
十二、StringTable
1、String 的基本特性
(面试常问)StringTable(字符串常量池)为什么要调整?
- jdk7中将StringTable放到了堆空间中,因为永久代的回收效率很低。在fullGC的时候才触发,而fullGC是老年代空间不足或永久代不足时才触发。
- 这就导致了StringTable回收效率不高,而我们开发中会创建大量的字符串,回收效率低,导致永久代内存不足。放到堆里,能及时回收内存。
String的基本特性:
- 字符串,用""引起来表示
- 声明为final的不可被继承的
- 实现了Serializable接口,表示支持序列化
- 实现了Comparable接口,表示可以比较大小
jdk8及以前,内部定义了final char[] value用于存储字符串数据,jdk9类型更改:private final char value[]; * private final byte[] value; 原因:
- char数组每个字符占两个字节16位,String是堆空间的主要部分,大部分是拉丁字符,占一个字节,节省空间
- 中文等UTF-16 的用两个字节存储。
- StringBuffer,StringBuilder同样做了修改
String代表不可变的字符序列(不可变性):
- 当字符串重新赋值,需要重新指定内存区域赋值,不能使用原有的value进行赋值。
- 当调用String的replace方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
- 当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能对使用原有的value进行赋值。
字符串常量池中不会存储相同的字符串:
- String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern()方法时性能会大幅下降。
- 使用-XX:StringTablesize可设置StringTable的长度
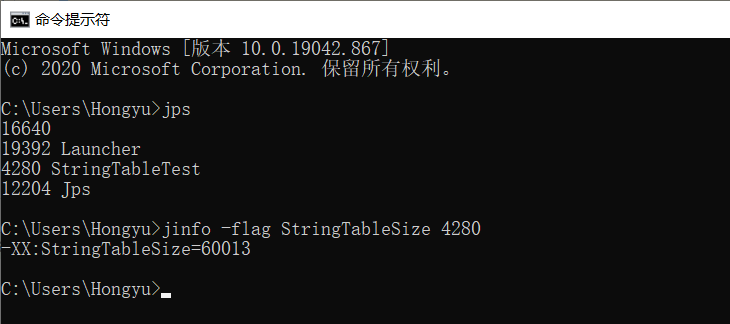
- 在JDK6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快,StringTableSize设置没有要求。
- 在JDK7中,StringTable的长度默认值是60013,StringTableSize设置没有要求。
- 在JDK8中,StringTable的长度默认值是60013,StringTable可以设置的最小值为1009。
2、String 的内存分配
Java语言中有8种基本数据类型和一种比较特殊的类型String,这些类型为了使他们再运行过程中速度更快,更节省内存,都提供了一种常量池的概念。
String的常量池比较特殊,主要使用方法有两种:
- 直接使用双引号,声明出来的String对象会直接存储在常量池中。
- 如果不是双引号声明的String对象,可以使用String提供的 intern() 方法。
jdk6及之前,字符串常量池存在永久代,与应用程序创建的其他对象一起分配。jdk7的时候,字符串常量池调整到 Java堆中,调优时仅需调整堆的大小就可以。jdk8中,永久代变为元空间并直接使用本地内存,字符串常量池仍在堆中。
为什么要调整?
- 永久代默认情况下比较小,大量字符串容易导致OOM。
- 永久代垃圾回收频率低。
- 堆中空间足够大,字符串可被及时回收。
3、String 的基本操作
Java语言规范要求完全相同的字符串字面量,应该包含同样的Unicode字符序列,包含同一份码点序列的常量,并且必须指向同一个String类实例。
4、字符串拼接操作
1、常量与常量的拼接结果在常量池,原理是编译期优化
测试代码:
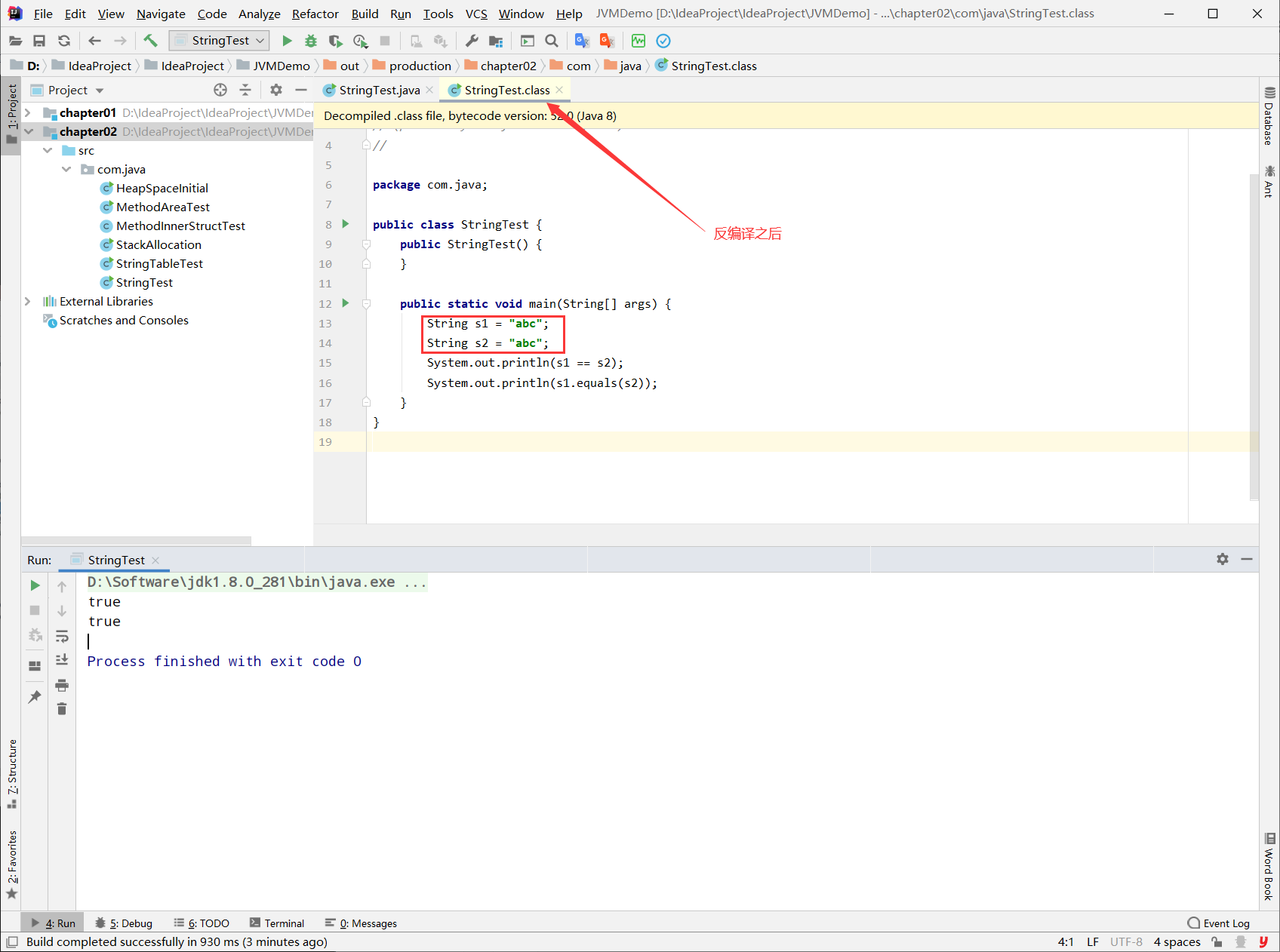
public class StringTest {
public static void main(String[] args) {
String s1 = "a" + "b" + "c";
String s2 = "abc";
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
运行结果:
true
true
分析:
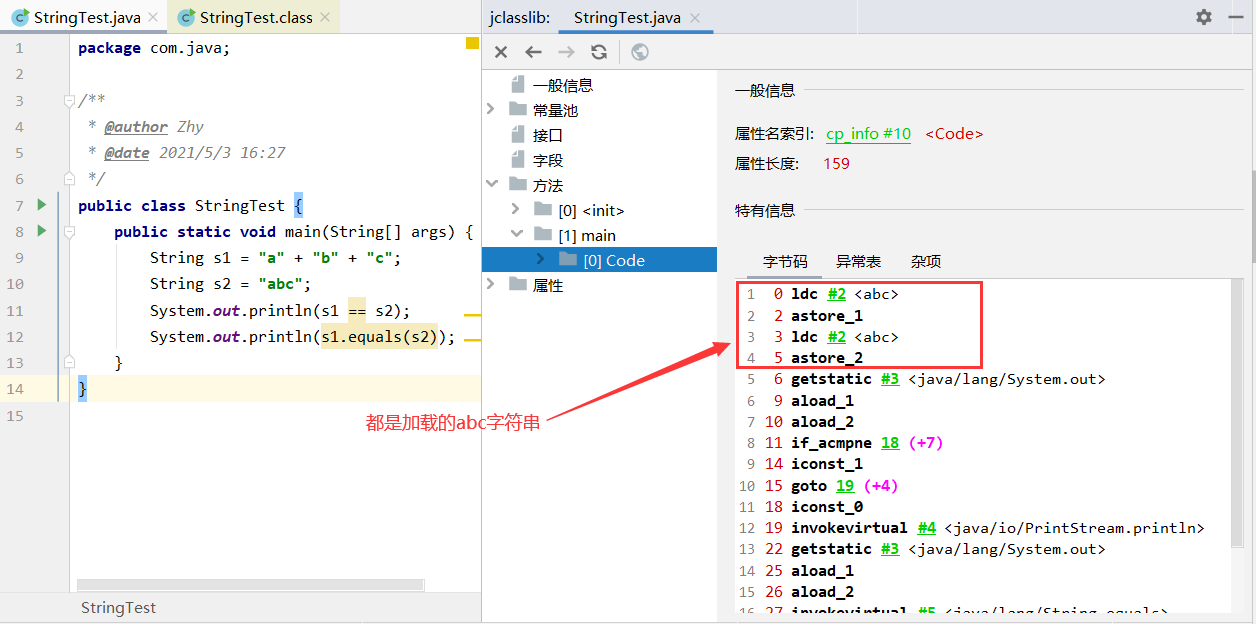
2、常量池中不存在相同内容的常量(hashtable)
3、只要有一个变量,拼接结果就在堆中(常量池以外的堆),变量的拼接原理是StringBuilder
测试代码:
public class StringTest {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "world";
String s3 = "helloworld";
String s4 = "hello" + "world"; // 编译期优化
String s5 = s1 + "world";
String s6 = "hello" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true
// 如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),具体的内容为拼接的结果: helloworld
System.out.println(s3 == s5); // false
System.out.println(s3 == s6); // false
System.out.println(s3 == s7); // false
System.out.println(s5 == s6); // false
System.out.println(s5 == s7); // false
System.out.println(s6 == s7); // false
// intern():判断字符串常量池中是否存在helloworld值,如果存在,则返回常量池中helloworld的地址;
// 如果字符串常量池中不存在helloworld,则在常量池中加载一份helloworld,并返回此对象的地址。
String s8 = s7.intern();
System.out.println(s3 == s8); // true
}
}
运行结果: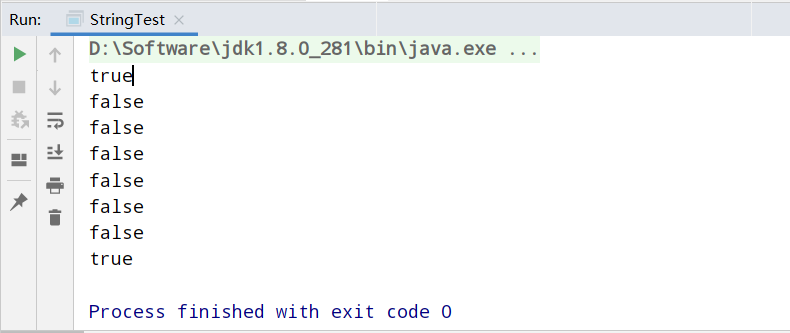
+:字符串拼接底层
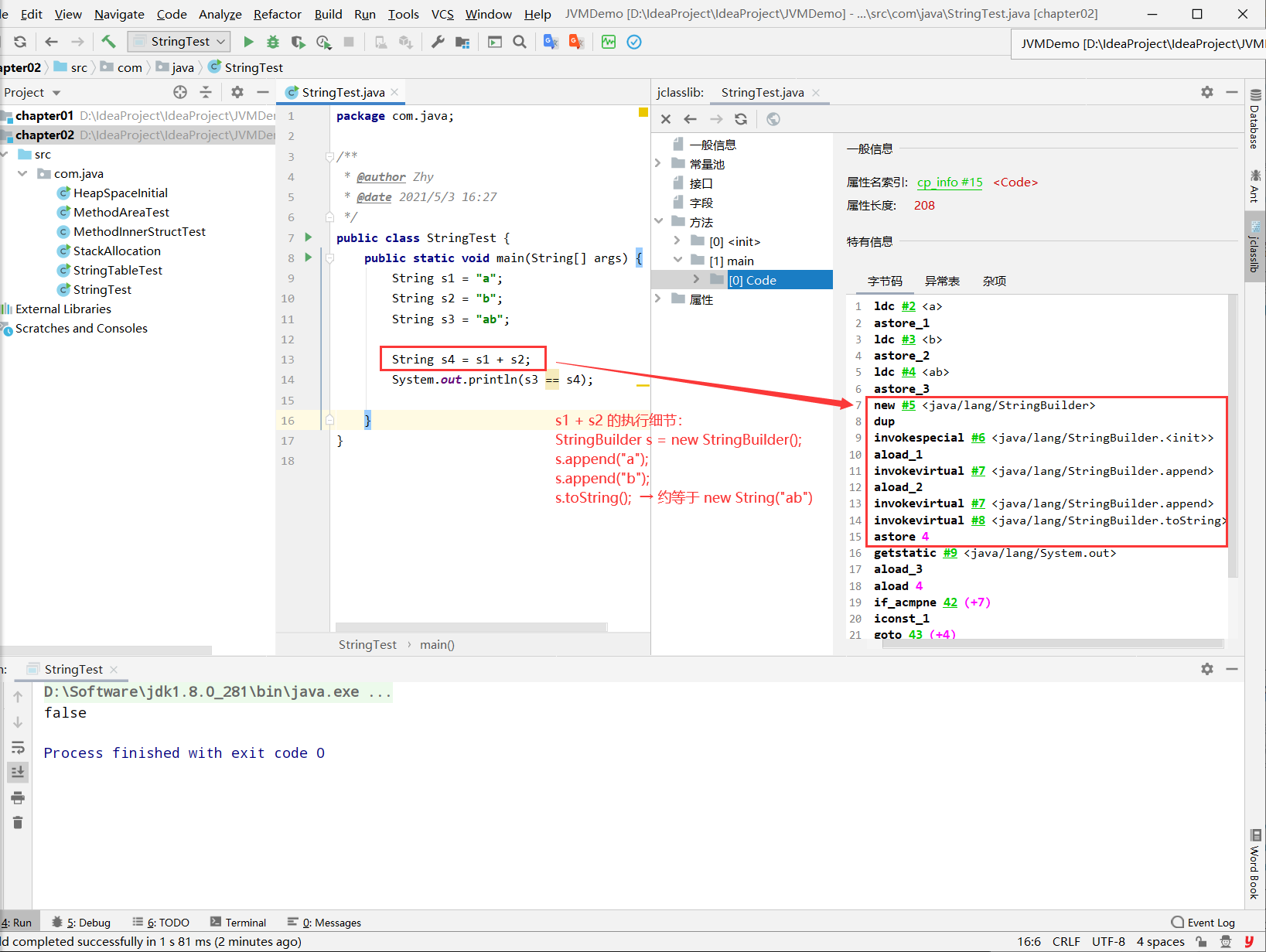
补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer。
Final修饰符
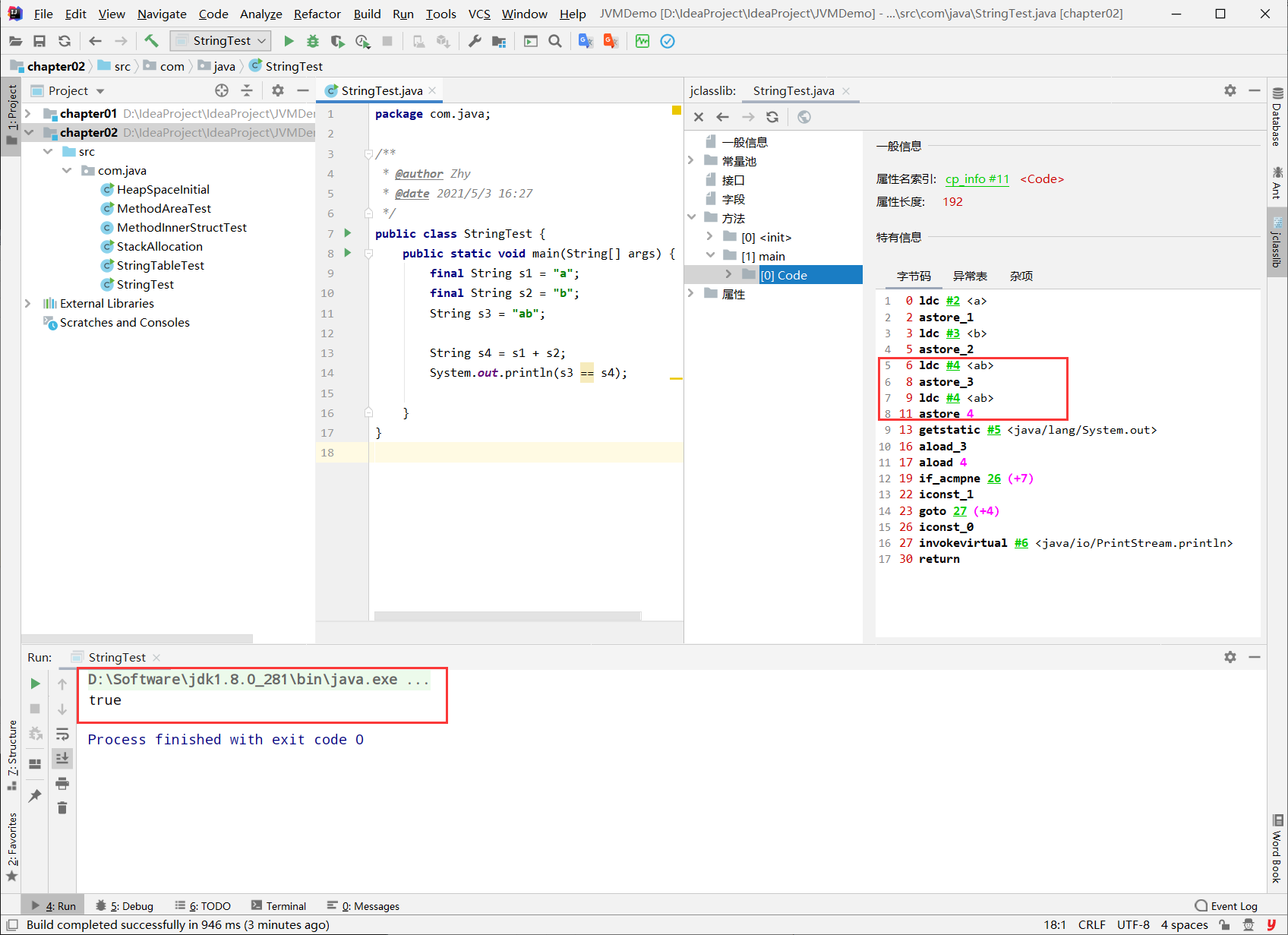
字符串拼接操作不—定使用的是 StringBuilder!
如果拼接符号左右两边都是字符串常量或常量引用(加final关键字),则仍然使用编译期优化,即非 StringBuilder的方式。
针对于final修饰类、方法、基本数据类型、引用数据类型的量的结构时,能使用上final的时候建议使用上。
4、对比用+号拼接字符串和StringBuilder.append操作
public class StringBuilderTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
method1(100000);
long end = System.currentTimeMillis();
System.out.println("花费时间:" + (end - start));
}
public static void method1(int highLevel) {
String str = "";
for (int i = 0; i < highLevel; i++) {
str += "a";
}
}
public static void method2(int highLevel) {
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
stringBuilder.append("a");
}
}
}
运行结果:
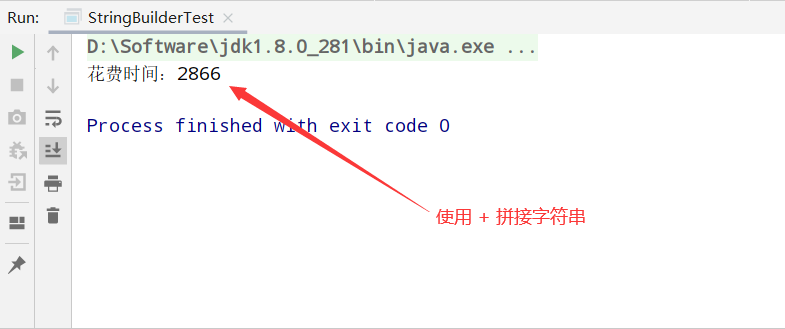
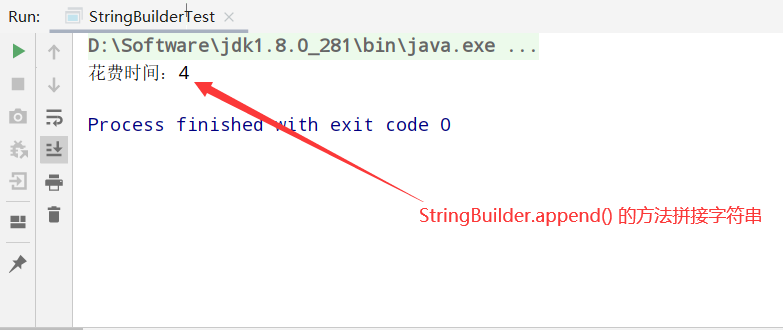
对比用+号拼接字符串和StringBuilder.append的方式,我们不难发现,拼接10万次,+号2866,append用了4毫秒。
通过StringBuilder的append() 的方式添加字符串的效率要远高于使用String的字符串拼接方式(+), 原因如下:
- StringBuilder的append()的方式: 自始至终中只创建过一个StringBuilder的对象;使用String的字符串拼接方式:创建过多个StringBuilder和String的对象。
- 使用String的字符串拼接方式(+): 内存中由于创建了较多的StringBuilder和String对象,内存占用更大; 如果进行GC,需要花费额外的时间。
- 改进的空间: 在实际开发中,如果基本确定要前前后后添加的字符串长度不高于某个限定值highLevel的情况下,建议使用构造器实例化。
StringBuilder s = new StringBuilder(highLevel); //new char[highLevel]
5、intern() 的使用
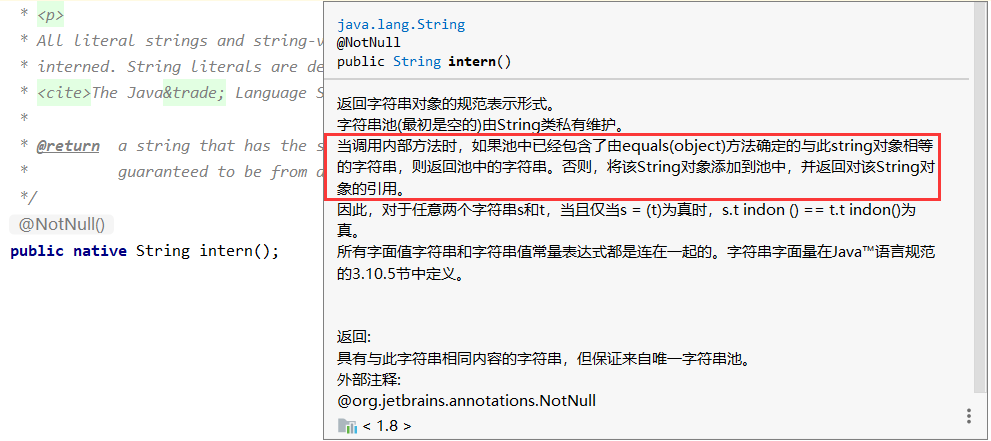
如果字符串常量池中,通过equals判断是否相同,如果没有则在常量池中生成,确保字符串在内存里只有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度,注意,这个值会被存放在字符串内部池。(String intern pool)。
如何保证变量 s 指向的是字符串常量池中的数据呢?
方式一:
String s = "hello"; //字面量定义的方式
方式二:
String s = new String("hello").intern();
String s = new StringBuilder("shkstart").toString().intern();
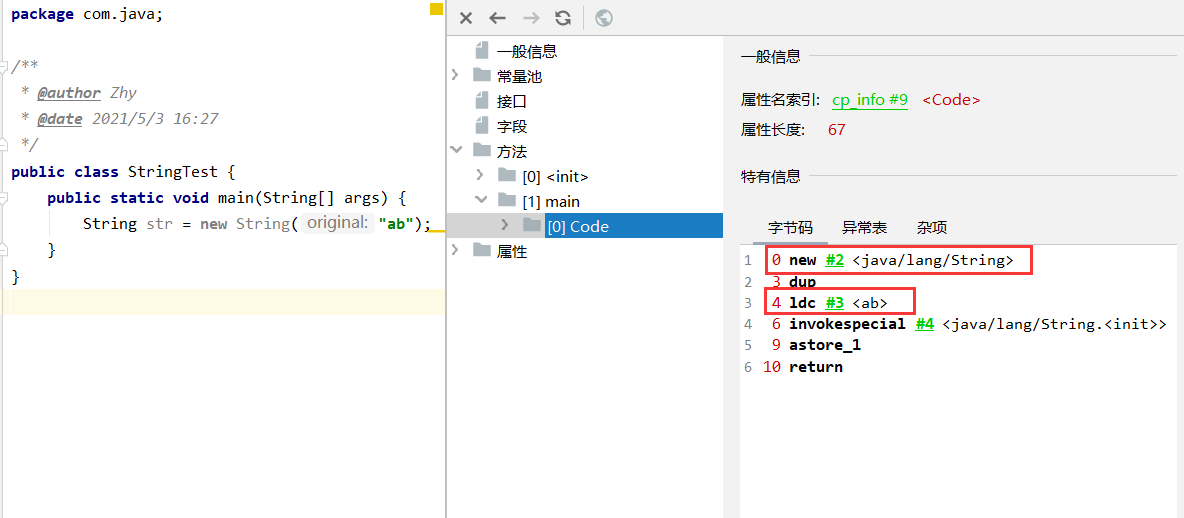
(面试常问)new String(“ab”)会创建几个对象?
2个对象:
- 一个对象是:new关键字在堆空间创建的
- 另一个对象是:字符串常量池中的对象"ab"。 字节码指令:ldc,在字符串常量池中放入 “ab”(若字符串常量池中没有 “ab” )。
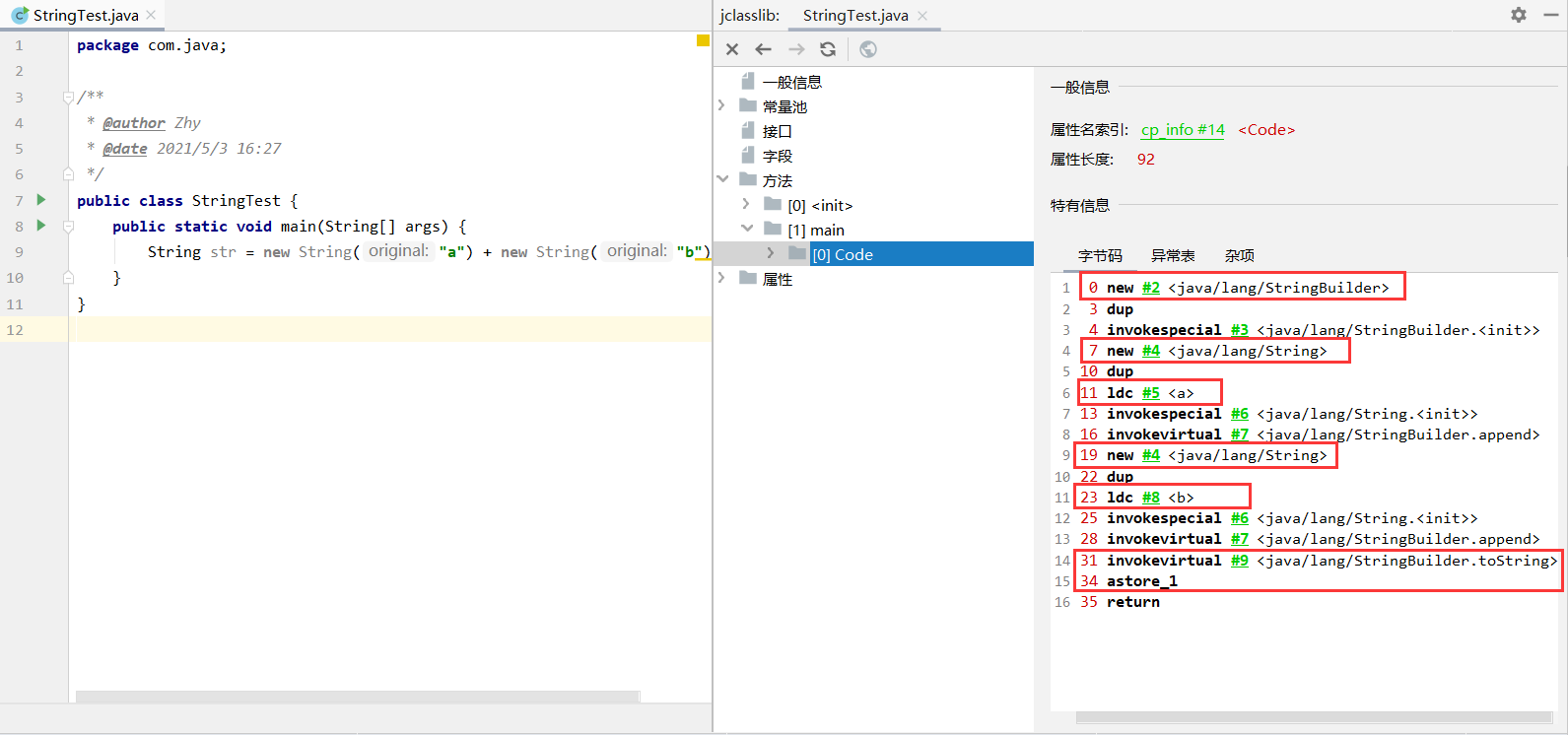
(面试常问)new String(“a”) + new String(“b”) 会创建几个对象?
6个对象:
- 对象1,new StringBuilder() (有变量的字符串拼接操作)
- 对象2,new String(“a”)
- 对象3,字符串常量池中的"a"
- 对象4,new String(“b”)
- 对象5,常量池中的"b"
- 对象6,StringBuilder的toString() 方法会 new String(“ab”)

(面试题)判断 true 或者false?
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
打印结果是:
- jdk6 下false false
- jdk7/8 下false true
jdk6的解释: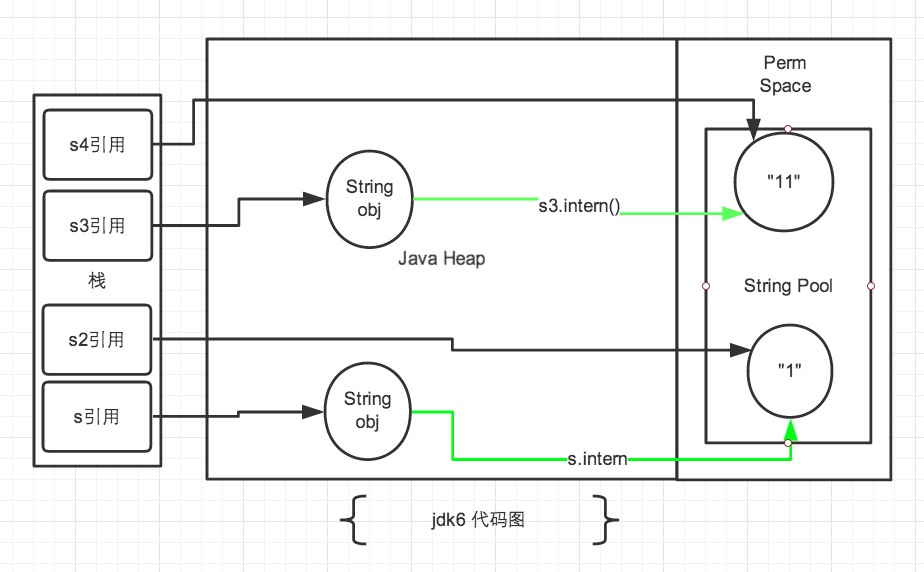
注:图中绿色线条代表 string 对象的内容指向。 黑色线条代表地址指向。
在jdk6中上述的所有打印都是 false 的,因为 jdk6中的常量池是放在 Perm 区中的,Perm 区和正常的 JAVA Heap 区域是完全分开的。上面说过如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 JAVA Heap 区域。所以拿一个 JAVA Heap 区域的对象地址和字符串常量池的对象地址进行比较肯定是不相同的,即使调用String.intern方法也是没有任何关系的。
jdk7中的解释: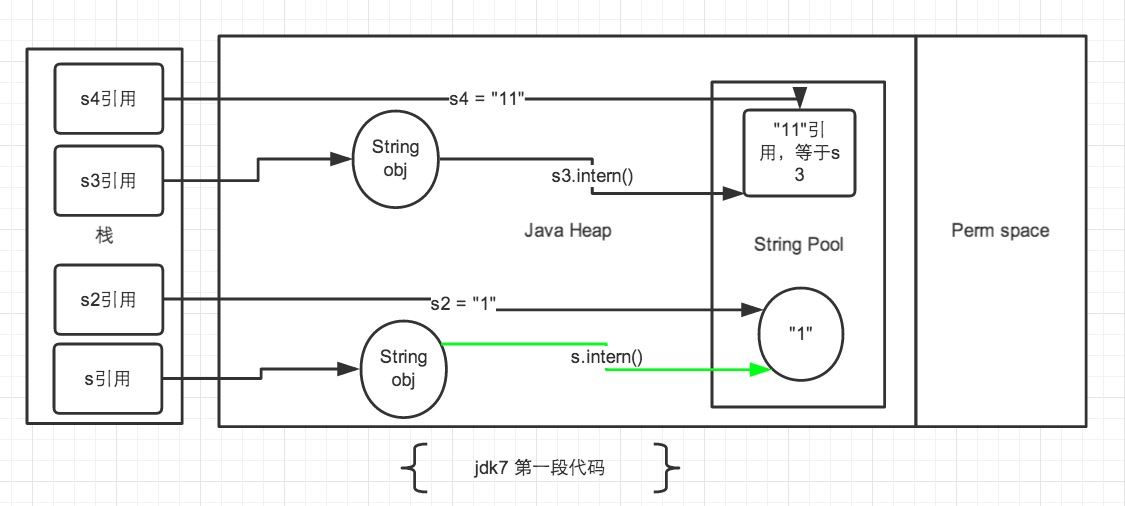
在Jdk6 以及以前的版本中,字符串的常量池是放在堆的 Perm 区的,Perm 区是一个类静态的区域,主要存储一些加载类的信息,常量池,方法片段等内容,默认大小只有4m,一旦常量池中大量使用 intern 是会直接产生java.lang.OutOfMemoryError: PermGen space错误的。 所以在 jdk7 的版本中,字符串常量池已经从 Perm 区移到正常的 Java Heap 区域了。
String s3 = new String("1") + new String("1");,这句代码中现在生成了2最终个对象,是字符串常量池中的“1” 和 JAVA Heap 中的 s3引用指向的对象。中间还有2个匿名的new String("1")。此时s3引用对象内容是”11”,但此时字符串常量池中是没有 “11”对象的。
接下来s3.intern();这一句代码,是将 s3中的“11”字符串放入 String 常量池中,因为此时常量池中不存在“11”字符串,因此常规做法是跟 jdk6 图中表示的那样,在常量池中生成一个 “11” 的对象,关键点是 jdk7 中常量池不在 Perm 区域了,这块做了调整。常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用指向 s3 引用的对象。 也就是说引用地址是相同的。
最后String s4 = "11"; 这句代码中”11”是显示声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。所以 s4 引用就指向和 s3 一样了。因此最后的比较 s3 == s4 是 true。
public class StringTest {
public static void main(String[] args) {
String s3 = new String("1") + new String("1");
String s4 = "11";
String s5 = s3.intern();
System.out.println(s3 == s4);
System.out.println(s4 == s5);
}
}
修改代码将s3.intern();语句下调一行,放到String s4 = "11";后面,其运行结果为
- jdk7 下false true
首先执行String s4 = "11";声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象。然后再执行s3.intern();时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。而 s5是从字符串常量池中取回来的引用,当然和s4相等。
总结:
- jdk1.6中,s.intern() 将这个字符串对象放入串池,如果串池中有,则并不会放入,返回已有串池中的对象的地址,如果没有,会把对象复制一份,放入串池,并返回串池中的对象地址。
- jdk1.7起,s.intern() 将这个字符串对象尝试放入串池,如果串池中有,则并不会放入,返回已有的串池中的对象的地址,如果没有,则会把对象的引用地址复制一份,放入串池,并返回串池中的引用地址。
案例1: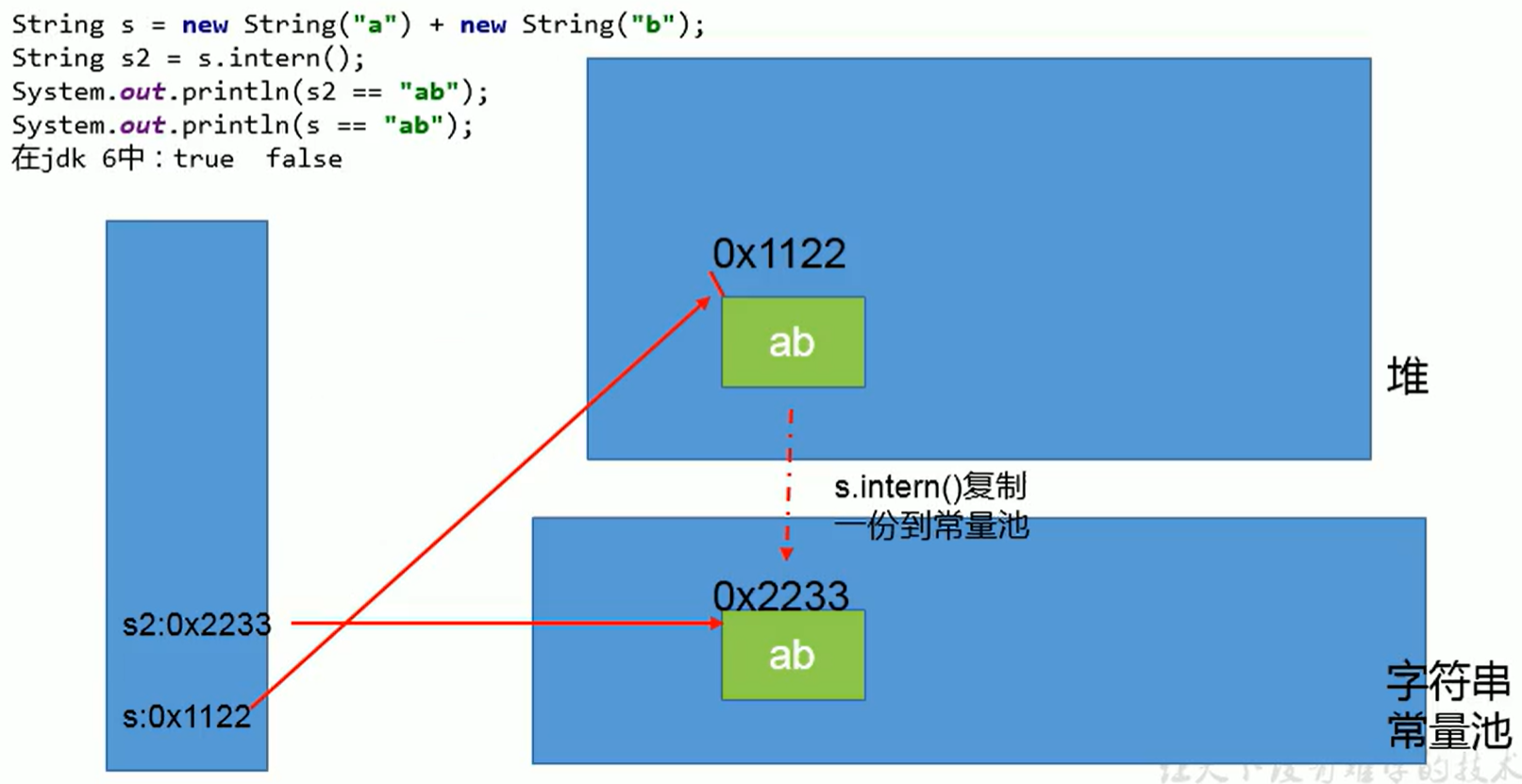
案例2:
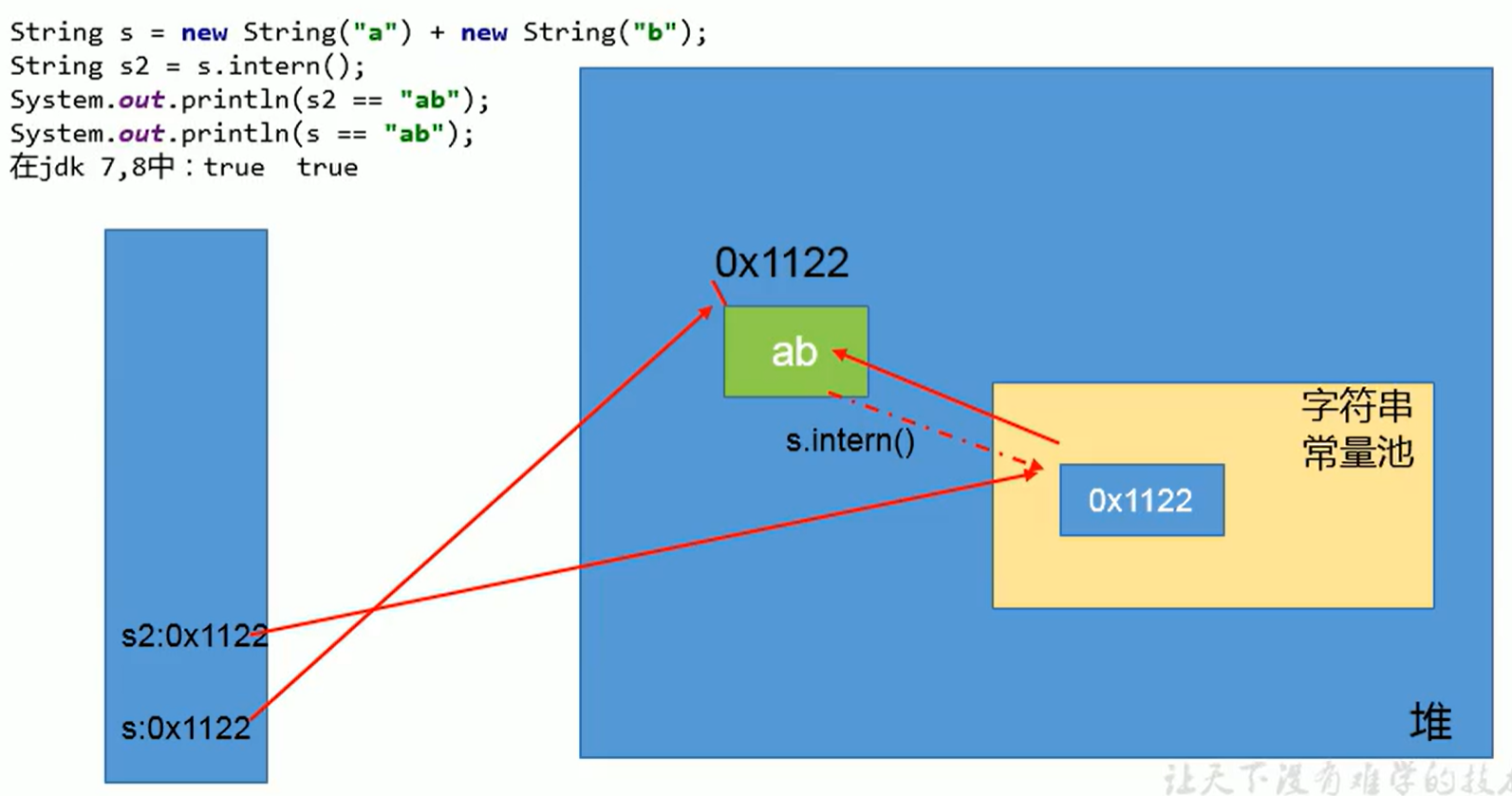
案例3: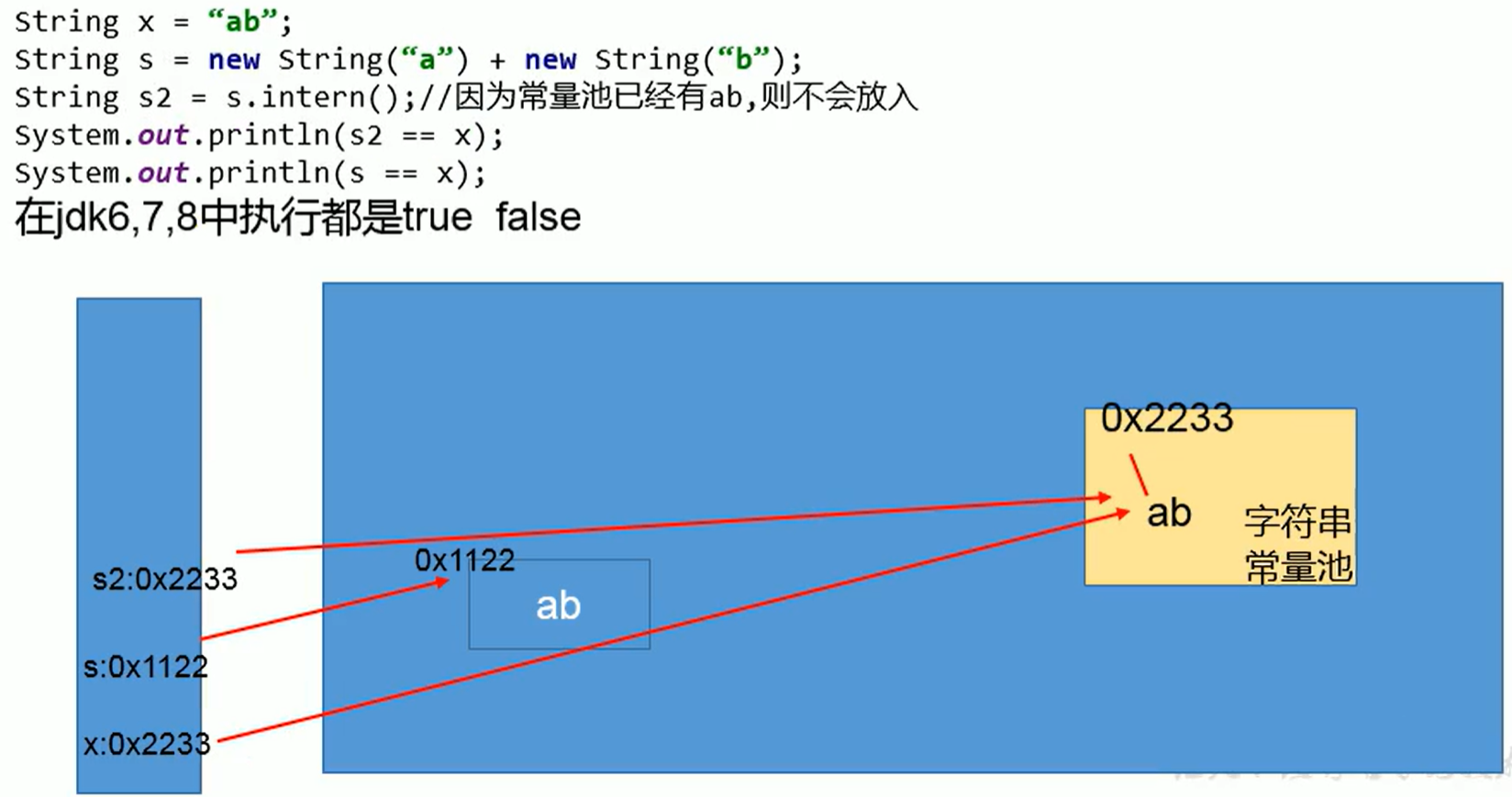
intern()的效率测试:
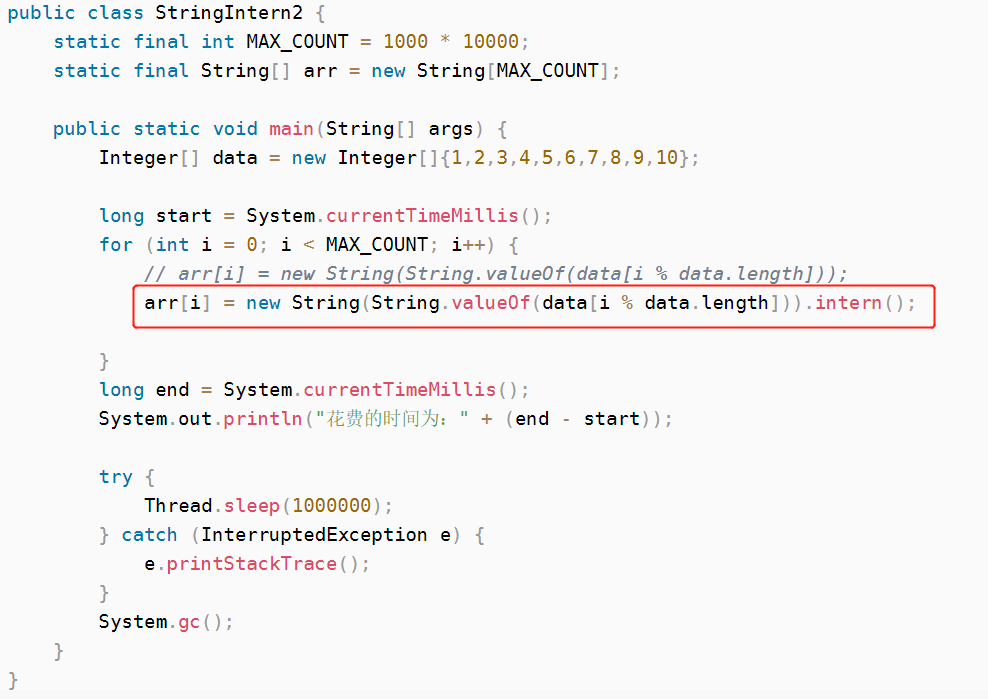
- 直接 new String :由于每个 String 对象都是 new 出来的,所以程序需要维护大量存放在堆空间中的 String 实例,程序内存占用也会变高,数组所指向的是堆中的实例。
- 使用 intern() 方法:虽然每个 String 对象也是 new 出来的,但是使用intern()方法后数组中字符串的引用都指向字符串常量池中的字符串,那么堆中的 String 对象会随着GC而清理掉。
- 对于程序中大量使用存在的字符串时,尤其存在很多已经重复的字符串时,使用intern()方法能够节省内存空间。比如社交网站,很多人都存储相同的:北京市、海淀区等信息。这时候如果字符串都调用intern() 方法,就会很明显降低内存的大小。
StringTable的垃圾回收:-XX:+PrintStringTableStatistics
String 去重的的具体实现:
- 当垃圾收集器工作的时候,会访问堆上存活的对象。对每一个访问的对象都会检查是否是候选的要去重的String对象。
- 如果是,把这个对象的一个引用插入到队列中等待后续的处理。一个去重的线程在后台运行,处理这个队列。处理队列的一个元素意味着从队列删除这个元素,然后尝试去重它引用的String对象。
- 使用一个Hashtable来记录所有的被String对象使用的不重复的char数组。当去重的时候,会查这个Hashtable,来看堆上是否已经存在一个一模一样的char数组。
- 如果存在,String对象会被调整引用那个数组,释放对原来的数组的引用,最终会被垃圾收集器回收掉。
UsestringDeduplication (bool):开启string去重,默认是不开启的,需要手动开启。