目录
1、 1全局唯一ID;
1、 2Redis实现全局唯一Id;
1、 3实现秒杀下单;
1、 4库存超卖问题分析;
1、 5乐观锁解决超卖问题;
1、 6优惠券秒杀——一人一单功能;
1、 7集群环境下的并发问题;
1、 8集群环境下的并发问题解决方案——分布式锁;
1、 8.1基本原理和实现方式对比;
1、 8.2Redis分布式锁的实现核心思路;
1、 8.3实现分布式锁的版本一;
1、 8.3.1Redis分布式锁误删情况说明;
1、 8.3.2解决Redis分布式锁误删问题;
1、 8.3.3分布式锁的原子性问题;
1、 8.3.4Lua脚本解决多条命令原子性问题;
小总结:
1、 8.4实现分布式锁的版本二(Redission);
1、 8.4.1分布式锁-redission可重入锁原理;
1、 8.4.2分布式锁-redission锁重试原理;
小总结:
1、 8.4.3分布式锁-redission的MutiLock原理;
Redission总结:
1、 9秒杀优化;
1、 9.1秒杀优化-异步秒杀思路;
1、 9.2秒杀优化-Redis完成秒杀资格判断;
1、 9.3秒杀优化-基于阻塞队列实现秒杀优化;
1、 10Redis消息队列;
1、 10.1Redis消息队列-认识消息队列;
1、 10.2Redis消息队列-基于List实现消息队列;
1、 10.3Redis消息队列-基于PubSub的消息队列;
1、 10.4Redis消息队列-基于Stream的消息队列;
1、 10.5Redis消息队列-基于Stream的消息队列-消费者组;
1、 10.6Redis消息队列实现方式的对比分析;
1.1 全局唯一ID
每个店铺都可以发布优惠券
当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题:
①id的规律性太明显
②受单表数据量的限制
场景分析一:如果我们的id具有太明显的规则,用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
场景分析二:随着我们商城规模越来越大,mysql的单表的容量不宜超过500W,数据量过大之后,我们要进行拆库拆表,但拆分表了之后,他们从逻辑上讲他们是同一张表,所以他们的id是不能一样的, 于是乎我们需要保证id的唯一性。
全局ID生成器,是一种在分布式系统下用来生成全局唯一ID的工具,一般要满足下列特性:
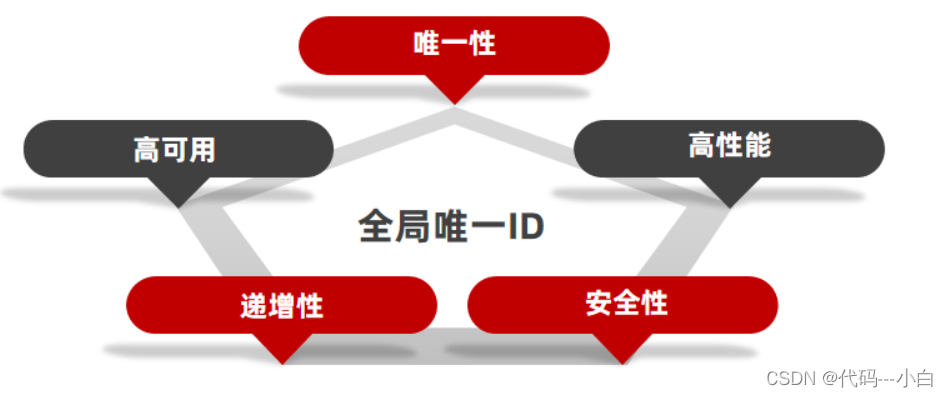
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年
序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
1.2 Redis实现全局唯一Id
知识小贴士:关于countdownlatch
countdownlatch名为信号枪:主要的作用是同步协调在多线程的等待于唤醒问题
我们如果没有CountDownLatch ,那么由于程序是异步的,当异步程序没有执行完时,主线程就已经执行完了,然后我们期望的是分线程全部走完之后,主线程再走,所以我们此时需要使用到CountDownLatch
CountDownLatch 中有两个最重要的方法
1、 countDown;
2、 await;
await 方法 是阻塞方法,我们担心分线程没有执行完时,main线程就先执行,所以使用await可以让main线程阻塞,那么什么时候main线程不再阻塞呢?当CountDownLatch 内部维护的 变量变为0时,就不再阻塞,直接放行,那么什么时候CountDownLatch 维护的变量变为0 呢,我们只需要调用一次countDown ,内部变量就减少1,我们让分线程和变量绑定, 执行完一个分线程就减少一个变量,当分线程全部走完,CountDownLatch 维护的变量就是0,此时await就不再阻塞,统计出来的时间也就是所有分线程执行完后的时间。
1.3 实现秒杀下单
下单核心思路:当我们点击抢购时,会触发右侧的请求,我们只需要编写对应的controller即可
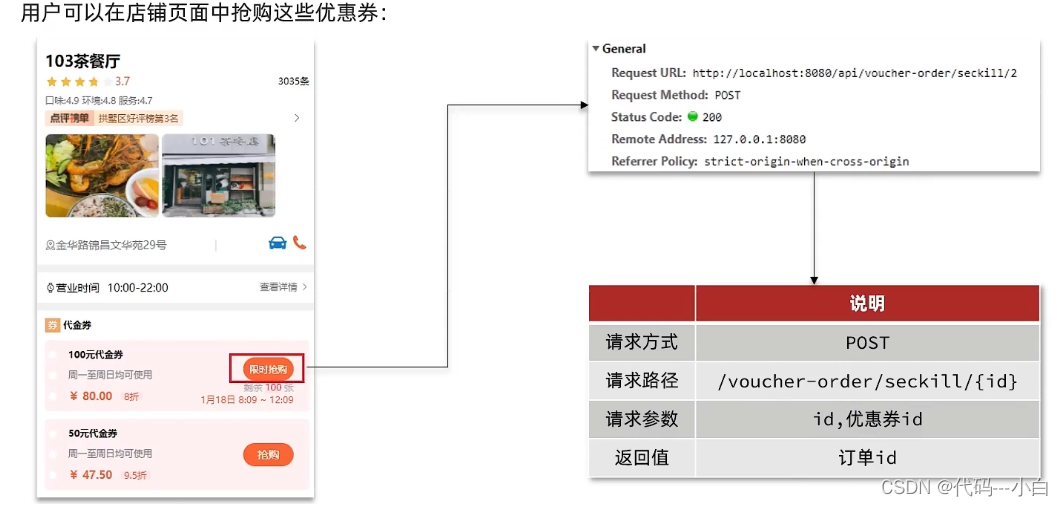
秒杀下单应该思考的内容:
下单时需要判断两点:
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
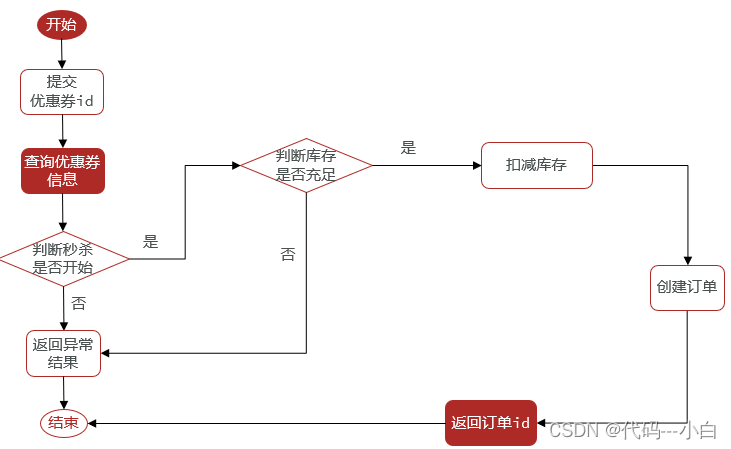
下单核心逻辑分析:
当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件
比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。
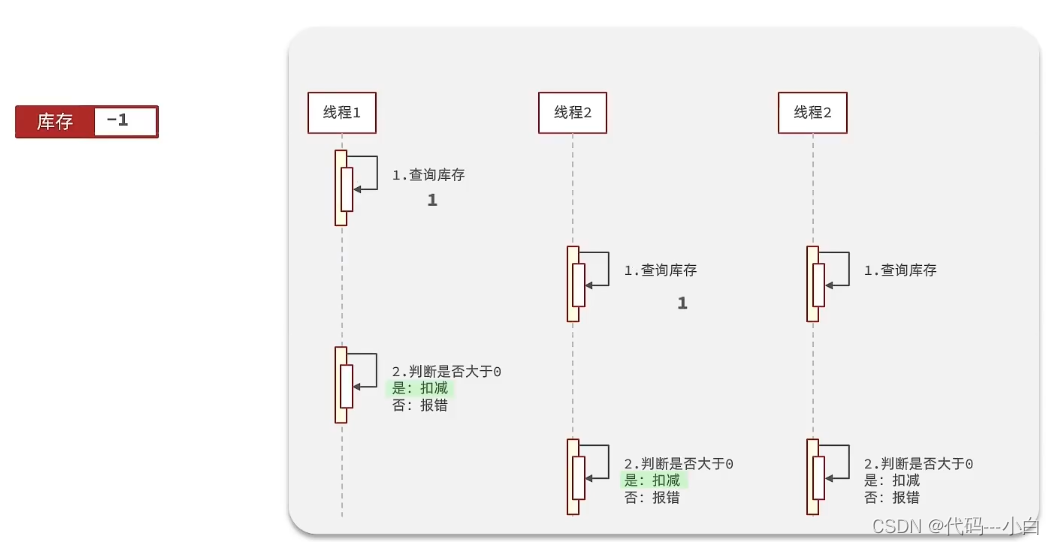
1.4 库存超卖问题分析
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,此时就会出现库存的超卖问题。
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案:见下图:
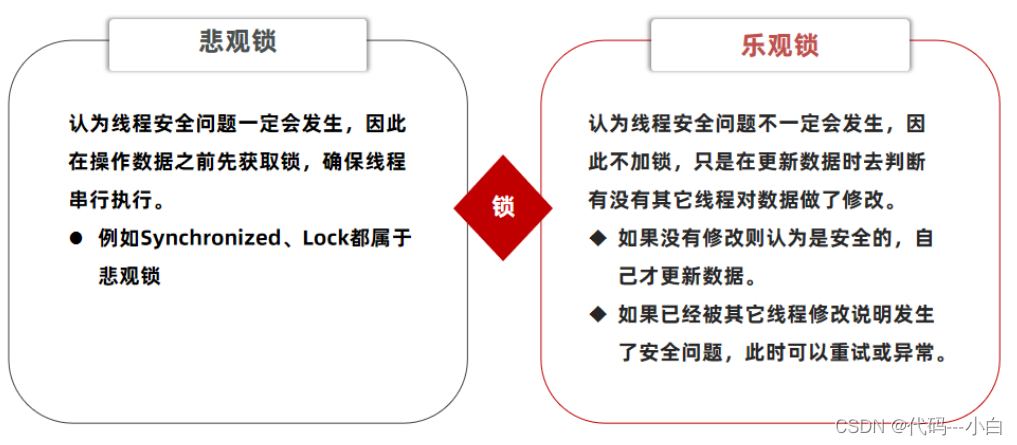
悲观锁:
悲观锁可以实现对于数据的串行化执行,比如syn,和lock都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等。
乐观锁:
乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas。
乐观锁的典型代表:就是cas,利用cas进行无锁化机制加锁,var5 是操作前读取的内存值,while中的var1+var2 是预估值,如果预估值 == 内存值,则代表中间没有被人修改过,此时就将新值去替换 内存值。
乐观锁的关键是判断之前查询得到的数据是否有被修改过,常见的方式有两种:
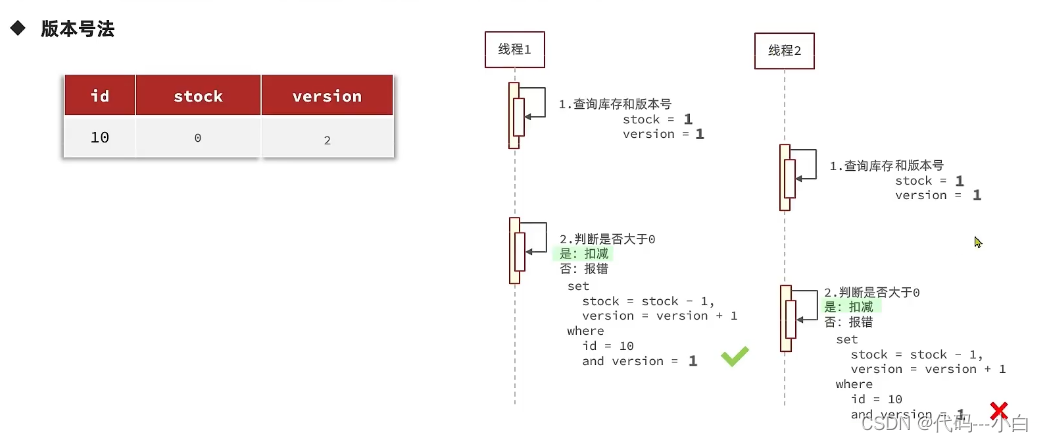
1.5 乐观锁解决超卖问题
修改代码方案一、
逻辑的核心含义是:只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的,但是以上这种方式通过测试发现会有很多失败的情况,失败的原因在于:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败。
修改代码方案二、
之前的方式要修改前后都保持一致,但是这样我们分析过,成功的概率太低,所以我们的乐观锁需要变一下,改成stock大于0 即可。
知识小扩展:
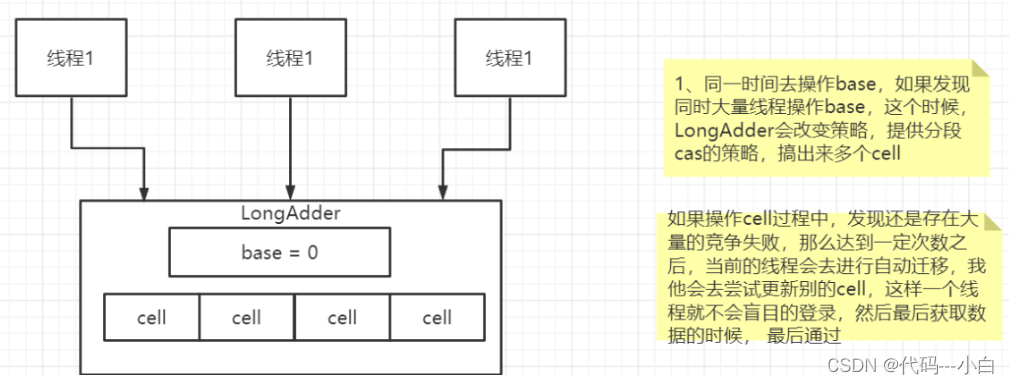
针对cas中的自旋压力过大,我们可以使用Longaddr这个类去解决
Java8 提供的一个对AtomicLong改进后的一个类,LongAdder
大量线程并发更新一个原子性的时候,天然的问题就是自旋,会导致并发性问题,当然这也比我们直接使用syn来的好
所以利用这么一个类,LongAdder来进行优化
如果获取某个值,则会对cell和base的值进行递增,最后返回一个完整的值。
1.6 优惠券秒杀——一人一单功能
需求:修改秒杀业务,要求同一个优惠券,一个用户只能下一单。
现在的问题在于:
优惠卷是为了引流,但是目前的情况是,一个人可以无限制的抢这个优惠卷,所以我们应当增加一层逻辑,让一个用户只能下一个单,而不是让一个用户下多个单
具体操作逻辑如下:比如时间是否充足,如果时间充足,则进一步判断库存是否足够,然后再根据优惠卷id和用户id查询是否已经下过这个订单,如果下过这个订单,则不再下单,否则进行下单。
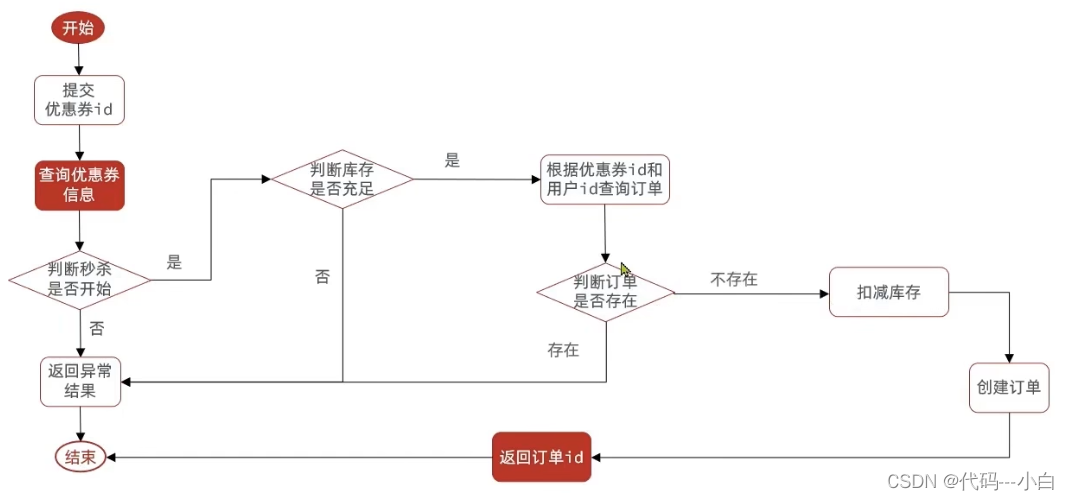
**存在问题:**现在的问题还是和之前一样,并发过来,查询数据库,都不存在订单,所以我们还是需要加锁,但是乐观锁比较适合更新数据,而现在是插入数据,所以我们需要使用悲观锁操作
**注意:**在这里提到了非常多的问题,我们需要慢慢的来思考,首先我们的初始方案是封装了一个createVoucherOrder方法,同时为了确保他线程安全,在方法上添加了一把synchronized 锁。
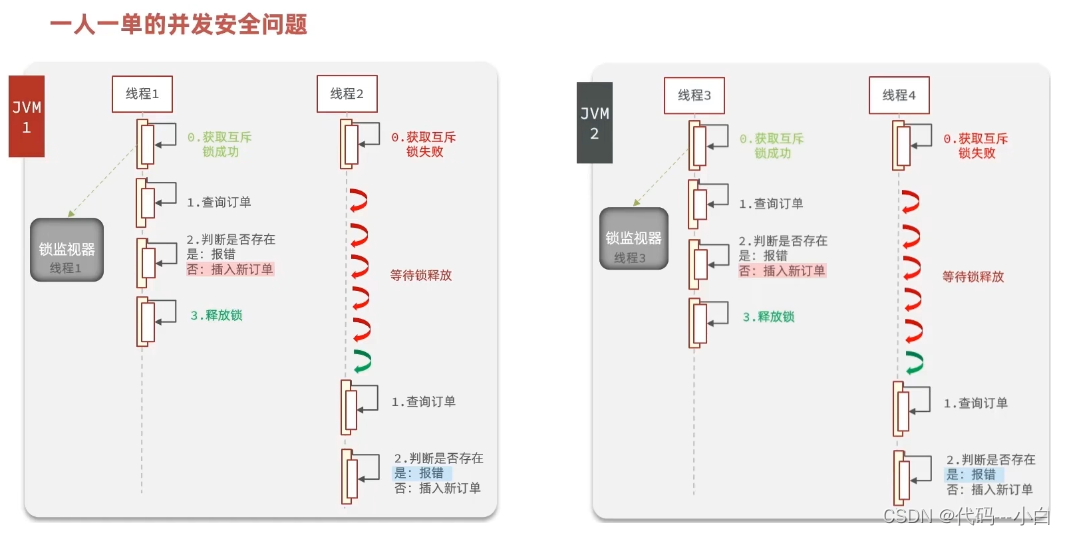
1.7 集群环境下的并发问题
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了。
1、 我们将服务启动两份,端口分别为8081和8082:;

2、 然后修改nginx的conf目录下的nginx.conf文件,配置反向代理和负载均衡:;

有关锁失效原因分析:
由于现在我们部署了多个tomcat,每个tomcat都有一个属于自己的jvm,那么假设在服务器A的tomcat内部,有两个线程,这两个线程由于使用的是同一份代码,那么他们的锁对象是同一个,是可以实现互斥的,但是如果现在是服务器B的tomcat内部,又有两个线程,但是他们的锁对象写的虽然和服务器A一样,但是锁对象却不是同一个,所以线程3和线程4可以实现互斥,但是却无法和线程1和线程2实现互斥,这就是 集群环境下,syn锁失效的原因,在这种情况下,我们就需要使用分布式锁来解决这个问题。
1.8 集群环境下的并发问题解决方案——分布式锁
1.8.1 基本原理和实现方式对比
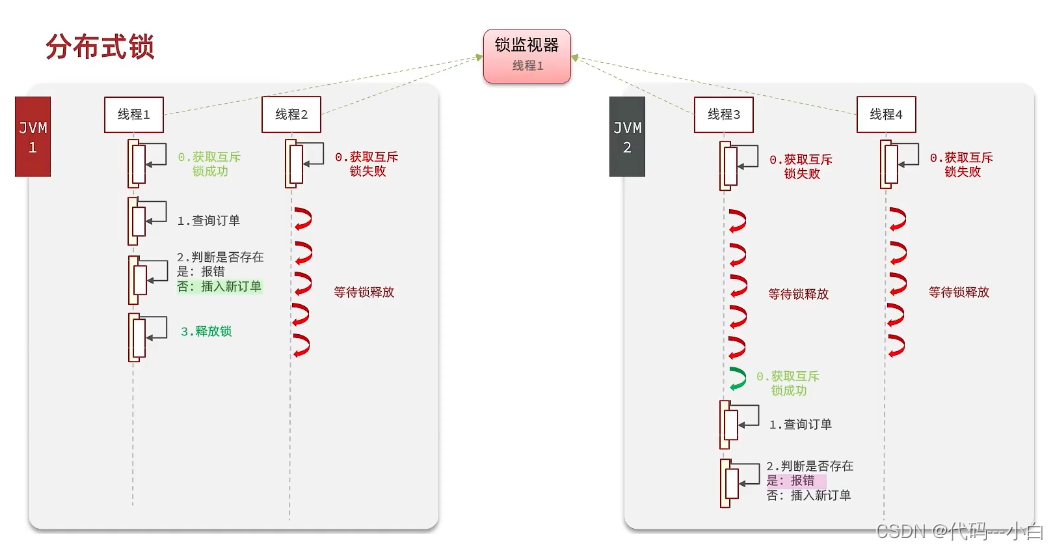
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的核心思想就是让大家都使用同一把锁,只要大家使用的是同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路。
那么分布式锁他应该满足一些什么样的条件呢?
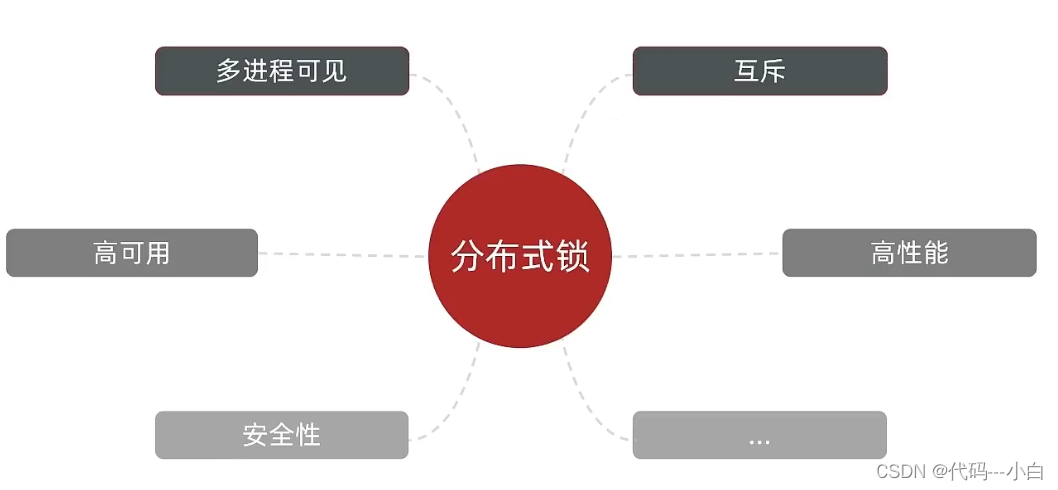
可见性:多个线程都能看到相同的结果,注意:这个地方说的可见性并不是并发编程中指的内存可见性,只是说多个进程之间都能感知到变化的意思;
互斥:互斥是分布式锁的最基本的条件,使得程序串行执行;
高可用:程序不易崩溃,时时刻刻都保证较高的可用性;
高性能:由于加锁本身就让性能降低,所有对于分布式锁本身需要他就较高的加锁性能和释放锁性能;
安全性:安全也是程序中必不可少的一环。
常见的分布式锁有三种:
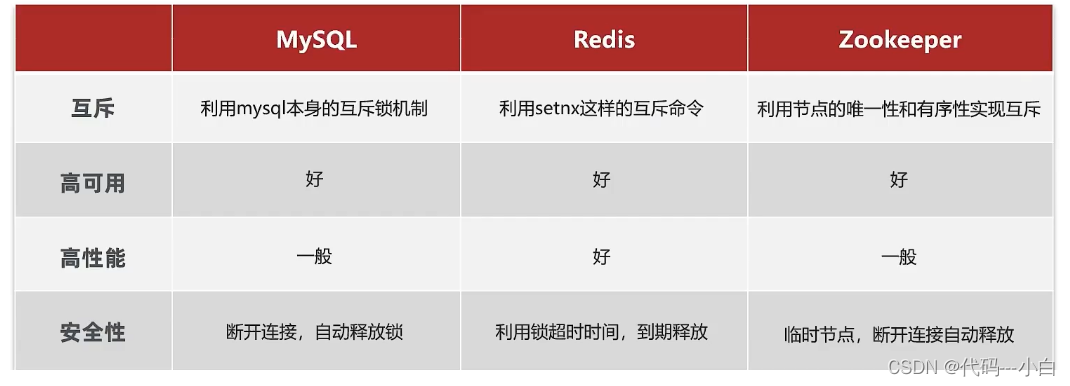
Mysql:mysql本身就带有锁机制,但是由于mysql性能本身一般,所以采用分布式锁的情况下,其实使用mysql作为分布式锁比较少见。
Redis:redis作为分布式锁是非常常见的一种使用方式,现在企业级开发中基本都使用redis或者zookeeper作为分布式锁,利用setnx这个方法,如果插入key成功,则表示获得到了锁,如果有人插入成功,其他人插入失败则表示无法获得到锁,利用这套逻辑来实现分布式锁。
Zookeeper:zookeeper也是企业级开发中较好的一个实现分布式锁的方案,由于本套视频并不讲解zookeeper的原理和分布式锁的实现,所以不过多阐述。
1.8.2 Redis分布式锁的实现核心思路
实现分布式锁时需要实现的两个基本方法:
-
获取锁:
-
互斥:确保只能有一个线程获取锁
-
非阻塞:尝试一次,成功返回true,失败返回false
-
释放锁:
-
手动释放
-
超时释放:获取锁时添加一个超时时间
核心思路:
我们利用redis 的setNx 方法,当有多个线程进入时,我们就利用该方法,第一个线程进入时,redis 中就有这个key 了,返回了1,如果结果是1,则表示他抢到了锁,那么他去执行业务,然后再删除锁,退出锁逻辑,没有抢到锁的哥们,等待一定时间后重试即可。
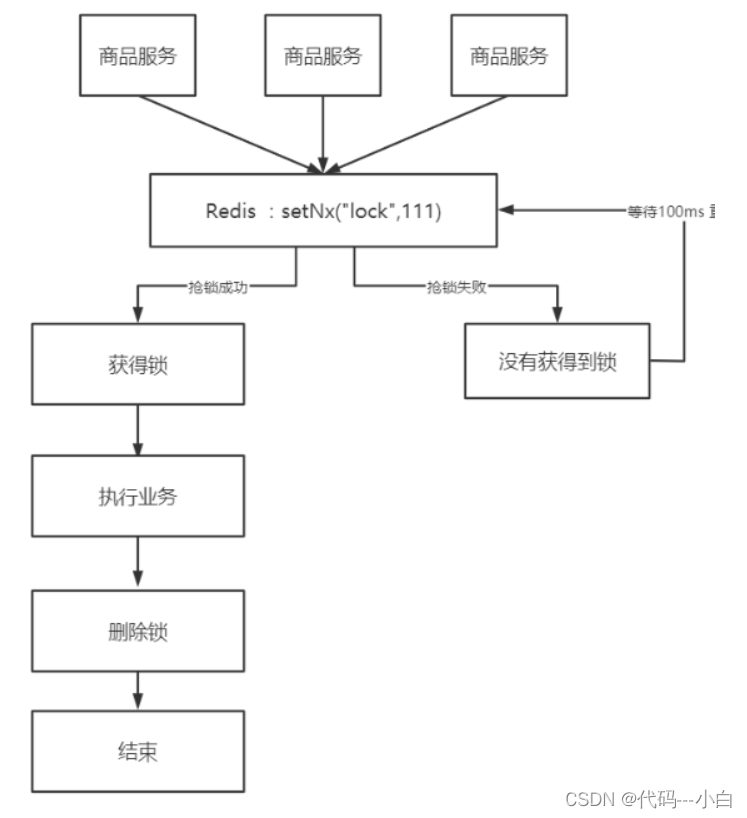
1.8.3 实现分布式锁的版本一
- 加锁逻辑
利用setnx方法进行加锁,同时增加过期时间,防止死锁,此方法可以保证加锁和增加过期时间具有原子性
1.8.3.1 Redis分布式锁误删情况说明
逻辑说明:
持有锁的线程在锁的内部出现了阻塞,导致他的锁自动释放,这时其他线程,线程2来尝试获得锁,就拿到了这把锁,然后线程2在持有锁执行过程中,线程1反应过来,继续执行,而线程1执行过程中,走到了删除锁逻辑,此时就会把本应该属于线程2的锁进行删除,这就是误删别人锁的情况说明
解决方案:解决方案就是在每个线程释放锁的时候,去判断一下当前这把锁是否属于自己,如果属于自己,则不进行锁的删除,假设还是上边的情况,线程1卡顿,锁自动释放,线程2进入到锁的内部执行逻辑,此时线程1反应过来,然后删除锁,但是线程1,一看当前这把锁不是属于自己,于是不进行删除锁逻辑,当线程2走到删除锁逻辑时,如果没有卡过自动释放锁的时间点,则判断当前这把锁是属于自己的,于是删除这把锁。
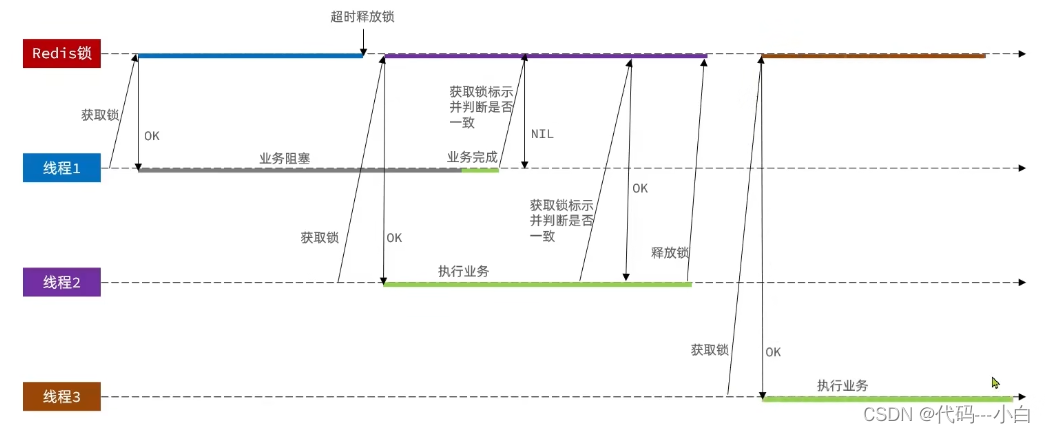
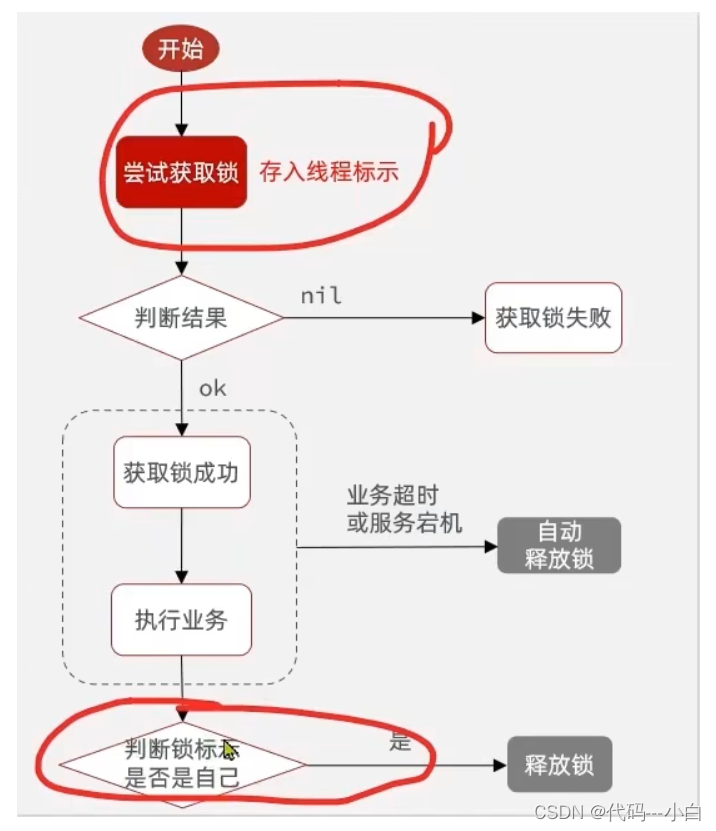
1.8.3.2 解决Redis分布式锁误删问题
需求:修改之前的分布式锁实现,满足:在获取锁时存入线程标示(可以用UUID表示) 在释放锁时先获取锁中的线程标示,判断是否与当前线程标示一致
- 如果一致则释放锁
- 如果不一致则不释放锁
核心逻辑:在存入锁时,放入自己线程的标识,在删除锁时,判断当前这把锁的标识是不是自己存入的,如果是,则进行删除,如果不是,则不进行删除。
有关代码实操说明:
在我们修改完此处代码后,我们重启工程,然后启动两个线程,第一个线程持有锁后,手动释放锁,第二个线程此时进入到锁内部,再放行第一个线程,此时第一个线程由于锁的value值并非是自己,所以不能释放锁,也就无法删除别人的锁,此时第二个线程能够正确释放锁,通过这个案例初步说明我们解决了锁误删的问题。
1.8.3.3 分布式锁的原子性问题
更为极端的误删逻辑说明:
线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删除锁,但是此时他的锁到期了,那么此时线程2进来,但是线程1他会接着往后执行,当他卡顿结束后,他直接就会执行删除锁那行代码,相当于条件判断并没有起到作用,这就是删锁时的原子性问题,之所以有这个问题,是因为线程1的拿锁,比锁,删锁,实际上并不是原子性的,我们要防止刚才的情况发生。
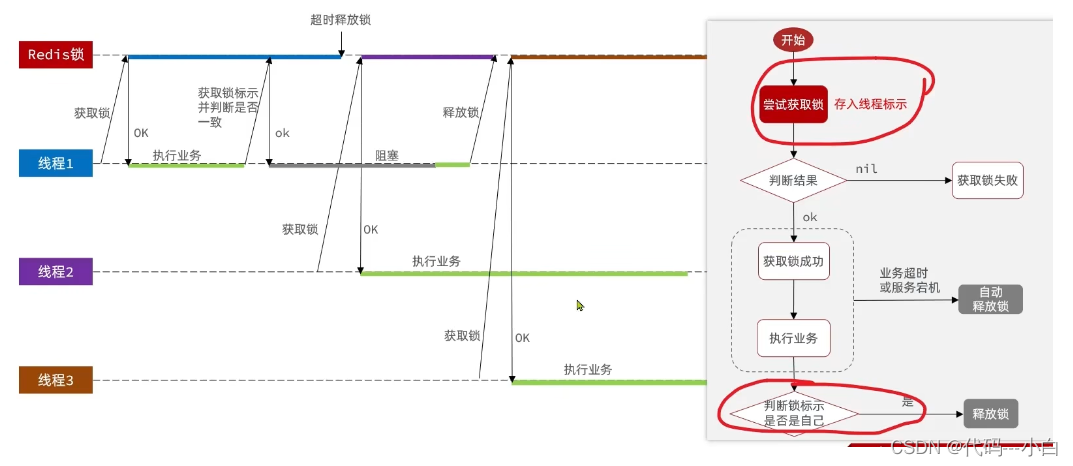
1.8.3.4 Lua脚本解决多条命令原子性问题
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。Lua是一种编程语言,它的基本语法大家可以参考网站:https://www.runoob.com/lua/lua-tutorial.html,这里重点介绍Redis提供的调用函数,我们可以使用lua去操作redis,又能保证他的原子性,这样就可以实现拿锁比锁删锁是一个原子性动作了,作为Java程序员这一块并不作一个简单要求,并不需要大家过于精通,只需要知道他有什么作用即可。
这里重点介绍Redis提供的调用函数,语法如下:
lua redis.call('命令名称', 'key', '其它参数', ...)
例如,我们要执行set name jack,则脚本是这样:
```lua
执行 set name jack
redis.call('set', 'name', 'jack') ```
例如,我们要先执行set name Rose,再执行get name,则脚本如下:
```lua
先执行 set name jack
redis.call('set', 'name', 'Rose')
再执行 get name
local name = redis.call('get', 'name')
小总结:
基于Redis的分布式锁实现思路:
-
利用set nx ex获取锁,并设置过期时间,保存线程标示
-
释放锁时先判断线程标示是否与自己一致,一致则删除锁
-
特性:
-
利用set nx满足互斥性
-
利用set ex保证故障时锁依然能释放,避免死锁,提高安全性
-
利用Redis集群保证高可用和高并发特性
笔者总结:我们一路走来,利用添加过期时间,防止死锁问题的发生,但是有了过期时间之后,可能出现误删别人锁的问题,这个问题我们开始是利用删之前 通过拿锁,比锁,删锁这个逻辑来解决的,也就是删之前判断一下当前这把锁是否是属于自己的,但是现在还有原子性问题,也就是我们没法保证拿锁比锁删锁是一个原子性的动作,最后通过lua表达式来解决这个问题
但是目前还剩下一个问题锁不住,什么是锁不住呢,你想一想,如果当过期时间到了之后,我们可以给他续期一下,比如续个30s,就好像是网吧上网, 网费到了之后,然后说,来,网管,再给我来10块的,是不是后边的问题都不会发生了,那么续期问题怎么解决呢,可以依赖于我们接下来要学习redission啦
测试逻辑:
第一个线程进来,得到了锁,手动删除锁,模拟锁超时了,其他线程会执行lua来抢锁,当第一天线程利用lua删除锁时,lua能保证他不能删除他的锁,第二个线程删除锁时,利用lua同样可以保证不会删除别人的锁,同时还能保证原子性。
1.8.4 实现分布式锁的版本二(Redission)
基于setnx实现的分布式锁存在下面的问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
**超时释放:**我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。

那么什么是Redission呢?
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
Redission提供了分布式锁的多种多样的功能。

1.8.4.1 分布式锁-redission可重入锁原理
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
在redission中,我们的也支持支持可重入锁
在分布式锁中,他采用hash结构用来存储锁,其中大key表示表示这把锁是否存在,用小key表示当前这把锁被哪个线程持有,所以接下来我们一起分析一下当前的这个lua表达式
这个地方一共有3个参数
KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
exists: 判断数据是否存在 name:是lock是否存在,如果==0,就表示当前这把锁不存在
redis.call('hset', KEYS[1], ARGV[2], 1);此时他就开始往redis里边去写数据 ,写成一个hash结构
Lock{
id+ ":" + threadId : 1
}
如果当前这把锁存在,则第一个条件不满足,再判断
redis.call('hexists', KEYS[1], ARGV[2]) == 1
此时需要通过大key+小key判断当前这把锁是否是属于自己的,如果是自己的,则进行
redis.call('hincrby', KEYS[1], ARGV[2], 1)
将当前这个锁的value进行+1 ,redis.call('pexpire', KEYS[1], ARGV[1]); 然后再对其设置过期时间,如果以上两个条件都不满足,则表示当前这把锁抢锁失败,最后返回pttl,即为当前这把锁的失效时间
如果小伙帮们看了前边的源码, 你会发现他会去判断当前这个方法的返回值是否为null,如果是null,则对应则前两个if对应的条件,退出抢锁逻辑,如果返回的不是null,即走了第三个分支,在源码处会进行while(true)的自旋抢锁。
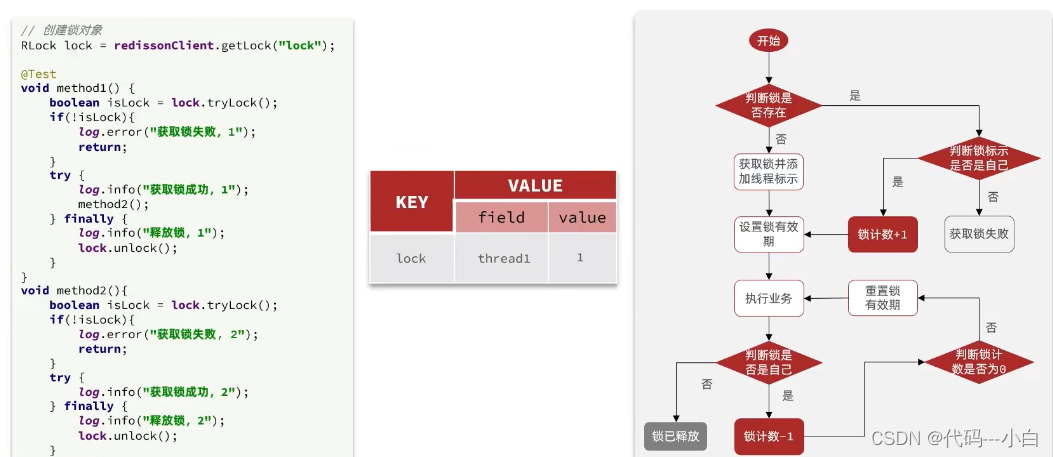
1.8.4.2 分布式锁-redission锁重试原理
说明:由于项目中已经说明了有关tryLock的源码解析以及其看门狗原理,所以笔者在这里给大家分析lock()方法的源码解析,希望大家在学习过程中,能够掌握更多的知识
抢锁过程中,获得当前线程,通过tryAcquire进行抢锁,该抢锁逻辑和之前逻辑相同。
1、 先判断当前这把锁是否存在,如果不存在,插入一把锁,返回null;
2、 判断当前这把锁是否是属于当前线程,如果是,则返回null;
小总结:
Redisson分布式锁原理:
• 可重入 :利用 hash 结构记录线程 id 和重入次数
• 可重试 :利用信号量和 PubSub 功能实现等待、唤醒,获取锁失败的重试机制
• 超时续约 :利用 watchDog ,每隔一段时间( releaseTime / 3 ),重置超时时间
1.8.4.3 分布式锁-redission的MutiLock原理
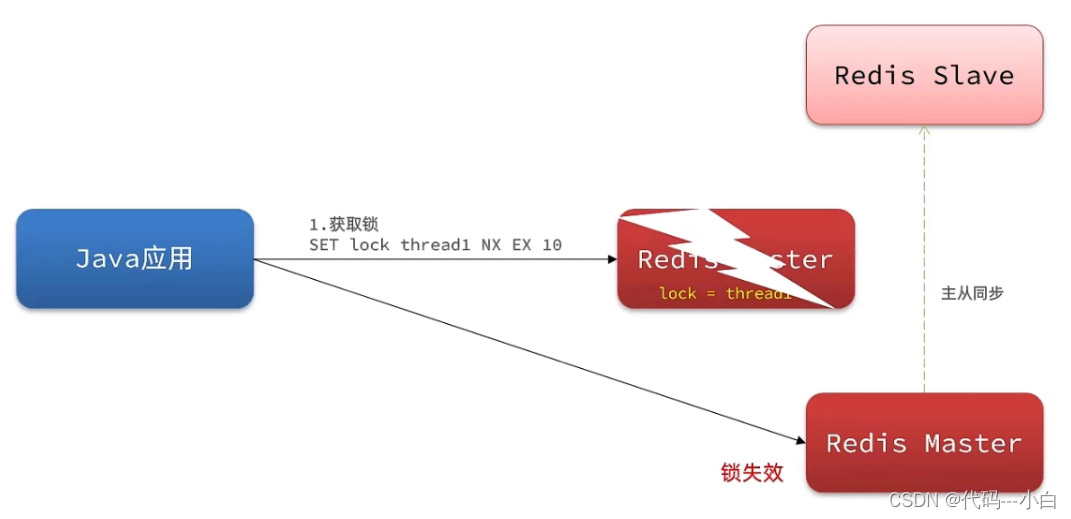
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
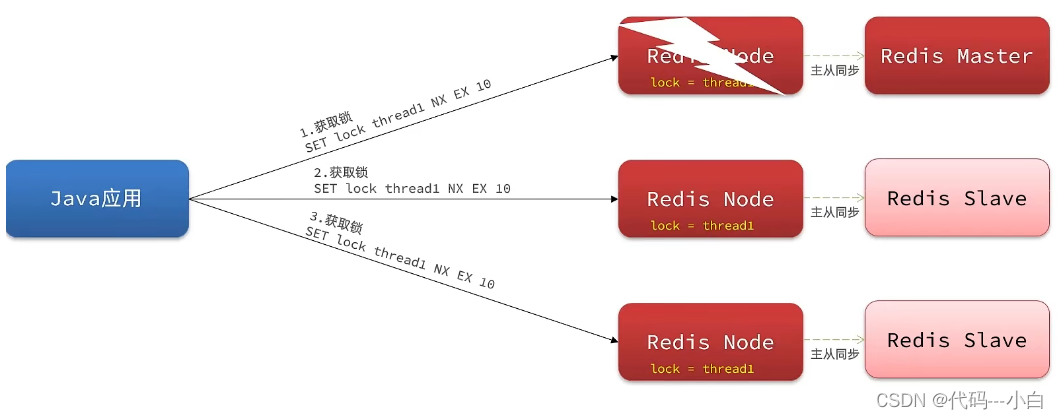
为了解决这个问题,redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
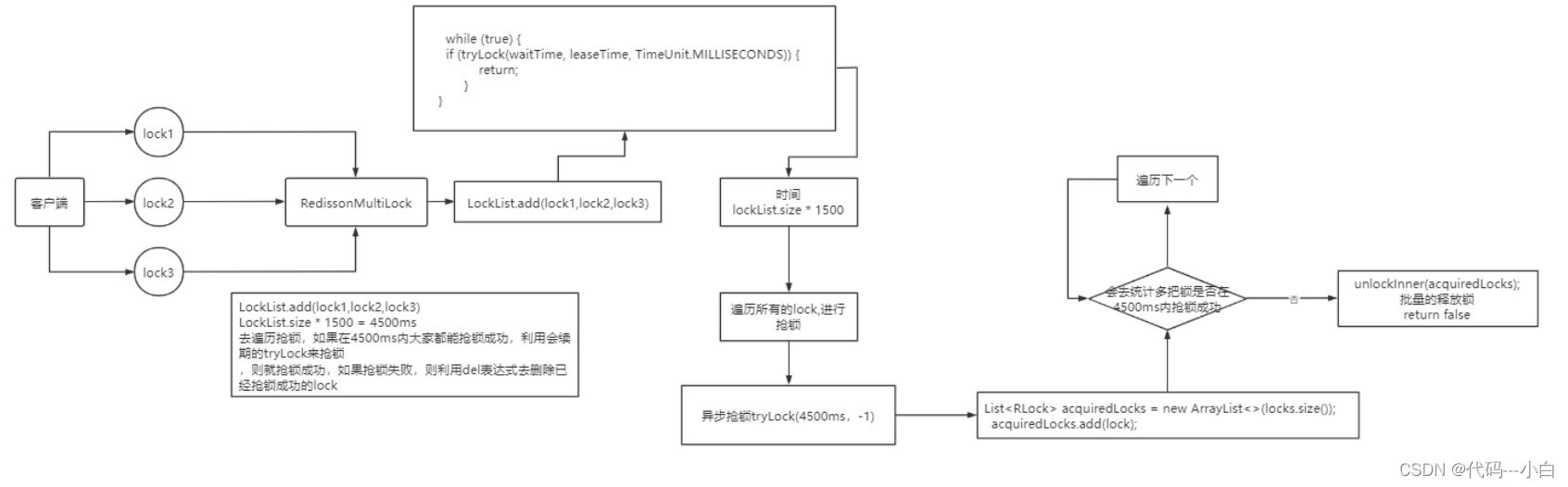
那么MutiLock 加锁原理是什么呢?笔者画了一幅图来说明
当我们去设置了多个锁时,redission会将多个锁添加到一个集合中,然后用while循环去不停去尝试拿锁,但是会有一个总共的加锁时间,这个时间是用需要加锁的个数 * 1500ms ,假设有3个锁,那么时间就是4500ms,假设在这4500ms内,所有的锁都加锁成功, 那么此时才算是加锁成功,如果在4500ms有线程加锁失败,则会再次去进行重试。
Redission总结:
1**)不可重入Redis分布式锁:**
原理:利用 setnx 的互斥性;利用 ex 避免死锁;释放锁时判断线程标示;
缺陷:不可重入、无法重试、锁超时失效。
2**)可重入的Redis分布式锁**
原理:利用 hash 结构,记录线程标示和重入次数;利用 watchDog 延续锁时间;利用信号量控制锁重试等待;
缺陷:redis 宕机引起锁失效问题。
3**)Redisson的multiLock:**
原理:多个独立的 Redis 节点,必须在所有节点都获取重入锁,才算获取锁成功;
缺陷:运维成本高、实现复杂。
1.9 秒杀优化
1.9.1 秒杀优化-异步秒杀思路
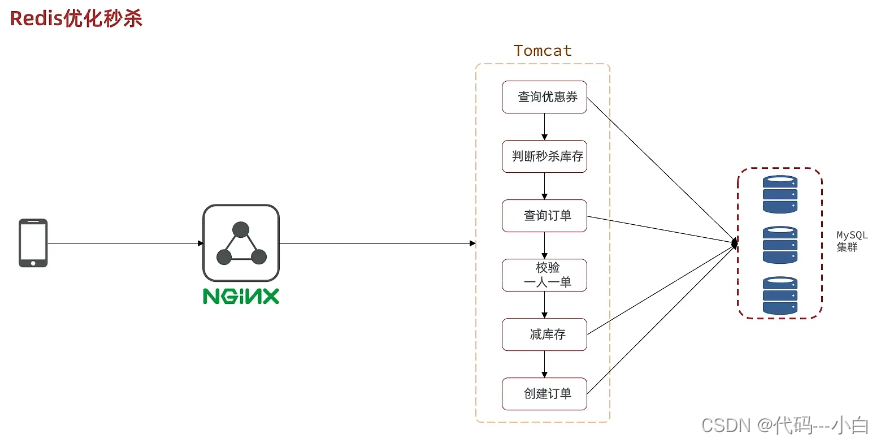
我们来回顾一下下单流程
当用户发起请求,此时会请求nginx,nginx会访问到tomcat,而tomcat中的程序,会进行串行操作,分成如下几个步骤
1、 查询优惠卷;
2、 判断秒杀库存是否足够;
3、 查询订单;
4、 校验是否是一人一单;
5、 扣减库存;
6、 创建订单;
在这六步操作中,又有很多操作是要去操作数据库的,而且还是一个线程串行执行, 这样就会导致我们的程序执行的很慢,所以我们需要异步程序执行,那么如何加速呢?
在这里笔者想给大家分享一下课程内没有的思路,看看有没有小伙伴这么想,比如,我们可以不可以使用异步编排来做,或者说我开启N多线程,N多个线程,一个线程执行查询优惠卷,一个执行判断扣减库存,一个去创建订单等等,然后再统一做返回,这种做法和课程中有哪种好呢?答案是课程中的好,因为如果你采用我刚说的方式,如果访问的人很多,那么线程池中的线程可能一下子就被消耗完了,而且你使用上述方案,最大的特点在于,你觉得时效性会非常重要,但是你想想是吗?并不是,比如我只要确定他能做这件事,然后我后边慢慢做就可以了,我并不需要他一口气做完这件事,所以我们应当采用的是课程中,类似消息队列的方式来完成我们的需求,而不是使用线程池或者是异步编排的方式来完成这个需求。
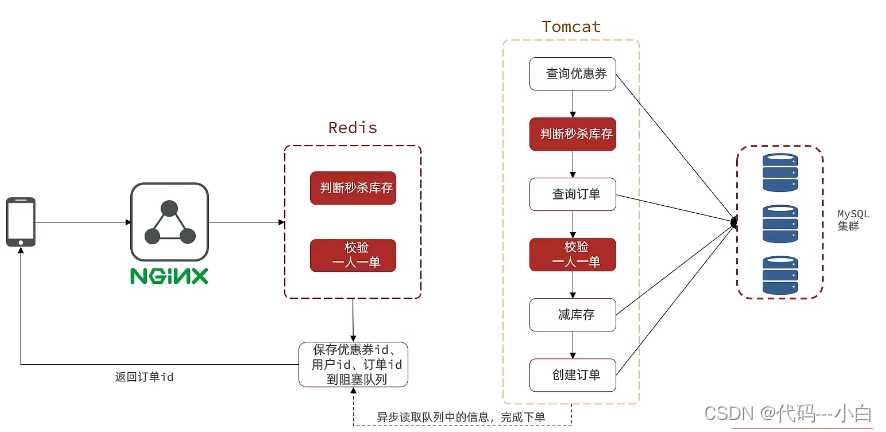
优化方案:我们将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,根本就不用等下单逻辑走完,我们直接给用户返回成功, 再在后台开一个线程,后台线程慢慢的去执行queue里边的消息,这样程序不就超级快了吗?而且也不用担心线程池消耗殆尽的问题,因为这里我们的程序中并没有手动使用任何线程池,当然这里边有两个难点
第一个难点是我们怎么在redis中去快速校验一人一单,还有库存判断。
第二个难点是由于我们校验和tomct下单是两个线程,那么我们如何知道到底哪个单他最后是否成功,或者是下单完成,为了完成这件事我们在redis操作完之后,我们会将一些信息返回给前端,同时也会把这些信息丢到异步queue中去,后续操作中,可以通过这个id来查询我们tomcat中的下单逻辑是否完成了。
我们现在来看看整体思路:当用户下单之后,判断库存是否充足只需要导redis中去根据key找对应的value是否大于0即可,如果不充足,则直接结束,如果充足,继续在redis中判断用户是否可以下单,如果set集合中没有这条数据,说明他可以下单,如果set集合中没有这条记录,则将userId和优惠卷存入到redis中,并且返回0,整个过程需要保证是原子性的,我们可以使用lua来操作
当以上判断逻辑走完之后,我们可以判断当前redis中返回的结果是否是0 ,如果是0,则表示可以下单,则将之前说的信息存入到到queue中去,然后返回,然后再来个线程异步的下单,前端可以通过返回的订单id来判断是否下单成功。
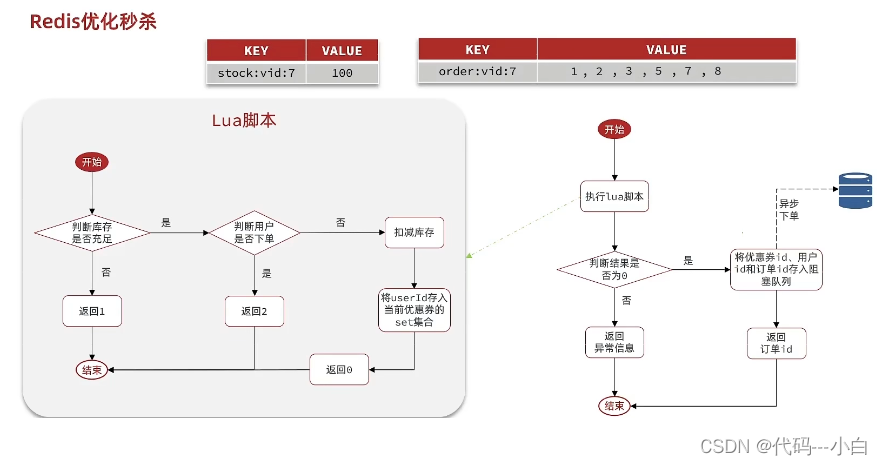
1.9.2 秒杀优化-Redis完成秒杀资格判断
需求:
- 新增秒杀优惠券的同时,将优惠券信息保存到Redis中;
- 基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功;
- 如果抢购成功,将优惠券id和用户id封装后存入阻塞队列;
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能。
1.9.3 秒杀优化-基于阻塞队列实现秒杀优化
修改下单动作,现在我们去下单时,是通过lua表达式去原子执行判断逻辑,如果判断我出来不为0 ,则要么是库存不足,要么是重复下单,返回错误信息,如果是0,则把下单的逻辑保存到队列中去,然后异步执行。
小总结:
秒杀业务的优化思路是什么?
-
先利用Redis完成库存余量、一人一单判断,完成抢单业务
-
再将下单业务放入阻塞队列,利用独立线程异步下单
-
基于阻塞队列的异步秒杀存在哪些问题?
-
内存限制问题
-
数据安全问题
1.10 Redis消息队列
1.10.1 Redis消息队列-认识消息队列
什么是消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
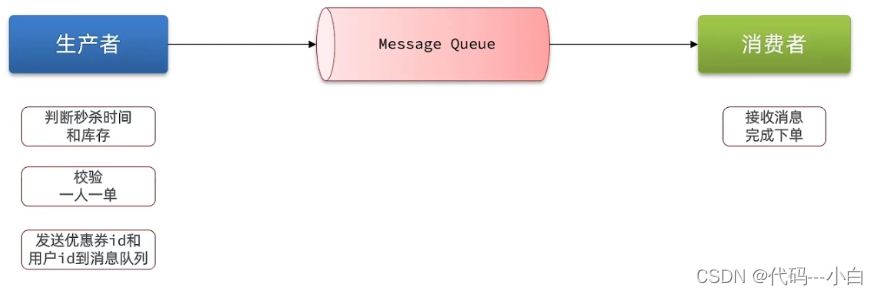
使用队列的好处在于 **解耦:**所谓解耦,举一个生活中的例子就是:快递员(生产者)把快递放到快递柜里边(Message Queue)去,我们(消费者)从快递柜里边去拿东西,这就是一个异步,如果耦合,那么这个快递员相当于直接把快递交给你,这事固然好,但是万一你不在家,那么快递员就会一直等你,这就浪费了快递员的时间,所以这种思想在我们日常开发中,是非常有必要的。
这种场景在我们秒杀中就变成了:我们下单之后,利用redis去进行校验下单条件,再通过队列把消息发送出去,然后再启动一个线程去消费这个消息,完成解耦,同时也加快我们的响应速度。
这里我们可以使用一些现成的mq,比如RocketMQ、kafka,rabbitmq等等,但是呢,如果没有安装mq,我们也可以直接使用redis提供的mq方案,降低我们的部署和学习成本。
1.10.2 Redis消息队列-基于List实现消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。 不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

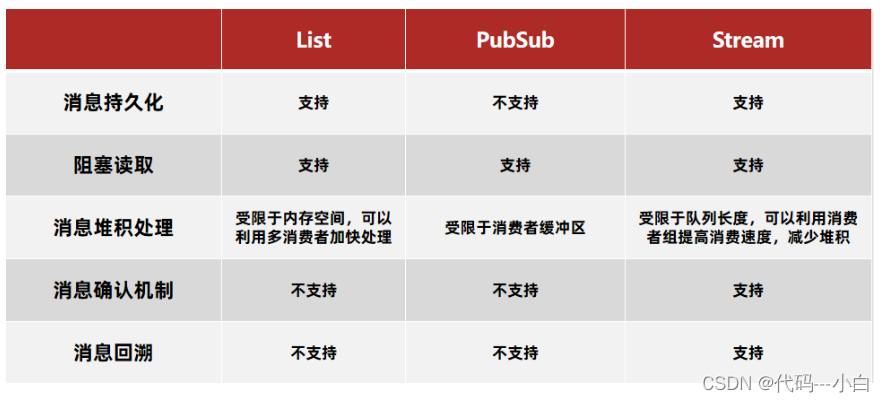
基于List的消息队列有哪些优缺点? 优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
1.10.3 Redis消息队列-基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel [channel] :订阅一个或多个频道 PUBLISH channel msg :向一个频道发送消息 PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道。
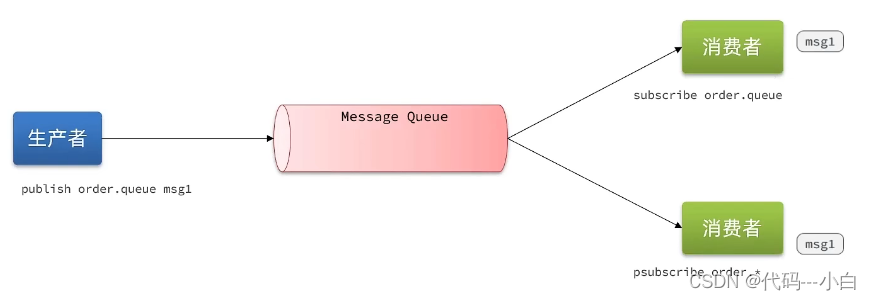 基于PubSub的消息队列有哪些优缺点? 优点:
基于PubSub的消息队列有哪些优缺点? 优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
1.10.4 Redis消息队列-基于Stream的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
1.10.5 Redis消息队列-基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:

1.10.6Redis消息队列实现方式的对比分析
参考文献:
有一说一,黑马老师的这个Reids这个课程真的很顶。 黑马程序员Redis入门到实战教程,深度透析redis底层原理+redis分布式锁+企业解决方案+黑马点评实战项目_哔哩哔哩_bilibili
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: