目录
1Redis数据结构-动态字符串
2Redis数据结构-intset
编辑小总结:
3Redis数据结构-Dict
小总结:
4Redis数据结构-ZipList
5Redis数据结构-QuickList
小总结:
7Redis数据结构-SkipList
小总结:
8Redis数据结构-RedisObject
9五种数据结构
1 Redis数据结构-动态字符串
我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。
不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题:
1、 获取字符串长度的需要通过运算;
2、 非二进制安全;
3、 不可修改;
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。


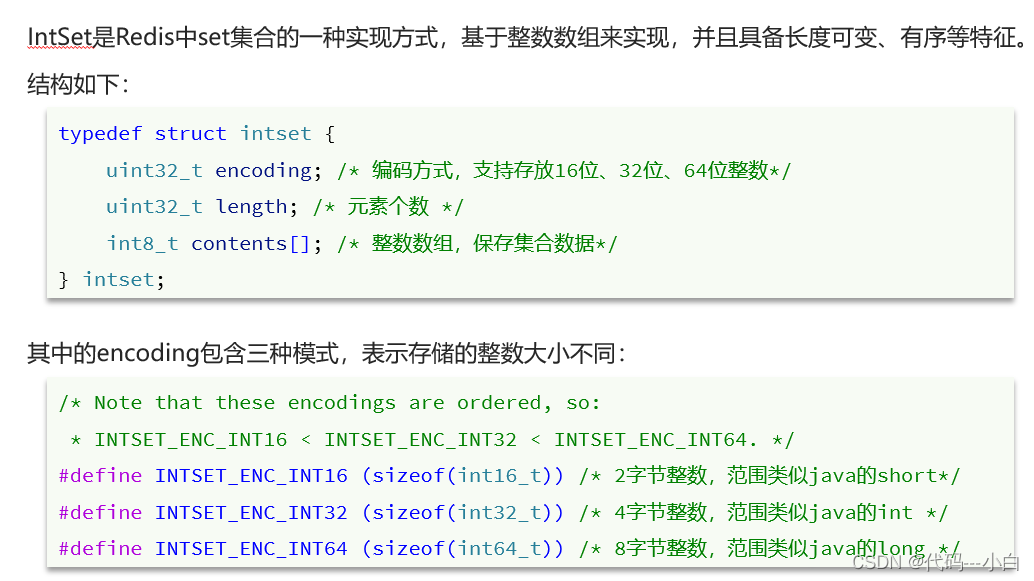
2 Redis数据结构-intset
 小总结:
小总结:
Intset可以看做是特殊的整数数组,具备一些特点:
- Redis会确保Intset中的元素唯一、有序
- 具备类型升级机制,可以节省内存空间
- 底层采用二分查找方式来查询
3 Redis数据结构-Dict
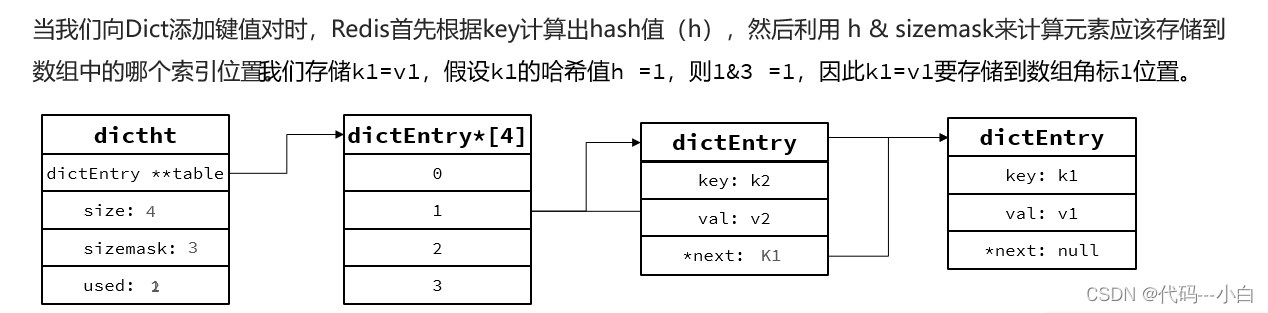
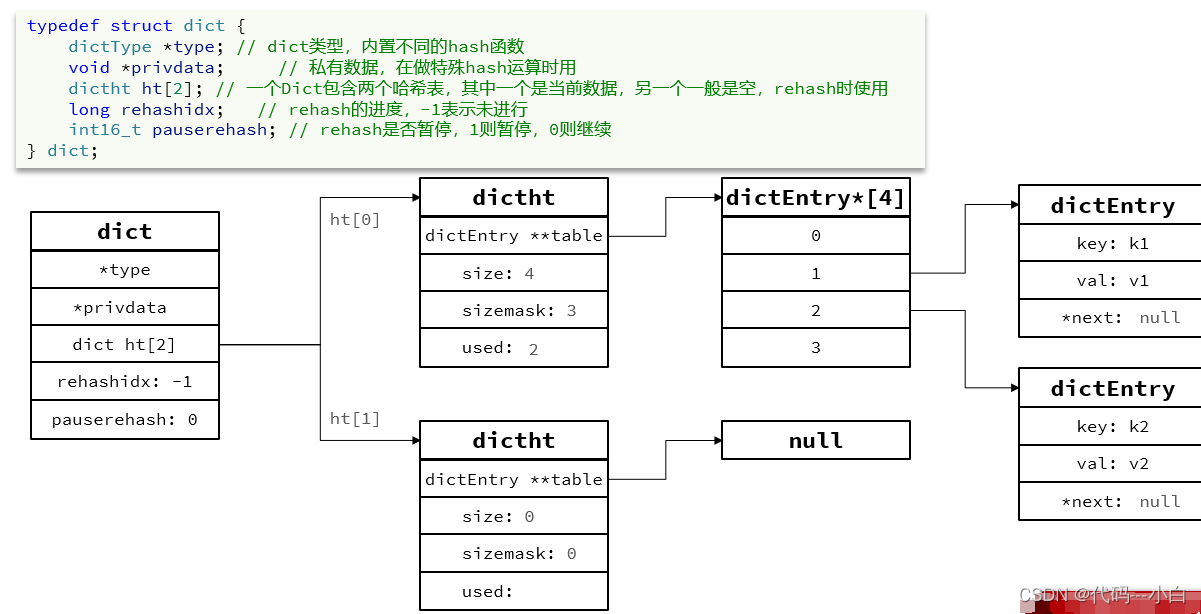
我们知道Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。 Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)。
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
u哈希表的 LoadFactor >= 1 ,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
u哈希表的 LoadFactor > 5 ;
Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
-
计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
-
如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
-
如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
-
按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
-
设置dict.rehashidx = 0,标示开始rehash
-
将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
-
将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
-
将rehashidx赋值为-1,代表rehash结束
-
在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空

小总结:
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used + 1的2^n
- 收缩大小为第一个大于等于used 的2^n
- Dict采用渐进式rehash,每次访问Dict时执行一次rehash
- rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
4 Redis数据结构-ZipList
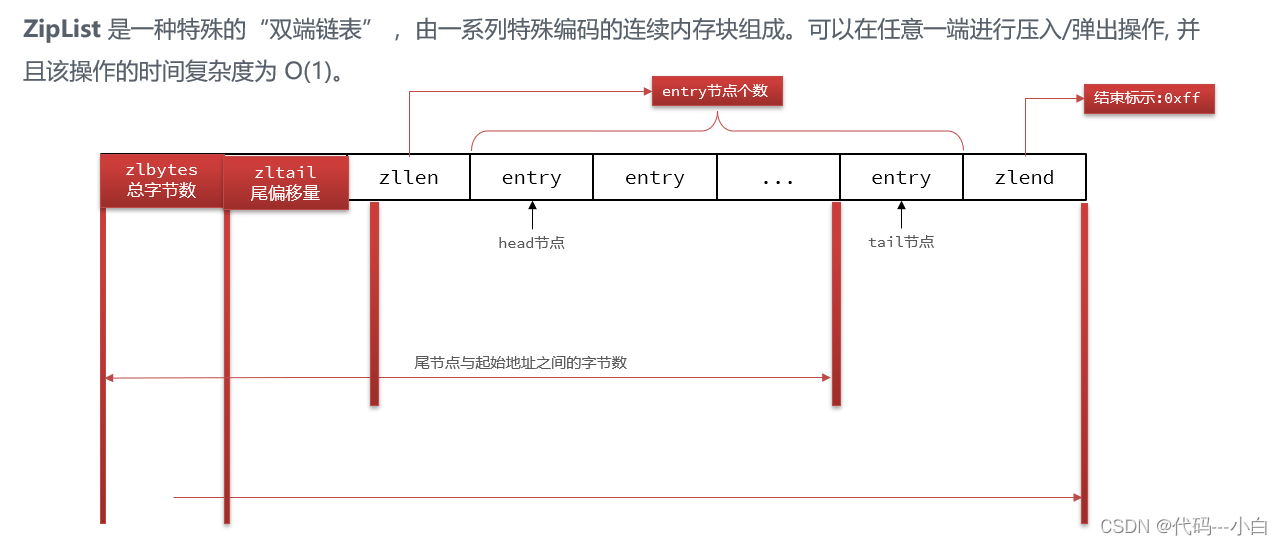
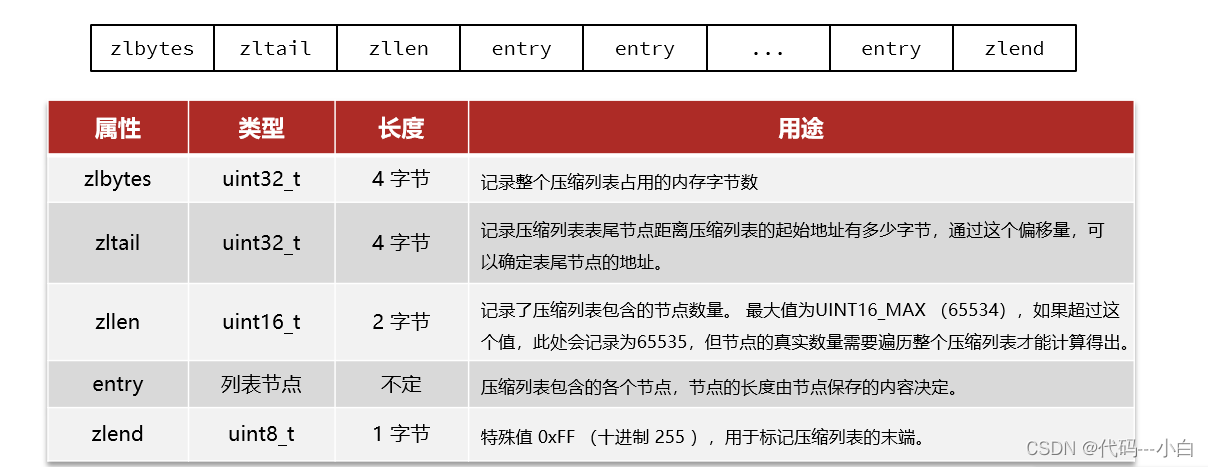

ZipList的每个Entry都包含previousentrylength来记录上一个节点的大小,长度是1个或5个字节: 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据 现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previousentrylength属性用1个字节即可表示,如图所示:
ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
小总结:
ZipList特性:
- 压缩列表的可以看做一种连续内存空间的"双向链表"
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
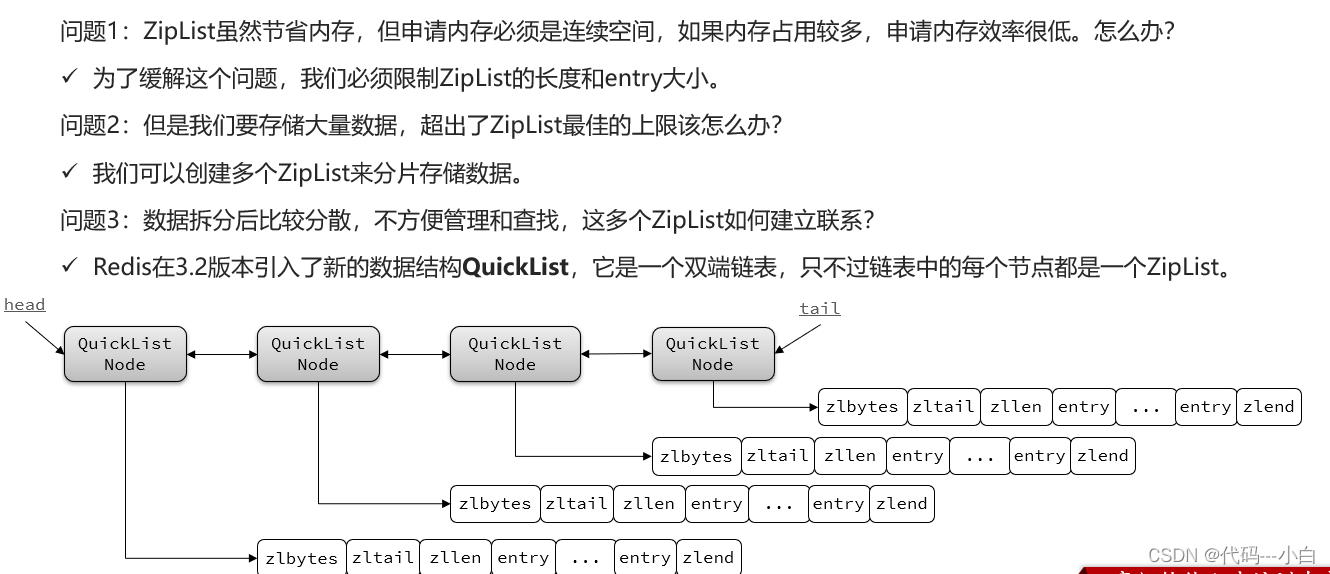
5 Redis数据结构-QuickList
小总结:
SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
7 Redis数据结构-SkipList
SkipList(跳表)首先是链表,但与传统链表相比有几点差异: 元素按照升序排列存储 节点可能包含多个指针,指针跨度不同。
小总结:
SkipList的特点:
- 跳跃表是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序,score值一样则按照ele字典排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
8 Redis数据结构-RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象,源码如下:
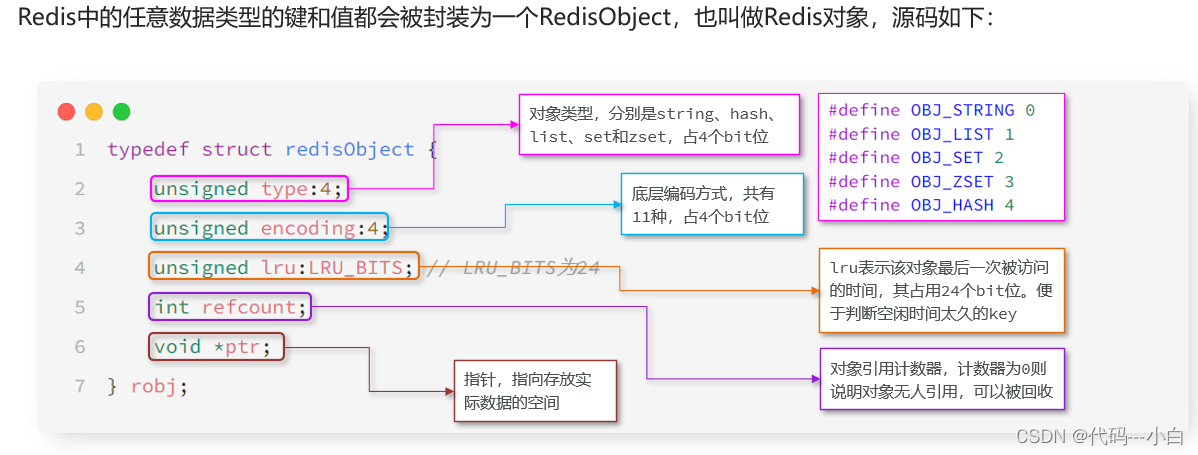
1、 什么是redisObject:从Redis的使用者的角度来看,⼀个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从keyspace到objectspace的映射关系这个映射关系的key是string类型,⽽value可以是多种数据类型,比如:string,list,hash、set、sortedset等我们可以看到,key的类型固定是string,而value可能的类型是多个⽽从Redis内部实现的⾓度来看,database内的这个映射关系是用⼀个dict来维护的dict的key固定用⼀种数据结构来表达就够了,这就是动态字符串sds而value则比较复杂,为了在同⼀个dict内能够存储不同类型的value,这就需要⼀个通⽤的数据结构,这个通用的数据结构就是robj,全名是redisObject;
9 五种数据结构

参考文献:
有一说一,黑马老师的这个Reids这个课程真的很顶,目前见过性价比最高的一个Redis讲解课程。 黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目_哔哩哔哩_bilibili
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: