一、分词器
ElasticSearch 核心功能就是数据检索,实现该功能需要将文档数据写入es并分析转为词条流,大概分以下三步:
1、 写入:将文档数据写入es的索引;
2、 词条化:分词器将输入的文本转为一个一个的词条流;
3、 过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤器、小写过滤器等;
es内置了多种分词器(如下图),但大多数都只适用于英语,所以我们还需要安装第三方的中文分词器。
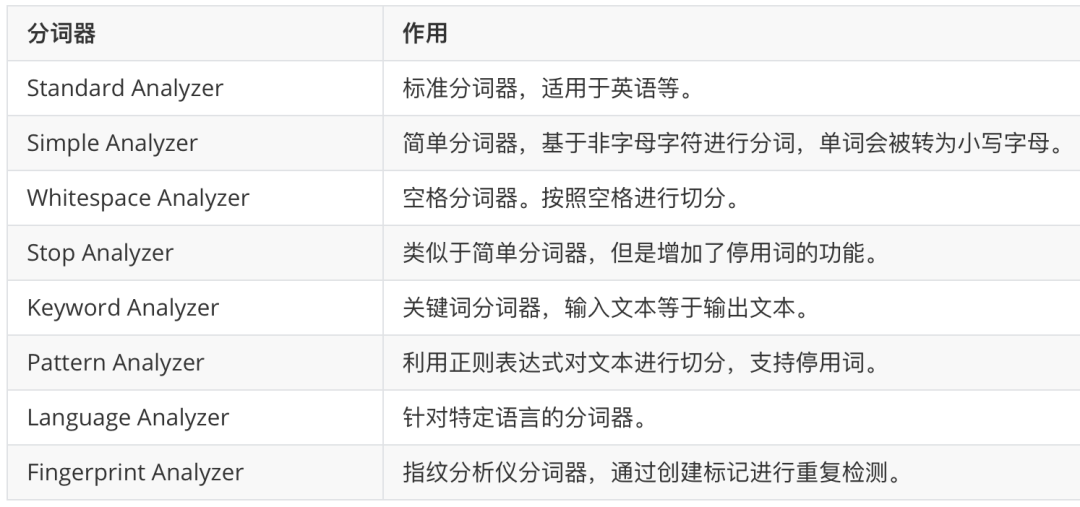
二、中文分词器
1、安装
在Es 中,使用较多的中文分词器是 elasticsearch-analysis-ik ,我们采用下载解压安装的方式:
1、 在GitHub下载最新的正式版:https://github.com/medcl/elasticsearch-analysis-ik;
2、 在es/plugins目录下新建ik目录,将下载的文件解压到该目录;
3、 重启es;
2、测试
在官网的Quick Example部分,就用详细的测试步骤,测试工具我们选择postman。
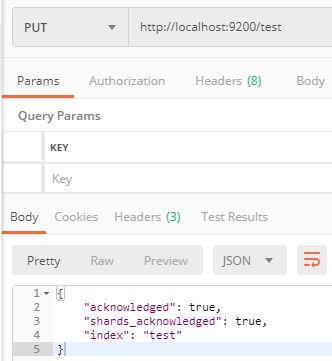
2、 1、首先创建一个名为test的索引:http://localhost:9200/test;
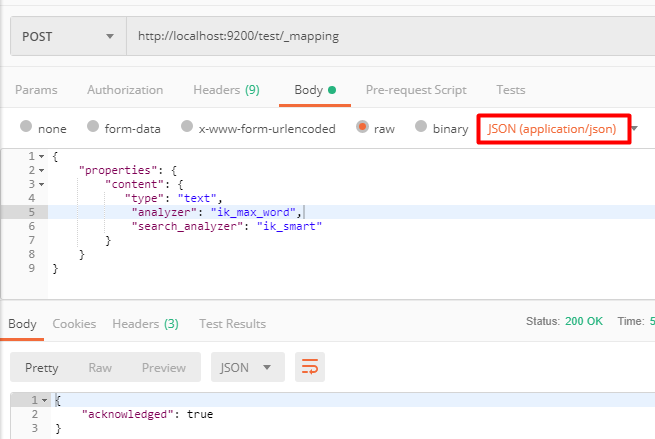
2、 2、接着,创建test索引的Mapping,定义一些基本信息:**http://localhost:9200/test/_mapping,**注意要使用POST请求和JSON格式文本;
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
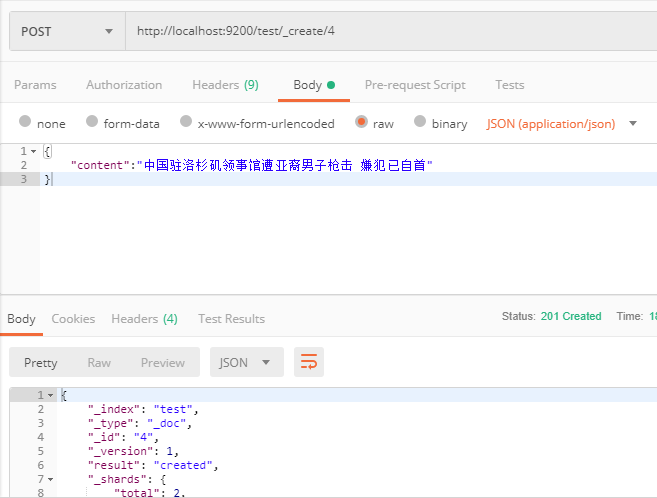
2、 3、分别输入一些文本内容:http://localhost:9200/test/_create/1;
{"content":"美国留给伊拉克的是个烂摊子吗"}
{"content":"公安部:各地校车将享最高路权"}
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
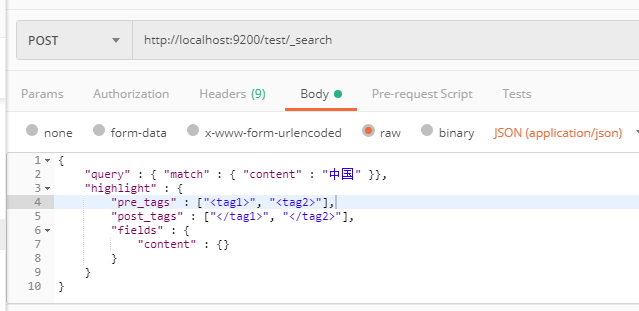
2、 4、最后使用highlighting方式进行检索:http://localhost:9200/test/_search;
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
请求结果:
{
"took": 350,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.642793,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "3",
"_score": 0.642793,
"_source": {
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
},
"highlight": {
"content": [
"中韩渔警冲突调查:韩警平均每天扣1艘<tag1>中国</tag1>渔船"
]
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "4",
"_score": 0.642793,
"_source": {
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
},
"highlight": {
"content": [
"<tag1>中国</tag1>驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
]
}
}
]
}
}
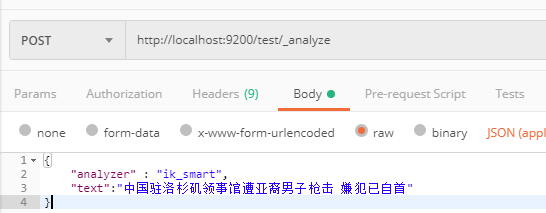
2、 5、也可以直接使用ik_smart分析器进行分词测试:http://localhost:9200/test/_analyze;
分词结果:
{
"tokens": [
{
"token": "中国",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "驻",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 1
},
{
"token": "洛杉矶",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "领事馆",
"start_offset": 6,
"end_offset": 9,
"type": "CN_WORD",
"position": 3
},
{
"token": "遭",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 4
},
{
"token": "亚裔",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 5
},
{
"token": "男子",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 6
},
{
"token": "枪击",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 7
},
{
"token": "嫌犯",
"start_offset": 17,
"end_offset": 19,
"type": "CN_WORD",
"position": 8
},
{
"token": "已",
"start_offset": 19,
"end_offset": 20,
"type": "CN_CHAR",
"position": 9
},
{
"token": "自首",
"start_offset": 20,
"end_offset": 22,
"type": "CN_WORD",
"position": 10
}
]
}
3、自定义拓展词库
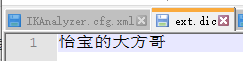
3、 1、本地拓展词库;
首先在ik/config目录下新建拓展字典文件,文件后缀名为.dic,如ext.dic。然后在字典中新增自定义分词,注意内容格式是一行一个分词。
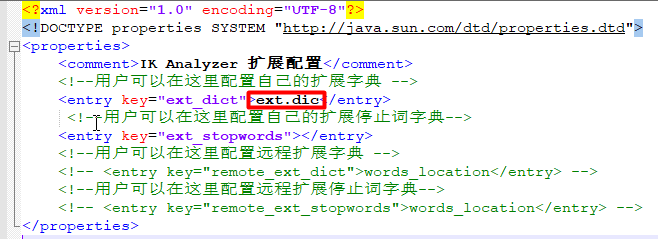
最后在ik/config/配置文件中配置拓展字典相对路径,重启es即可。
试试看效果:
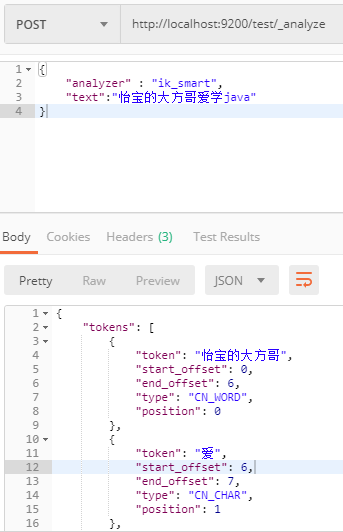
3、 2、远程拓展词库;
本地拓展词库有个弊端,就是每次更新词库之后都要重启es,而配置了远程词库后即可实现热更新。
我们新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 ext.dic 文件(注意是UTF-8编码格式),写入扩展词:
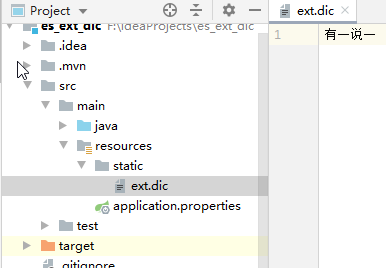
然后同样在ik/config/配置文件中配置静态远程拓展字典路径,配置完成后,重启 es 即可。
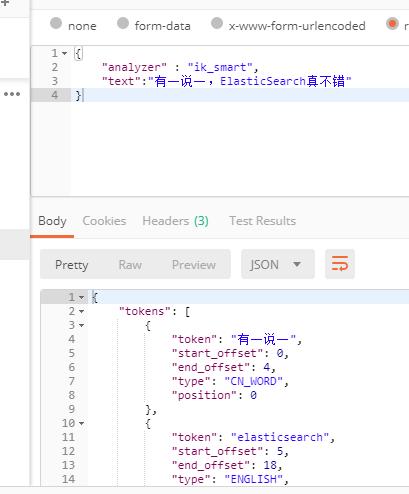
远程拓展字典接口只需要满足以下两点,即可实现热更新:
1、 该http请求需要返回两个头部(header),一个是Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库(httpserver会在客户端请求该文件时自动返回相应的Last-Modified和ETag);
2、 该http请求返回的内容格式是一行一个分词;
后续还可以根据业务需要,做一个工具或定时服务,定维护更新远程词库。
4、ik_max_word 和 ik_smart 的区别?
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
版权声明:
本文仅记录ElasticSearch学习心得,如有侵权请联系删除。
更多内容请访问原创作者:
微信公众号:江南一点雨 
B站:https://space.bilibili.com/49484631?from=search&seid=6136072956000981995
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: