软件界有只猫,不用我说,各位看官肯定知道是哪只,那就是大名鼎鼎的Tomcat,现在又来了一只猫,据说是位东方萌妹子,暂且认作Tom猫的表妹,本来叫OpencloudDB,后又改名为Mycat,或许Cat更亲切?那现在就来认识下这只小猫吧。 数据库的核心地位就不说了,但现在的问题是,各种RDB,各种NoSQL交织,又是分布式、多租户的场景下,心里有没有十足的把握能稳住如此局面呢。有需求,就有市场!自然,相应的技术也应运而生,Mycat作为一款DB中间件,可以作为应用和DB间的“桥梁”,让后台DB的复杂组成对应用透明,处理分库分表、多租户架构和大数据实时查询等都不在话下!
工具:
Idea201902/JDK11/ZK3.5.5/Gradle5.4.1/RabbitMQ3.7.13/Lombok0.26/Erlang21.2/RocketMQ4.5.2/Sentinel1.6.3/SpringBoot2.1.6/RHEL7.6/VMware15.0.4/Mysql8.0.17/Mycat1.6.7.3/MysqlWorkbench6.3
**难度:**新手--战士--老兵--大师
目标:
1、 Linux下使用Mycat连接Mysql集群(两主一从),读写分离式应用;
步骤:
1、 建立Mysql集群,步骤参考往期文章(Linux下Mysql集群使用);
2、 下载Mycat,放到Linux中/usr/mycat下,记得先建立此目录;
3、 进入该目录,解压:;
[root@localhost mycat]# tar -zxvf Mycat-server-1.6.7.3-release-20190828135747-linux.tar.gz
4、 可以看到目录结构如下,和Tom哥确实略像: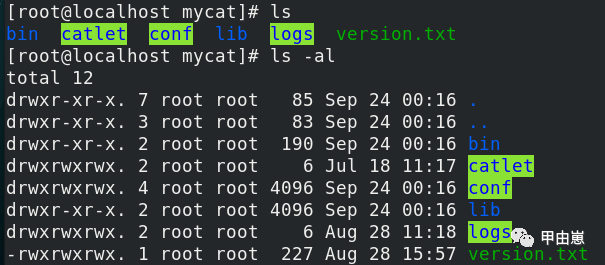 ;
;
- bin—Mycat的各种管理命令;
- catlet—扩展功能;
- conf—配置信息,这个也是本期重点使用的;
- lib—jar包库,因为Mycat是Java开发的;
- logs—日志文件;
5、 Mycat融合应用的架构,即本次目标架构:![*][nbsp1]如果需要做扩展高可用,即可变成这样的:![*][nbsp2]就是这么简单!;
6、 其实Mycat从应用上讲,就是做配置,源码可按喜好研究,据说很复杂!![*][nbsp3]主要是三个文件核心文件rule.xml、schema.xml、server.xml的配置:;
- server.xml:Mycat的配置文件,可以将Mycat视为DBServer的代理,
- schema.xml:逻辑表与物理DB/分片分库的映射配置,
- rule.xml:分库分表规则,
7、 挨个看看长啥样,参数的含义注释上基本有说明,这里都是全局配置参数:;
<system>中设置Mycat全局属性;<firewall>设置黑白名单;<user>设置用户登录Mycat的账号信息;<privileges>单独设置表的DML权限;
server.xml原版样例:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequnceHandlerType">2</property>
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--off heap for merge/order/group/limit 1开启 0关闭-->
<property name="useOffHeapForMerge">0</property>
<!--单位为m-->
<property name="memoryPageSize">64k</property>
<!--单位为k-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--单位为m-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
8、 schema.xml,配置schema下各个table的分片/分库,以及物理DB:;
<schema>+<table>租户和子表配置,<dataNode>分片,<dataHost>物理DB,
原版样例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost>
<dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost>
<dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost>
<dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> -->
<!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
9、 rule.xml详细描述表的分片规则,格式如下:;
<tableRule name="分片规则名">
<rule>
<columns>分片的列</columns>
<algorithm>分片算法名</algorithm>
</rule>
</tableRule>
<function name="分片算法名" class="算法实现类">
<property name="算法参数">参数值</property>
</function>
原版样例:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
部分常用的分片规则算法说明:
- PartitionByMurmurHash(一致性hash):将物理节点虚拟并映射为一个“一致性hash环”;
- PartitionByCRC32PreSlot(crc32slot 算法):crc32(key)%102400=slot,slot 按照范围均匀分布在 dataNode 上;
- LatestMonthPartion(单月小时拆分):单月内按照小时拆分,最小粒度是小时,可以一天最多 24 个分片,最少 1 个分片,一个月完后下月 从头开始循环;
- PartitionByMonth(自然月):按自然月分片;
- PartitionByRangeMod(范围求模):先进行范围分片计算出分片组,组内再求模;
- PartitionByJumpConsistentHash(一致性hash):另一种一致性hash算法;
- PartitionByFileMap(枚举):通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省份或区县来做保存,而全国省份区县是固定的;
- PartitionByLong(固定分片 hash 算法):取 id 的二进制低 10 位取模运算,即( id 二进制) &1111111111,partitionCount分片个数,partitionLength分片长度,默认这两个参数的向量积为1024;
- AutoPartitionByLong(范围约定):按照提前规划好分片字段范围计算属于哪个分片,start <= range <= end;
- PartitionByMod(求模):即根据 id 进行十进制求模预算,相比固定分片 hash,此种在批量插入时可能存在批量插入单事务插入多数据分片,增大事务一致性难度;
- PartitionByDate(按天分片):即根据指定的格式,起止日期,按日期划分,如果配置了 sEndDate 则代表数据达到了这个日期的分片后后循环从开始分片插入;
10、 情况一:如果DB是一主一从:需注意这里的主从复制由Mysql实现,Mycat不负责数据复制功能只需配置server.xml和schema.xml即可:本次server.xml实例:;
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property>
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property>
<property name="useGlobleTableCheck">0</property>
<property name="sqlExecuteTimeout">300</property>
<property name="sequnceHandlerType">2</property>
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">0</property>
<property name="memoryPageSize">64k</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">false</property>
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
</system>
<user name="mycat" defaultAccount="true">
<property name="password">12345678</property>
<property name="schemas">dubbo_db</property>
</user>
</mycat:server>
schema.xml示例:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="dubbo_db" checkSQLschema="true" sqlMaxLimit="100">
<table name="dubbo_delivery" primaryKey="ID" dataNode="dn1"/>
<table name="dubbo_finance" primaryKey="ID" dataNode="dn1 "/>
<table name="dubbo_item" primaryKey="ID" dataNode="dn1 " />
<table name="dubbo_order" primaryKey="ID" dataNode="dn1"/>
<table name="dubbo_order_detail" primaryKey="ID" dataNode="dn1 "/>
<table name="dubbo_stock" primaryKey="ID" dataNode="dn1 " />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="localhost1" database="dubbo_db" />
<!-- 物理数据库配置 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.1.204:3306" user="root" password="abcd@1234">
<readHost host="hostS2" url="192.168.1.205:3306" user="root" password="abcd@1234" />
</writeHost>
</dataHost>
</mycat:schema>
11、 情况二,即本期目标架构,DB是两主一从:server.xml不变,本次schema.xml实例:;
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="dubbo_db" checkSQLschema="true" sqlMaxLimit="100">
<table name="dubbo_delivery" primaryKey="ID" dataNode="dn1"/>
<table name="dubbo_finance" primaryKey="ID" dataNode="dn1,dn2" rule="rule1"/>
<table name="dubbo_item" primaryKey="ID" dataNode="dn1,dn2" rule="rule2"/>
<table name="dubbo_order" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-murmur"/>
<table name="dubbo_order_detail" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-month"/>
<table name="dubbo_stock" primaryKey="ID" dataNode="dn1" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1" dataHost="localhost1" database="dubbo_db" />
<dataNode name="dn2" dataHost="localhost2" database="dubbo_db" />
<!-- 物理数据库配置 -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.1.204:3306" user="root" password="abcd@1234">
<readHost host="hostS2" url="192.168.1.205:3306" user="root" password="abcd@1234" />
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.1.206:3306" user="root" password="abcd@1234" />
</dataHost>
</mycat:schema>
本次rule.xml实例:只有使用了分片模式时,才需要配置rule规则,这里写了三种rule,其实也没全部用上:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<!--规则定义-->
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<!--自定义规则-->
<tableRule name="rule1">
<rule>
<columns>userr_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>id</columns>
<algorithm>func2</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<!--规则算法实现-->
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<!--分片数量,partitionCount*partitionLength=1024-->
<property name="partitionCount">2</property>
<property name="partitionLength">512</property>
</function>
<function name="func2" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
</mycat:rule>
12、 测试:配置好mycat/conf/下的3个xml文件,即配置好了Mycat与物理DB的连接,应用端连接仅需修改连接串端口为Mycat的IP+端口,账号为server.xml中user信息,注意:要写上默认schema,否则启动应用报Mycatnochose错,![*][nbsp4];
13、 此处有坑!如果Mysql是独立安装在linux上,需要对远程访问打开,否则访问默认仅限本地,导致远程连接一直报错,以开放root用户远程连接为例:;
mysql> use mysql;
mysql> update user set Host='%' where User='root';
mysql> quit;
再重启mysql:
[root@localhost ~]# systemctl restart mysqld
启动Mycat:
[root@localhost ~]# cd /usr/mycat/mycat/bin
[root@localhost bin]# ./mycat start
mycat启动成功: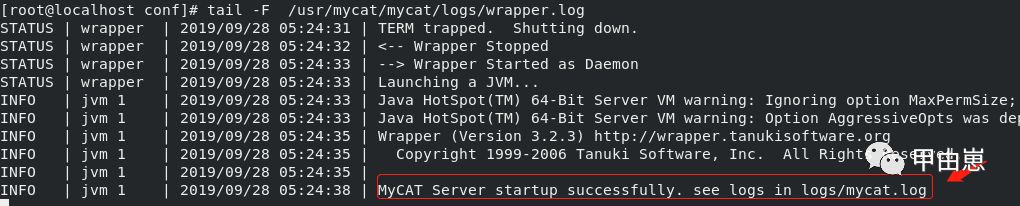
如果启动有问题,使用以下命令查看log:
[root@localhost conf]# tail -F /usr/mycat/mycat/logs/wrapper.log
[root@localhost conf]# tail -F /usr/mycat/mycat/logs/mycat.log
然后可以在window上使用如MysqlWorkbench,Navicat测试下是否连接正常,并测试下Mycat连接: 为了集中测试代码,我只改写了finance模块,写个service方法:com.biao.mall.service.DubboFinanceServiceImpl中:
为了集中测试代码,我只改写了finance模块,写个service方法:com.biao.mall.service.DubboFinanceServiceImpl中:
//插入1000条数据,看data分布
@Override
public void testMycat(){
DubboFinanceEntity financeEntity = new DubboFinanceEntity();
for (int i = 0; i < 1000; i++) {
financeEntity.setUserId(String.valueOf(i+100));
financeDao.insert(financeEntity);
}
return "testMycat successfully";
}
写个controller方法跑一跑:
@RestController
@RequestMapping("/finance")
public class DubboFinanceController {
private DubboFinanceServiceImpl financeService;
@Autowired
public DubboFinanceController(DubboFinanceServiceImpl financeService) {
this.financeService = financeService;
}
@RequestMapping("/mycat")
public void testMycat(){
return financeService.testMycat();
}
}
URI来一个! DB情况如下,请看数量和ID(DB主键)分布,红色数字是IP,user_id分布分为两部分488+512=1000,ID(DB主键)为自增型,所以都从1开始,204和205为主从,故保持一致:
DB情况如下,请看数量和ID(DB主键)分布,红色数字是IP,user_id分布分为两部分488+512=1000,ID(DB主键)为自增型,所以都从1开始,204和205为主从,故保持一致: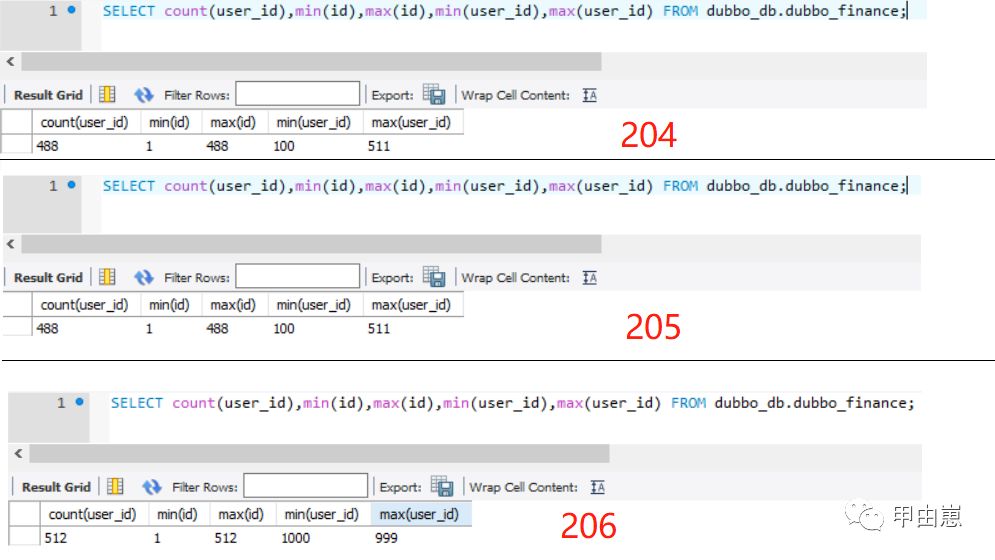
这里只测试了两主一从和一种分片规则,其他类似,请君自测!
13、 代码地址:其中的day16,;
https://github.com/xiexiaobiao/dubbo-project.git
后记:
1、 认识Mycat的关键特性:;
- 支持Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理;
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从;
- 基于Nio实现,有效管理线程,高并发问题;
- 支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页;
- 支持通过全局表,ER关系的分片策略,实现了高效的单库多表join查询;
- 支持多租户方案,即同DB下多schema模式;
- 支持全局序列号,解决分布式下的主键生成问题;
- 分片规则丰富,插件化开发,易于扩展,可自定义;
- 集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(V2.0dev);
- 引入Mycat的无痕切换,我觉得这是最大的优势;
2、 认清Mycat的局限性:;
- 目前只支持跨库join2个表,不支持3 表及其以上跨库 join ;
- Mycat并没有根据二阶段提交协议实现 XA事务,而是只保证 prepare 阶段数据一致性的弱XA事务,分布式事务场景下,强一致性无法保证;
- 分页排序场景下,会一次查询所有分片,再集中排序分页,有性能瓶颈;
- 不同类型DB适配一般,如Oracle/SQLServer等,由于SQL语法差异,须做彻底的语句兼容测试;
- 没有API配置方法,只有XML方式配置,十分过时;
3、 Mycat作为DB上一层的重量级中间件,统一了入口,实际上也破坏了分布式的定义,未能充分发挥DB层的效能,所以也有很多不看好的声音,DB独立使用,更能发挥灵活自由配置,直接对接应用层更为高效;
4、 总结:Mycat框架的使用,需持谨慎态度,至少目前来看如此;