目录
一、复合分片策略ComplexShardingStrategy
二、ComplexShardingStrategy配置实现
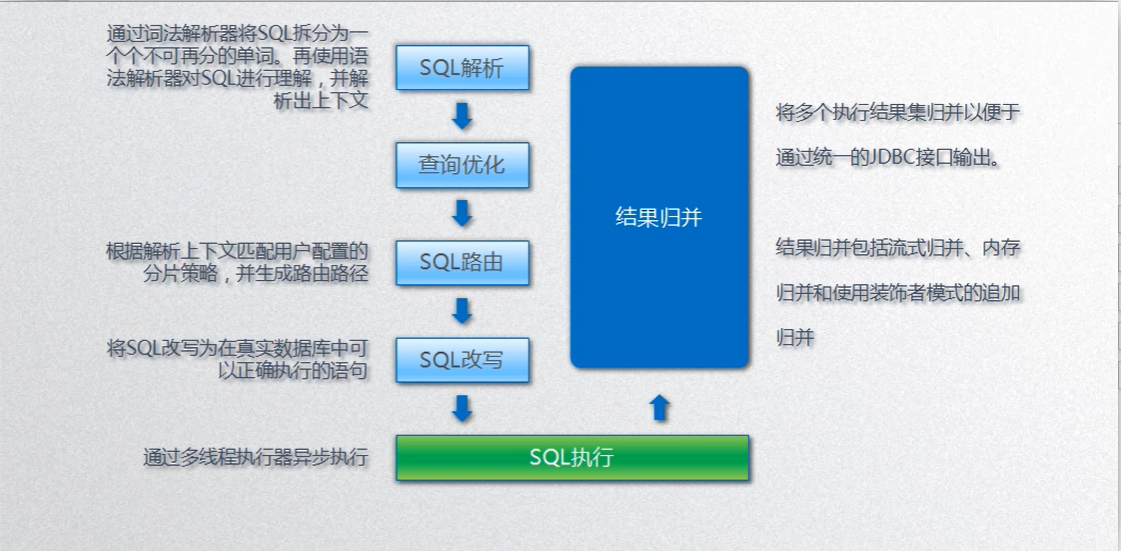
分库分表最核心的两点SQL 路由 、 SQL 改写
application.properties 配置
自定义ComplexShardingAlgorithm
一、复合分片策略ComplexShardingStrategy
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
- ComplexShardingStrategy支持多分片键
- 由于多分片键之间的关系复杂,因此Sharding-JDBC并未做过多的封装,而是直接将分片键值组合以及分片操作符交于算法接口,完全由应用开发者实现,提供最大的灵活度
二、ComplexShardingStrategy配置实现
Sharding -jdbc 在使用分片策略的时候,与分片算法是成对出现的,每种策略都对应一到两种分片算法(不分片策略NoneShardingStrategy除外)
分库分表最核心的两点SQL 路由 、 SQL 改写
SQL 路由:解析原生SQL,确定需要使用哪些数据库,哪些数据表
Route (路由)引擎:为什么要用Route 引擎呢?
在实际查询当中,数据可能不只是存在一台MYSQL服务器上,
SELECT * FROM t_order WHERE order _id IN(1,3,6)
数据分布:
ds0.t_order0 (1,3,5,7)
ds1.t_order0(2,4,6)
这个SELECT 查询就需要走2个database,如果这个SQL原封不动的执行,肯定会报错(表不存在),Sharding-jdbc 必须要对这个sql进行改写,将库名和表名 2个路由加上
SELECT * FROM ds0.t_order0 WHERE order _id IN(1,3)
SELECT * FROM ds0.t_order1 WHERE order _id IN(6)
SQL 改写:将SQL 按照一定规则,重写FROM 的数据库和表名(Route 返回路由决定需要去哪些库表中执行SQL)
application.properties 配置
配置主要分为三个部分
1、 配置数据源;
2、 分库配置;
3、 分表配置;
```java # 复合分片 sharding.jdbc.datasource.names=ds0,ds1 sharding.jdbc.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds0.url=jdbc:mysql://127.0.0.1:5306/ds0?useUnicode=yes&characterEncoding=utf8 sharding.jdbc.datasource.ds0.username=root sharding.jdbc.datasource.ds0.password=root sharding.jdbc.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver sharding.jdbc.datasource.ds1.url=jdbc:mysql://127.0.0.1:5306/ds1?useUnicode=yes&characterEncoding=utf8 sharding.jdbc.datasource.ds1.username=root sharding.jdbc.datasource.ds1.password=root # 分库配置 (行表达式分片策略 + 行表达式分片算法) sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=user_id sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2} sharding.jdbc.config.sharding.binding-tables=t_order,t_order_item # t_order分表配置 (复合分片策略) sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}_$->{0..1} sharding.jdbc.config.sharding.tables.t_order.table-strategy.complex.sharding-columns=user_id,order_id sharding.jdbc.config.sharding.tables.t_order.table-strategy.complex.algorithm-class-name=ai.yunxi.sharding.config.ComplexShardingAlgorithm # t_order_item分表配置 (复合分片策略) sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds$->{0..1}.t_order_item$->{0..1}_$->{0..1} # 标准 和 inline 都是单分片键 ,复合分片策略可以配置则多分片键 sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.complex.sharding-columns=user_id,order_id # 自定义算法,让使用者根据业务自定义实现(开发性接口更灵活方便) sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.complex.algorithm-class-name=ai.yunxi.sharding.config.ComplexShardingAlgorithm # 定义广播表 sharding.jdbc.config.sharding.broadcast-tables=t_province sharding.jdbc.config.props.sql.show=true
### **自定义ComplexShardingAlgorithm** ###
> ```java
> import io.shardingsphere.api.algorithm.sharding.ListShardingValue;
> import io.shardingsphere.api.algorithm.sharding.ShardingValue;
> import io.shardingsphere.api.algorithm.sharding.complex.ComplexKeysShardingAlgorithm;
> import java.util.ArrayList;
> import java.util.Collection;
> import java.util.Iterator;
> import java.util.List;
>
> public class ComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm {
>
> /**
> *
> * @param collection 在加载配置文件时,会解析表分片规则。将结果存储到 collection中,doSharding()参数使用
> * @param shardingValues SQL中对应的
> * @return
> */
> @Override
> public Collection<String> doSharding(Collection<String> collection, Collection<ShardingValue> shardingValues) {
> System.out.println("collection:" + collection + ",shardingValues:" + shardingValues);
>
> Collection<Integer> orderIdValues = getShardingValue(shardingValues, "order_id");
> Collection<Integer> userIdValues = getShardingValue(shardingValues, "user_id");
>
> List<String> shardingSuffix = new ArrayList<>();
>
> // user_id,order_id分片键进行分表
> for (Integer userId : userIdValues) {
> for (Integer orderId : orderIdValues) {
> String suffix = userId % 2 + "_" + orderId % 2;
> for (String s : collection) {
> if (s.endsWith(suffix)) {
> shardingSuffix.add(s);
> }
> }
> }
> }
>
> return shardingSuffix;
> }
>
> /**
> * 例如: SELECT * FROM T_ORDER user_id = 100000 AND order_id = 1000009
> * 循环 获取SQL 中 分片键列对应的value值
> * @param shardingValues sql 中分片键的value值 -> 1000009
> * @param key 分片键列名 -> user_id
> * @return shardingValues 集合 -> [1000009]
> */
> private Collection<Integer> getShardingValue(Collection<ShardingValue> shardingValues, final String key) {
> Collection<Integer> valueSet = new ArrayList<>();
> Iterator<ShardingValue> iterator = shardingValues.iterator();
> while (iterator.hasNext()) {
> ShardingValue next = iterator.next();
> if (next instanceof ListShardingValue) {
> ListShardingValue value = (ListShardingValue) next;
> // user_id,order_id分片键进行分表
> if (value.getColumnName().equals(key)) {
> return value.getValues();
> }
> }
> }
> return valueSet;
> }
> }
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: