数类型
* @param arguments 参数
*/
public final void recordMethodInvocation(final Class<?> targetClass, final String methodName, final Class<?>[] argumentTypes, final Object[] arguments) {
try {
jdbcMethodInvocations.add(new JdbcMethodInvocation(targetClass.getMethod(methodName, argumentTypes), arguments));
} catch (final NoSuchMethodException ex) {
throw new ShardingJdbcException(ex);
}
}
/**
* 回放记录的方法调用.
*
* @param target 目标对象
*/
public final void replayMethodsInvocation(final Object target) {
for (JdbcMethodInvocation each : jdbcMethodInvocations) {
each.invoke(target);
}
}
记录了调用的方法与传入方法的参数,实际是将JdbcMethodInvocation对象放入WrapperAdapter的成员变量。下面再看如何保存的。
用途举例: AbstractConnectionAdapter 的 #setAutoCommit(),先记录,后回放(在获取真正的connection时)。
@Override
public final void setAutoCommit(final boolean autoCommit) throws SQLException {
this.autoCommit = autoCommit;
recordMethodInvocation(Connection.class, "setAutoCommit", new Class[] {boolean.class}, new Object[] {autoCommit});
for (Connection each : cachedConnections.values()) {
each.setAutoCommit(autoCommit);
}
}
回放代码:在ShardingConnection.getConnection()
为啥这么设计呢?简单理解就是(当它无数据库连接时,先记录;等获得到数据连接后,再回放)。后面细说。
3.3 JdbcMethodInvocation
上面说的记录到 JdbcMethodInvocation,看看jdbcMethodInvocations记录了所有调用的方法与参数。
public final class JdbcMethodInvocation {
private final Method method;//调用的方法
private final Object[] arguments;//调用方法时传入的参数
/**
* 调用方法.
*
* @param target 目标对象
*/
public void invoke(final Object target) {
try {
method.invoke(target, arguments);
} catch (final IllegalAccessException | InvocationTargetException ex) {
throw new ShardingJdbcException("Invoke jdbc method exception", ex);
}
}
}
使用了反射。
3.4 核心流程举例
上面说的3.2,3.3是jdbc的核心类,怎么串联起来执行的呢?找个例子看下具体流程
看下jdbc的规范的:https://docs.oracle.com/javase/tutorial/jdbc/basics/index.html
ShardingPreparedStatement的executeUpdate方法:
下面图来自芋道博客:
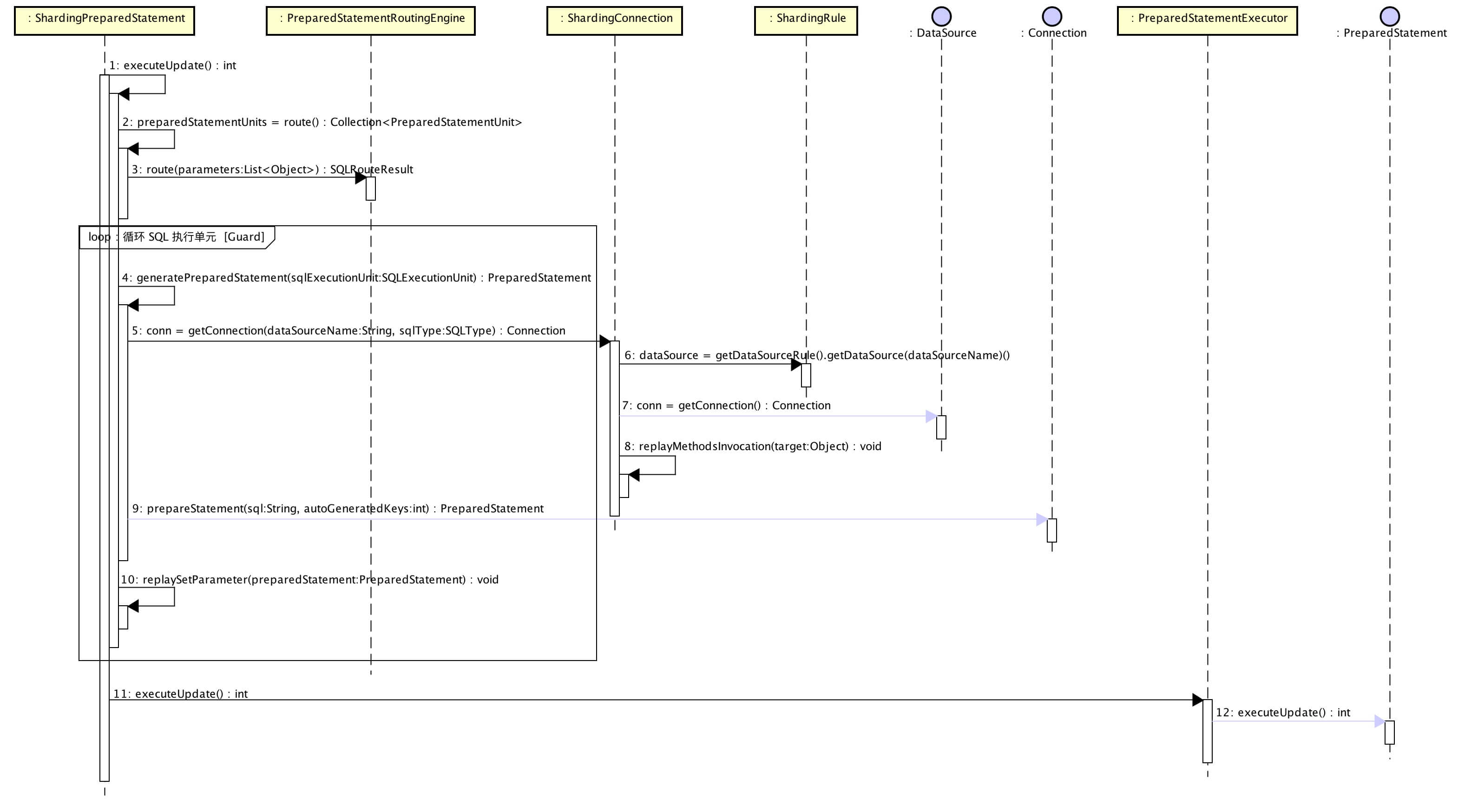
@Override
public int executeUpdate() throws SQLException {
try {
Collection<PreparedStatementUnit> preparedStatementUnits = route();
return new PreparedStatementExecutor(
getConnection().getShardingContext().getExecutorEngine(), routeResult.getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeUpdate();
} finally {
clearBatch();
}
}
总体上分两部分:1 route() 分库分表路由,获得预编译语句对象执行单元集合:Collection
2PreparedStatementExecutor.executeUpdate 就是上图的步骤11、12
/**
* Execute update.
*
* @return effected records count
* @throws SQLException SQL exception
*/
public int executeUpdate() throws SQLException {
List<Integer> results = executorEngine.executePreparedStatement(sqlType, preparedStatementUnits, parameters, new ExecuteCallback<Integer>() {
@Override
public Integer execute(final BaseStatementUnit baseStatementUnit) throws Exception {
return ((PreparedStatement) baseStatementUnit.getStatement()).executeUpdate();
}
});
return accumulate(results);
}
再来看看调用细节。
route
private Collection<PreparedStatementUnit> route() throws SQLException {
Collection<PreparedStatementUnit> result = new LinkedList<>();
//设置路由
routeResult = routingEngine.route(getParameters());
//遍历SQL执行单元
for (SQLExecutionUnit each : routeResult.getExecutionUnits()) {
SQLType sqlType = routeResult.getSqlStatement().getType();
Collection<PreparedStatement> preparedStatements;
// 创建实际的 PreparedStatement
if (SQLType.DDL == sqlType) {
preparedStatements = generatePreparedStatementForDDL(each);
} else {
//上面的DDL少用。generatePreparedStatement是常用创建
preparedStatements = Collections.singletonList(generatePreparedStatement(each));
}
routedStatements.addAll(preparedStatements);
// 回放设置占位符参数到 PreparedStatement
for (PreparedStatement preparedStatement : preparedStatements) {
replaySetParameter(preparedStatement);
result.add(new PreparedStatementUnit(each, preparedStatement));
}
}
return result;
}
private PreparedStatement generatePreparedStatement(final SQLExecutionUnit sqlExecutionUnit) throws SQLException {
Optional<GeneratedKey> generatedKey = getGeneratedKey();
// 获得连接
Connection connection = getShardingConnection().getConnection(sqlExecutionUnit.getDataSource(), getRouteResult().getSqlStatement().getType());
// 声明返回主键,因为算法缺陷通常不用框架自带的,自己设置
if (isReturnGeneratedKeys() || isReturnGeneratedKeys() && generatedKey.isPresent()) {
return connection.prepareStatement(sqlExecutionUnit.getSql(), RETURN_GENERATED_KEYS);
}
return connection.prepareStatement(sqlExecutionUnit.getSql(), getResultSetType(), getResultSetConcurrency(), getResultSetHoldability());
}
调用 #generatePreparedStatement() 创建 PreparedStatement,后调用 #replaySetParameter() 回放设置占位符参数到 PreparedStatement。声明返回主键一般很少用,基于snowflake的算法需要自己改造。
再看获取连接部分代码,调用 ShardingConnection#getConnection() 方法获得该 PreparedStatement 对应的真实数据库连接( Connection ):
public Connection getConnection(final String dataSourceName, final SQLType sqlType) throws SQLException {
if (getCachedConnections().containsKey(dataSourceName)) {
return getCachedConnections().get(dataSourceName);
}
DataSource dataSource = shardingContext.getShardingRule().getDataSourceMap().get(dataSourceName);
Preconditions.checkState(null != dataSource, "Missing the rule of %s in DataSourceRule", dataSourceName);
String realDataSourceName;
if (dataSource instanceof MasterSlaveDataSource) {
NamedDataSource namedDataSource = ((MasterSlaveDataSource) dataSource).getDataSource(sqlType);
realDataSourceName = namedDataSource.getName();
if (getCachedConnections().containsKey(realDataSourceName)) {
return getCachedConnections().get(realDataSourceName);
}
dataSource = namedDataSource.getDataSource();
} else {
realDataSourceName = dataSourceName;
}
Connection result = dataSource.getConnection();
getCachedConnections().put(realDataSourceName, result);
replayMethodsInvocation(result);
return result;
}
调用 #getCachedConnection() 尝试获得已缓存的数据库连接;如果缓存存在直接返回.其中: #getCachedConnections()来自ShardingConnection父类AbstractConnectionAdapter。属性为
@Getter
private final Map<String, Connection> cachedConnections = new HashMap<>();
而connectionMap 为保存真实Connection的Map,其key为配置文件中真实dataSource Bean的id。connectionMap 的初始值为空。在调用ShardingConnection的getConnection方法得到真实的Connection对象后,才会将其实放connectionMap 中。
从ShardingRule 配置的 DataSourceRule 获取真实的数据源( DataSource )
MasterSlaveDataSource 判断是否主从,实现主从数据源封装
调用 #replayMethodsInvocation() 回放记录的 Connection 方法,这里就有上面的说的回放代码。
我们再看看获取数据源部分:
ShardingJDBC框架通过配置文件指定ShardingDataSource与外部应用程序交互,达到访问真实数据源的目的。其有三个成员变量
public class ShardingDataSource extends AbstractDataSourceAdapter implements AutoCloseable {
private ShardingProperties shardingProperties;
private ExecutorEngine executorEngine;
private ShardingContext shardingContext;
shardingProperties为一些属性,executorEngine为一个多线程的执行引擎其内部采用Guava的ListeningExecutorService实现。shardingContext为上下文信息,记录了分库分表规则配置、执行引擎、sql路由引擎这些信息。以便ShardingConnection 使用。
利用ShardingJDBC框架后通过DataSource得到的Connection实际上是包装后的ShardingConnection。ShardingDataSource对DataSource的所有方法进行了重写,其中getConnection如下:
@Override
public ShardingConnection getConnection() throws SQLException {
return new ShardingConnection(shardingContext);
}
得到得到的Connection实际上是包装后的ShardingConnection,而Sharding上下文对象在创建ShardingConnection时被传入。
public final class ShardingConnection extends AbstractConnectionAdapter {
@Getter
private final ShardingContext shardingContext;
再回到上面的示例:当我们调用con.setAutoCommit方法时,实际是调用ShardingConnection重写后的setAutoCommit方法。该方法在其父类AbstractConnectionAdapter中完成重写。
public final void setAutoCommit(final boolean autoCommit) throws SQLException {
this.autoCommit = autoCommit;
//记录调用过的方法与对应参数,当在产生真正的Connection对象时,
//再利用反射的方式让真正的Connection对象调用该方法
recordMethodInvocation(Connection.class, "setAutoCommit", new Class[] {boolean.class}, new Object[] {autoCommit});
for (Connection each : cachedConnections.values()) {
each.setAutoCommit(autoCommit);
}
}
除了setAutoCommit方法外以下的方式也是通过这JdbcMethodInvocation实现的。
AbstractConnectionAdapter类:setReadOnly,setTransactionIsolation
总结:
通过ShardingDataSource类得到的ShardingConnection不是真的JDBC Connection对象,其父类AbstractConnectionAdapter内部有一个Map<String, Connection> cachedConnections 。key为数据源名,value为真实的Connection。当调用Connection类的一些方法时,实际是调用了ShardingConnection 重写后的方法,而此时connectionMap的还是空,达不到调用真实Connection对象方法的功能,为此在ShardingConnection 重写后的方法方法中将调用的方法与方法的参数记录到JdbcMethodInvocation对象中。只有当ShardingPreparedStatement或者ShardingStatement调用对应数据操作函数时(executeQuery,execute,executeUpdate)才会调用ShardingConnection的getContetion方法产生真实的Connection对象,同时把这些对象放入connectionMap。为此在调用ShardingConnection 的setAutoCommint方法、setReadOnly方法、setTransactionIsolation方法时,要记录一下所有调用过的方法的名称与参数。当通过ShardingPreparedStatement或者ShardingStatement产生一个实际的Connection时,再通过反射的方式让真实的Connection对象调用JdbcMethodInvocation记录的方法与方法的参数。
参考:
https://blog.csdn.net/jackyechina/article/details/53010667
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: