本文从官网的配置的 数据源入门,介绍支持的分库分表及与对应的API源码
一 官网分库分表数据源配置
1、 1[核心概念:][Link1];
shardingjdbc 对数据分为yaml,spring,spring boot等多种方式。
可以结合实际项目使用,我们实际采用spring,但是为了节省篇幅,把官网的yaml带注释的贴过来。
dataSources: 数据源配置
<data_source_name> 可配置多个: !!数据库连接池实现类
driverClassName: 数据库驱动类名
url: 数据库url连接
username: 数据库用户名
password: 数据库密码
... 数据库连接池的其它属性
defaultDataSourceName: 默认数据源,未配置分片规则的表将通过默认数据源定位
tables: 分库分表配置,可配置多个logic_table_name
<logic_table_name>: 逻辑表名
actualDataNodes: 真实数据节点,由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。不填写表示将为现有已知的数据源 + 逻辑表名称生成真实数据节点。用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况。
databaseStrategy: 分库策略,以下的分片策略只能任选其一
standard: 标准分片策略,用于单分片键的场景
shardingColumn: 分片列名
preciseAlgorithmClassName: 精确的分片算法类名称,用于=和IN。该类需使用默认的构造器或者提供无参数的构造器
rangeAlgorithmClassName: 范围的分片算法类名称,用于BETWEEN,可以不配置。该类需使用默认的构造器或者提供无参数的构造器
complex: 复合分片策略,用于多分片键的场景
shardingColumns : 分片列名,多个列以逗号分隔
algorithmClassName: 分片算法类名称。该类需使用默认的构造器或者提供无参数的构造器
inline: inline表达式分片策略
shardingColumn : 分片列名
algorithmInlineExpression: 分库算法Inline表达式,需要符合groovy动态语法
hint: Hint分片策略
algorithmClassName: 分片算法类名称。该类需使用默认的构造器或者提供无参数的构造器
none: 不分片
tableStrategy: 分表策略,同分库策略
bindingTables: 绑定表列表
- 逻辑表名列表,多个<logic_table_name>以逗号分隔
defaultDatabaseStrategy: 默认数据库分片策略,同分库策略
defaultTableStrategy: 默认数据表分片策略,同分库策略
props: 属性配置(可选)
sql.show: 是否开启SQL显示,默认值: false
executor.size: 工作线程数量,默认值: CPU核数
还是比较好理解的。
二 常见分库分表方法:
Sharding-JDBC认为对于分片策略存有两种维度:
-
数据源分片策略(DatabaseShardingStrategy):数据被分配的目标数据源
-
表分片策略(TableShardingStrategy):数据被分配的目标表
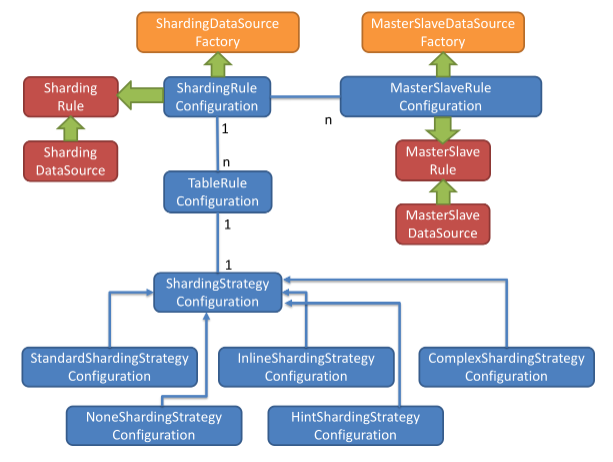
2.1 分片策略
Sharding分片策略继承自ShardingStrategy,提供了5种分片策略:

StandardShardingStrategy
标准分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。
RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
ComplexShardingStrategy
复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。
ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此Sharding-JDBC并未做过多的封装,而是直接将分片键值组合以及分片操作符交于算法接口,完全由应用开发者实现,提供最大的灵活度。
InlineShardingStrategy
Inline表达式分片策略。使用Groovy的Inline表达式,提供对SQL语句中的=和IN的分片操作支持。
InlineShardingStrategy只支持单分片键,对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: tuser${user_id % 8} 表示t_user表按照user_id按8取模分成8个表,表名称为t_user_0到t_user_7。
HintShardingStrategy
通过Hint而非SQL解析的方式分片的策略。
NoneShardingStrategy
不分片的策略。
2.2分片算法类:
Sharding提供了以下4种算法接口:
PreciseShardingAlgorithm:精准分片算法
RangeShardingAlgorithm:范围分片算法
HintShardingAlgorithm: 基于hint的强制分片算法
ComplexKeysShardingAlgorithm:复合分片算法
可以看官网的example。
三 对应的API类
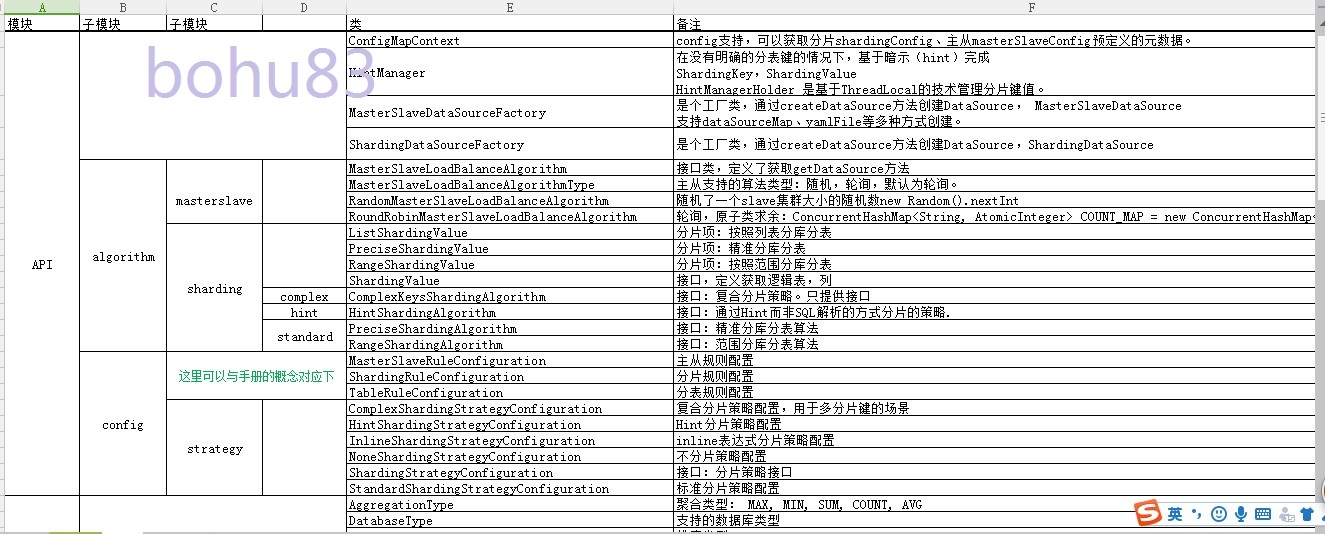
api跟上面的对应的,分库分表的。
看下主从,在io.shardingjdbc.core.api.algorithm.masterslave下面
目的是在读的时候,如何选择从数据库。目前在sharding-jdbc中,实现了随机跟轮询,我们看下是如何实现的。
/**
* Random slave database load-balance algorithm.
*
* @author zhangliang
*/
public final class RandomMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {
return slaveDataSourceNames.get(new Random().nextInt(slaveDataSourceNames.size()));
}
}
随机就是用随机slave集群大小的随机数
/**
* Round-robin slave database load-balance algorithm.
*
* @author zhangliang
*/
public final class RoundRobinMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private static final ConcurrentHashMap<String, AtomicInteger> COUNT_MAP = new ConcurrentHashMap<>();
@Override
public String getDataSource(final String name, final String masterDataSourceName, final List<String> slaveDataSourceNames) {
AtomicInteger count = COUNT_MAP.containsKey(name) ? COUNT_MAP.get(name) : new AtomicInteger(0);
COUNT_MAP.putIfAbsent(name, count);
count.compareAndSet(slaveDataSourceNames.size(), 0);
return slaveDataSourceNames.get(count.getAndIncrement() % slaveDataSourceNames.size());
}
}
轮询采用了COUNT_MAP,缓存的内容是name-count的键值对,而count是一个原子类。然后对slave集群大小求余保证每个都轮询到。
sharding包下面,是分片键
对应的分片项PreciseShardingValue
对应的分片项RangeShardingValue
对应的分片项ListShardingValue
下面是对应的分表算法:
PreciseShardingAlgorithm:精准分片算法
RangeShardingAlgorithm:范围分片算法
HintShardingAlgorithm: 基于hint的强制分片算法
ComplexKeysShardingAlgorithm:复合分片算法
config:基于配置的,可以与最上面的官网的手册对应下。
参考:
https://www.cnblogs.com/mr-yang-localhost/p/8313360.html
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: