一、Lucene
谈到搜索引擎基本都绕不开Lucene,作为一个开源、免费、高性能、纯 Java 编写的全文检索引擎,可以算作是开源领域最好的全文检索工具包。
不过Lucene只是一个工具包,并非完整的搜索引擎。而基于Lucene开发的完整搜索引擎有Solr、ElasticSearch,在分布式和大数据场景下,ElasticSearch更胜一筹。
Lucene主要特点:
- 简单
- 跨语言(除了java,还有C++、C#、Python等语言版本)
- 强大的搜索引擎
- 索引速度快
- 索引文件兼容不同平台
二、ElasticSearch
1、简介
ElasticSearch 基于 Java 编写,通过进一步封装 Lucene,将搜索的复杂性屏蔽起来,开发者只需要一套简单的 RESTful API 就可以操作全文检索。
ElasticSearch 在分布式环境下表现优异,支持 PB 级别的结构化或非结构化海量数据处理,这也是它比较受欢迎的原因之一。
ElasticSearch 的主要特点:
- 分布式文件存储。
- 实时分析的分布式搜索引擎。
- 高可拓展性。
- 可插拔的插件支持。
ElasticSearch 有三大功能:
- 数据搜集
- 数据分析
- 数据存储
2、安装
2.1、单节点安装
首先在ES官网上下载ElasticSearch,我们这里选择的是7.10版本
Es支持矩阵
将下载的文件解压,解压后的目录含义如下:
| 目录 | 含义 |
|---|---|
| modules | 依赖模块目录 |
| lib | 第三方依赖库 |
| logs | 输出日志目录 |
| plugins | 插件目录 |
| bin | 可执行文件目录 |
| config | 配置文件目录 |
| data | 数据存储目录 |
启动方式:进入到 bin 目录下,windows系统直接执行 elasticsearch.bat 启动即可,看到 started 表示启动成功。
ElasticSearch默认监听端口是9200,浏览器直接访问localhost:9200可以看到节点信息。
其中节点和集群的名字都可以自定义配置,打开 config/elasticsearch.yml 文件,添加以下配置:
cluster.name: amby-es
node.name: master
保存配置文件,重启Es后,刷新localhost:9200即可看到新的自定义节点和集群名字 。
2.2、HEAD工具安装
Elasticsearch-head 插件,可以通过可视化的方式查看集群信息,分别有Chrome浏览器插件安装和下载插件安装两种方式,这里我们选用下载插件安装方式。
首先从GitHub上下载ElasticSearch-head插件包,地址:https://github.com/mobz/elasticsearch-head,可以选择拉取到git,或者直接下载zip压缩包。
下载完成后,进入到ElasticSearch-head目录,首先执行 npm install 命令安装插件(使用 npm 命令需要安装 node.js)。
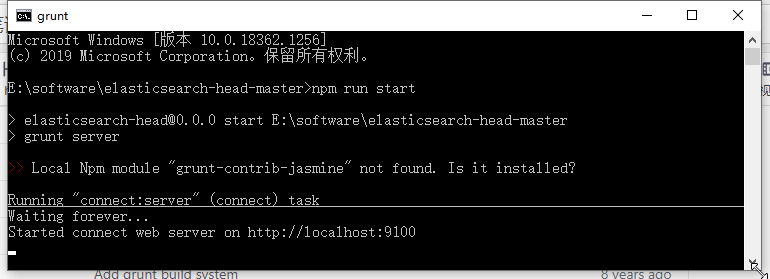
安装完成后,执行 npm run start 命令,启动插件。看到以下页面表示启动成功:
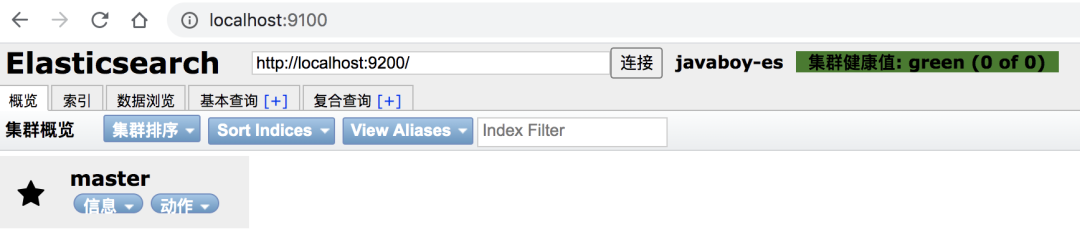
启动成功后,访问9100端口,页面如下:

**注意:**如果使用下载插件安装,此时看不到集群数据。原因在于这里通过跨域的方式请求集群数据的,默认情况下,集群不支持跨域,所以这里就看不到集群数据有跨域问题。需要在config/elasticsearch.yml 文件中添加以下配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后,重启 es,此时 head 上就有数据了。
2.3、分布式安装
我们以一主二从为例,master端口为9200,slave端口分别为9201和9202。
首先在master主机的config/elasticsearch.yml文件中添加以下配置:
node.master: true
network.host: 127.0.0.1
另外复制两份es压缩包,分别解压成slave01和slave02,分别在config/elasticsearch.yml文件中添加以下配置:
# 集群名称必须保持一致
cluster.name: amby-es
node.name: slave01
network.host: 127.0.0.1
http.port: 9201
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
# 集群名称必须保持一致
cluster.name: amby-es
node.name: slave02
network.host: 127.0.0.1
http.port: 9202
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
启动两台从机,就可以在head上看到集群信息了。
2.4、Kibana安装
Kibana 是一个 Elastic 公司推出的一个针对 es 的分析以及数据可视化平台,可以搜索、查看存放在 es 中的数据。
首先在官网下载Kibana:https://www.elastic.co/cn/kibana
解压后执行运行bin/kibana.bat文件启动,访问localhost:5601查看。因为我们是新安装的es还没有数据,可以选择初始化 es 提供的测试数据,也可以不使用。
注意,如果有修改过es的端口和地址,需要在config/kibana.yml文件中配置。
3、核心概念
1、 集群(Cluster):一个或多个节点组成一个集群,维护共同的数据,一起对外提供服务集群中所有节点必须要有共同的集群名字,可以在elasticsearc.yml文件中修改cluster.name在集群有三种状态:绿色(所有分片都能正常工作)、黄色(至少一个副本分片不能正常工作)、红色(集群不能正常工作);
2、 节点(Node):集群中的一个服务器就是一个节点,节点中会存储数据,同时参与集群的索引以及搜索功能将一个节点加入集群,只需要配置集群名即可;
3、 索引(Index):可以分两种,名词-具有相似特征文档的集合、动词-索引数据以及对数据索引操作;
4、 类型(Type):类型是索引上的逻辑分类或分区;
5、 文档(document):一个可以被索引的数据单元,例如一个用户的文档、一个产品的文档等等,文档都是JSON格式的;
6、 分片(Shards):索引都是存储在节点上,受限于节点的空间大小以及数据处理能力,需要对索引进行分片在创建索引的时候,需要指定分片的数量默认情况下,一个索引会自动创建1个分片,并且为每一个分片创建一个副本;
7、 副本(Replicas):对主分片的备份;
8、 Settings:对索引的定义信息;
9、 Mapping:保存了定义索引字段的存储类型、分词方式、是否存储等信息;
10、 Anzlyzer:字段分词方式的定义;
版权声明:
本文仅记录ElasticSearch学习心得,如有侵权请联系删除。
更多内容请访问原创作者:
微信公众号:江南一点雨 
B站:https://space.bilibili.com/49484631?from=search&seid=6136072956000981995
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: