路由引擎
无论是分库分表、还是读写分离,一个SQL在DB上执行前都需要经过特定规则运算获得运行的目标库表信息。路由引擎的职责定位根据分片规则计算SQL应该在哪个数据库、哪个表上执行。前者结果会传给后续执行引擎,然后根据其数据库标识获取对应的数据库连接;后者结果则会传给改写引擎在SQL执行前进行表名的改写,即替换为正确的物理表名。计算哪个数据库依据的算法是要用户配置的库路由规则,计算哪个表依据的算法是用户配置的表路由规则。目前在ShardingSphere中需要进行路由的功能模块有两个:先处理分库分表sharding再处理读写分离master-slave
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是BETWEEN)。不携带分片键的SQL则采用广播路由。
路由引擎的整体结构划分如下图。
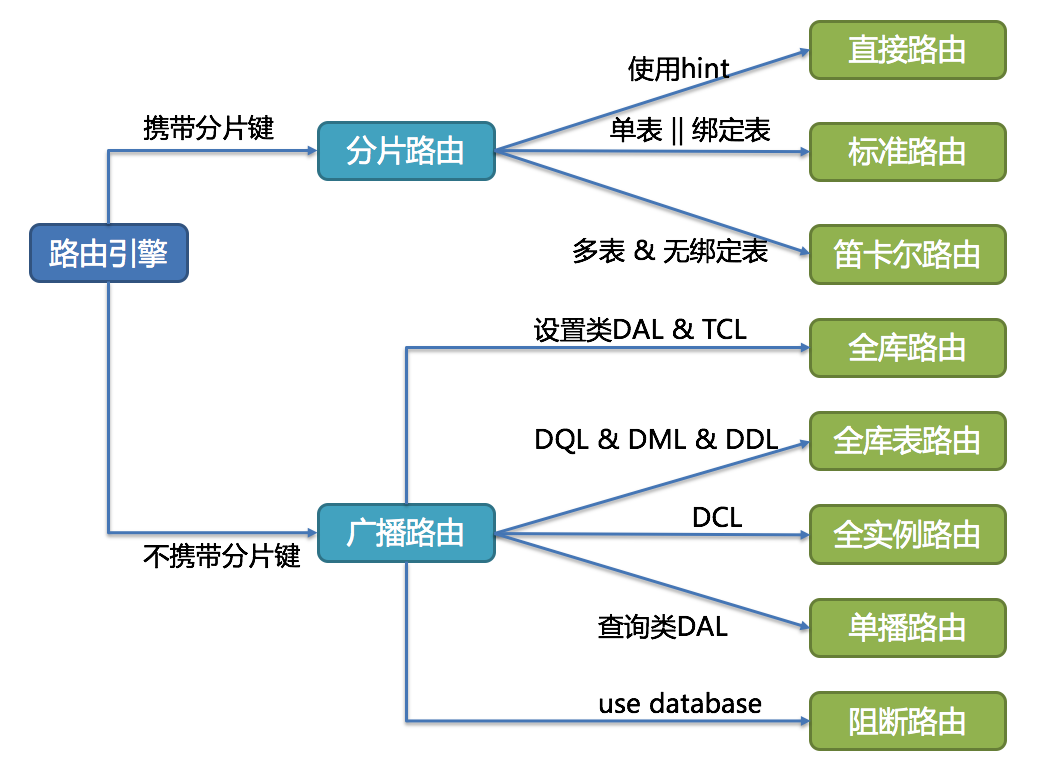
一、分片路由
用于原生SQL中有包含有分片键的场景,又细分为直接路由、标准路由和笛卡尔积路由这3种类型。执行的性能也依次减弱。
1.1 直接路由
满足直接路由的条件相对苛刻,它需要通过Hint强制路由的(使用HintAPI直接指定路由至库表)方式分片,并且是只分库不分表的前提下,则可以避免SQL解析和之后的结果归并。 因此它的兼容性最好,可以执行包括子查询、自定义函数等复杂情况的任意SQL。直接路由还可以用于分片键不在SQL中的某些特殊场景。例如,设置用于数据库分片的键为3
hintManager.setDatabaseShardingValue(3);
假如路由算法为 order_id % 2,当一个逻辑库t_order对应2个真实库ds_0和ds_1时,路由后SQL将在ds_1上执行。下方是使用API的代码样例:
String sql = "SELECT * FROM t_order";
try (
HintManager hintManager = HintManager.getInstance();
Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
hintManager.setDatabaseShardingValue(3);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
//...
}
}
}
1.2 标准路由
标准路由是ShardingSphere最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表和广播表之间关联查询的SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是BETWEEN或IN时,则路由结果不一定落入唯一的库(表),因此一条逻辑SQL最终可能被拆分为多条用于执行的真实SQL。 举例说明,如果按复合分片规则按照order_id的奇数和偶数进行分库,user_id 的奇数和偶数进行分表时,一个单表查询的SQL如下:
SELECT * FROM t_order WHERE order_id IN (1, 2) AND user_id IN (1,2) ;
那么路由的结果应为:
SELECT * FROM t_order WHERE ds0.order_id_0 IN (1, 2) AND user_id IN (1,2) ;
SELECT * FROM t_order WHERE ds0.order_id_1 IN (1, 2) AND user_id IN (1,2) ;
SELECT * FROM t_order WHERE ds1.order_id_0 IN (1, 2) AND user_id IN (1,2) ;
SELECT * FROM t_order WHERE ds1.order_id_1 IN (1, 2) AND user_id IN (1,2) ;
绑定表和广播表的join关联查询与单表查询复杂度和性能相当
- 广播表在每个分库中都有相同的一份数据,例如原生SQL jion t_order_item,每个分库都存在一张t_order_item表,不需要特殊处理就可以查询 ;
- 绑定表之间的数据是一一对应的,order_id 为奇数的数据只会存储在相同库的一个分表中,有很强的关联性,SQL拆分后的数目与单表是一致的;
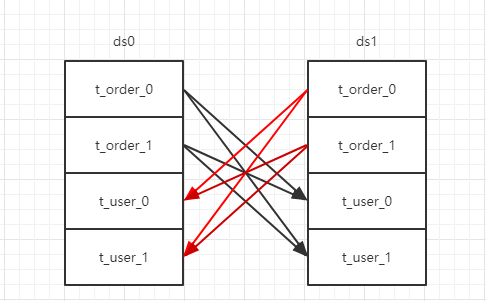
1.3 笛卡尔路由
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行。
不管是mycat还是sharding,所有的分库分表对非绑定表和广播表之间的关联查询都无法做到有效优化支持,无法根据分片规则计算出SQL应该在哪个数据库、哪个表上执行,那么结果就是把所有分库分表中关联使用到的表交叉查询。笛卡尔路由查询性能较低,需谨慎使用。
示例如下:
SELECT * FROM t_order AS t1 LFTE JION t_user AS t2 ON t1.user_id = t2.user_id
WHERE t1.order_id IN (1, 2)
二、广播路由
对于不携带分片键的SQL,则采取广播路由的方式。根据SQL类型又可以划分为全库表路由、全库路由、全实例路由、单播路由和阻断路由这5种类型。
2.1 全库表路由
全库表路由用于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分片键的DQL和DML,以及DDL等。例如:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
则会遍历所有数据库中的所有表,逐一匹配逻辑表和真实表名,能够匹配得上则执行。路由后成为
SELECT * FROM ds0.t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM ds0.t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM ds1.t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM ds1.t_order_1 WHERE good_prority IN (1, 10);
2.2 全库路由
全库路由用于处理对数据库的操作,包括用于库设置的SET类型的数据库管理命令,以及TCL这样的事务控制语句。 在这种情况下,会根据逻辑库的名字遍历所有符合名字匹配的真实库,并在真实库中执行该命令,例如:
SET autocommit=0;
在t_order中执行时有2个真实库。则实际会在 ds0 和 ds1 上都执行这个命令。
2.3 全实例路由
全实例路由用于DCL操作,授权语句针对的是数据库的实例。无论一个实例中包含多少个Schema,每个数据库的实例只执行一次。例如:
CREATE USER customer@127.0.0.1 identified BY '123';
这个命令将在所有的真实数据库实例中执行,以确保customer用户可以访问每一个实例。
2.4 单播路由
单播路由用于获取某一真实表信息的场景,它仅需要从任意库中的任意真实表中获取数据即可。例如:
DESCRIBE t_order;
ds0 和 但ds1 上的的两个真实表t_order_0,t_order_1的描述结构相同,所以这个命令在任意真实表上选择执行一次。
2.5 阻断路由
阻断路由用于屏蔽SQL对数据库的操作,例如:
USE order_db;
这个命令不会在真实数据库中执行,因为ShardingSphere采用的是逻辑Schema的方式,无需将切换数据库Schema的命令发送至数据库中。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: