ElasticSearch7.3学习(六)----文档(document)内部机制详解
1、数据路由
1.1 文档存储怎么路由到相应分片?
一个文档,最终会落在主分片的一个分片上,到底应该在哪一个分片?这就是数据路由。
1.2 路由算法
shard = hash(routing) % number_of_primary_shards
简单来说就是哈希值对主分片数取模。
举例:
对一个文档经行crud时,都会带一个路由值 routing number。默认为文档_id(可能是手动指定,也可能是自动生成)。
存储1号文档,经过哈希计算,哈希值为2,此索引有3个主分片,那么计算2%3=2,就算出此文档在P2分片上。决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的。无论hash值是几,无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。
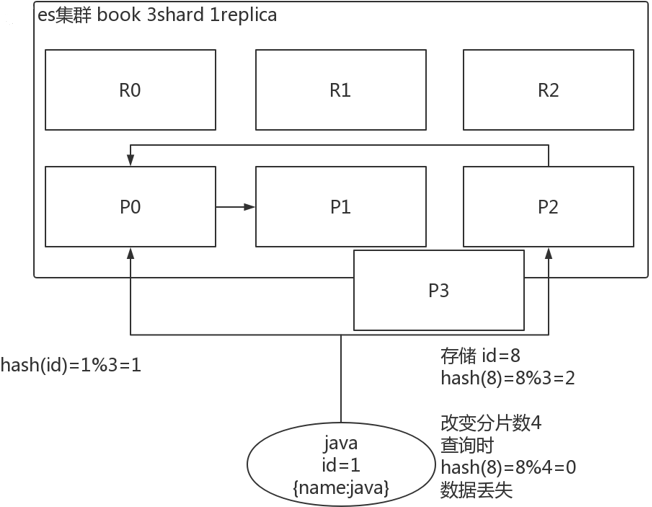
1.3 手动指定 routing number
PUT /test_index/_doc/15?routing=num
{
"num": 0,
"tags": []
}
场景:在程序中,架构师可以手动指定已有数据的一个属性为路由值,好处是可以定制一类文档数据存储到一个分片中。缺点是设计不好,会造成数据倾斜。所以,不同文档尽量放到不同的索引中。剩下的事情交给es集群自己处理。
1.4 主分片数量不可变
涉及到以往数据的查询搜索,所以一旦建立索引,主分片数不可变。
2、文档(Document)的增删改内部机制(写数据过程)
增删改可以看做update,都是对数据的改动。一个改动请求发送到es集群,经历以下四个步骤:
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
(3)实际的node上的primary shard处理请求,然后将数据同步到replica node。
(4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
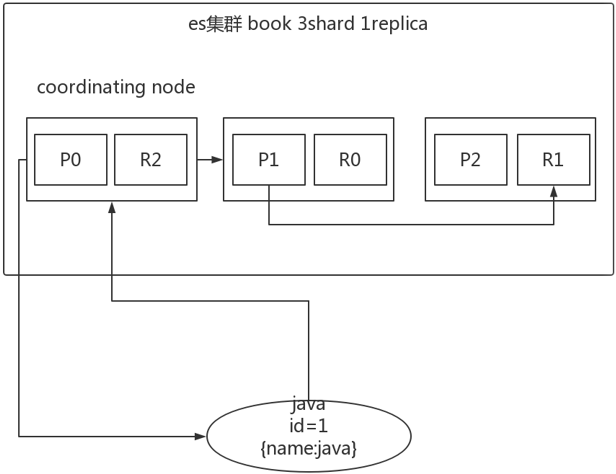
如上图所示,存在一个book索引,3个主分片,一个副本分片。比如说选择第一个节点为协调节点,在根据id进行数据路由,判断出属于第一个分片,找到对应的主分片完成对应的请求,在去对应的副本分片完成请求,最后在将响应结果返回给客户端。
3、文档的查询内部机制(读数据过程)
1、 客户端发送请求到任意一个node,成为coordinatenode;
2、 coordinatenode对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primaryshard以及其所有replica中随机选择一个,让读请求负载均衡;
3、 接收请求的node返回document给coordinatenode;
4、 coordinatenode返回document给客户端;
5、 特殊情况:document如果还在建立索引过程中,可能只有primaryshard有,任何一个replicashard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primaryshard和replicashard就都有了;
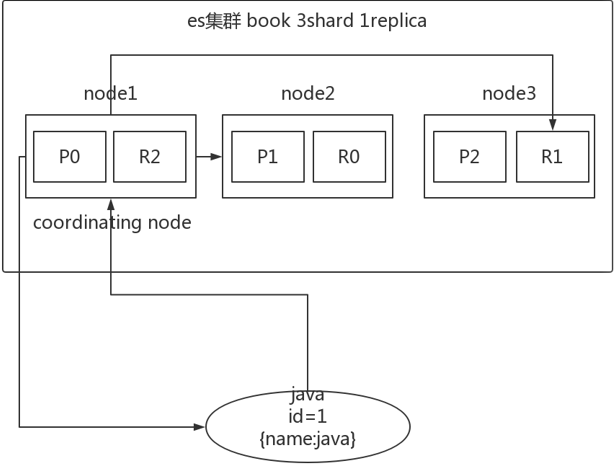
如上图所示,存在一个book索引,3个主分片,一个副本分片。比如说选择第一个节点为协调节点,在根据id进行数据路由,判断出属于第一个分片,在primary shard以及其所有replica中随机选择一个,最后在将响应结果返回给客户端。
4、文档的搜索机制(过程)
es最强大的是做全文检索,就是比如你有三条数据:
- java真好玩儿啊
- java好难学啊
- j2ee特别牛
你根据java 关键词来搜索,将包含 java的 document 给搜索出来。es 就会给你返回:java真好玩儿啊,java好难学啊。
- 客户端发送请求到一个 coordinate node。
- 协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard,都可以。
- query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
- fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
5、bulk api奇特的json格式
POST /_bulk
{"action": {"meta"}}
{"data"}
{"action": {"meta"}}
{"data"}
[
{
"action":{
"method":"create"
},
"data":{
"id":1,
"field1":"java",
"field1":"spring",
}
},
{
"action":{
"method":"create"
},
"data":{
"id":2,
"field1":"java",
"field1":"spring",
}
}
]
如上所示,为什么bulk api不采用下面的那种阅读性非常强的格式而是采用上面那种格式呢?原因有以下3点。
1、 bulk中的每个操作都可能要转发到不同的node的shard去执行;
2、 如果采用比较良好的json数组格式,这种格式允许任意的换行,整个可读性非常棒,读起来很爽,es拿到这种标准格式的json串以后,要按照下述流程去进行处理;
(1)将json数组解析为JSONArray对象,这个时候,整个数据,就会在内存中出现一份一模一样的拷贝,一份数据是json文本,一份数据是JSONArray对象
(2)解析json数组里的每个json,对每个请求中的document进行路由
(3)为路由到同一个shard上的多个请求,创建一个请求数组。100请求中有10个是到P1.
(4)将这个请求数组序列化
(5)将序列化后的请求数组发送到对应的节点上去
3、 耗费更多内存,更多的jvmgc开销;
一般来说bulk size最佳大小在几千条左右,然后大小在10MB左右,所以说,可怕的事情来了。假设说现在100个bulk请求发送到了一个节点上去,然后每个请求是10MB,100个请求,就是1000MB = 1GB,然后每个请求的json都copy一份为jsonarray对象,此时内存中的占用就会翻倍,就会占用2GB的内存,甚至还不止。因为弄成jsonarray之后,还可能会多搞一些其他的数据结构,2GB+的内存占用。占用更多的内存可能就会积压其他请求的内存使用量,比如说最重要的搜索请求,分析请求,等等,此时就可能会导致其他请求的性能急速下降。另外的话,占用内存更多,就会导致java虚拟机的垃圾回收次数更多,跟频繁,每次要回收的垃圾对象更多,耗费的时间更多,导致es的java虚拟机停止工作线程的时间更多。
再看看现在的奇特格式
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "5" }}
{ "create": { "_index": "test_index", "_id": "14" }}
{ "test_field": "test14" }\n
{ "update": { "_index": "test_index", "_id": "2"} }
{ "doc" : {"test_field" : "bulk test"} }\n
(1)不用将其转换为json对象,不会出现内存中的相同数据的拷贝,直接按照换行符切割json
(2)对每两个一组的json,读取meta,进行document路由
(3)直接将对应的json发送到node上去
这种格式最大的优势在于,不需要将json数组解析为一个JSONArray对象,形成一份大数据的拷贝,不至于浪费内存空间,也能尽可能地保证性能。
本文来自博客园,作者:|旧市拾荒|,转载请注明原文链接:https://www.cnblogs.com/xiaoyh/p/16001448.html
posted @ 2022-03-13 23:13 |旧市拾荒| 阅读( 586) 评论( 0) 编辑 收藏 举报
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: