0. 引言
上一节,我们简单介绍了solr并演示了单节点solr的安装流程,本章,我们继续讲解solr的核心概念
1. 核心概念
- 核心(索引/表)
在es中有索引这个概念,相当于mysql中的表(与mysql中的索引区分开来),而在solr中称之为核心 core, 所以我们可以看到页面上有一个core admin,就是用来管理核心的,个人更喜欢将其称之为索引,与es的概念形成关联记忆。
和数据库一样,solr的数据就是由一个个core组成。
- 文档 doc
doc全称document, es中也有相同的概念,相当于数据库中的一行数据,一个doc也就表示的一个core中的一条数据
- 结构 Schema
Schema类似于数据库中的表结构,以schema.xml的文本形式存在于conf目录下,在添加数据到索引中时,需要配置Schema。schema中包含:字段、字段类型、唯一键
- 分词
之前没有接触过搜索引擎的同学,可能还不太理解分词是什么概念,与传统的数据库模糊查查询不一样,搜索引擎是基于分词查询的,从而来弥补模糊查询不足的地方
举个例子,我们想要查询沙县小吃,那么传统的模糊查询是使用前后模糊匹配,类似 沙县小吃 ,这样的匹配模式,但如果我们的内容只有“沙县”,没有小吃时,就会导致匹配不到我们想要的信息。而分词不同,分词首先就将我们的搜索文本分割成一个个的词组,比如:沙县、小吃,然后分别匹配这些分词在哪个数据中出现的,将其匹配出来,并计算相关度得分。
- 倒排索引
说明了分词,我们需要继续讲解倒排索引,也叫反向索引,来帮助大家理解solr为什么能实现毫秒级的搜索体验
如下图为普通的正向索引,一句话被对应分割成了一组分词,当我们查询"china"时,会去各个文档的分词组中查询是否存在,这样的做法需要遍历每个文档,数据量较大时,明显就很慢了
而逆向索引的处理刚好相反,以分词为存储的主键,文档ID为值,这样能直接通过分词查询出哪些文档存在该关键字,通过文档ID是顺序存储的,那么也就意味着是有压缩空间的,具体大家可以参考之前书写的关于ES的分词压缩算法,核心思想类似:浅谈倒排索引的两种压缩算法:FOR算法和RBM算法倒排索引的存储方式,其核心优势就在于当数量特别大时,其在性能的提高和空间上的节约
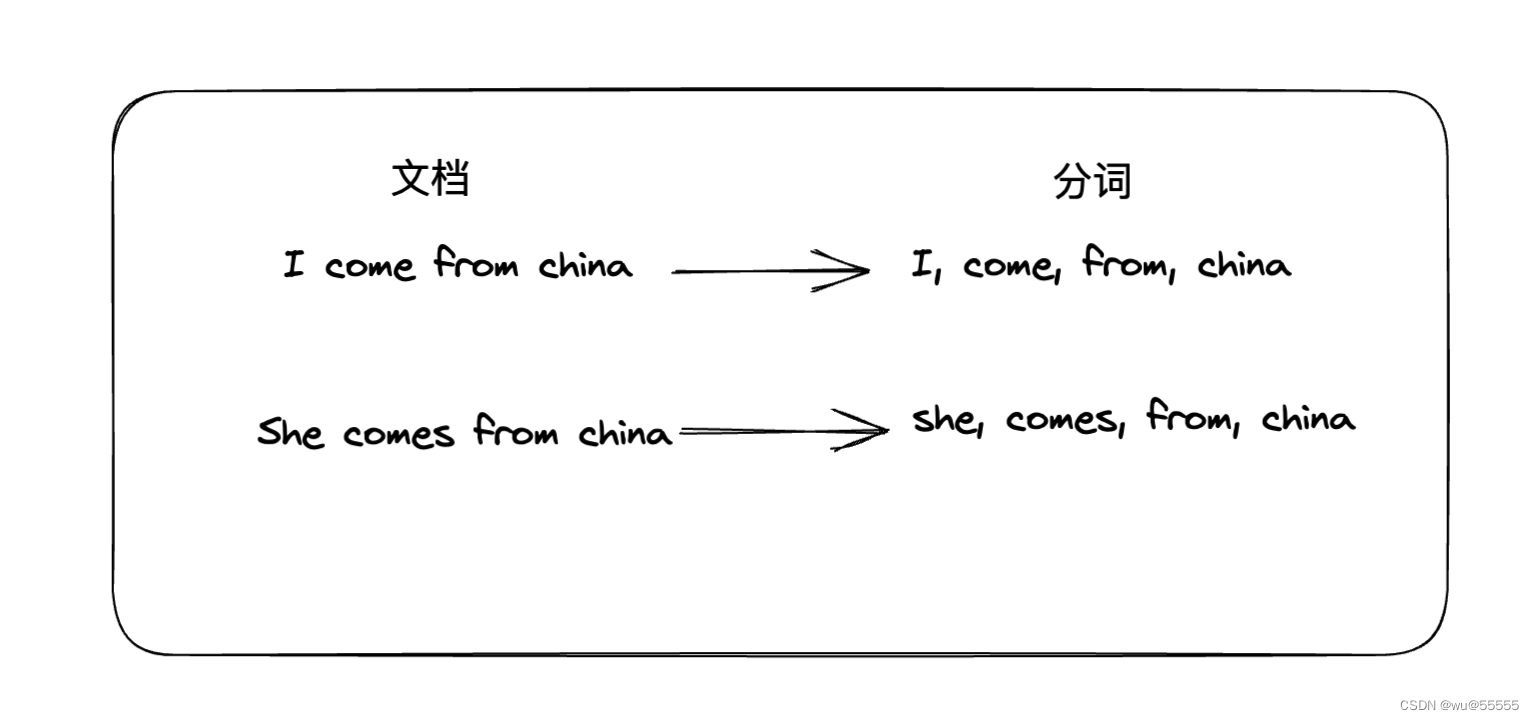

- 存储说明
2. solr-admin页面介绍
我们打开solr的管理界面,会发现页面分成了5个部分
- Dashboard solr的基本信息
如下图所示,可以看到solr的版本、java版本等基础信息

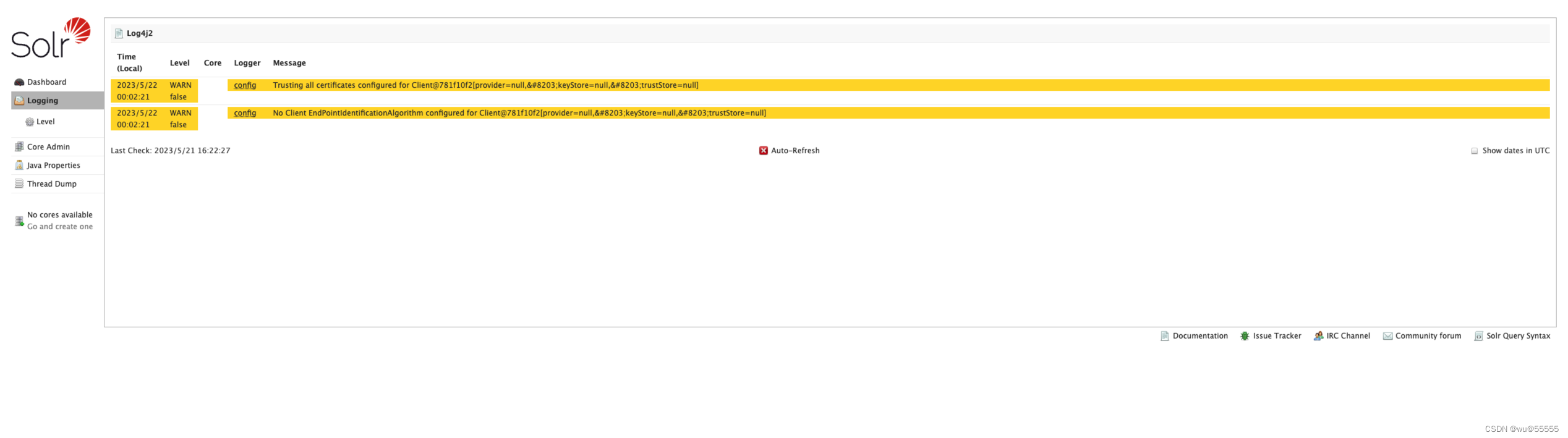
- Logging 日志
非常重要的页面,当solr出现问题,比如数据库data-import同步失败时,就可以通过该页面查看日志详情,从而来进行排错,擅用Logging页面,将会为你节约大量的排错时间
- Core Admin 核心/索引管理,类似数据库表管理
如下图所示,我们可以在Core Admin中进行数据的同步、查询、新增修改、配置文件的查看等
- Overview: 概览,一些核心/索引的统计信息
- Analysis: 分词查询,如果想知道某个查询词会被分词成什么样,可在这里操作,类似es中的_analyze语句
- DataImport: 数据同步,分为增量同步和全量同步
- Documents: 数据新增或更新、删除,新增和更新用的都是/update,id存在则更新,不存在则新增
- Files: 配置文件信息,也提供了上传或下载文件到solr服务的功能,可以通过此自定义查询组件
- Ping: 用于测试与solr服务器之前的连接是否正常
- Plugins/Stats:插件管理页面,可以查看、启用、禁用已经安装了的solr插件
- Query:查询页面,提供在线查询solr数据的页面
- Replication:管理solr分片配置
- Schema:管理solr索引结构
- Segments info:查看solr索引的段信息,了解索引大小、文档数量、字段等信息
- Java Properties java相关属性
- Thread Dump 线程相关信息
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: