欢迎支持笔者新作:《深入理解Kafka:核心设计与实践原理》和《RabbitMQ实战指南》,同时欢迎关注笔者的微信公众号:朱小厮的博客。

欢迎跳转到本文的原文链接:https://honeypps.com/mq/rabbitmq-monitor-3/
确保RabbitMQ能够健康的运行还不足以让人放松警惕。考虑这样一种情况:小明为小张创建了一个队列并绑定了一个交换器,之后某人由于疏忽而阴差阳错的删除了这个队列而无人得知,最后小张在使用这个队列的时候就会报出“NOT FOUND”的错误。如果这些在测试环境中发生,那么还可以弥补。如果在实际生产环境中,如果误删了一个队列,那必然会造成不可估计的影响。此时业务方如果正在使用这个队列,正常情况下会立刻报出异常,相关人员迅可以迅速做出动作以尽可能的降低影响。试想如果是一个定时任务调用此队列,并在深夜3点执行相应的逻辑,此时报出异常想必也会对相关人员造成不小的精神骚扰。
不止删除队列这一个方面,还有删除了一个交换;或者修改了绑定信息;亦或者是胡乱建立了一个队列绑定到现有的一个交换器中,同时又没有消费者订阅消费此队列,从而留下消息堆积的隐患等等都会对使用RabbitMQ服务的业务应用造成影响。所以对于RabbitMQ元数据的管理与监控也尤为重要。
许多应用场景是在业务逻辑代码中创建相应的元数据资源(交换器、队列以及绑定关系)并使用。对于排他的、自动删除的这类非高可靠性要求的元数据资源可以一定程度上忽略元数据变更的影响。但是对于两个非常重要的且通过消息中间件交互的业务应用,在使用相应的元数据资源时最好做相应的管控,如果一方或者其它方肆意的变更所使用的元数据必然对另一方造成不小的影响。管控的介入自然会降低消息中间件的灵活度,但是可以增强系统的可靠性。比如通过专用的“元数据审核系统”来配置相应的元数据资源,提供给业务方使用的用户只有可读和可写的权限,这样进一步可以降低风险。
非管控的元数据可以天马行空,业务方可以在这一时刻创建,下一时刻就删除,对其监控也无太大的意义。对于管控的元数据来说,监控的介入就会有意义也会有必要很多。虽然对于只有可读写权限的用户不能够变更元数据信息,也难免会被其他具有可配置权限的超级用户篡改。RabbitMQ中在创建元数据资源的时候是以一种声明的形式完成的:无则创建、有则不变,不过在对应的元数据存在的情况下,对其再次声明时使用不同的属性会报出相应的错误信息。我们可以利用这一特性来监控元数据的变更,通过定时程序来将记录中的元数据信息重新声明一次,查看是否有异常报出。不过这种方法非常具有局限性,只能增加元数据的信息,而不能减少。比如有一个队列没有消费者且以后也不会被使用,我们对其进行了解绑操作,这样就没有更多的消息流入而造成消息堆积,不过这一变更由于某些局限性没有及时将记录变更以通知到那个定时程序,此时又重新将此队列绑定到原交换器中。
这里列举一个简单的元数据管控及监控的示例来应对此种情况,此系统并非最优,但可以给读者在实际应用时提供一种解决对应问题的思路。
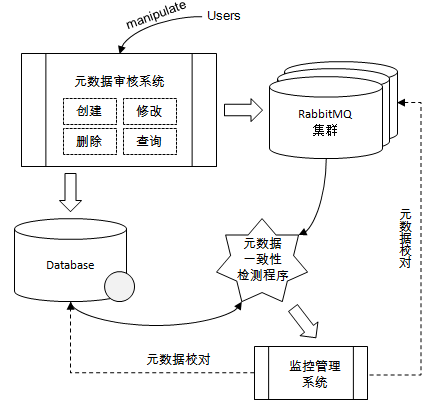
如图所示,所有的业务应用都需要通过元数据审核系统来申请创建(当然也可以包含查询、修改及删除)相应的元数据信息。在申请动作完成之后,由专门的人员进行审批,之后在数据库中存储和在RabbitMQ集群中创建相应的元数据,这两个步骤可以同时进行,且也无需为这两个动作添加强一致性的事务逻辑。在数据库和RabbitMQ集群之间会有一个元数据一致性校验程序用来检测出元数据不一致的地方,然后将不一致的数据上送到监控管理系统。监控管理系统中可以显示元数据不一致的记录信息,也可以以告警的形式推送出来,然后相应的管理人员可以选择手动或者自动的进行元数据修正。这里的不一致有可能是由于数据库的记录未被正确及时的更新,也有可能是RabbitMQ集群中元数据造异常篡改。元数据修正需慎之又慎,在整个系统修正逻辑完备之前,建议优先采用人工的方式,毕竟不一致的元数据仅占少数,人工修正的工作量并不太大。
RabbitMQ的元数据可以很顺利的以表的形式记录在数据库中,主要的元数据是“queues”、“exchanges”和“bindings”,可以分别建立三张表:
- Table 1:队列信息表,名称为rmq_queues。列名有name、vhost、durable、auto_delete、arguments、cluster_name、description。vhost表示虚拟主机。cluster_name表示队列所在的集群名称,毕竟一般一个公司所用的RabbitMQ集群并非只有一个。description是相应的描述信息,相当于备注,通常可置为空。
- Table 2:交换器信息表,名称为rmq_exchanges。列名有name、vhost、type、durable、auto_delete、internal、arguments、cluster_name、description。vhost、cluster_name和description可参考Table 1。
- Table 3:绑定信息表,名称为rmq_bindings。列名有source、vhost、destination、destination_type、routing_key、arguments、cluster_name、description。vhost、cluster_name和description可参考Table 1。
元数据一致性检测程序可以通过/api/definitions的HTTP API接口获取集群的元数据信息,通过解析之后与数据库中的记录一一比对,查看是否有不一致的地方。
欢迎跳转到本文的原文链接:https://honeypps.com/mq/rabbitmq-monitor-3/
欢迎支持笔者新作:《深入理解Kafka:核心设计与实践原理》和《RabbitMQ实战指南》,同时欢迎关注笔者的微信公众号:朱小厮的博客。

版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: