一.消费者组
消费者组: Consumer GRoup
- kafka提供可扩容且具有容错性的消费机制
- 组内有多个消费者和消费者 实例(Consumer Instance),共享公共ID(Group ID)
- 组内的所有消费者协调在一起消费订阅主题(Subscribed Topics)的所有分区(Partition)
- 每个分区只能由同一个消费者组内的一个Consumer实例来消费。
Consunmer Group 可以有一个或多个Consumer实例。
- 这里的实例是一个单独的进程,也可以是统一进程下的线程。实际场景,使用进程更为常见。
- Group ID 是一个字符串,在一个kafka集群中,它标识唯一一个Consumer Group。
- Consunmer Group 下所有实例订阅的主题的单个分区,只能分配给组内某个Consumer实例消费。这个分区当然也被其他的Group消费。
二.传统两种模型:
点对点模型/订阅模型
传统消息缺陷:
-
一旦被消费,就会从队列中被删除,只能被下游的一个Consumer消费;
订阅模型
- 下游多个Consumer都要枪这个共享消息队列的消息。
- 发布/订阅模型允许消息被多个Consumer消费,但是伸缩性不高,每个订阅者必须要订阅主题的所有分区,这种全量订阅的方式及不灵活也会影响消息真实的投递效果
- Consumer Group订阅多个主题后,组内每个实例都不要求一定要订阅主题的所有分区,他只会消费部分分区中的消息。
- Consumer Group之间彼此独立,互不影响,他们能够订阅相同的一组主题而互不干涉。
- Broker端的留存机制 完美规避伸缩性差的问题;
如果实例都属于同一个Group,那么它实现的就是消息队列模型
如果所有实例分别属于不同的Group,那么它属于发布/订阅模型 ####
三.一个Group下该有多少个consumer实例:
Consumer实例的数量应该等于该Group订阅的主题的分区总数。
例子:
-
Consumer Group订阅了3个主题分别是A,B,C
-
他们的分区数分别是1,2,3 总共是6个分区
-
那么为该GRoup设置6个Consumer实例比较理想,能最大限度实现高伸缩。
-
你有3个实例,那么平均下来每个实例大约消费2个分区(6/3=2)
-
如果设置了8个实例,那么有2个实例不会被分配任何分区,永远处于空闲状态
-
实际使用过程中,不建议设置大于总分区数的Consumer实例
-
设置多余的实例只会浪费资源
四.kafka如何管理消费组的位移:
1、 位移(Offset):消费者在消费的过程中记录自己消费到的位置信息;
2、 ConsumerGroup端重平衡也就是Rebalance过程;
3、 Rebalance本质上是一种协议,规定ConsumerGroup下的所有Consumer如何达成一致,来分配订阅Topic的每个分区;
比如某个Group下有20个consumer实例,他订阅了一个具有 100个分配的Topic。
正常情况下,kafka平均会为每个consumer分配5个分区这个分配的分配叫Rebalance;
那么consumer Group何时进行 Rebalance?
1、 组成员数发生变更:组成员发生变更:比如新的Consumer实例加入组或者离开组,抑或是有写consumer实例崩溃被剔除组;
2、 订阅主题数发生变更ConsumerGroup可以使用正则表达式的方式订阅主题比如consumer.subscribe(Pattern.compile("t.*c"))该Group订阅所有以字母t开头,字母c结尾的主题就会发生Rebalance;;
3、 订阅主题的分区数发生变更Kafka当前只能允许增加一个主题的分区数当分区数增加时,就会触发订阅该主题的所有Group开启Rebalance;
简单的例子:
Consumer Group发生Rebalance 过程 ####
假设目前consumer Group下有两个consumerA和B。假设成员C加入就会触发kafka Rebalance
并根据默认的分配 策略重新为A B和 C分配分区
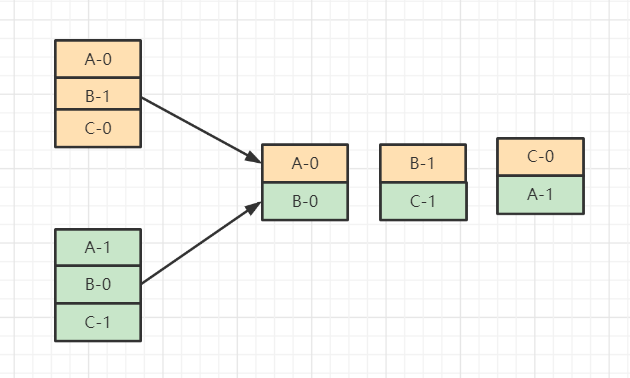
五.Rebalance的缺点:
- Rebalance过程对Consumer Group消费过程有着极大的影响
- 所有consumer实例都会停止消费,等待Reblance完成
- Rebalance的设计是 所有consumer实例共同参与,全部重新分配所有分区;
- 更高效的做法是尽量减少分配方案的变动。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: