一.主题(Topic)
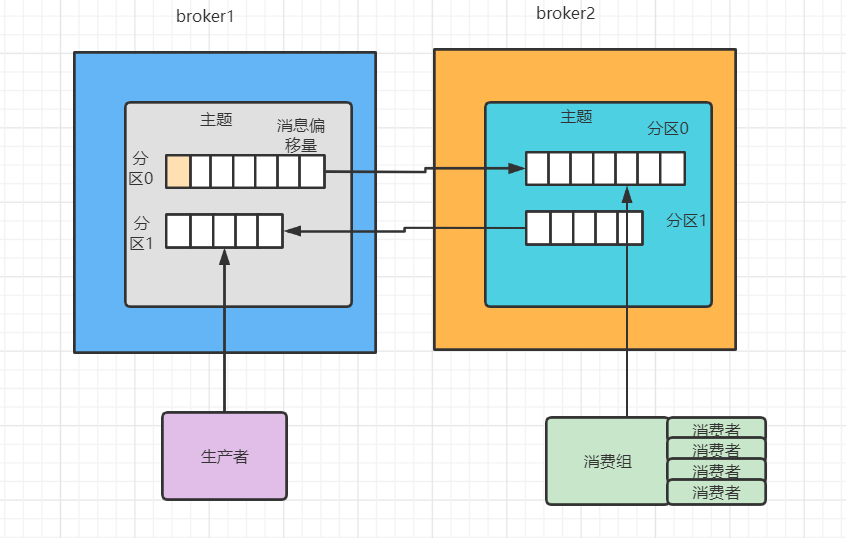
- 主题(Topic):发布订阅的对象,我们可以为每个业务,每个应用甚至是每类数据都创建专属的主题。
- 生产者(Producer):向主题发布消息的客户端应用程序,生产者程序通常持续不断的向一个或多个主题发送消息。
- 消费者(Consumer)订阅这些主题消息的客户都安应用程序;消费者也能同时订阅多个主题消息。
- 我们把生产者和消费者统称为客户端(clients)
- 同时运行多个生产者和消费者实例。这些实例会不断向kafka集群中的多个主题生产和消费消息。
二.Broker
- Broker:Kafka服务器端由Broker的服务进程构成;
- 一个Kafka集群由多个Broker组成,Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化。
三.备份机制(Repliacation)
- 备份的思想:将相同的数据拷贝再多台机器上,而这相同数据拷贝在Kafka中被称为副本(Replica)
- Kafka定义了两类副本:领导者副本(Leader Peplica)和追随者副本(Follower Replica)
- 前者对外提供服务,指的是与客户端程序进行交互;
- 后端只能复制领导者副本,不能与外界进行交互。
- 很多其他系统中追随者副本是可以对外提供服务,比如MySQl的从库是可以处理读操作,但是Kafka副本不会对外提供服务。
副本的工作机制
生产者
- 生产者总是向领导者副本写操作;而消费者总是从领导者副本读消息。
- 追随者副本,只会请求领导把最新生产的消息发送给它,让他与领导者保存同步。
四.伸缩性Scalability
- 伸缩性:领导者副本积累很多数据,导致单台Broker机制都无法容纳,将数据分割成多份保存在不同Broker上。
- 分区(prartitioning):
- KafKa分区机制:将每个主题划分成多个分区(Partion),每个分区是一组有序的消息日志
- 生产者生产的每条消息都只会被发送到一个分区中,也就是向一个双分区主题发送一条消息,这条消息要么在分区0要么在分区1中。
- kafka分区编号是从0开始的,如果Topic有100个分区,那么他们的分区号是0到99.
五.副本与分区的关系
- 实际上,副本是在分区层级上定义的。每个分区都可以配置若干个副本,其中只能有一个领导者副本和N-1个追随者副本。
- 生产者像分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表证
- 分区位移从0开始,假设一个生产者向一个空分区写入10条消息,那么这10条消息位移依次是0,1,2,3.....,9
六.kafka的三层消息架构:
- 第一层:主题层,每个主题可以配置M个分层,而每个分区又可以配置N个副本。
- 第二层:分层区,每个分区的N个副本只能有一个充当领导者的脚本,对外提供服务;
- 其他N-1个副本是追随者副本,只是提供数据冗余之用。
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增。
- 客户端只与分区的领导副本交互。
七.Kafka Broker 持久化数据
- kafka使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件
- 因为只能追加写入,避免了缓慢的随机I/O操作,改为性能较好的顺序I/O写操作----这是实现Kafka高吞吐量特性的重要手段。
八.kafka如何定期删除消息以及回收磁盘?
- 通过日志段(Log Segment)机制。在Kafka底层,一个日志又进一步细分成多个日志段;
- 消息被追加写到当前最新的日志段,当写满一个日志段后,kafka会自动切分出一个新的日志段,将老的日志段封存起来。
- Kafka在后台有定时任务定期检查老的日志段是否能够删除,从而实现回收磁盘空间的目的。
九.消费者组
- 消费者组(Consumer Group):多个消费者实例共同组成一个组来消费一组主题
- 这个组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费他。
为什么要引入消费者组:
- 提升消费者端的吞吐量,多个消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS);
kafka重平衡
- 消费者组里面的所有消费者实例可以"瓜分"订阅主题的数据
- 还可以彼此协调:
- 组内某个实例挂掉,kafka能够自动检测到,将failed实例之前负责的分区转移给其他活着的实例,这就是大名鼎鼎的重平衡。
十.小结:
- 消息:Record:kafka是消费引擎他,这里的消息是指kafka处理的主要对象。
- 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体业务。
- 分区:partiton:一个有序不变的消息序列。每个主题下有多个分区。
- 消息位移:Offset:标识分区中每个消息的位置信息,是一个单调递增且不变的值。
- 副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
- 生产者:Producer。向主题发布新消息的应用程序。
- 消费者:Consumer。从主题订阅新消息的应用程序。
- 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
- 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
十一.Kafka 不像 MySQL 那样允许追随者副本对外提供读服务
- 1,kafka的分区已经让读是从多个broker读从而负载均衡,不是MySQL的主从,压力都在主上;
- 2,kafka保存的数据和数据库的性质有实质的区别就是数据具有消费的概念,是流数据,kafka是消息队列,所以消费需要位移,而数据库是实体数据不存在这个概念,如果从kafka的follower读,消费端offset控制更复杂;
- 3,生产者来说,kafka可以通过配置来控制是否等待follower对消息确认的,如果从上面读,也需要所有的follower都确认了才可以回复生产者,造成性能下降,如果follower出问题了也不好处理
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: